Неважно, отдаем ли мы себе в этом отчет, но когда нужно подождать, мы волнуемся и сгораем от нетерпения. Особенно это касается ожидания «вслепую», т.е. когда неизвестно, сколько же еще придется мучиться. Как выяснил Брэд Аллан Майерс, считающийся изобретателем индикатора состояния в 1980-х, возможность отслеживать ход выполнения во время ожидания может значительно улучшить механизм взаимодействия пользователя с приложением (Майерс, 1985).

Типичный индикатор состояния от Simeon87 [GPL (http://www.gnu.org/licenses/gpl.html)], Wikimedia Commons
Поскольку я программирую на R для исследований в биоинформатике, мой код обычно не для широкой публики, но все же важно, чтобы мои пользователи, то бишь коллеги и исследователи, были счастливы, насколько это возможно. Но отслеживание хода выполнения в R — не самая простая задача. В этой статье представлены несколько возможных решений, в том числе и мое собственное (pbmcapply).
Вывод на экран
Самый легкий способ отслеживать ход выполнения в R — периодически выводить процент завершенной на данный момент работы: по умолчанию — на экран, или писать его в какой-то файл с логами где-то на диске. Нет смысла говорить, что это, вероятно, наименее элегантный способ решения, но многие все равно его используют.
Pbapply
Лучшее (и по-прежнему простое) решение — подключить пакет pbapply. Если верить информации на его странице, пакет очень популярен — 90 тыс. скачиваний. Его легко использовать. Каждый раз, когда собираетесь вызвать apply, вызовите ее pbapply-версию. Например:
# Некоторые числа, с которыми мы будем работать nums <- 1:10 # Вызовем sapply, чтобы посчитать квадратный корень этих чисел sqrt <- sapply(nums, sqrt) # Теперь посмотрим на ход выполнения с пакетом pbapply sqrt <- pbsapply(nums, sqrt)Пока числа обрабатываются, будет выводиться периодически обновляющийся индикатор состояния.

Индикатор состояния, сгенерированный pbapply. Пользователь может увидеть, сколько примерно еще нужно времени, и текущее состояние в виде индикатора.
Хотя pbapply — прекрасный инструмент, и я часто его использую, с ним не удалось отобразить ход выполнения для параллельной версии apply — mcapply — до недавнего времени. В сентябре автор pbapply добавил в свой пакет поддержку кластеров в простой сети (snow-type — Simple Network Of Workstations — простая сеть рабочих станций) и многоядерного разветвления. Но этот подход предполагает разделение элементов на части и последовательное применение к ним mcapply. Один из недостатков этого подхода состоит в том, что если количество элементов сильно превышает количество ядер, нужно вызвать mcapply много раз. Вызовы mcapply, построенные на основе функции fork() в Unix/Linux, очень дороги: разветвление в множество дочерних процессов занимает время и слишком много памяти.
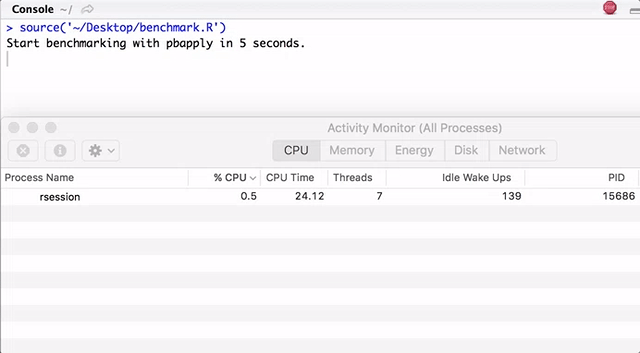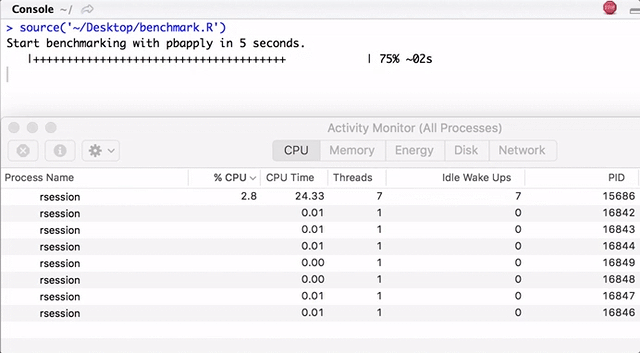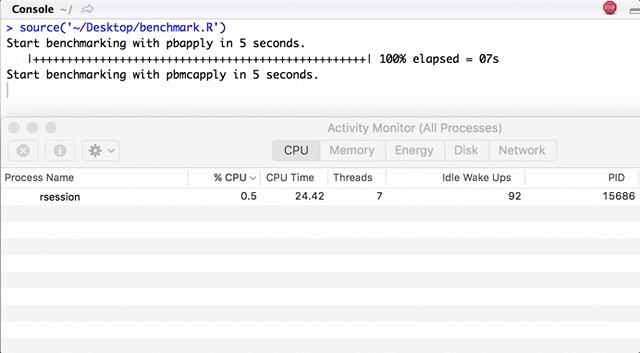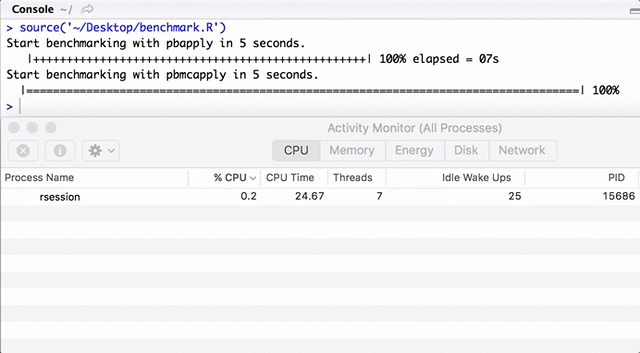
Обратите внимание, pbapply генерирует много дочерних процессов, а pbmcapply переиспользует их там, где это возможно. Для pbapply/pbmcapply выделено 4 ядра. Код на R можно загрузить отсюда.
Pbmcapply
Pbmcapply — мое собственное решение проблемы. Оно доступно через пакет CRAN, и его легко использовать:
# Установить pbmcapply install.packages("pbmcapply")Как понятно из названия, я вдохновился пакетом pbapply. В отличие от pbapply, мое решение не предполагает много вызовов mcapply. Вместо этого pbmcapply использует пакет future.

Схема pbmcapply. FutureCall() выполняется в отдельном процессе, который потом разветвляется в заданное количество дочерних. Дочерние процессы периодически передают информацию о своем ходе через progressMonitor. Как только progressMonitor получает данные, он выводит состояние на стандартное устройство вывода.
В компьютерных науках future обозначает объект, который позже будет содержать значение. Это позволяет программе выполнять какой-то код как future и, не дожидаясь вывода, переходить к следующему шагу. В pbmcapply mcapply можно поместить во future. Future будет периодически предоставлять информацию о своем состоянии основной программе, которая, в свою очередь, будет отображать индикатор состояния.
Поскольку в pbmcapply затраты ресурсов минимальны и нелинейны, получим значительное улучшение производительности, когда количество элементов сильно превышает количество ядер процессора. В качестве иллюстрации используются одно- и многопоточные apply-функции в R. Очевидно, что даже с pbmcapply, производительность страдает, поскольку для запуска процесса мониторинга требуется время.

Сравнение производительности pbapply и pbmcapply. Код на R можно загрузить отсюда. Левая панель показывает затраты ресурсов при вызове каждого из пакетов. Правая панель показывает время на каждый вызов.
Все имеет свою цену. Наслаждаясь удобством интерактивного отслеживания состояния, помните, это немного замедляет программу.
Заключение
Как и всегда, универсального решения нет. Если ваш основной приоритет — производительность (например, при запуске программы в кластере), возможно, наилучший способ отслеживания хода выполнения — print. Однако, если лишние пару секунд ничего не решают, пожалуйста, воспользуйтесь моим решением (pbmcapply) или pbapply, чтобы сделать вашу программу более удобной.
Ссылки
Myers, B. A. (1985). The importance of percent-done progress indicators for computer-human interfaces. In ACM SIGCHI Bulletin (Vol. 16, №4, pp. 11–17). ACM.
ссылка на оригинал статьи https://habrahabr.ru/post/317314/
Добавить комментарий