
Изменения курса рубля два года назад заставили нас задуматься о способах снижения стоимости железа для Почты Mail.Ru. Нам понадобилось уменьшить количество закупаемого железа и цену за хостинг. Чтобы найти, где сэкономить, давайте посмотрим, из чего состоит почта.

Индексы и тела писем составляют 15 % объёма, файлы — 85 %. Место для оптимизаций надо искать в файлах (аттачах в письмах). На тот момент у нас не была реализована дедупликация файлов; по нашим оценкам, она может дать экономию в 36 % всего объёма почты: многим пользователям приходят одинаковые письма (рассылки социальных сетей с картинками, магазинов с прайсами и т.д.). В этом посте я расскажу про реализацию такой системы, сделанной под руководством PSIAlt.
Хранилище метаинформации
Есть поток файлов, и надо быстро понимать, дублируется файл или нет. Простое решение — давать им имена, которые генерируются на основе содержимого файла. Мы используем sha1. Изначальное имя файла хранится в самом письме, поэтому о нём заботиться не надо.
Мы получили письмо, достали файлы, посчитали от содержимого sha1 и значение вычисления добавили в письмо. Это необходимо, чтобы при отдаче письма легко найти его файлы в нашем будущем хранилище.
Теперь зальём туда файл. Нам интересно спросить у хранилища: есть ли у тебя файл с sha1? Это значит, что надо все sha1 хранить в памяти. Назовём место для хранения fileDB.
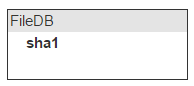
Один и тот же файл может быть в разных письмах; значит, будем вести счётчик количества писем с таким файлом.
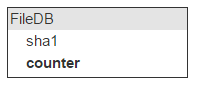
При добавлении файла счётчик увеличивается. Около 40 % файлов удаляется. Соответственно, при удалении письма, в котором есть файлы, залитые в облако, надо уменьшать счётчик. Если он достигает 0 — файл можно удалить.
Тут мы встречаем первую сложность: информация о письме (индексы) находится в одной системе, а о файле — в другой. Это может привести к ошибке, например:
- Приходит запрос на удаление письма.
- Система поднимает индексы письма.
- Видит, что есть файлы (sha1).
- Посылает запрос на удаление файла.
- Происходит сбой, и письмо не удаляется.
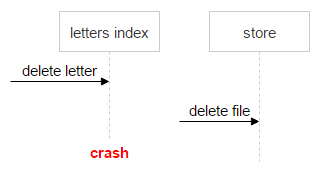
В этом случае письмо осталось в системе, а счётчик уменьшился на единицу. Когда второй раз придёт удаление этого письма — мы ещё раз уменьшим счётчик и получим проблему. Файл может быть ещё в одном письме, а счётчик у него нулевой.
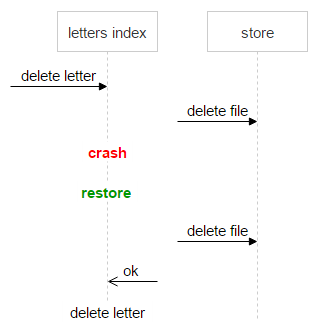
Важно не потерять данные. Нельзя допустить ситуацию, когда пользователь открывает письмо, а файла там нет. При этом хранить на дисках немного лишних файлов не проблема. Достаточно иметь механизм, который однозначно покажет, корректно или нет счётчик свёлся к нулю. Для этого мы завели ещё одно поле — magic.
Алгоритм простой. В письме вместе с sha1 от файла мы генерируем и сохраняем ещё одно произвольное число. Все запросы на заливку или удаление файла делаем с этим числом. Если пришёл запрос на заливку, то к хранимому magic прибавляем это число. Если на удаление — отнимаем.
Таким образом, если все письма корректное количество раз увеличили и уменьшили счётчик, то magic тоже будет равен нулю. Если он отличен от нуля — удалять файл нельзя.
Давайте рассмотрим это на примере. Есть файл sha1. Он залит один раз, и при заливке письмо сгенерировало для него случайное число (magic), равное 345.

Теперь приходит ещё одно письмо с таким же файлом. Оно генерирует свой magic (123) и заливает файл. Новый magic суммируется со старым, а счётчик увеличивается на единицу. В результате в FileDB magic для sha1 стал равен 468, а counter — 2.

Пользователь удаляет второе письмо. Из текущего magic вычитается magic, запомненный во втором письме, counter уменьшается на единицу.
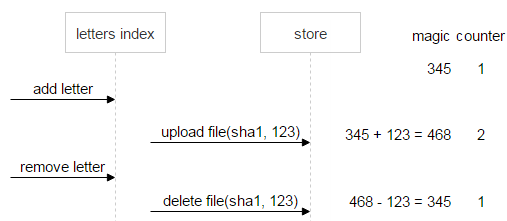
Сначала рассмотрим ситуацию, когда всё идёт хорошо. Пользователь удаляет первое письмо. Тогда magic и counter станут равны нулю. Значит, данные консистентны, можно удалять файл.

Теперь предположим, что что-то пошло не так: первое письмо отправило две команды на удаление. Counter (0) говорит о том, что ссылок на файл не осталось, однако magic (222) сигнализирует о проблеме: файл удалять нельзя, пока данные не приведены к консистентному состоянию.
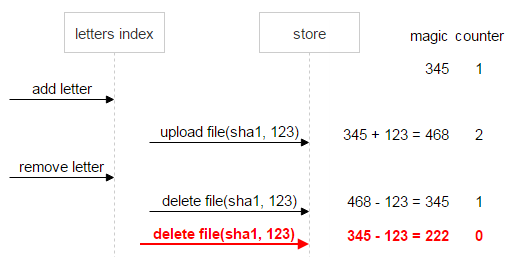
Давайте докрутим ситуацию до конца и предположим, что и первое письмо удалено. В этом случае magic (–123) по-прежнему говорит о неконсистентности данных.
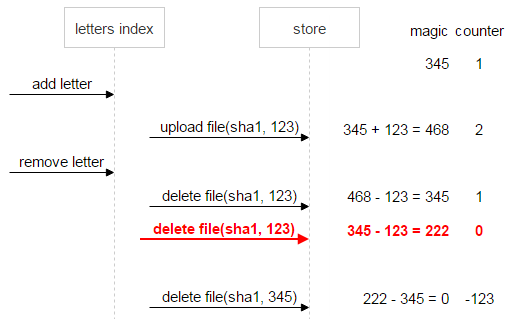
Для надёжности сразу же, как только счётчик стал равен нулю, а magic — нет (в нашем случае это magic = 222, counter = 0), файлу выставляется флаг «не удалять». Так что даже если после множества добавлений и удалений по дикому стечению обстоятельств magic и counter сравняются с нулём, мы всё равно будем знать, что файл проблемный и удалять его нельзя.
Вернёмся к FileDB. У любой сущности есть некоторые флаги. Планируете вы или нет, но они понадобятся. Например, вам надо пометить файл как неудаляемый.
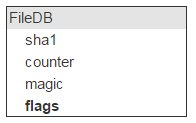
У нас есть все свойства файла, кроме главного: где он физически лежит. Это место идентифицирует сервер (IP) и диск. Таких серверов с диском должно быть два.
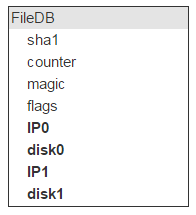
Но на одном диске лежит много файлов (в нашем случае — около 2 000 000). Значит, у этих записей в FileDB в качестве места хранения будут одни и те же пары дисков. Так что хранить эту инфу в FileDB расточительно. Выносим её в отдельную таблицу, а в FileDB оставляем ID для указания на запись в новой таблице.
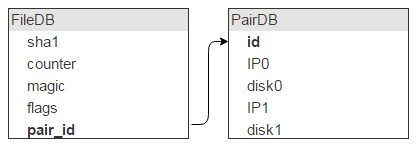
Думаю, очевидно, что, помимо такого описания пары, нужно ещё поле flags. Забегая вперед, скажу: во флагах лежит информация о том, что диски сейчас залочены, например один вылетел и второй копируется, поэтому ничего нового на них писать нельзя.

Также нам надо знать количество свободного места на каждом диске. Добавляем эти поля в таблицу.

Чтобы всё работало быстро, FileDB и PairDB должны быть в оперативной памяти. Возьмём Tarantool 1.5. Сразу скажу, что сейчас следует использовать последнюю версию. В FileDB пять полей (по 20, 4, 4, 4 и 4 байта), итого 36 байт данных. Ещё на каждую запись хранится header размером 16 байт плюс по 1 байту на длину каждого поля. Итого получается 57 байт на одну запись.

Tarantool позволяет задать в конфиге минимальный размер для аллокации, так что можно свести практически к нулю размер накладных расходов по памяти. Мы будем аллоцировать ровно столько, сколько надо под одну запись. У нас 12 000 000 000 файлов.
(57 * 12 * 10^9) / (1024^3) = 637 GbНо это не всё, нам нужен индекс по полю sha1. А это ещё 12 байт на запись.
(12 * 12 * 10^9) / (1024^3) = 179 GbИтого получается около 800 Gb оперативной памяти. Но не забываем про реплики, а это значит × 2.

Если берём машины с 256 Gb оперативной памяти, то нам потребуется восемь машин.
Мы можем оценить размер PairDB. Но средний размер файла у нас 1 Мб и диски размером 1 Tb. Это позволяет хранить около 1 000 000 файлов на диске. Значит, нам надо около 28 000 дисков. Одна запись в PairDB описывает два диска, следовательно, в PairDB 14 000 записей. Это пренебрежимо мало по сравнению с FileDB.
Заливка файлов
Со структурой баз данных разобрались, теперь перейдем к АПИ для работы с системой. Вроде нужны методы upload и delete. Но вспомним о дедупликации: не исключено, что файл, который мы пытаемся залить, уже есть в хранилище. Нет смысла заливать его второй раз. Значит, потребуются такие методы:
- inc(sha1, magic) — увеличить счётчик. Если файла нет — вернуть ошибку. Вспоминаем, что ещё нам нужен magic. Это позволит защититься от неверных удалений файлов.
- upload(sha1, magic) — его следует вызывать, если inc вернул ошибку. Значит, такого файла нет и надо его залить.
- dec(sha1, magic) — вызывается, если пользователь удаляет письмо. Сначала мы уменьшаем счётчик.
- GET /sha1 — скачиваем файл просто по http.
Разберём, что происходит во время upload. Для демона, который реализует этот интерфейс, мы выбрали протокол iproto. Демоны должны масштабироваться на любое количество машин, поэтому не хранят состояние. К нам приходит по сокету запрос:

По имени команды мы знаем длину заголовка и считываем сначала его. Сейчас нам важна длина файла origin-len. Надо подобрать пару серверов для его заливки. Просто выкачиваем весь PairDB, там всего несколько тысяч записей. Далее применяем стандартный алгоритм выбора нужной пары. Составляем отрезок, длина которого равна сумме свободных мест всех пар, и случайно выбираем точку на отрезке. В какую пару попала точка на отрезке — та и выбрана.

Однако выбирать пару таким простым способом опасно. Представьте, что все диски заполнены на 90 % и вы добавили пустой диск. С огромной вероятностью все новые файлы будут литься на него. Чтобы избежать этой проблемы, нужно брать для построения общего отрезка не свободное место пары, а корень N-й степени от свободного места.
Пару выбрали, но наш демон потоковый, и если мы начали стримить файл на сторедж, то обратной дороги нет. Поэтому, прежде чем заливать реальный файл, вначале отправляем небольшой тестовый. Если заливка тестового файла прошла, тогда вычитаем из сокета filecontent и стримим его на сторедж. Если нет — выбираем другую пару. Sha1 можно считать на лету, поэтому его мы тоже проверяем сразу при заливке.
Рассмотрим теперь заливку файла от loader к выбранной паре дисков. На машинах с дисками мы подняли nginx и используем протокол webdav. Пришло письмо. В FileDB этого файла ещё нет, а значит, его надо через loader залить на пару дисков.
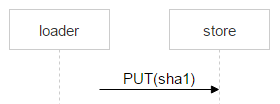
Но ничего не мешает ещё одному пользователю получить такое же письмо: предположим, у письма два адресата. В FileDB этого файла пока нет; значит, ещё один loader будет заливать точно такой же файл и может выбрать эту же пару.
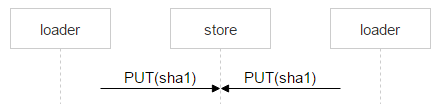
Скорее всего, nginx решит проблему корректно, но нам надо всё контролировать, поэтому сохраняем файл со сложным именем.
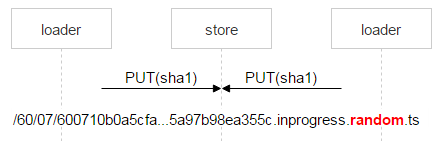
Красным выделена часть имени, в которой каждый loader пишет случайное число. Таким образом, два PUT не пересекаются и заливают разные файлы. Когда nginx ответил 201, loader делает атомарную операцию MOVE, указывая конечное имя файла.
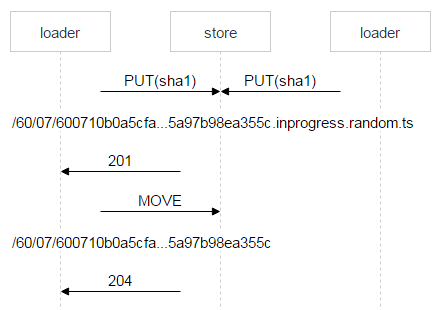
Когда второй loader дольёт свой файл и тоже сделает MOVE, файл перезапишется, но это один и тот же файл — проблем не будет. Когда он окажется на дисках, надо добавить запись в FileDB. Тарантул у нас разбит на два спейса. Пока мы используем только нулевой.

Однако вместо простого добавления записи о новом файле мы используем хранимую процедуру, которая либо увеличивает счётчик файла, либо добавляет запись о файле. Почему так? За время, когда loader проверил, что файла нет в FileDB, залил его и пошёл добавлять запись, кто-то другой уже мог залить этот файл и добавить запись. Выше мы рассматривали как раз такую ситуацию. У одного письма два получателя, и два loader’а стали его заливать. Когда второй закончит, он тоже пойдёт в FileDB.
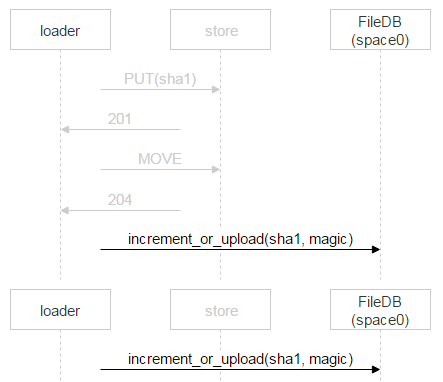
В этом случае второй loader просто инкрементирует счётчик.
Теперь перейдём к процедуре dec. Для нашей системы приоритетны две задачи — гарантированно записать файл на диск и быстро отдать его клиенту с диска. Физическое удаление файла генерирует нагрузку на диск и мешает первым двум задачам. Поэтому его мы переносим в офлайн. Сама процедура dec уменьшает счётчик. Если последний стал равен нулю, как и magic, то файл больше никому не нужен. Мы переносим запись о нём из space0 в space1 в тарантуле.
decrement (sha1, magic){ counter-- current_magic –= magic if (counter == 0 && current_magic == 0){ move(sha1, space1) } }
Valkyrie
На каждом сторедже у нас есть демон Valkirie, который следит за целостностью и консистентностью данных, как раз он и работает со space1. Один диск — один инстанс демона. Демон перебирает файлы на диске один за другим и проверяет, если ли запись о файле в space1, иными словами — надо ли его удалить.
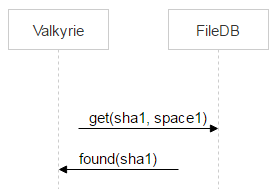
Но между переносом файла в space1 при выполнении операции dec() и обнаружением файла валькирией проходит время. Значит, между этими двумя событиями файл может быть залит ещё раз и опять оказаться в space0.
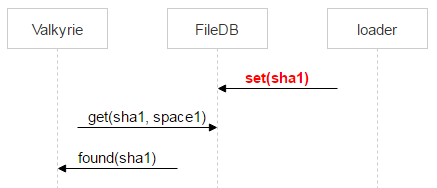
Поэтому Valkyrie сразу проверяет, не появился ли файл в space0. Если это случилось и pair_id записи указывает на пару дисков, с которой работает текущая валькирия, то удаляем запись из space1.
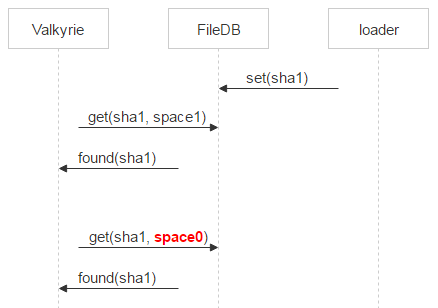
Если записи не оказалось, то файл — кандидат на удаление. Всё же между запросом в space0 и физическим удалением есть временной зазор. Стало быть, в этом зазоре опять же есть вероятность появления записи о файле в space0. Поэтому мы помещаем файл на карантин.

Вместо удаления файла переименовываем его, добавляя в имя deleted и timestamp. То есть физически мы удалим файл timestamp + какое-то время, указанное в конфиге. Если произошёл сбой и файл решили удалить по ошибке, то пользователь придёт за ним. Мы восстановим файл и исправим ошибку, не потеряв данные.
Теперь вспоминаем, что дисков два, на каждом работает своя Valkyrie. Валькирии никак не синхронизируются друг с другом. Возникает вопрос: когда удалять запись из space1?
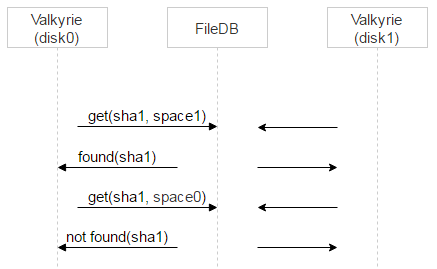
Делаем две вещи. Для начала назначаем для конкретного файла одну из Valkyrie мастером. Делается это очень просто: по первому биту из названия файла. Если он 0, то мастер — disk0, если 1, то мастер — disk1.

Теперь разнесём их по времени. Вспомним: когда запись о файле находится в space0, там есть поле magic для проверки консистентности. Когда мы переносим запись в space1, magic не нужен, поэтому запишем в него timestamp времени переноса в space1. Теперь Valkyrie master будет обрабатывать записи в space1 сразу, а slave будет добавлять к timestamp задержку и обрабатывать записи позже + удалять их из space1.
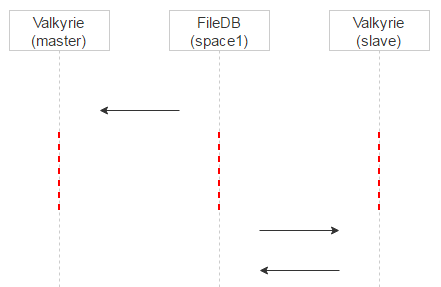
За счёт этого мы получаем ещё один плюс. Если на мастере файл ушёл в карантин по ошибке, то при запросе на мастер мы это увидим в логах и разберёмся. Клиент, который запрашивал файл, тем временем сфолбечится на slave, и пользователь получит файл.
Мы рассмотрели случай, когда Valkyrie находит на диске файл с именем sha1 и у этого файла (как кандидата на удаление) есть запись в space1. Давайте рассмотрим, какие ещё варианты возможны.
Пример. Файл есть на диске, но о нём нет записи в FileDB. Если в рассмотренном выше случае Valkyrie master по каким-то причинам некоторое время не работал, slave успел поместить файл на карантин и удалить запись из space1. В этом случае мы тоже ставим файл на карантин через sha1.deleted.ts.
Ещё пример. Запись есть, но указывает на другую пару. Это может случиться при заливке файла, если одно письмо пришло двум адресатам. Давайте вспомним схему.
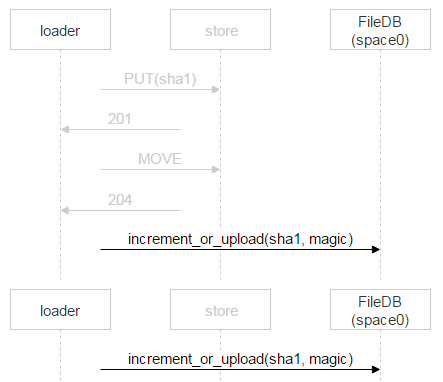
Что случится, если второй loader лил файл не на ту же пару дисков, что и первый? Он инкрементирует счётчик в space0, но на паре дисков, куда он лил, останутся мусорные файлы. Мы идём на эту пару и проверяем, что файлы читаются и совпадает sha1. Если всё ОК — то такие файлы можно сразу удалять.
Ещё Valkyrie может встретить файл на карантине. Если срок карантина истек, то файл удаляется.
Теперь Valkyrie натыкается на хороший файл. Его надо прочитать с диска и проверить на целостность, сравнить с sha1. Затем — сходить на другой диск из пары и выяснить, есть ли там файл. Для этого достаточно HEAD-запроса. Целостность файла проверит демон, запущенный на той машине. Если на текущей машине целостность файла нарушена, то он тут же загружается с другого диска. Если на том диске файл отсутствует, то заливаем его с текущего диска на второй.
Нам осталось рассмотреть последний кейс: проблемы с диском. После мониторинга админы понимают, что это случилось. Ставят диск в режим service (readonly) и на втором диске запускают процедуру размува. Все файлы со второго диска раскидываются по другим парам.
Результат
Вернёмся к началу. Наша почта выглядела так:

После переезда на новую схему мы сэкономили 18 Pb:

Почта стала занимать 32 Pb (25 % — индексы, 75 % — файлы). Освободившиеся 18Pb позволили нам долгое время не покупать новое железо.
ссылка на оригинал статьи https://habrahabr.ru/post/316740/
Добавить комментарий