Автор статьи – Роман Левченко (www.rlevchenko.com), MVP – Cloud and Datacenter Management
Всем привет!
Совсем недавно была объявлена глобальная доступность Windows Server 2016, означающая возможность уже сейчас начать использование новой версии продукта в Вашей инфраструктуре. Список нововведений довольно обширный и мы уже описывали часть из них (тут и тут), но в этой статье разберем службы высокой доступности, которые, на мой взгляд, являются самыми интересными и используемыми (особенно в средах виртуализации).

Cluster OS Rolling upgrade
Миграция кластера в прошлых версиях Windows Server является причиной значительного простоя из-за недоступности исходного кластера и создания нового на базе обновленной ОС на узлах с последующей миграцией ролей между кластерами. Такой процесс несет повышенные требования к квалификации персонала, определенные риски и неконтролируемые трудозатраты. Данный факт особенно касается CSP или других заказчиков, которые имеют ограничения по времени недоступности сервисов в рамках SLA. Не стоит описывать, что для поставщика ресурсов означает значительное нарушение SLA 🙂
Windows Server 2016 ситуацию исправляет через возможность совмещения Windows Server 2012 R2 и Windows Server 2016 на узлах в рамках одного кластера во время его апгрейда (Cluster OS Rolling Upgrade (далее CRU)).

Из названия можно догадаться, что процесс миграции кластера заключается в основном в поэтапной переустановке ОС на серверах, но об этом поговорим подробнее чуть позже.
Определим сначала список «плюшек», которые CRU предоставляет:
- Полное отсутствие простоя при апгрейде кластеров WS2012R2 Hyper-V/SOFS. Для других кластерных ролей (к примеру, SQL Server) возможна их недоступность (менее 5 минут), необходимая для отработки разового failover.
- Нет необходимости в дополнительном аппаратном обеспечении. Как правило, кластер строится из учета возможной недоступности одного или нескольких узлов. В случае с CRU, недоступность узлов будет планируемой и поэтапной. Таким образом, если кластер может безболезненно пережить временное отстутствие хотя бы 1 из узлов, то для достижения zero-downtime дополнительных узлов не требуется. Если планируется апгрейд сразу нескольких узлов (это поддерживается), то необходимо заранее спланировать распределение нагрузки между доступными узлами.
- Создание нового кластера не требуется. CRU использует текущий CNO.
- Процесс перехода обратим (до момента повышения уровня кластера).
- Поддержка In-Place Upgrade. Но, стоит отметить, что рекомендуемым вариантом обновления узлов кластера является полноценная установка WS2016 без сохранения данных (clean-os install). В случае с In-Place Upgrade обязательна проверка полной функциональности после обновления каждого из узлов (журналы событий и т.д.).
- CRU полностью поддерживается VMM 2016 и может быть автоматизирован дополнительно через PowerShell/WMI.
Процесс CRU на примере 2-х узлового кластера Hyper-V:
- Рекомендуется предварительное резервное копирование кластера (БД) и выполняемых ресурсов. Кластер должен быть в работоспособном состоянии, узлы доступны. При необходимости следует исправить имеющиеся проблемы перед миграцией и
приостановить задачи резервного копирования перед стартом перехода.
- Обновить узлы кластера Windows Server 2012 R2, используя Cluster Aware Updating (CAU) или вручную через WU/WSUS.
- При имеющемся настроенном CAU необходимо временное его отключение для предотвращения его возможного воздействия на размещение ролей и состояния узлов во время перехода.

- CPU на узлах должны иметь поддержку SLAT для поддержки выполнения виртуальных машин в рамках WS2016. Данное условие является обязательным.
- На одном из узлов выполняем перенос ролей (drain roles) и исключение из кластера (evict):

- После исключения узла из кластера выполняем рекомендуемую полную установку WS2016 (clean OS install, Custom: Install Windows only (advanced))

- После переустановки верните сетевые параметры обратно*, обновите узел и установите необходимые роли и компоненты. В моем случае требуется наличие роли Hyper-V и, конечно, Failover Clustering.
New-NetLbfoTeam -Name HV -TeamMembers tNIC1,tNIC2 -TeamingMode SwitchIndependent -LoadBalancingAlgorithm DynamicAdd-WindowsFeature Hyper-V, Failover-Clustering -IncludeManagementTools -RestartNew-VMSwitch -InterfaceAlias HV -Name VM -MinimumBandwidthMode Weight -AllowManagementOS 0* использование Switch Embedded Teaming возможно только после полного завершения перехода на WS2016.
- Добавьте узел в соответствующий домен.
Add-Computer -ComputerName HV01 -DomainName domain.com -DomainCredential domain\rlevchenko - Возвращаем узел в кластер. Кластер начнет работать в смешанном режиме поддержки функциональности WS2012R2 без поддержки новых возможностей WS2016. Рекомендуется завершить обновление оставшихся узлов в течение 4 недель.

- Перемещаем кластерные роли обратно на узел HV01 для перераспределения нагрузки.
- Повторяем шаги (4-9) для оставшейся ноды (HV02).
- После обновления узлов до WS2016 необходимо поднять функциональный уровень (Mixed Mode – 8.0, Full – 9.0) кластера для завершения миграции.
PS C:\Windows\system32> Update-ClusterFunctionalLevel
Updating the functional level for cluster hvcl.
Warning: You cannot undo this operation. Do you want to continue?
[Y] Yes [A] Yes to All [N] No [L] No to All [S] Suspend [?] Help (default is Y): aName
— Hvcl - (опционально и с осторожностью) Обновление версии конфигурации ВМ для включения новых возможностей Hyper-V. Требуется выключение ВМ и желателен предварительный бекап. Версия ВМ в 2012R2 – 5.0, в 2016 RTM – 8.0.В примере показана команда для обновления всех ВМ в кластере:
Get-ClusterGroup|? {$_.GroupType -EQ "VirtualMachine"}|Get-VM|Update-VMVersionПеречень версий ВМ, поддерживаемые 2016 RTM:

Cloud Witness
В любой кластерной конфигурации необходимо учитывать особенности размещения Witness для обеспечения дополнительного голоса и общего кворума. Witness в 2012 R2 может строиться на базе общего внешнего файлового ресурса или диска, доступных каждому из узлов кластера. Напомню, что необходимость конфигурации Witness рекомендована при любом количестве узлов, начиная с 2012 R2 (динамический кворум).
В Windows Server 2016 для обеспечения возможности построения DR на базе Windows Server и для других сценариев доступна новая модель кворумной конфигурации на базе Cloud Witness.
Cloud Witness использует ресурсы Microsoft Azure (Azure Blob Storage, через HTTPS, порты на узлах должны быть доступны) для чтения/записи служебной информации, которая изменяется при смене статуса кластерных узлов. Наименование blob-файла производится в соответствии с уникальным идентификатором кластера, — поэтому один Storage Account можно предоставлять нескольким кластерам сразу (1 blob-файл на кластер в рамках создаваемого автоматически контейнера msft-cloud-witness). Требования к размеру облачного хранилища минимальны для обеспечения работы witness и не требует больших затрат на его поддержку. Так же размещение в Azure избавляет от необходимости третьего сайта при конфигурации Stretched Cluster и решения по его аварийному восстановлению.

Cloud Witness может применяться в следующих сценариях:
- Для обеспечения DR кластера, размещенного в разных сайтах (multi-site).
- Кластеры без общего хранилища (Exchange DAG, SQL Always-On и другие).
- Гостевые кластеры, выполняющиеся как в Azure, так и в on-premises.
- Кластеры хранения данных с или без общего хранилища (SOFS).
- Кластеры в рамках рабочей группы или разных доменах (новая функциональность WS2016).
Процесс создания и добавления Cloud Witness достаточно прост:
- Создайте новый Azure Storage Account (Locally-redundant storage) и в свойствах аккаунта скопируйте один из ключей доступа.

- Запустите мастер настройки кворумной конфигурации и выберите Select the Quorum Witness – Configure a Cloud Witness.

- Введите имя созданного storage account и вставьте ключ доступа.

- После успешного завершения мастера конфигурации, Witness появится в Core Resources.

- Blob-файл в контейнере:

Для упрощения можно использовать PowerShell:

Workgroup and Multi-Domain Clusters
В Windows Server 2012 R2 и предыдущих версиях необходимо соблюдение глобального требования перед созданием кластера: узлы должны быть членами одного и того же домена. Active Directory Detached кластер, презентованный в 2012 R2, имеет подобное требование и не упрощает его существенным образом.
В Windows Server 2016 возможно создание кластера без привязки к AD в рамках рабочей группы или между узлами, являющиеся членами разных доменов. Процесс схож с созданием deattached -кластера в 2012 R2, но имеет некоторые особенности:
- Поддерживается только в рамках среды WS2016.
- Требуется роль Failover Clustering.
Install-WindowsFeature Failover-Clustering -IncludeManagementTools - На каждом из узлов требуется создать пользователя с членством в группе Administrators или использовать built-in уч. запись. Пароль и наименование пользователя должны быть идентичны.

net localgroup administrators cluadm /addПри появлении ошибки “Requested Registry access is not allowed” необходимо изменить значение политики LocalAccountTokenFilterPolicy.
New-ItemProperty -Path HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System -Name LocalAccountTokenFilterPolicy -Value 1 - Primary DNS -suffix на узлах должен быть определен.

- Создание кластера поддерживается как через PowerShell, так и через GUI.
New-Cluster -Name WGCL -Node rtm-1,rtm-2 -AdministrativeAccessPoint DNS -StaticAddress 10.0.0.100 - В качестве Witness возможно использование только Disk Witness или описанный ранее Cloud Witness. File Share Witness, к сожалению, не поддерживается.
Поддерживаемые сценарии использования:
| Роль | Статус поддержки | Комментарий |
|---|---|---|
| SQL Server | Поддерживается | Рекомендуется использовать встроенную аутентификацию SQL Server |
| File Server | Поддерживается, но не рекомендуется | Отсутствие Kerberos аутентификации, являющейся основной для SMB |
| Hyper-V | Поддерживается, но не рекомендуется | Доступна только Quick Migration. Live Migration не поддерживается |
| Message Queuing (MSMQ) | Не поддерживается | MSMQ требуется ADDS |
Virtual Machine Load Balancing / Node Fairness
Динамическая оптимизация, доступная в VMM, частично перекочевала в Windows Server 2016 и предоставляет базовое распределение нагрузки на узлах в автоматическом режиме. Для перемещения ресурсов используется Live Migration и эвристики, на базе которых кластер каждые 30 минут решает проводить балансировку или нет:
- Текущий % использования памяти на узле.
- Средняя загрузка по CPU в 5 минутном интервале.
Предельные допустимые значения загрузки определяются значением AutoBalancerLevel:
get-cluster| fl *autobalancer* AutoBalancerMode : 2 AutoBalancerLevel : 1
| AutoBalancerLevel | Агрессивность балансировки | Комментарий |
|---|---|---|
| 1 (по умолчанию) | Low | Осуществлять балансировку при загрузке узла более 80% по одной из эвристик |
| 2 | Medium | При загрузке более 70% |
| 3 | High | При загрузке более 60% |
Параметры балансировщика можно определить и в GUI (cluadmin.msc). По умолчанию, используется Low уровень агрессивности и режим постоянной балансировки.

Для проверки я использую следующие параметры:
AutoBalancerLevel: 2
(Get-Cluster).AutoBalancerLevel = 2AutoBalancerMode: 2
(Get-Cluster).AutoBalancerMode = 2Имитируем нагрузку сначала по CPU (около 88%) и затем по RAM (77%). Т.к. определен средний уровень агрессивности при принятии решения о балансировке и наши значения по загрузке выше определенного значения (70%) виртуальные машины на загруженном узле должны переехать на свободный узел. Скрипт ожидает момент живой миграции и выводит затраченное время (от точки начала загрузки на узла до осуществления миграции ВМ).
В случае с большой нагрузкой по CPU балансировщик переместил более 1 ВМ, при нагрузке RAM – 1 ВМ была перемещена в рамках обозначенного 30 минутного интервала, в течение которого происходит проверка загрузки узлов и перенос ВМ на другие узлы для достижения <=70% использования ресурсов.

При использовании VMM встроенная балансировка на узлах автоматически отключается и заменяется на более рекомендуемый механизм балансировки на базе Dynamic Optimization, который позволяет расширенно настроить режим и интервал выполнения оптимизации.
Virtual machine start ordering
Изменение логики старта ВМ в рамках кластера в 2012 R2 строится на понятии приоритетов (low,medium,high), задача которых обеспечивать включение и доступность более важных ВМ перед запуском остальных «зависимых» ВМ. Обычно это требуется для multi-tier сервисов, построенных, к примеру, на базе Active Directory, SQL Server, IIS.
Для повышения функциональности и эффективности в Windows Server 2016 добавлена возможность определять зависимости между ВМ или группами ВМ для решения обеспечения корректного их старта, используя Set или наборы кластерных групп. Преимущественно нацелены на использование совместно с ВМ, но могут быть использованы и для других кластерных ролей.

Для примера используем следующий сценарий:
1 ВМ Clu-VM02 является приложением, зависимым от доступности Active Directory, выполняемой на вирт. машине Clu-VM01. А ВМ Clu-VM03, в свою очередь, зависит от доступности приложения, расположенного на ВМ Clu-VM02.
Создадим новый set, используя PowerShell:

ВМ с Active Directory:
PS C:\> New-ClusterGroupSet -Name AD -Group Clu-VM01
Name: AD
GroupNames: {Clu-VM01}
ProviderNames: {}
StartupDelayTrigger: Delay
StartupCount: 4294967295
IsGlobal: False
StartupDelay: 20
Приложение:
New-ClusterGroupSet -Name Application -Group Clu-VM02
Зависимый сервис от приложения:
New-ClusterGroupSet -Name SubApp -Group Clu-VM03
Добавляем зависимости между set’ами:
Add-ClusterGroupSetDependency -Name Application -Provider AD
Add-ClusterGroupSetDependency -Name SubApp -Provider Application
В случае необходимости можно изменить параметры set’а, используя Set-ClusterGroupSet. Пример:
Set-ClusterGroupSet Application -StartupDelayTrigger Delay -StartupDelay 30StartupDelayTrigger определяет действие, которое необходимо произвести после старта группы:
- Delay – ожидать 20 секунд (по умолчанию). Используется совместно с StartupDelay.
- Online – ожидать состояния доступности группы в set.
StartupDelay – время задержки в секундах. 20 секунд по умолчанию.
isGlobal – определяет необходимость запуска set’а перед стартом других наборов кластерных групп (к примеру, set с группами ВМ Active Directory должен быть глобально доступен и, следовательно, стартовать раньше других коллекций).
Попробуем стартовать ВМ Clu-VM03:
Происходит ожидание доступности Active Directory на Clu-VM01 (StartupDelayTrigger – Delay, StartupDelay – 20 секунд)

После запуска Active Directory происходит запуск зависимого приложения на Clu-VM02 (StartupDelay применяется и на этом этапе).

И последним шагом является запуск самой ВМ Clu-VM03.

VM Compute/Storage Resiliency
В Windows Server 2016 появились новые режимы работы узлов и ВМ для повышения степени их устойчивости в сценариях проблемного взаимодействия между кластерными узлами и для предотвращения полной недоступности ресурсов за счет реакции на «малые» проблемы перед возникновением более глобальных (проактивное действие).
Режим изоляции (Isolated)
На узле HV01 внезапно стала недоступна служба кластеризации, т.е. у узла появляются проблемы интра-кластерного взаимодействия. При таком сценарии узел помещается в состояние Isolated (ResiliencyLevel) и временно исключается из кластера.

Виртуальные машины на изолированном узле продолжают выполняться* и переходят в статус Unmonitored (т.е. служба кластера не «заботится» о данных ВМ).

*При выполнении ВМ на SMB: статус Online и корректное выполнение (SMB не требует «кластерного удостоверения» для доступа). В случае с блочным типом хранилища ВМ уходят статус Paused Critical из-за недоступности Cluster Shared Volumes для изолированного узла.
Если узел в течение ResiliencyDefaultPeriod (по умолчанию 240 секунд) не вернет службу кластеризации в строй (в нашем случае), то он переместит узел в статус Down.
Режим карантина (Quarantined)
Предположим, что узел HV01 успешно вернул в рабочее состояние службу кластеризации, вышел из Isolated режим, но в течение часа ситуация повторилась 3 или более раза (QuarantineThreshold). При таком сценарии WSFC поместит узел в режим карантина (Quarantined) на дефолтные 2 часа (QuarantineDuration) и переместит ВМ данного узла на заведомо «здоровый».


При уверенности, что источник проблем был ликвидирован, можем ввести узел обратно в кластер:

Важно отметить, что в карантине одновременно могут находиться не более 25% узлов кластера.
Для кастомизации используйте вышеупомянутые параметры и cmdlet Get-Cluster:
(Get-Cluster). QuarantineDuration = 1800Storage Resiliency
В предыдущих версиях Windows Server отработка недоступности r/w операций для вирт. диска (потеря соединения с хранилищем) примитивная – ВМ выключаются и требуется cold boot на последующем старте. В Windows Server 2016 при возникновении подобных проблем ВМ переходит в статус Paused-Critical (AutomaticCriticalErrorAction), предварительно «заморозив» своё рабочее состояние (её недоступность сохранится, но неожиданного выключения не будет).
При восстановлении подключения в течение таймаута (AutomaticCriticalErrorActionTimeout, 30 минут по умолчанию), ВМ выходит из paused-critical и становится доступной с той «точки», когда проблема была идентифицирована (аналогия – pause/play).
Если таймаут будет достигнут раньше возвращения хранилища в строй, то произойдет выключение ВМ (действие turn off)

Site-Aware/Stretched Clusters и Storage Replica
Тема, заслуживающая отдельного поста, но постараемся кратко познакомиться уже сейчас.
Ранее нам советовали сторонние решения (много $) для создания полноценных распределенных кластеров (обеспечение SAN-to-SAN репликации). С появлением Windows Server 2016 сократить бюджет в разы и повысить унификацию при построении подобных систем становится действительностью.
Storage Replica позволяет осуществлять синхронную (!) и асинхронную репликацию между любыми системами хранения (включая Storage Spaces Direct) и поддерживающая любые рабочие нагрузки, — лежит основе multi-site кластеров или полноценного DR -решения. SR доступна только в редакции Datacenter и может применяться в следующих сценариях:
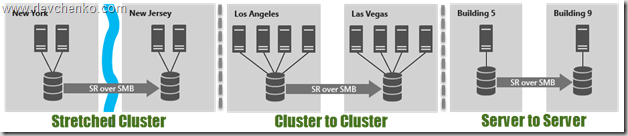
Использование SR в рамках распределенного кластера особенно ещё наличием автоматической отработки по отказу и тесной работы с site-awareness, который был презентован так же в Windows Server 2016. Site-Awarieness позволяет определять группы узлов кластера и привязывать их к физическому месторасположению (site fault domain/сайт) для формирования кастомных политик отказа (failover), размещения данных Storage Spaces Direct и логики распределения VM. Кроме того, возможна привязка не только на уровне сайтов, но и на более низкие уровни (node, rack, chassis).

New-ClusterFaultDomain –Name Voronezh –Type Site –Description “Primary” –Location “Voronezh DC” New-ClusterFaultDomain –Name Voronezh2 –Type Site –Description “Secondary” –Location “Voronezh DC2” New-ClusterFaultDomain -Name Rack1 -Type Rack New-ClusterFaultDomain -Name Rack2 -Type Rack New-ClusterFaultDomain -Name HPc7000 -type Chassis New-ClusterFaultDomain -Name HPc3000 -type Chassis Set-ClusterFaultDomain –Name HV01 –Parent Rack1 Set-ClusterFaultDomain –Name HV02 –Parent Rack2 Set-ClusterFaultDomain Rack1,HPc7000 -parent Voronezh Set-ClusterFaultDomain Rack2,HPc3000 -parent Voronezh2 

Такой подход в рамках мульти-сайт кластера несет следующие плюсы:
- Отработка Failover первоначально происходит между узлами в рамках Fault домена. Если все узлы в Fault Domain недоступны, то только тогда переезд на другой.
- Draining Roles (миграция ролей при режиме обслуживания и т.д.) проверяет возможность переезда сначала на узел в рамках локального сайта и только потом перемещает их на иной.
- Балансировка CSV (перераспределение кластерных дисков между узлами) так же будет стремиться отрабатывать в рамках родного fault-домена/сайта.
- ВМ будут стараться располагаться в том же сайте, где и их зависимые CSV. Если CSV мигрируют на другой сайт, то ВМ через 1 минуту начнут свою миграцию на тот же сайт.
Дополнительно, используя логику site-awareness, возможно определение «родительского» сайта для всех вновь создаваемых ВМ/ролей:
(Get-Cluster).PreferredSite = <наименование сайта>Или настроить более гранулярно для каждой кластерной группы:
(Get-ClusterGroup -Name ИмяВМ).PreferredSite = <имя предпочтительного сайта>
Другие нововведения
- Поддержка Storage Spaces Direct и Storage QoS.
- Изменение размера shared vhdx для гостевых кластеров без простоя, поддержка Hyper-V репликации и рез. копирования на уровне хоста.
- Улучшенная производительность и масштабирование CSV Cache с поддержкой tiered spaces, storage spaces direct и дедупликации (отдать десятки ГбБ RAM под кеш – без проблем).
- Изменения в формировании журналов кластера (информация о временном поясе и т.д.) + active memory dump (новая альтернатива для full memory dump) для упрощения диагностирования проблем.
- Кластер теперь может использовать несколько интерфейсов в рамках одной и той же подсети. Конфигурировать разные подсети на адаптерах не требуется для их идентификации кластером. Добавление происходит автоматически.
На этом наш обзорный тур по новым функциям WSFC в рамках Windows Server 2016 завершен. Надеюсь, что материал получился полезным. Спасибо за чтение и комментарии.
Отличного всем дня!
ссылка на оригинал статьи https://habrahabr.ru/post/316928/
Добавить комментарий