Популярный украинский сервис такси Uklon регулярно устраивает розыгрыши среди своих водителей и клиентов. По результатам каждого розыгрыша они публикуют на свою facebook страницу видео с контактными данными участников: имя и адрес электронной почты (пример). Фрагмент кадра:
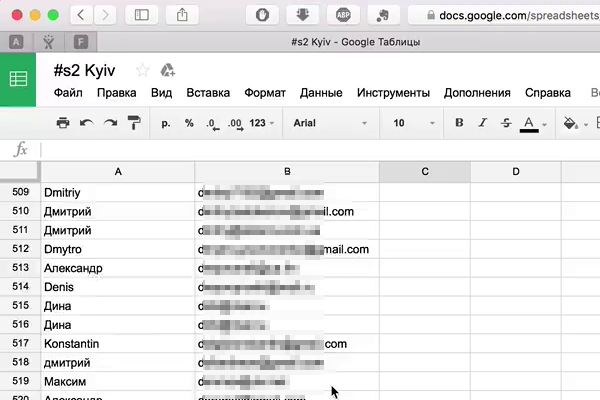
В оригинальном видео адреса не размыты, их для статьи размыл я, чтобы не распространять эти данные дальше. На мое письмо в их поддержку, что это не очень хорошая идея:
Добрый день!
Нельзя в видео (ссылка) выкладывать адреса и имена людей.
1. Во-первых, ваши конкуренты могут получить список ваших клиентов и водителей
2. Во-вторых, вы нарушаете закон Украины про доступ к персональным данным
Они ответили, что им все равно:
Здравствуйте, Денис, при регистрации каждый пользователь дает согласие на использование его персональных данных uklon.com.ua/document/useragreement — пункт 2.6. Большое спасибо за ваш отзыв.
Поэтому я решил написать небольшой пост, как можно получить контактные данные с видео, не используя какие-то специальные умения. Дисклаймер: этот пост носит образовательный характер, и демонстрирует как не стоит обращаться с данными клиентов.
1. Скачиваем видео
Есть много сервисов для скачивания видео с facebook. Я воспользовался http://www.fbdown.net/, он дает прямую ссылку на видео. Все последующие примеры будут на Убунте, но должны аналогично работать и в других ОС.
2. Разбиваем на кадры
В исходном видео список контактов показан в первых 17 секундах видео. С помощью ffmpeg мы сохраняем первые 17 секунд видео, как последовательность png изображений:
$ ffmpeg -i video.mp4 -t 00:00:17 out%d.png 3. Подготавливаем к OCR

Для распознавания мы будем использовать свободный OCR tesseract. Который довольно неплохо работает, но чувствителен к качеству исходных изображений.
Обрежем все лишнее используя ImageMagick
с кадров (начиная с координат 40, 202 и размеров 345×421).
convert '*.png[345x421+40+202]' thumbnail%03d.pngДолжно получиться как на картинке справа, без размытия конечно же.
Tesseract плохо определяет небольшие буквы, поэтому в его мануале рекомендуют просто увеличить скриншоты в 2-3 раза:
convert thumbnail*.png -filter Lanczos -resize 300% final%d.png4. Распознавание
Приходимся по всем файлам и распознаем. Ключом -psm 4 мы указываем, что хотим чтобы tesseract воспринимал текст как одну колонку. А ключом load_system_dawg=0, что не надо использовать словари при распознавании:
for i in final*.png; do tesseract $i stdout -psm 4 -l eng+rus -c load_system_dawg=0; done > text.txt Удаляем дубликаты — и наша база готова:
sort -u text.txt > uniq.txt Выводы
В результате работы в базе довольно много ошибок. И есть два варианта улучшения:
- использовать коммерческие OCR;
- настроить шаблоны для tesseract, чтобы он знал, что мы распознаем адреса электронной почты.
В любом случае цель статьи было показать не качество распознавания, а принципиальную возможность сделать это быстро и с минимальными ресурсами.
ссылка на оригинал статьи https://habrahabr.ru/post/317242/
Добавить комментарий