Это перевод обзора статьи «MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing» Fan et al. в Proceedings of the 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI’13), pdf тут
Чуваки (бывший гугловец, чувак из университета Карнеги Меллон и еще один из Интел лабс) сделали улучшенный Memcached-совместимый кеш (по факту просто допилили мемкеш), и у них классные результаты производительности. Мне очень понравился обзор этой статьи в блоге "The morning paper" — описание алгоритмов и прочее.
Курсивом — мои комментарии как переводчика.
В основе MemC3 другой, чем в обычном мемкеше, алгоритм хэширования — оптимистичное "кукушечное" хеширование (cuckoo), и дополнительно к этому особый "CLOCK" алгоритм вытеснения. Соединенные вместе, они дают до 30% более эффективное использование памяти и увеличение производительности в запросах в секунду до 3 раз по сравнению с вашим обычным Memcached (при нагрузках с преобладающим чтением небольших объектов, что типично для мемкешей в Facebook).
В конце оригинальной статьи есть отличный разбор полученных результатов с точки зрения вклада примененных оптимизаций. Это выглядят это примерно так:

Полная пропускная способность (по сети) в зависимости от числа тредов
В этом разборе мы просто заценим алгоритмы, а детали их вкрячивания в мемкеш и методики перформанс тестирования, пожалуйста, читайте в оригинальной статье.
Кукушечное хэширование
Сначала разберемся с обычным кукушечным хешированием. Как работает самая обычная хэш-таблица? Вы хэшируете ключ и по этому хэшу выбираете ячейку таблицы (bucket или ведро:), в которую нужно вставить или в которой можно найти соответствующее ключу значение. Куку-хэширование использует две хэш-функции, получается, две возможные ячейки для вставки или поиска значения.
Рассмотрим следующую таблицу, в которой каждая строка представляет собой ячейку, в каждой из которых четыре слота для данных. Слот — это указатель на сами данные, объект пару ключ-значение.
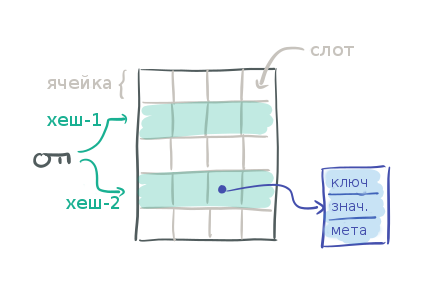
Имея ключ для поиска, мы считаем для него два хеша и получаем две возможные ячейки. То есть нужно проверить 2 ячейки × 4 слота = 8 слотов, чтобы найти или не найти нужный ключ.
То есть при поиске в такой хеш-таблице нужно много операций по сравнению с "обычной" хеш-таблицей.
Кукушечное хэширование получило свое название из-за того, как обрабатывается операция вставки. Сперва мы хэшируем ключ X, который собираемся вставлять, используя обе хэш-функции, и получаем две возможные ячейки. Если какая-либо из этих ячеек имеет пустой слот, то сохраняем Х туда. Если же все слоты заняты, значит, пришло время какому-то ключу подвинуться. Случайно выбираем один слот в одной из этих двух ячеек и перемещаем (или "переселяем") из него ключ (назовем его Y), таким образом освобождая место для записи X. Теперь хэшируем уже Y двумя хеш-функциями и находим вторую ячейку, где он мог бы находиться, и пытаемся вставить Y туда. Если все слоты этой ячейки тоже заполнены, то перемещаем какой-то ключ уже из этих слотов, чтобы освободить место для Y, и продолжаем делать так, пока пустой слот не найден (или пока не достигнем некоторого максимального количества перемещений, например, 500).
Тут алгоритм ведет себя похоже на кукушку — вытаскивает чужой ключ из уже использованного места и кладет туда свой, отсюда и название.
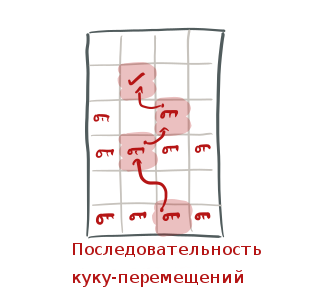
Если так и не получается найти свободный слот, то значит, эту хэш-таблицу пора расширять — увеличивать выделенную под нее память.
Хотя такой алгоритм для вставки, кажется, может потребовать выполнения целой последовательности, цепочки перемещений, оценка временной сложности операции вставки для куку-хэширования — O(1).
Цитата из оригинальной работы
Использование тегов для улучшения операций поиска
Из вышесказанного понятно, что происходит много выборок по ключу и много сравнений, и все это не слишком хорошо с точки зрения локальности данных. (Видимо, автор имеет в виду, что, поскольку ни ключи, ни даже хеши ключей не хранятся непосредственно в слотах ячеек таблицы, а хранятся в отдельно выделенных структурах ключ-значение, то происходит много рандомных обращений по памяти и полных сравнений ключей, что не позволяет хорошо работать процессорным кешам) Первое, что мы сделали для оптимизации куку-хэширования — ввели теги. Тег — это 1-байтовое хэш-значение ключа, и мы будем хранить его прямо в слоте хэш-таблицы рядом с указателем на ключ. Такие теги позволяют очень быстро (всего-то сравнив один байт) понять, может ли сохраненный ключ совпадать с искомым или нет, без необходимости извлекать его по указателю и целиком сравнивать.
Могут происходить лишние извлечения для двух разных ключей, имеющих один и тот же тег, поэтому ключ всё равно надо извлекать и сравнивать полностью, чтобы убедиться, что он совпадает с искомым. С однобайтовыми тегами частота коллизий будет всего 1/2^8 = 0,39%. В случае проверки всех 8 слотов-кадидатов (например, при поиске отсутствующего ключа — miss’е), будет происходить в среднем 8 × 0,39% = 0,03 разыменований указателей. Поскольку каждая ячейка помещается в один блок процессорного кеша процессора (обычно 64 байт), в среднем каждый поиск обернется только в считывание двух блоков для проверки двух ячеек плюс либо 0.03 разыменований указателей в случае поиска отсутствующего ключа — miss’е, либо 1,03 в случае успешного поиска — hit’е.
Цитата из оригинальной работы
Использование тегов для улучшения операции вставки
При определении двух возможных ячеек для ключа вместо использования двух хеш-функций, мы будем использовать только один хэш, а также дополнительный тег: пусть ячейка_1 = хэш(X), и у нас есть тег(X), то ячейка_2 = ячейка_1 ⊕ тег(X). Эта конструкция имеет следующее полезное свойство — можно определить ячейку_1, зная тег и ячейку_2. То есть при операциях перемещения ключа нам становится неважно, в какой ячейке лежал ключ, мы можем вычислить альтернативную ячейку без обращения к полному ключу.
Поддержка параллельности доступа
Наша схема хеширования, насколько нам известно, является первой реализацией с поддержкой параллельного доступа (multi-reader, single writer), обладающей высокой эффективностью использования памяти (даже при > 90% заполненности таблицы).
Цитата из оригинальной работы
Чтобы добавить параллелизма в такой алгоритм, нужно решить две проблемы:
- избежать дед-локов при получении лока на ячейки для записи, ведь мы не можем знать наперед, какие ячейки будут затронуты нашей операцией
- избежать ложных кэш-миссов, когда в процессе перемещения какой-то ключ уже был убран из одной ячейки, но еще не вставлен в новую, а в этот момент произошло считывание.
Конечно, строго говоря, авторы не решили первую проблему, они просто забили на нее, так как позволяют одновременно выполняться лишь одной операции записи. В реальных условиях в профиле нагрузки часто доминирует чтение, так что это разумный компромисс.
Кеш-миссов (ложно отрицательных срабатываний) можно избежать, если сначала определить полную цепочку куку-перемещений, но еще ничего не перемещая, а затем выполнить эти перемещения в обратном порядке — от последнего пустого слота до желаемой исходной вставки. В сочетании с тем, что операции записи идут в один поток, получается, что каждый отдельный обмен гарантированно не вызывает каких-либо дополнительных перемещений и может быть выполнен без необходимости наперед блокировать всю цепочку.
Самая прямолинейная реализация — брать блокировку на каждую из двух ячеек, участвующих в обмене (осторожно с порядком), и разблокировать их после обмена. Тут нужно два лока/релиза на каждый обмен.
Мы пытались оптимизировать производительность для наиболее распространенного использования и воспользовались преимуществом наличия только одного треда записи, чтобы выстроить все insert’ы и lookup’ы в один поток последовательных операций с малым оверхедом. Вместо того, чтобы лочить ячейки, мы заводим на каждой ключ-счетчик версии. Увеличиваем счетчик при перемещении ключа при insert’е и следим за изменением версии во время lookup’а для детекта одновременно происходящего перемещения.
Цитата из оригинальной работы
Но где вы храните эти счетчики?? Если добавить их к каждому объекту ключ-значение, то будет использовано много памяти при сотнях миллионов ключей. Также появляется возможность для race-condition, поскольку эти объекты ключ-значение, хранятся за пределами самой хеш-таблицы и, таким образом, не защищены локами.
Решение состоит в том, чтобы использовать массив счетчиков фиксированного размера — значительно меньшего, чем количество ключей. Массив в 8192 счетчиков влезает в 32KB кэш, и каждый счетчик используется для нескольких ключей, за счет использования нашего старого знакомого — хэширования. Такой компромисс, использование таких шареных счетчиков, по-прежнему даёт хорошую степень параллелизации доступа, сохраняя при этом вероятность "лишней повторной попытки" (счетчик версии увеличился на единицу для какого-то другого ключа, который имеет хэш коллизию в таблице счетчиков версий) низкой, примерно — 0,01%.
Эти счетчики вписаны в общий алгоритм следующим образом:
- При необходимости перемещения какого-то ключа процесс вставки увеличивает счетчик версии этого ключа на единицу, чтобы обозначить происходящий процесс перемещения. После того, как ключ перемещен, счетчик увеличивается на единицу снова. Отсчет начинается с нуля, поэтому нечетные значения счетчика соответствуют заблокированным ключам, а четное — разблокированным.
- Процесс поиска, который видит нечетное значение у счетчика, ждет и затем делает повторную попытку. Если же счетчик был четный, то нужно запомнить это значение, считать обе ячейки, а затем сравнить значение счетчика с запомненным. Если значение счетчика изменилось, то нужно повторить операцию заново.
Дополнительная хитрость для оптимизации куку-хеширования заключается в параллельном поиске нескольких возможных путей вставки. Это увеличивает шансы быстрее найти пустой слот. По тестам вышло, что оптимально проверять параллельно два возможных пути.
Вытеснение по "ЧАСАМ"
До сих пор мы говорили о вставках и поисках. И хотя оптимизированное куку-хэширование так же весьма эффективно использует память, все равно можно ожидать, что в какой-то момент наш кэш заполнится до предела (или почти до предела), и тогда нужно будет беспокоиться о вытеснении.
В обычном Memcached используется политика вытеснения наиболее давно используемых ключей— LRU, но она требует по 18 байт на ключ (два указателя и 2-байтный счетчик ссылок), чтобы обеспечить безопасное вытеснение строго в порядке LRU. Это также привносит значительные накладные расходы на синхронизацию.
В противоположность этому, MemC3 использует всего 1 бит на ключ с возможностью параллелизации операций. Это достигается за счет отказа от строгого LRU в пользу приблизительного LRU основанного на CLOCK алгоритме.
Поскольку в нашем целевом случае преобладают мелкие объекты, то использование памяти снижается при использовании приближенного к LRU вытеснения, что позволяет кэшу хранить значительно больше записей, что, в свою очередь, улучшает общий хит-рейт. Как будет показано в разделе 5, такое управление вытеснением дает увеличение пропускной способности от 3 до 10 раз по сравнению с обычным Memcached, и все это при лучшем хит-рейте.
Цитата из оригинальной работы
Представьте циклический буфер битов и виртуальную часовую стрелку, указывающую на конкретное место в буфере.
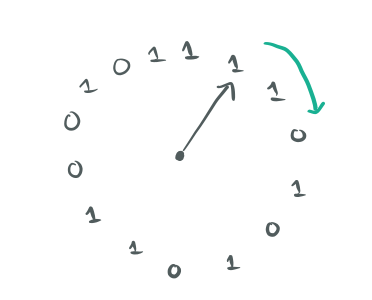
Каждый бит представляет "возраст" (давность использования) какого-то объекта пары ключ-значение. Бит равен ‘1’, если соответствующий ключ использовался недавно, и ‘0’ — в противном случае. Любая операция с ключом просто устанавливает соответствующий бит давности в ‘1’. При вытеснении нужно проверить тот бит, на который указывает стрелка часов. Если это ‘0’, то можно вытеснить соответствующий ключ из кеша. Если это ‘1’, то записываем туда ‘0’ и сдвигаем стрелку часов вперед, на следующий бит. Этот процесс повторяется до тех пор, пока не найден нулевой бит.
Процесс вытеснения интегрирован со схемой оптимистических блокировок следующим образом:
Когда процесс вытеснения выбирает ключ-жертву X по CLOCK алгоритму, то он сначала увеличивает счетчик версии ключа X, чтобы сообщить остальным тредам, которые в настоящее время читают X, что им нужно попробовать позже еще раз; затем он удаляет X, делая его недоступным для последующего чтения, в том числе для тех повторных попыток от других тредов; и, наконец, увеличивает счетчик версии ключа X снова, чтобы завершить цикл изменений. Обратите внимание, что все вытеснения и вставки сериализуются с помощью локов, так что при обновлении счетчиков они не влияют друг на друга.
Цитата из оригинальной работы
На этом всё. Надеюсь вам понравилось так же, как и мне.
Подписывайтесь на наш хабра-блог.
ссылка на оригинал статьи https://habrahabr.ru/post/316762/
Добавить комментарий