Всем добрый день, с вами снова Роман Поборчий в блоге JUG.ru, и сегодня мы разбираем доклад Руслана cheremin Черёмина про escape-анализ и скаляризацию:
Слайды можно посмотреть и скачать тут. Традиционный disclaimer: про Java только разбираемый в статье доклад, а не сама статья.
Сюжет
Здесь у меня большая часть впечатлений — позитивные, всё, что, как мне кажется, в докладе обязательно должно быть, в нём есть. Предлагаемые изменения носят в основном косметический характер.
Постановка задачи
Не знаю, как вас, а меня Руслан вполне убедил, что полезно разобраться, как в Java работает escape-анализ. Если писать код с учётом этого знания, будет меньше объектов в куче, меньше gc и вообще мир будет лучше. Ответ на вопрос «зачем» есть.
Тем не менее, шуточная картинка, которая появляется на 03:37, слегка затмевает статистику. После первого просмотра я запомнил только этот график и как раз хотел посетовать, что нет никаких цифр о том, сколько можно выгадать «в среднем случае». При втором просмотре оказалось, что цифры (~15% аллокаций, которые можно устранить) упоминаются. Если бы удалось найти и показать похожий «нормальный» случай, это бы лучше отложилось в памяти. Конечно, такие данные из своей практики найти на заказ не всегда просто, нет так нет.
Выводы
Выводы и рекомендации в докладе естественно следуют из логики рассказа, практически полезны и конкретны. Мы не просто понимаем, что надо делать «хорошо» (например, писать маленькие методы) и почему именно это надо делать. Мы ещё и выяснили, что у этого «хорошо» почти всегда можно узнать точную количественную меру и даже можно при необходимости её переопределить! Чего ещё желать для счастья?
Разве что можно было бы зрителей предостеречь: что-нибудь обязательно сломается, если мы станем часто и бездумно переопределять дефолты компилятора, но это потребует примеров и времени и размоет фокус.
Упущение
Чего мне здесь не хватает, так это описания методики экспериментов: в первый раз результаты запусков появляются на слайде 16 (время 13:38), и там сразу фигурируют 12 run’ов, ограниченных не числом вызовов, а временем. Почему именно так? В этом есть какой-то смысл, или так исторически сложилось? Почему в одних случаях время 5 секунд (слайды 16, 17, 19 и несколько других), в других 3 (слайды 68, 73 и несколько других), а ещё в других и вовсе не указано (слайды 89, 90, 91)?
Я уверен, что тут методику достаточно объяснить один раз, просто чтобы убрать возможное недоверие, и во всех последующих упоминаниях станут не нужны повторяющиеся детали, подробнее об этом в секции про слайды.
На сцене висит ружьё
Ружьё повесил не сам докладчик, удружил кто-то из зрителей выкриком с места, но, так или иначе, речь дважды зашла о Φ-функциях (в частности, полминуты начиная с 16:40). Компилятор — одна из тех вещей, для понимания которых нужны фундаментальные знания, но у нашей аудитории эти знания есть не всегда. Раз уж случился контакт двух-трёх понимающих, то стоило попробовать в общих чертах донести до всех, о чём же речь, чтобы они не чувствовали себя обделёнными.
Я задумался, нельзя ли было на пальцах, раз подготовленных заранее слайдов нет, за минуту рассказать, что это за Φ-функции такие и какое примерно отношение они имеют к теме рассказа. Ориентируюсь на себя, то есть на уровень человека, двадцать лет назад сдавшего спецкурс по компиляторам и с тех пор работавшего с ними только как пользователь. В момент просмотра доклада я, конечно, не помнил, что это. Итак, смотрим на слайд 23 и пытаемся объяснить, что там происходит:
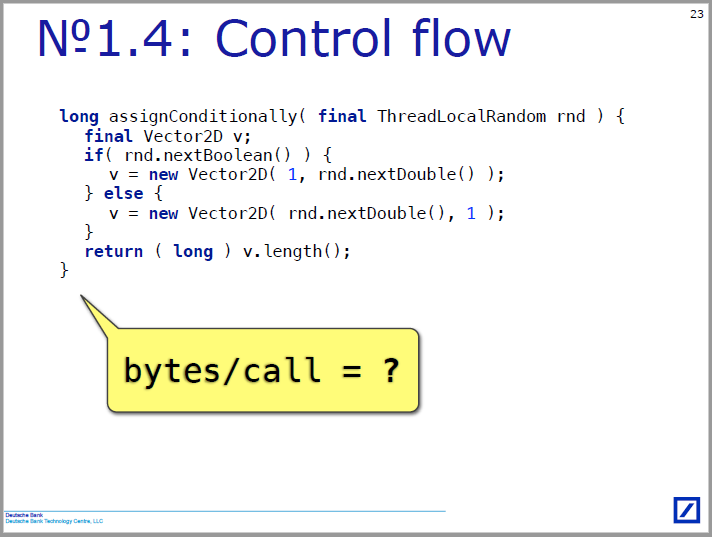
Только текстом получается всё-таки довольно тяжело, но если готовиться заранее, то можно нарисовать схему и не бояться говорить про SSA-form: на уровне концепции это несложно. В реализациях наверняка много неочевидных деталей, и в некоторых аудиториях придётся делать ещё отступления, чтобы объяснить, кто такие внутреннее представление и базовый блок, но тем не менее.
Если этот пост прочтёт настоящий компиляторщик, он, возможно, даже не снимая с полки свой зачитанный до дыр Dragonbook, укажет на ошибки и заодно объяснит, как правильно рассказывать.
Слайды
Следить за ходом рассказа легко, слайды в этом помогают. Если где-то есть много текста или большая выдача консольной утилиты, то интересные места подсвечены. Примеров с кодом достаточно много, и они по ходу рассказа сменяют друг друга всё быстрее, от этого немного устаёшь, но ничего критичного. К паре вещей всё же хочется привлечь внимание.
Лазерная указка
Те, кто читал предыдущий разбор, уже всё знают про использование лазерной указки. Выступление Руслана происходит в таком же широком зале с двумя экранами, как и у Сергея, и точно так же целеуказатель в каждый момент времени не видно примерно трети аудитории.
В каждом конкретном случае слайд можно модифицировать, чтобы было сразу понятно, о чём идёт речь. Например, слайд 13 (появляется на 10:20) вылечить совсем просто:

Здесь достаточно показывать не весь текст сразу, а последовательно открывать строчки по мере того, как до них доходит речь.
Повторяющиеся элементы
При просмотре выступления мне всё время хотелось что-нибудь сделать с количественными результатами экспериментов, которые в одном и том же формате встречаются на многих слайдах:
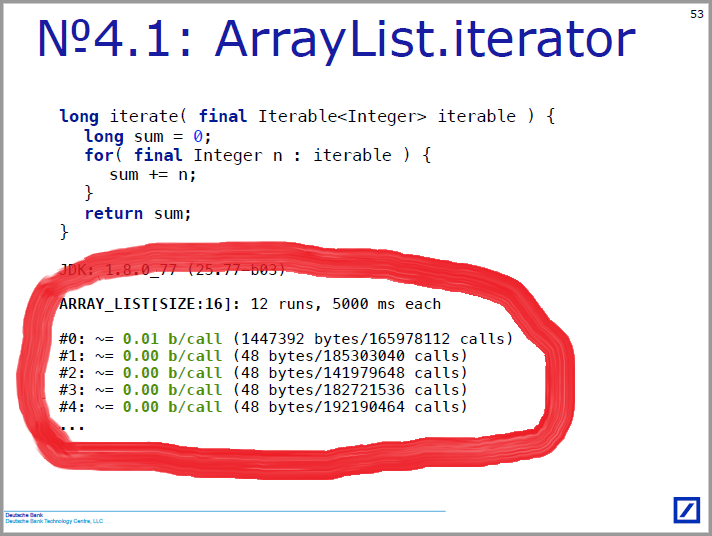
Что с ними не так?
- Это много плотного текста, читать его, если бы захотелось так делать, трудно.
- Интересный момент наступает не между run’ами, а где-то внутри одного, обычно близко к началу первого. Поэтому результаты, сгруппированные по run’ам (типа 0.01 байта на итерацию) выглядят непривычно, хоть их и проще получить.
- Моментальную информацию об исходе эксперимента зритель получает из цвета. Это нормально, но может создать трудности людям с красно-зелёным расстройством цветовосприятия (а оно, как назло, самое распространённое).
Как это упростить?
Показательнее всего был бы график, где по оси X отложен номер вызова (сквозной для всех run’ов), а по оси Y — количество байт, аллоцированных в куче на этот вызов. В плохом случае график горизонтален, в хорошем — горизонтален первые сколько-то (тысяч) вызовов, а затем падает в ноль. Заодно из него было бы видно, насколько быстро включается оптимизация, как-то так:

В таком виде интересно было бы проследить за динамикой происходящего с вероятностной функцией (слайды 98-91). Там график, скорее всего, должен быть какой-то интересный:

Возможно, я чего-то не понимаю, и данные для такого графика, даже с натяжками, в принципе получить нельзя. Тогда можно попытаться сильно уменьшить размер run’ов и строить график по ним.
Регулярные разборы
Если вы хотите получить обратную связь по своему выступлению, то я с радостью вам её предоставлю.
- Ссылка на видеозапись выступления.
- Ссылка на слайды.
- Заявка от автора. Без согласия самого докладчика ничего разбирать не будем.
Всё это нужно отправить хабраюзеру p0b0rchy, то есть мне. Обещаю, что отзыв будет конструктивным и вежливым, а также осветит и положительные моменты, а не только то, что надо улучшать.
ссылка на оригинал статьи https://habrahabr.ru/post/317536/
Добавить комментарий