В данной статье я хочу показать насколько просто сегодня использовать нейронные сети. Вокруг меня довольно много людей одержимы идеей того, что нейронки может использовать только исследователь. И что бы получить хоть какой то выхлоп, нужно иметь как минимуму кандидатскую степень. А давайте на реальном примере посмотрим как оно на самом деле, взять и с нуля за один вечер обучить chatbot. Да еще не просто абы чем а самым что нинаесть ламповым TensorFlow. При этом я постарался описать все настолько просто, что-бы он был понятен даже начинающему программисту! В путь!

Шаги, которые на предстит пройти на нашем тернистом пути
- Необходимо найти реализацию нейроннйо сети, которую можно использовать для нашей цели.
- Подготовить данные (корпус), которые могут быть использованы для обучения.
- Обучить модель.
Отдельное спасибо моим патронам, которые сделали эту статью возможной:
Aleksandr Shepeliev, Sergei Ten, Alexey Polietaiev, Никита Пензин, Карнаухов Андрей, Matveev Evgeny, Anton Potemkin. Вы тоже можете стать одним из них вот тут.
Реализация нейронки, которую можно использовать для нашей цели
TensorFlow включает реализацию RNN (рекурентной нейронной сети), которая используется для обучения модели перевода для пары языков английский / французский. Именно эту реализацию мы и будем использовать для обучения нашего чат-бота.
Вероятно, кто-то может спросить: «Почему, черт возьми, мы смотрим на обучения модели перевода, если мы делаем чат-бот?». Но это может показаться странным только на первом этапе. Задумайтесь на секунду, что такое “перевод”? Перевод может быть представлен в виде процесса в два этапа:
- Создание языко-независимого представление входящего сообщения.
- Отображение информации полученной на первом шаге на язык перевода.
Теперь задумайтесь, а что, если мы будем обучать ту же модель RNN, но, вместо Eng/Fre пары мы будем подставлять Eng/Eng диалоги из фильмов? В теории, мы можем получить чат-бот, который способен отвечать на простые однострочные вопросы (без способности запоминать контекст диалога). Этого должно быть вполне достаточным для нашего первого бота. Плюс, этот подход очень прост. Ну а в будущем, мы сможем, отталкиваясь от нашей первой реализации, сделать чат-бот более разумным.
Позже мы узнаем, как обучать более сложные сети, которые являются более подходящими для чат-ботов (например retrieval-based models).
Для нетерпеливых: картинка в начале статьи это собственно пример разговора с ботом после всего 50 тысяч учебных итераций. Как видите, бот способен давать более или менее информативные ответы на некоторые вопросы. Качество бота улучшается с количеством итераций обучения. Например, вот как глупо он отвечал после первых 200 итераций:
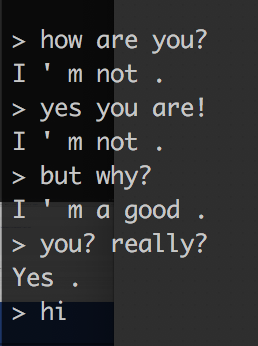
Такой простой подход также позволяет нам создавать ботов с разными характерами. Например, можно было бы обучить его на диалогах из саги “Звездные войны” или «Властелин колец». Более того, если бот имеет достаточно большой корпус диалога одного и того же героя (например, все диалоги Чендлера из фильма «Друзья»), то можно создать бота этого самого героя.
Подготовка данных (корпуса) для обучения
Для обучения нашего первого бота мы будем использовать корпус диалогов из кинофильмов “Cornell Movie Dialogs Corpus”. Для его использования нам нужно сконвертировать диалоги в нужный для обучения вид. Для этого я подготовил небольшой скрипт.
Я бы настоятельно рекомендовал вам прочитать README файл, чтобы понять больше о корпусе и о том, что этот скрипт делает, и только потом продолжить чтение статьи. Однако, если вам просто нужно команды, которые вы можете слепо скопировать и выполнить, чтобы получить готовые для обучения данные, вот они:
tmp# git clone https://github.com/b0noI/dialog_converter.git Cloning into ‘dialog_converter’… remote: Counting objects: 59, done. remote: Compressing objects: 100% (49/49), done. remote: Total 59 (delta 33), reused 20 (delta 9), pack-reused 0 Unpacking objects: 100% (59/59), done. Checking connectivity… done. tmp# cd dialog_converter dialog_converter git:(master)# python converter.py dialog_converter git:(master)# ls LICENSE README.md converter.py movie_lines.txt train.a train.bК концу выполнения вы будете иметь 2 файла, которые можно использовать для дальнейшего обучения: train.a и train.b
Обучение модели
Это самая захватывающая часть. Для того, чтобы обучить модель мы должны:
- Найти машину с мощной и поддерживаемой TensorFlow (что очень важно) видеокартой (читай: NVIDIA).
- Изменить оригинальный «translate» скрипт, который используется для обучения модели перевода пары Eng/Fre.
- Подготовить машину для обучения.
- Начать обучение.
- Подождать.
- Подождать.
- Подождать.
- Я серьезно … Нужно подождать.
- Profit.
В поисках Атлантиды машины для обучения
Для того, чтобы сделать этот процесс как можно более простым, я буду использовать собранный AMI — "Bitfusion Ubuntu 14 Scientific Computing", который будет использоваться с AWS. Он имеет предварительно установленный TensorFlow, который был собран с поддержкой GPU. К моменту написания статьи, Bitfusion AMI включал TensorFlow версии 0.11.
Процесс создания EC2 инстанса из AMI образа достаточно прост и его рассмотрение выходит за рамки этой статьи. Однако стоит обратить внимание на две важных детали, которые имеют отношение к процессу, это тип instance и размер SSD. Для типа я бы рекомендовал использовать: p2.xlarge — это самый дешевый тип, который имеет NVIDIA GPU с достаточным количеством видеопамяти (12 Гбит). Что касается размера SSD — я бы рекомендовал выделить по крайней мере 100GB.
Теперь нам нужно изменить оригинальный «translate» скрипт
На этом этапе, я надеюсь, я могу предположить, что у вас есть ssh доступ к машине, где вы будете обучать TensorFlow.
Во-первых, давайте обсудим, зачем вообще нам нужно изменять исходный скрипт. Дело в том, что сам скрипт не позволяет переопределить источник данных, которые используются для обучения модели. Чтобы это исправить я создал feature-request. И постараюсь скоро подготовить реализацию, но на данный момент, вы можете поучаствовать добавляя +1 к “реквесту”.
В любом случае, не надо бояться — модификация очень проста. Но даже столь малую модификацию я уже сделал за вас и создал репозиторий, содержащий модифицированный код. Остается только сделать следующее:
Переименуйте файлы «train.a» и «train.b» на «train.en» и «train.fr» соответственно. Это необходимо, так как учебный скрипт все еще считает, что он обучается на перевод с английского на французский.
Оба файла должны быть загружены на удаленные хосты — это можно сделать с помощью команды rsync:
➜ train# REMOTE_IP=... ➜ train# ls train.en train.fr ➜ train rsync -r . ubuntu@$REMOTE_IP:/home/ubuntu/trainТеперь давайте подключимся к удаленному хосту и запустим tmux сессию. Если вы не знаете, что такое tmux, вы можете просто подключиться через SSH:
➜ train ssh ubuntu@$REMOTE_IP 53 packages can be updated. 42 updates are security updates. ######################################################################################################################## ######################################################################################################################## ____ _ _ __ _ _ | __ )(_) |_ / _|_ _ ___(_) ___ _ __ (_) ___ | _ \| | __| |_| | | / __| |/ _ \| '_ \ | |/ _ \ | |_) | | |_| _| |_| \__ \ | (_) | | | |_| | (_) | |____/|_|\__|_| \__,_|___/_|\___/|_| |_(_)_|\___/ Welcome to Bitfusion Ubuntu 14 Tensorflow - Ubuntu 14.04 LTS (GNU/Linux 3.13.0-101-generic x86_64) This AMI is brought to you by Bitfusion.io http://www.bitfusion.io Please email all feedback and support requests to: support@bitfusion.io We would love to hear from you! Contact us with any feedback or a feature request at the email above. ######################################################################################################################## ######################################################################################################################## ######################################################################################################################## Please review the README located at /home/ubuntu/README for more details on how to use this AMI Last login: Sat Dec 10 16:39:26 2016 from 99-46-141-149.lightspeed.sntcca.sbcglobal.net ubuntu@tf:~$ cd train/ ubuntu@tf:~/train$ ls train.en train.frДавайте проверим, что TensorFlow установлен и он использует GPU:
ubuntu@tf:~/train$ python Python 2.7.6 (default, Jun 22 2015, 17:58:13) [GCC 4.8.2] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import tensorflow as tf I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcublas.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcudnn.so.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcufft.so.7.5 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcuda.so.1 locally I tensorflow/stream_executor/dso_loader.cc:111] successfully opened CUDA library libcurand.so.7.5 locally >>> print(tf.__version__) 0.11.0Как видно, установлен TF версии 0.11 и он использует библиотеку CUDA. Теперь давайте склоним учебный скрипт:
ubuntu@tf:~$ mkdir src/ ubuntu@tf:~$ cd src/ ubuntu@tf:~/src$ git clone https://github.com/b0noI/tensorflow.git Cloning into 'tensorflow'... remote: Counting objects: 117802, done. remote: Compressing objects: 100% (10/10), done. remote: Total 117802 (delta 0), reused 0 (delta 0), pack-reused 117792 Receiving objects: 100% (117802/117802), 83.51 MiB | 19.32 MiB/s, done. Resolving deltas: 100% (88565/88565), done. Checking connectivity... done. ubuntu@tf:~/src$ cd tensorflow/ ubuntu@tf:~/src/tensorflow$ git checkout -b r0.11 origin/r0.11 Branch r0.11 set up to track remote branch r0.11 from origin. Switched to a new branch 'r0.11'Обрати внимание, что нам нужна ветка r0.11.Прежде всего, эта ветка согласуется с версией локально установленного TensorFlow. Во-вторых, я не перенес мои изменения в другие ветки, поэтому, в случае необходимости, придется делать это руками вам самим.
Поздравляю! Вы дошли до этапа начала обучения. Смело запускайте это самое обучение:
ubuntu@tf:~/src/tensorflow$ cd tensorflow/models/rnn/translate/ ubuntu@tf:~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train ... Tokenizing data in /home/ubuntu/train/train.en tokenizing line 100000 ... global step 200 learning rate 0.5000 step-time 0.72 perplexity 31051.66 eval: bucket 0 perplexity 173.09 eval: bucket 1 perplexity 181.45 eval: bucket 2 perplexity 398.51 eval: bucket 3 perplexity 547.47Давайте обсудим некоторые ключи, которые мы используем:
- en_vocab_size — сколько уникальных слов изучит модель “английского языка”. Если число уникальных слов из исходных данных превышает размер словаря, все слова, которые не в словаре, будут помечены как «UNK» (code: 3). Но не рекомендую делать словарь больше, чем необходимо; но он не должен быть и меньше;
- fr_vocab_size — то же самое, но для другой части данных (для “французского языка”);
- data_dir — директория с исходными данными. Здесь скрипт будет искать файлы «train.en» и «train.fr»;
- train_dir — директория, в которую скрипт будет записывать промежуточный результат обучения.
Давайте убедимся в том, что обучение продолжается, и все идет по плану
Вы успешно начали обучение. Но давайте подтвердим, что процесс продолжается и все в порядке. Мы не хотим, чтобы в конечном итоге через 6 часов мы выяснили, что что-то в самом начале было сделано не так. Мы с Глебом уже как-то обучили нечто полуразумное =)
Прежде всего, мы можем подтвердить, что процесс обучения “откусил” себе памяти у GPU:
$ watch -n 0.5 nvidia-smi 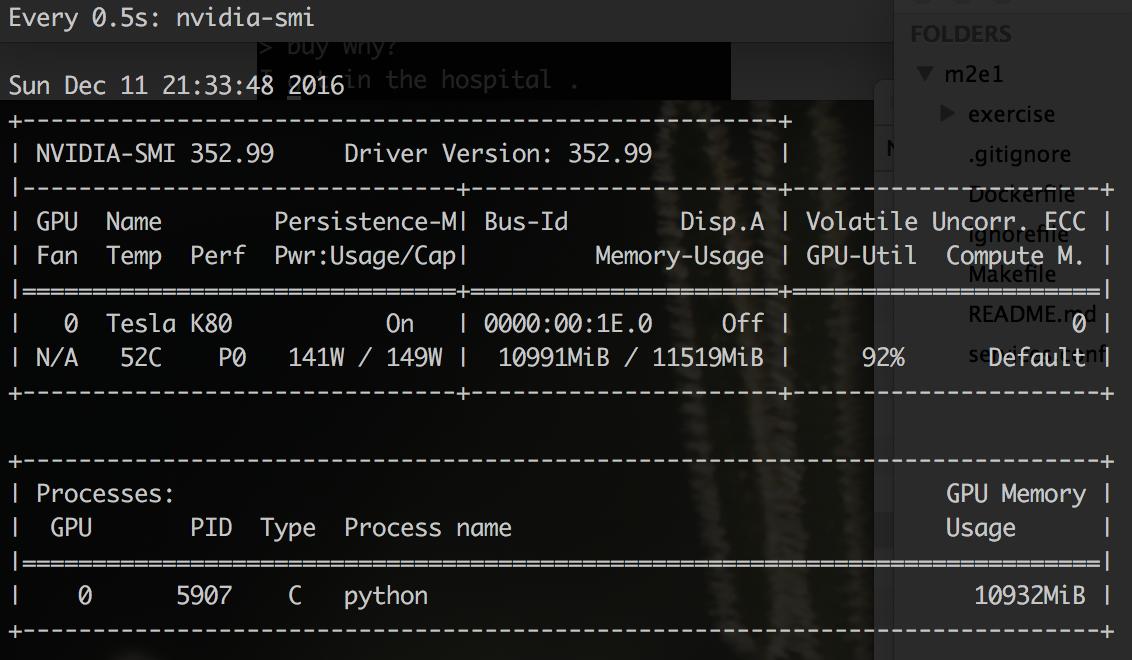
Как видно, не хило так кусанул, почти вся память на GPU занята. Это хороший знак. И не нужно бояться, что ваш процесс вот-вот “откинет копыта” с ошибкой OutOfMemory. Просто во время запуска TF прибирает к своим рукам всю память на GPU, до которой может дотянуться.
Затем можно проверить папку «train» — она должна содержать несколько новых файлов:
~$ cd train ~/train$ ls train.fr train.ids40000.fr dev.ids40000.en dev.ids40000.fr train.en train.ids40000.en vocab40000.frЗдесь важно заглянуть в файлы vocab4000.* и train.ids40000.*. Там должно быть атмосферно и душевно, вот посмотрите:
~/train$less vocab40000.en _PAD _GO _EOS _UNK . ' , I ? you the to s a t it of You ! that ... Каждая строка в файле — это уникальное слово, которое было найдено в исходных данных. Каждое слово в исходных данных будет заменено числом, которое представляет номер строки из этого файла. Можно сразу же заметить, что есть некоторые технические слова: PAD (0), GO (1), EOS (2), UNK (3). Наверное самое важное из них для нас — «UNK», так как количество слов помеченных этим кодом (3) даст нам некоторое представление о том, насколько корректно выбран нами размер нашего словаря.
Теперь давайте посмотрим на train.ids40000.en:
~/train$ less train.ids40000.en 1181 21483 4 4 4 1726 22480 4 7 251 9 5 61 88 7765 7151 8 7 5 27 11 125 10 24950 41 10 2206 4081 11 10 1663 84 7 4444 9 6 562 6 7 30 85 2435 11 2277 10289 4 275 107 475 155 223 12428 4 79 38 30 110 3799 16 13 767 3 7248 2055 6 142 62 4 1643 4 145 46 19218 19 40 999 35578 17507 11 132 21483 2235 21 4112 4 144 9 64 83 257 37 788 21 296 8 84 19 72 4 59 72 115 1521 315 66 22 4 16856 32 9963 348 4 68 5 12 77 1375 218 7831 4 275 11947 8 84 6 40 2135 46 5011 6 93 9 359 6370 6 139 31044 4 42 5 49 125 13 131 350 4 371 4 38279 6 11 22 316 4 3055 6 323 19212 6 562 21166 208 23 3 4 63 9666 14410 89 69 59 13262 69 4 59 155 3799 16 1527 4079 30 123 89 10 2706 16 10 2938 3 6 66 21386 4 116 8 ...Думаю вы уже догадались, что это данные из input.en, но со всеми словами замененными на коды согласно словарю. Теперь мы можем проверить, сколько же слов помечены как «неизвестные» (UNK/3):
~/train$ grep -o ' 3 ' train.ids40000.en | wc -l 7977Можете попробовать в последующих экспериментах увеличить размер словаря с 40k до 45k, или даже до 50к. Но, мы пока продолжим процесс “as is” и не станем его прерывать.
6 часов спустя… “Оно ожило!”
После ожидания достаточного количества времени, вы можете тупо убить процесс обучения. Не волнуйтесь, процесс сохраняет результат каждые 200 шагов обучения (это число можно менять). Я бы рекомендовал для обучения либо выбрать промежуток времени, который вы готовы ждать (он может зависеть от суммы, которую вы готовы платить за аренду машины), либо количество шагов, которое вы хотите, чтобы тренировочный процесс закончил.
Самое последнее и главное ради чего мы устроили этот весь беспредел — это начать чат. Для этого нам просто нужно добавить один ключ к команде, которая была использована для тренировки:
~/src/tensorflow/tensorflow/models/rnn/translate$ python ./translate.py --en_vocab_size=40000 --fr_vocab_size=40000 --data_dir=/home/ubuntu/train --train_dir=/home/ubuntu/train --decode ... Reading model parameters from /home/ubuntu/data/translate.ckpt-54400 > Hello! Hello . > Hi are you? Now , okay . > What is your name? My name is Sir Sir . > Really? Yeah . > what about the real name? N . . . real real . > are you a live? Yes . > where are you? I ' m here . > where is here? I don ' t know . > can I help you to get here? Yeah , to I ve ' t feeling nothing to me .
Это лишь начало! Вот пару идей для улучшения бота.
Чтобы помочь проекту или просто создать бота с характером можно:
- реализовать логику, которая находит идеальный размер для EN/FR словарей;
- опубликовать train.en/train.fr где-то, чтобы другие люди не создавали их с нуля;
- обучить бота мастера Yoda (или Дарта Вейдера);
- обучить бота, который будет говорить, как во вселенной из “Властелина колец”;
- обучить бота, который будет говорить, как люди из “StarWars” вселенной;
- обучить бота на своих диалогах, чтобы он разговаривал как вы!
ссылка на оригинал статьи https://habrahabr.ru/post/317732/
Добавить комментарий