
Мы наконец допинали функционал мониторинга elasticsearch до публичного релиза. Суммарно мы переделывали его три раза, так как результат нас не устраивал и не показывал проблемы, которые мы огребали на нашем кластере ES.
Под катом история про наш production кластер, наши проблемы и наш новый мониторинг ES.
Супер краткий курс по эластику
Elasticsearch — это распределенный само-масштабирующийся RESTful сервис полнотекстового поиска, построенный на базе библиотеки Apache Lucene.
Терминология ES:
- Нода (node) — процесс JVM, запущенный на каком-то сервере
- Индекс (index) — набор документов, по которому вы хотите искать, в индексе может быть несколько типов документов
- Шард (shard) — чаcть индекса. Индексы делятся на части, чтобы распределить индекс и запросы к нему между серверами
- Реплика (replica) — копия шарда. Каждый кусок индекса хранится в нескольких копиях на разных серверах для отказоусточивости.
Внутри каждый шард — это индекс, но уже в Lucene’овских терминах, и он делится на сегменты.
Как мы используем ES
У всех метрик в okmeter.io есть метки, проще говоря, идентификатором метрики в нашей системе является словарь ключ-значение, например:
{name: net.interface.bytes.in, site: okmeter, source_hostname: es103, plugin: net, interface: eth1}{name: process.cpu.user, site: okmeter, source_hostname: es103, plugin: process_info, process: /usr/bin/java, username: elasticsearch, container: ~host}{name: elasticsearch.shards.count, site: okmeter, source_hostname: es103, plugin: elasticsearch, cluster: okmeter-ovh, index: monthly-metadata-2016-10, shard_state: active, shard_type: primary}
Каждый такой словарь-идентификатор метрики — это документ в ES. Например, чтобы построить такой график
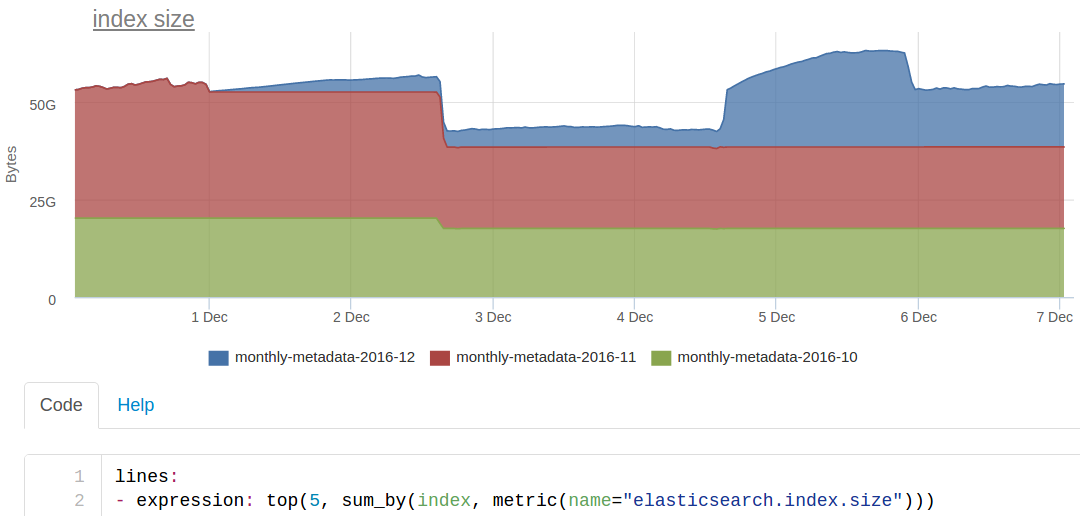
мы ищем в ES по такому (очень упрощенно) запросу
site:okmeter AND name:elasticsearch.index.size
он возвращает сколько-то id метрик, по которым мы достаем значения метрик из кассандры.
Статус кластера
Сам ES считает, что кластер может находиться в трех состояниях:
- зеленый — доступно требуемое количество копий каждого шарда каждого индекса
- желтый — какие-то копии шарда либо находятся в состоянии миграции, либо не прикреплены к нодам
- красный — часть индекса недоступна вообще
Основной график нашего стандартного дашборда по ES мы выбирали исходя из этих же состояний:
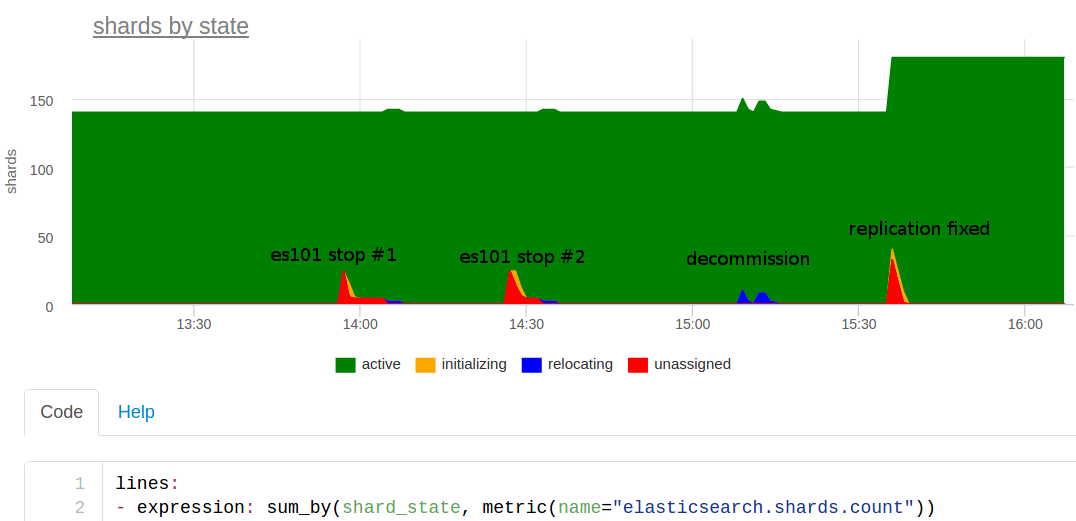
Расскажу про этот день. Накануне мы добавили более мощные серверы в кластер, а теперь нужно было убрать две старые ноды. Приблизительно в 14:00 мне пришла в голову идея, а не провести ли учения? Обсудили и решили, что можно поэкспериментировать — выключить одну ноду и посмотреть, как такой эластичный эластик это отработает.
Выключили и тут же заорал мониторинг, что на коллекторе метрик проблемы. Why??
Вернули ноду, подождали немного, всё наладилось. Странно, ну не может же быть такого, чтобы из-за выключения одного из нескольких эластиков мы прилегли. Наверное что-то другое…
Выключили ноду опять где-то в 14:30 — опять алерты. Хмммм. Учения показали, что падение одного эластика делает нам больно — тоже результат, но нужно разбираться.
Сделали своего рода decommission — аккуратно вывели ноды по одной из кластера. Синее на графике в 15:10 — это оно, шарды перемещались на другие ноды. Обошлось без проблем.
Присмотрелись к количеству шардов: 140 — странно, number_of_shards у нас 20, number_of_replicas — 2, и еще одна мастер копия, т.е. должно быть 60 шардов на индекс. Индексов 3 — свой на каждый месяц, значит должно быть всего 180 шардов. Оказалось, что декабрьский индекс создался с number_of_replicas — 0, т.е. без реплик, поэтому выключение любой ноды полностью ломает работу с этим индексом!
Хорошо, что отсутствие реплик обнаружилось в контролируемом эксперименте. Если бы мы это не заметили, могли огрести большие проблемы в будущем — пришлось бы аврально делать полную переиндексацию по данным из основного хранилища.
Чтобы увидеть эту проблему в будущем мы сделали автоматический триггер, который сообщит, если в каком-то индексе 0 реплик. Этот триггер выпустили в виде авто-триггера для всех клиентов сразу, мы же сервис мониторинга 🙂
Split brain
Самая пугающая и известная проблема с эластиком — это split brain, когда из-за проблем со связностью нод по сети, или если нода не отвечала долго (потому что застряла в GC например), в кластере может появиться вторая мастер-нода.
В этом случае получается как бы две версии индекса, какие-то документы попадают на индексацию в одну часть кластера, другие — в другую. Неконсистентность будет проявляться при поиске — на один и тот же запрос будут выдаваться разные результаты. Восстановление индекса в таком случае будет сложной задачей, скорее всего потребуется либо полная переиндексация, либо восстановление из бэкапа и с последующей доливкой изменений до текущего момента.
В ES есть механизм защиты от сплит-брейна, самая важная настройка — minimum_master_nodes, но по-умолчанию discovery.zen.minimum_master_nodes: 1, т.е. никакой защиты нет.
Мы воспроизводили это на тестовом кластере ElasticSearch и по результатам сделали два авто-триггера: один сработает, если увидит более одной мастер ноды в кластере, второй предупредит, если значение параметра discovery.zen.minimum_master_nodes меньше, чем рекомендованное — кворум (N/2+1) от текущего размера кластера. Это нужно именно мониторить, потому что вы можете решить добавить нод и забыть подправить minimum_master_nodes.
Мониторинг запросов в elastic
C состоянием кластера вроде разобрались, дальше нужно понимать, сколько каких запросов обрабатывает кластер и как быстро они отрабатывают.
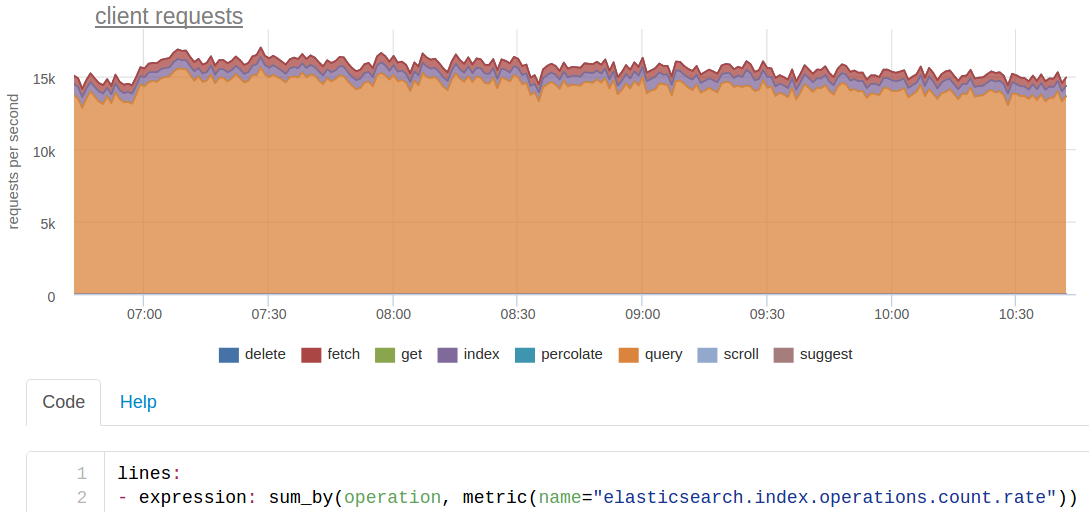
Любой поиск по нашему ES мы делаем сразу по трем индексам, каждый из которых поделен на 20 шардов. Из-за этого изначальные ~250 запросов в секунду на поиск от нашего кода для ES превращаются в ~15 тысяч.
Запросов на идексацию на самом деле у нас около 200 в секунду, но так как каждый шард хранится в трех копиях (основная + 2 реплики), то ES видит ~600 rps.
По временам запросов ES дает достаточно скудную статистику: есть счетчик обработанных запросов и есть кумулятивная сумма времен запросов по типам. Таким образом мы можем посчитать только среднее время ответа по каждому типу запросов, получаем график такого вида (мы вычисляем среднее прямо при отрисовке графика, так как сумма времен ответов тоже интересная метрика сама по себе):
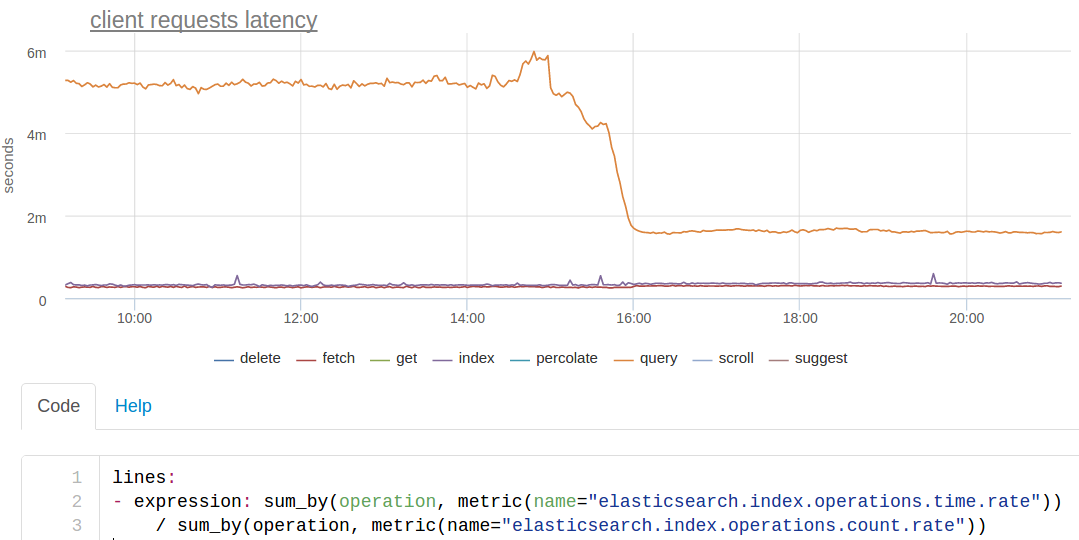
Оранжевая линия — это поиск. Видно, что в какой-то момент он ускорился приблизительно в 3 раза.
Это мы всего лишь сделали force merge сегментов. У нас индекс порезан помесячно. Индексируется всегда (почти) в текущий месяц, ищется по трём. Так как из индексов за предыдущие месяцы идет только чтение, мы можем сделать на них force merge сегментов прямо под нагрузкой:
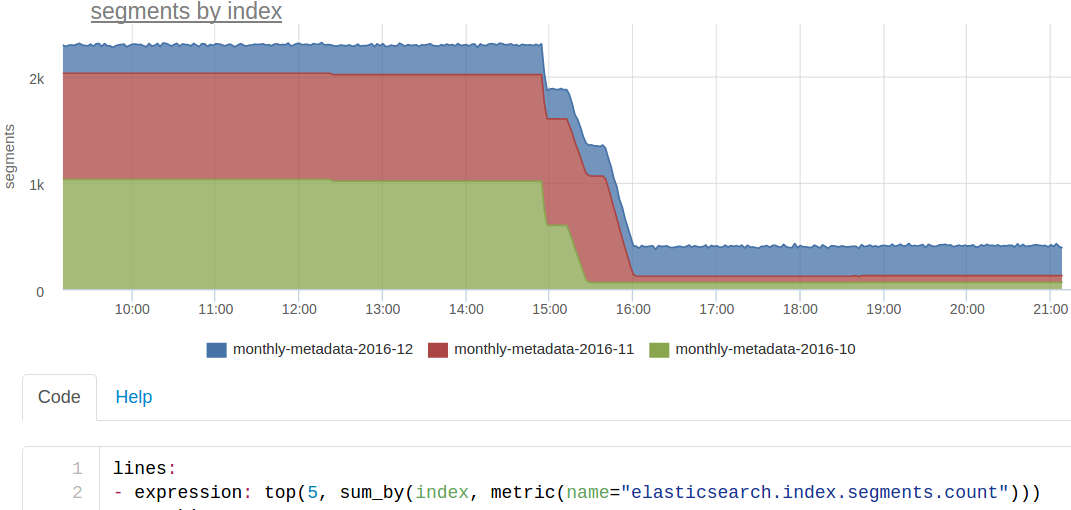
В итоге осталось по одному сегменту в каждом шарде, поиск по этим индексам стал заметно быстрее. Возможно нам стоит сделать крон, который будет делать force merge индекса за прошедший месяц.
Background ops графики
Кроме того мы отдельно вывели "background" операции — это то, что эластик делает в фоне сам или по запросу как с force merge. Отдельно, потому что логичнее видеть "пользовательские" запросы отдельно от "системных": у них и совсем разные тайминги — секунды вместо милисекунд, поэтому на одном графике будет не удобно смотреть. И количество таких операций бывает очень маленьким и может теряться на фоне всех пользовательских реквестов.
Этот график показывает тот самый merge, который снизил нам время ответа поиска, но в этот раз удобнее смотреть на сумму времен ответа ES (мы как бы смотрим, на что в целом тратились вычислительные ресурсы кластера):
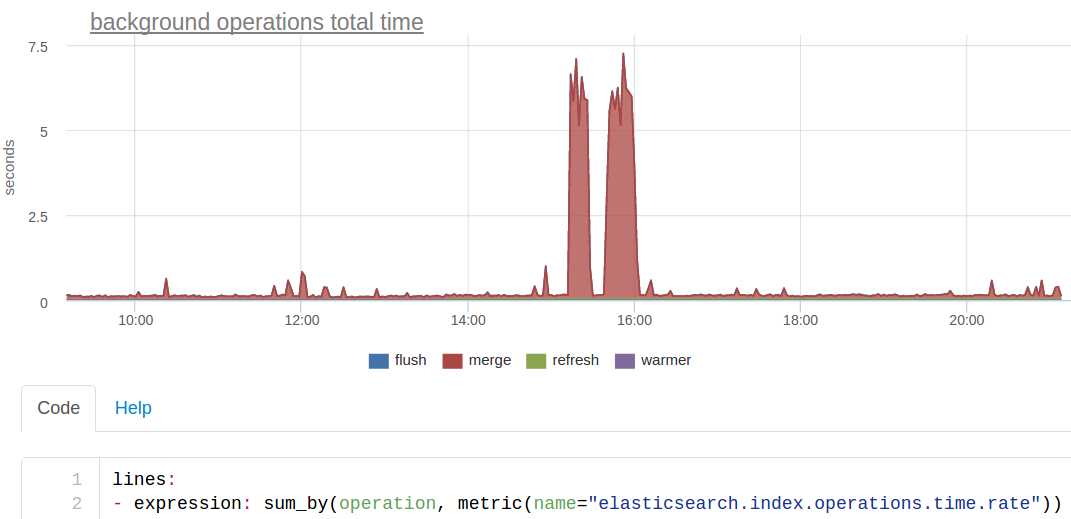
С точки зрения системных метрик линукса, этот merge выглядел как активная запись на диск процессом ES:

Кэши
Для обеспечения скорости выполнения запросов в эластике есть кэши:
- query_cache (раньше назывался filter_cache) — битсеты документов, которые матчатся на конкретный фильтр в запросе
- fielddata_cache — используется при аггрегациях
- request_cache — шард кэширует ответ на запрос целиком
Подробнее что кешируется, когда кешируется, когда инвалидируется, как тюнить, лучше читать в документации.
Наш мониторинговый агент снимет для каждого из этих кэшей: размер, хиты, миссы, эвикшены (вытестения).
Вот, например, был случай — эластики у нас упали по OutOfMemory. По логам разобраться сложно, но потом, когда уже подняли, заметили на графике резкий рост использования памяти fielddata кэшем:

Вообще-то мы не используем агрегации elasticsearch, мы вообще используем только самый базовый функционал. Нам нужно без скоринга найти все документы, в которых у заданных полей заданные значения. Почему же так выросло использование fielddata кэша?
Оказалось, что это был тоже контролируемый эксперимент 🙂 Вручную curl’ом дёргали тяжелые запросы на агрегацию, и от этого всё попадало. По идее от этого можно было защититься правильной настройкой лимитов памяти для fielddata. Но или они не сработали, или баги эластика (мы тогда сидели на старой версии 1.7).
Системные метрики
В дополнении к внутренним метрикам эластика, стоит смотреть на него сверху, как на процесс в операционной системе. Сколько он потребляет процессорного времени, сколько памяти, сколько создает нагрузки на диск.
Когда мы затевали обновление ES с версии 1.7.5, то решили обновиться сразу на 2.4 (последнюю, пятёрку, пока побаиваемся). Мажорное обновление elastic по стандартной процедуре нам делать как-то стрёмно, мы обычно поднимаем второй кластер и делаем синхронную копию через наш код — он умеет индексировать в несколько кластеров сразу.
При включении нового кластера в индексацию, обнаружилось, что новый ES пишет на диск ~350 раз в секунду, в то время как старый всего ~25:
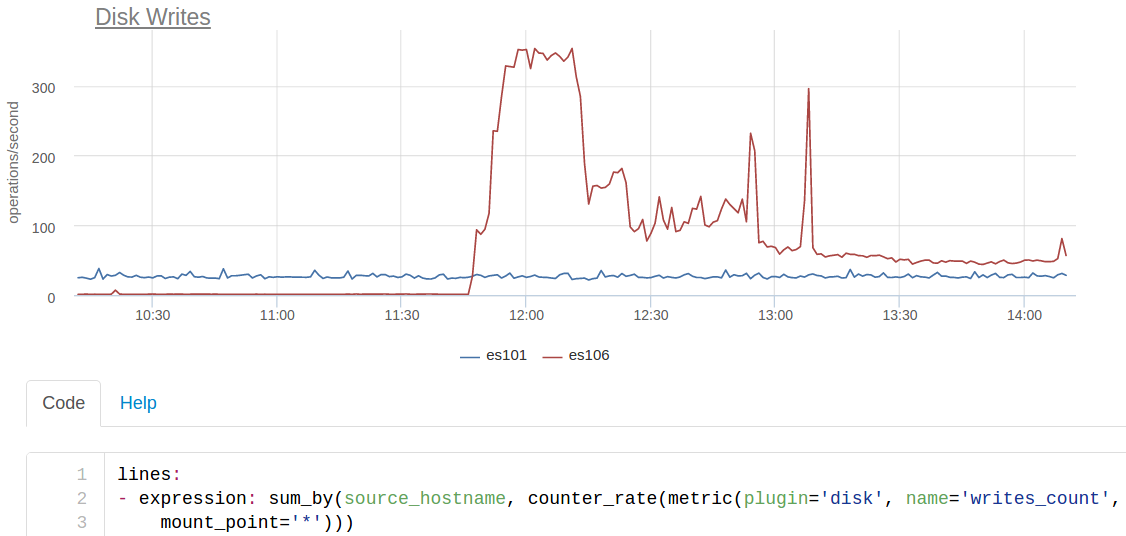
es101 — это нода из старого кластера, а es106 — из нового. Плюс на новые ноды не стали ставить SSD (посчитали, что всё влезет в память), поэтому такое io уронило производительность очень сильно.
Пошли перечитывать все новинки версии 2 эластика и нашли index.translog.durability. Он по умолчанию стал request, при таком значении translog синкается на диск после каждого запроса на индексацию. Поменяли на async со стандартныйм sync_interval в 5 секунд и стало почти как раньше.
Помимо системных метрик для ES полезно смотреть за метриками JVM — gc, memory пулы и прочее. Наш агент автоматически подцепит всё это через jmx и также автоматически появятся графики.
Автоматическое обнаружение ES
Не так давно мы уже рассказывали, что очень много сил тратим на то, чтобы все сервисы на серверах наших клиентов включались в мониторинг автоматом, без настройки. Такой подход позволяет ничего не забыть замониторить и сильно ускоряет внедрение.
Автодетект для ES устроен примерно так:
- по списку процессов находим процесс похожий на ES: jvm с классом запуска org.elasticsearch.bootstrap
- по строке запуска пытаемся найти конфиг ES
- читаем конфиг, понимаем listen IP и порт
Дальше дело техники — периодически снимаем метрики по стандартному API и отправляем их в облако.
Вместо заключения
Мы всегда стараемся исходить из реальных use case’ов. Чтобы запилить мониторинг какого-то сервиса, нам приходится досконально с ним разбираться, понимать что и как там может сломаться. По этому в первую очередь мы делали поддержку тех сервисов, которые хорошо умеем готовить и которыми пользуемся сами.
Кроме того очень помогают клиенты, которые рассказывают про свои проблемы. Мы постоянно дорабатываем дашборды/автотриггеры, чтобы в итоге показывать не какие-то графики, а сразу причины проблем.
Если у вас есть ES, который ждет, чтобы его замониторили, наш бесплатный 2х недельный триал — то, что вам нужно:)
ссылка на оригинал статьи https://habrahabr.ru/post/315860/
Добавить комментарий