В статье описывается подход к программированию многоядерных сигнальных процессоров на основе OpenMP. Рассматриваются директивы OpenMP, разбирается их смысл и варианты использования. Делается акцент на цифровых сигнальных процессорах. Примеры применения директив OpenMP выбраны приближенными к задачам цифровой обработки сигналов. Реализация проводится на процессоре TMS320C6678 фирмы Texas Instruments, включающем 8 DSP-ядер. В части I статьи рассматриваются основные директивы OpenMP. Во II части статьи планируется дополнить список директив, а также рассмотреть вопросы внутренней организации работы OpenMP и вопросы оптимизации программного обеспечения.
Данная статья отражает лекционно-практический материал, предлагаемый слушателям в рамках курсов повышения квалификации по программе «Многоядерные процессоры цифровой обработки сигналов C66x фирмы Texas Instruments», проводимых ежегодно в Рязанском радиотехническом университете. Статья планировалась к публикации в одном из научно-технических журналов, но в силу специфики рассматриваемых вопросов было принято решение о накоплении материала для учебного пособия по многоядерным DSP-процессорам. А пока данный материал будет копиться, он вполне может полежать на страницах Интернета в свободном доступе. Отзывы и пожелания приветствуются.
Введение
Современная индустрия производства высокопроизводительных процессорных элементов переживает в настоящее время характерный виток, связанный с переходом к многоядерным архитектурам [1, 2]. Данный переход является мерой скорее вынужденной, чем естественным ходом эволюции процессоров. Дальнейшее развитие полупроводниковой техники по пути миниатюризации и повышения тактовых частот с соответствующим ростом вычислительной производительности стало невозможным по причине резкого снижения их энергоэффективности. Логичным выходом из сложившейся ситуации производители процессорной техники посчитали переход к многоядерным архитектурам, позволяющим наращивать вычислительную мощь процессора не за счет более быстрой работы его элементов, а за счет параллельной работы большого числа операционных устройств [1]. Данный виток характерен для процессорной техники в целом, и, в частности, для процессоров цифровой обработки сигналов с их специфическими областями применения и особыми требованиями к вычислительной эффективности, эффективности внутренних и внешних пересылок данных при одновременном малом энергопотреблении, размерах и цене.
С точки зрения разработчика систем обработки сигналов реального времени, переход к использованию многоядерных архитектур цифровых сигнальных процессоров (ЦСП) можно выразить тремя основными проблемами. Первая – это освоение аппаратной платформы, ее возможностей, назначения тех или иных блоков и режимов их работы, заложенных производителем [1]. Вторая – адаптация алгоритма обработки и принципа организации системы для реализации на многоядерном ЦСП (МЦСП) [3]. Третья – разработка программного обеспечения (ПО) цифровой обработки сигналов, реализуемого на МЦСП. При этом разработка ПО для МЦСП имеет ряд принципиальных отличий от разработки традиционных одноядерных приложений, включая распределение тех или иных фрагментов кода по ядрам, разделение данных, синхронизацию ядер, обмен данными и служебной информацией между ядрами, синхронизацию кэш и другие.
Одним из наиболее привлекательных решений для портирования имеющегося «одноядерного» ПО на многоядерную платформу или для разработки новых «параллельных» программных продуктов является инструментарий Open Multi-Processing (OpenMP). OpenMP представляет собой набор директив компилятору, функций и переменных окружения, которые могут встраиваться в стандартные языки программирования, в первую очередь, в наиболее распространенный язык Си, расширяя его возможности организацией параллельных вычислений. Это основное достоинство OpenMP-подхода. Не нужно изобретения/изучения новых языков параллельного программирования. Одноядерная программа легко превращается в многоядерную путем добавления в стандартный код простых и понятных директив компилятору. Все что нужно, это чтобы компилятор данного процессора поддерживал OpenMP. То есть производители процессоров должны позаботиться о том, чтобы их компиляторы «понимали» директивы OpenMP-стандарта и переводили их в соответствующие ассемблерные коды.
Стандарт OpenMP разрабатывается ассоциацией нескольких крупных производителей вычислительной техники и регулируется организацией OpenMP Architecture Review Board (ARB) [4]. При этом он является универсальным, не предназначенным для конкретных аппаратных платформ конкретных производителей. Организация ARB открыто публикует спецификацию очередных версий стандарта [5]. Также представляет интерес краткий справочник по OpenMP [6].
В последнее время применению OpenMP в различных приложениях и на различных платформах посвящено огромное число работ [7-12]. Особый интерес представляют книги, позволяющие в полном объеме получить базовые знания по использованию OpenMP. В отечественной литературе это источники [13-16].
Данная работа посвящена описанию директив, функций и переменных окружения OpenMP. При этом спецификой работы является ее ориентация на задачи цифровой обработки сигналов. Примеры, иллюстрирующие смысл тех или иных директив, берутся с акцентом на реализацию на МЦСП. В качестве аппаратной платформы выбраны процессоры МЦСП TMS320C6678 фирмы Texas Instruments [17], включающие в свой состав 8 DSP-ядер. Данная платформа МЦСП является одной из передовых, пользующихся широким спросом на отечественном рынке. Кроме того, в работе рассматривается ряд вопросов внутренней организации механизмов OpenMP, имеющих значение для задач обработки сигналов реального времени, а также вопросы оптимизации.
Постановка задачи
Итак, пусть задача обработки состоит в формировании выходного сигнала, как суммы двух входных сигналов одинаковой длины:
z(n) = x(n) + y(n), n = 0, 1, …, N-1«Одноядерная» реализация данной задачи на стандартном языке Си/Си++ может выглядеть следующим образом:
void vecsum(float * x, float * y, float * z, int N) { for ( int i=0; i<N; i++) z[i] = x[i] + y[i]; }Пусть теперь мы имеем 8-ядерный процессор TMS320C6678. Возникает вопрос, как задействовать возможности многоядерной архитектуры для реализации данной программы?
Одним из решений является разработка 8 отдельных программ и независимая загрузка их на 8 ядер. Это чревато наличием 8 отдельных проектов, в которых необходимо учитывать совместные правила исполнения: расположение массивов в памяти, разделение частей массивов между ядрами и прочее. Кроме того, необходимо будет написание дополнительных программ, выполняющих синхронизацию ядер: если одно ядро завершило формирование своей части массива, это еще не значит, что весь массив готов; необходимо или вручную проверять, завершение работы всех ядер, или пересылать со всех ядер флаги завершения обработки на одно «главное» ядро, которое будет выдавать соответствующее сообщение о готовности выходного массива.
Описанный подход может быть правильным и эффективным, однако, он достаточно сложен в реализации и в любом случае требует от разработчика существенной переработки имеющегося ПО. Нам бы хотелось иметь возможность перейти от одноядерной к многоядерной реализации с минимальными изменениями исходного программного кода! В этом и состоит задача, которую решает OpenMP.
Начальные настройки OpenMP
Перед началом использования OpenMP в своей программе, очевидно, необходимо подключить данный функционал к своему проекту. Для процессоров TMS320C6678 это означает модификацию файла конфигурации проекта и используемой платформы, а также включение в свойства проекта ссылок на компоненты OpenMP. Такие специфические для конкретной аппаратной платформы настройки мы не будем рассматривать в статье. Рассмотрим более общие начальные настройки OpenMP.
Поскольку OpenMP является расширением языка Си, включение его директив и функций в свою программу должно сопровождаться включением файла описания этого функционала:
#include <ti/omp/omp.h>Далее необходимо сообщить компилятору (и функционалу OpenMP) с каким числом ядер мы имеем дело. Отметим, что OpenMP работает не с ядрами, а с параллельными потоками. Параллельный поток – понятие логическое, а ядро – физическое, аппаратное. В частности, на одном ядре могут реализовываться несколько параллельных потоков. В то же время, по-настоящему параллельное исполнения кода, естественно, подразумевает, что число параллельных потоков совпадает с числом ядер, и каждый поток реализуется на своем ядре. В дальнейшем мы будем считать, что ситуация именно так и выглядит. Однако следует иметь в виду, что номер параллельного потока и номер ядра его реализующего не обязательно должны совпадать!
К начальным настройкам OpenMP мы отнесем задание числа параллельных потоков с использованием следующей функции OpenMP:
omp_set_num_threads(8);Мы задали число ядер (потоков) равным 8.
Директива parallel
Итак, мы хотим, чтобы код представленной выше программы исполнялся на 8 ядрах. С OpenMP для этого достаточно всего лишь добавить в код директиву parallel следующим образом:
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { omp_set_num_threads(8); #pragma omp parallel { for ( int i=0; i<N; i++) z[i] = x[i] + y[i]; } }Все директивы OpenMP оформляются в виде конструкций вида:
#pragma omp <имя_директивы> [опция[(,)][опция[(,)]] …].В нашем случае никаких опций мы не используем, и директива parallel означает, что следующий за ней фрагмент кода, выделенный фигурными скобками, относится к параллельному региону и должен исполняться не на одном, а на всем заданном числе ядер.
Мы получили программу, которая выполняется на одном главном или ведущем ядре (master core), а те фрагменты, которые выделены директивой parallel выполняются на заданном числе ядер, включая как ведущее, так и ведомые ядра (slave core). В полученной реализации один и тот же цикл суммирования векторов будет выполняться сразу на 8 ядрах.
Типовая структура организации параллельных вычислений в OpenMP показана на рисунке 1.
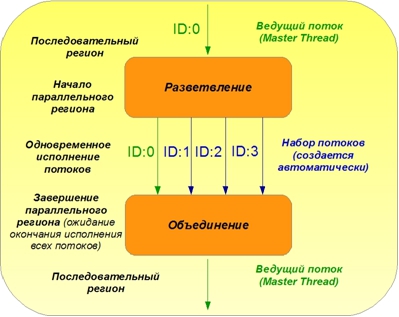
Рисунок 1. Принцип организации параллельных вычислений в OpenMP
Исполнение программного кода всегда начинается с последовательного региона, исполняемого на одном ядре в ведущем потоке. В точке начала параллельного региона, обозначаемой соответствующей директивой OpenMP, происходит организация параллельного исполнения следующего за директивой OpenMP кода в наборе потоков (параллельный регион). На рисунке для упрощения показано только четыре параллельных потока. При завершении параллельного региона потоки объединяются, ожидая окончания работы друг друга, и далее вновь следует последовательный регион.
Итак, нам удалось задействовать 8 ядер для реализации нашей программы, однако, смысла в таком распараллеливании нет, поскольку все ядра делают одну и ту же одинаковую работу. 8 ядер 8 раз сформировали один и тот же выходной массив данных. Время обработки при этом не уменьшилось. Очевидно, требуется как-то разделить работу между разными ядрами.
Проведем аналогию. Пусть есть бригада из 8 человек. Один из них является главным; остальные – его помощниками. К ним поступают запросы на проведение различных работ. Главный работник принимает и выполняет заказы, подключая, по возможности, своих помощников. Первая работа, за которую взялись наши работники, состояла в переводе текста с английского языка на русский. Бригадир взялся за выполнение работы, взял исходный текст, приготовил словари, скопировал текст для каждого из своих помощников и раздал всем один и тот же текст, не разделив работу между ними. Перевод будет выполнен. Задача будет решена корректно. Однако выигрыша от наличия 7 помощников не будет. Даже наоборот. Если им придется делить один и тот же словарь, или компьютер, или листок с исходным текстом, время выполнения задания может затянуться. Также работает и OpenMP в нашем первом примере. Требуется разделение работ. Каждому работнику следует указать, какой фрагмент общего текста должен переводить именно он.
Очевидным способом разделения работы между ядрами в контексте задачи суммирования массивов является распределение итераций цикла по ядрам в зависимости от номера ядра. Достаточно внутри параллельного региона узнать, на каком ядре выполняется код, и задать диапазон итераций цикла в зависимости от этого номера:
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { omp_set_num_threads(8); #pragma omp parallel { core_num = omp_get_thread_num(); a=(N/8)*core_num; b=a+N/8; for (int i=a; i<b; i++) z[i] = x[i] + y[i]; } }Чтение номера ядра выполняется функцией OpenMP omp_get_thread_num();. Эта функция, находясь внутри параллельного региона, выполняется одинаково на всех ядрах, но на разных ядрах дает разный результат. За счет этого становится возможным дальнейшее разделение работы внутри параллельного региона. Для простоты мы считаем, что число итераций цикла N кратно числу ядер. Чтение номера ядра может быть основано аппаратно на наличии в каждом ядре специального регистра номера ядра – регистра DNUM на процессорах TMS320C6678. Обратиться к нему можно различными средствами, включая ассемблерные команды или функции библиотеки поддержки кристалла CSL. Однако можно воспользоваться и функционалом, предоставляемым надстройкой OpenMP. Здесь, однако, мы вновь должны обратить внимание на то, что номер ядра и номер параллельного региона OpenMP – это разные понятия. Например, 3-й параллельный поток вполне может исполняться на, скажем, 5-ом ядре. Более того, в следующем параллельном регионе или при повторном прохождении того же параллельного региона 3-ий поток может исполняться уже на, например, 4-ом ядре. И так далее.
Мы получили программу, выполняющуюся на 8 ядрах. Каждое ядро обрабатывает свою часть входных массивов и формирует соответствующую область выходного массива. Каждый из наших работников переводит свою 1/8 часть текста и в идеале мы получаем 8-кратное ускорение решения задачи.
Директивы for и parallel for
Мы рассмотрели простейшую директиву parallel, позволяющую выделить в коде фрагменты, которые должны выполняться на нескольких ядрах параллельно. Эта директива, однако, подразумевает, что все ядра выполняют один и тот же код и разделения работ не предусматривается. Нам пришлось делать это самостоятельно, что выглядит несколько запутанно.
Автоматическое указание, как работа внутри параллельного региона делится между ядрами, возможно с использованием дополнительной директивы for. Данная директива используется внутри параллельного региона непосредственно перед циклами типа for и говорит о том, что итерации цикла должны быть распределены между ядрами. Директивы parallel и for могут использоваться раздельно:
#pragma omp parallel #pragma omp forА могут использоваться совместно в одной директиве для сокращения записи:
#pragma omp parallel forПрименение в нашем примере сложения массивов директивы parallel for приводит к следующему программному коду:
#include <ti/omp/omp.h> void vecsum (float * x, float * y, float * z, int N) { int i; omp_set_num_threads(8); #pragma omp parallel for for (i=a; i<b; i++) z[i] = x[i] + y[i]; }Если сравнить данную программу с исходной одноядерной реализацией, то мы увидим, что отличия минимальны. Мы всего лишь подключили заголовочный файл omp.h, установили число параллельных потоков и добавили одну строчку – директиву parallel for.
Замечание 1. Еще одним отличием, которое мы намеренно скрываем в наших рассуждениях, является перенос объявления переменной i из цикла в раздел описания переменных функции, а точнее из параллельного в последовательный регион кода. Сейчас еще рано пояснять данное действие, однако, оно является принципиальным и будет пояснено позже в разделе, касающемся опций private и shared.
Замечание 2. Мы говорим, что итерации цикла делятся между ядрами, однако, мы не говорим, как конкретно они делятся. Какие конкретно итерации цикла, на каком из ядер будут выполняться? OpenMP имеет возможности задавать правила распределения итераций по параллельным потокам, и мы рассмотрим эти возможности позже. Однако точно привязать конкретное ядро к конкретным итерациям можно только вручную рассмотренным ранее способом. Правда обычно такая привязка не является необходимой. В случае, если число итераций цикла не кратно числу ядер, распределение итераций по ядрам будет производиться так, чтобы нагрузка распределялась максимально равномерно.
Директивы sections и parallel sections
Разделение работы между ядрами может производиться либо на основе разделения данных, либо на основе разделения задач. Вспомним про нашу аналогию. Если все работники выполняют одно и то же – занимаются переводом текста, – но каждый переводит разный фрагмент текста, то это относится к первому типу разделения работы – разделению данных. Если же работники выполняют различные действия, например, один занимается переводом всего текста, другой ищет для него слова в словаре, третий набирает текст перевода и так далее, то это относится ко второму типу разделения работы – разделению задач. Рассмотренные нами директивы parallel и for позволяли разделять работу путем разделения данных. Разделение задач между ядрами позволяет выполнять директива sections, которая, как и в случае директивы for, может использоваться независимо от директивы parallel или совместно с ней для сокращения записи:
#pragma omp parallel #pragma omp sectionsи
#pragma omp parallel sectionsВ качестве примера мы приведем программу, в которой используются 3 ядра процессора, и каждое из ядер выполняет свой алгоритм обработки входного сигнала x:
#include <ti/omp/omp.h> void sect_example (float* x) { omp_set_num_threads(3); #pragma omp parallel sections { #pragma omp section Algorithm1(x); #pragma omp section Algorithm2(x); #pragma omp section Algorithm3(x); } }
Опции shared, private и default
Выберем для рассмотрения новый пример. Перейдем к вычислению скалярного произведения двух векторов. Простая программа на языке Си, реализующая данную процедуру, может выглядеть следующим образом:
float x[N]; float y[N]; void dotp (void) { int i; float sum; sum = 0; for (i=0; i<N; i++) sum = sum + x[i]*y[i]; }Результат выполнения (для тестовых массивов из 16 элементов) оказался равным:
[TMS320C66x_0] sum = 331.0Перейдем к параллельной реализации данной программы, используя директиву parallel for:
float x[N]; float y[N]; void dotp (void) { int i; float sum; sum = 0; #pragmaomp parallel for { for (i=0; i<N; i++) sum = sum + x[i]*y[i]; } }Результат выполнения:
[TMS320C66x_0] sum= 6.0Программа дает неверный результат! Почему?
Чтобы ответить на этот вопрос, необходимо разобраться, как связаны значения переменных в последовательном и параллельном регионах. Опишем логику работы OpenMP более подробно.
Функция dotp() начинает выполняться в виде последовательного региона на 0-м ядре процессора. При этом в памяти процессора организованы массивы x и y, а также переменные I и sum. При достижении директивы parallel в действие вступают служебные функции OpenMP, которые организуют последующую параллельную работу ядер. Происходит инициализация ядер, их синхронизация, подготовка данных и общий старт. Что происходит при этом с переменными и массивами?
Все объекты в OpenMP (переменные и массивы) можно разделить на общие (shared) и частные (private). Общие объекты размещаются в общей памяти и используются равноправно всеми ядрами внутри параллельного региона. Общие объекты совпадают с одноименными объектами последовательного региона. Они переходят из последовательного в параллельный регион и обратно без изменений, сохраняя свое значение. Доступ к таким объектам внутри параллельного региона осуществляется равноправно для всех ядер, и возможны конфликты общего доступа. В нашем примере массивы x и y, а также переменная sum, по умолчанию оказались общими. Получается, что все ядра используют одну и ту же переменную sum в качестве аккумулятора. В результате иногда складывается ситуация, при которой несколько ядер одновременно считывают одинаковое текущее значение аккумулятора, добавляют к нему свой частичный вклад и записывают новое значение в аккумулятор. При этом то ядро, которое делает запись последним, стирает результаты работы остальных ядер. Именно по этой причине наш пример дал неправильный результат.
Принцип работы с общими и частными переменными проиллюстрирован на рисунке 2.
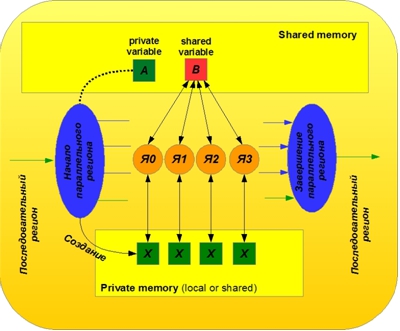
Рисунок 2. Иллюстрация работы OpenMP с общими и частными переменными
Частные объекты представляют собой копии исходных объектов, создаваемые отдельно для каждого ядра. Эти копии создаются динамически при инициализации параллельного региона. В нашем примере переменная i как счетчик итераций цикла по умолчанию считается частной. При достижении директивы parallel в памяти процессора создается 8 копий (по числу параллельных потоков) этой переменной. Частные переменные размещаются в частной памяти каждого ядра (могут размещаться в локальной памяти, а могут и в общей, в зависимости от того, как мы их объявили и сконфигурировали память). Частные копии по умолчанию никак не связаны с исходными объектами последовательного региона. По умолчанию значения исходных объектов не передаются в параллельный регион. Какими являются частные копии объектов в начале выполнения параллельного региона, неизвестно. По окончании параллельного региона значения частных копий просто теряются, если не принять специальных мер к передаче этих значений в последовательный регион, о которых мы расскажем далее.
Чтобы явно указать компилятору, какие объекты следует считать частными, а какие общими, совместно с директивами OpenMP применяются опции shared и private. Список объектов, относящихся к общим или частным, указывается через запятую в скобках после соответствующей опции. В нашем случае переменные i и sum должны быть частными, а массивы x и y – общими. Поэтому мы будем использовать конструкцию вида:
#pragma omp parallel for private(i, sum) shared(x, y)при открытии параллельного региона. Теперь у каждого ядра будет свой аккумулятор, и накопления будут идти независимо друг от друга. Дополнительно аккумуляторы надо теперь обнулить, так как исходное их значение неизвестно. Кроме того, возникает вопрос, как объединить частные результаты, полученные на каждом из ядер. Одним из вариантов является использование специального общего массива из 8 ячеек, в который каждое ядро поместит свой результат внутри параллельного региона, а после выхода из параллельного региона главное ядро суммирует элементы этого массива и сформирует окончательный результат. Мы получаем следующий код программы:
float x[N]; float y[N]; float z[8]; void dotp (void) { int i, core_num; float sum; sum = 0; #pragma omp parallel private(i, sum, core_num) shared(x, y, z) { core_num = omp_get_thread_num(); sum = 0; #pragma omp for for (i=0; i<N; i++) sum = sum + x[i]*y[i]; z[core_num] = sum; } for (i=0; i<8; i++) sum = sum + z[i]; }Результат выполнения:
[TMS320C66x_0] sum= 331.0Программа работает корректно, хотя является немного громоздкой. О том, как упростить ее мы поговорим далее.
Интересно, что при указании в качестве частных объектов имен массивов OpenMP при инициализации параллельного региона поступает также как и с переменными – динамически создает частные копии этих массивов. Убедиться в этом можно проведя простой эксперимент: объявив массив через опцию private, вывести значения указателей на этот массив в последовательном и в параллельном регионах. Мы увидим 9 разных адресов (при числе ядер – 8).
Далее можно убедиться, что значения элементов массивов никак друг с другом не связаны. Кроме того, при последующем входе в тот же параллельный регион адреса частных копий массивов могут быть иными, и значения элементов по умолчанию не сохраняются. Все это подводит нас к тому, что директивы OpenMP, открывающие и закрывающие параллельный регион, могут быть достаточно громоздкими и требовать определенного времени выполнения.
Если для объекта явное указание его типа (общий/частный) в директиве открытия параллельного региона отсутствует, то OpenMP «действует» по определенным правилам, описанным в [5]. Неописанные объекты OpenMP относит к типу по умолчанию. Какой это будет тип, private или shared, определяется переменной среды, – одним из параметров работы OpenMP. Данный параметр может задаваться и меняться в процессе работы. Исключение составляют переменные, используемые в качестве счетчиков итераций циклов. Они по умолчанию считаются частными. Правда это правило действует только для директив типа for и parallel for, поэтому лучше обращать на эти переменные особое внимание.
В связи с этим полезным оказывается применение опции default. Данная опция позволяет указать те объекты, для которых будет действовать правило – тип по умолчанию. При этом, если в качестве параметра этой опции выбрать none, то это будет означать, что никакая переменная не может принимать тип по умолчанию, то есть требуется обязательное явное указание типа всех объектов, встречаемых в параллельном регионе:
#pragma omp parallel private(sum, core_num) shared(x, y, z) default(i)или:
#pragma omp parallel private(i, sum, core_num) shared(x, y, z) default(none)
Опция reduction
В рассмотренном примере реализации скалярного произведения на 8 ядрах мы отметили один недостаток: объединение частных результатов работы ядер требует существенных доработок кода, что делает его громоздким и неудобным. В то же время концепция openMP подразумевает максимальную прозрачность перехода от одноядерной к многоядерной реализации и обратно. Упростить программу, рассмотренную в предыдущем разделе, позволяет применение опции reduction.
Опция reduction позволяет указать компилятору, что результаты работы ядер должны быть объединены, и задает правила такого объединения. Опция reduction предусмотрена для ряда наиболее распространенных ситуаций. Синтаксис опции следующий:
reduction (идентификатор : список объектов)
идентификатор – определяет, какую операцию объединения частных результатов требуется выполнить. Он же задает начальные значения переменных, которые представляют частные результаты.
список объектов – имена переменных, которые используются для формирования частных результатов работы ядер.
Все возможные варианты использования опции reduction, предусмотренные стандартом OpenMP на данный момент, приведены в Таблице 1.
Возможные идентификаторы операции: +, *, -, &, |, ^, &&, ||, max, min
Соответствующие начальные значения переменных: 0, 1, 0, 0, 0, 0, 1, 0, наименьшее значение для данного типа, наибольшее значение для данного типа.
В нашей программе скалярного произведения следует использовать опцию reduction c идентификатором «+» для переменной sum:
float x[N]; float y[N]; void dotp (void) { int i; float sum; #pragma omp parallel for private(i) shared(x, y) reduction(+:sum) for (i=0; i<N; i++) sum += x[i]*y[i]; }Результат выполнения:
[TMS320C66x_0] sum= 331.0Программа дает верный результат и при этом очень компактно выглядит и включает лишь минимальные отличия от исходного «последовательного» кода!
Синхронизация в OpenMP
Одной из основных проблем, имеющих место в многоядерных процессорах, является проблема синхронизации работы ядер. Когда несколько ядер одновременно решают одну общую задачу, как правило, возникает необходимость координации их действий. Если одно ядро начнет выполнять некоторые функции, раньше другого, то результат общей работы может оказаться некорректным. Мы уже частично столкнулись с этой проблемой, когда заставляли все ядра работать с одной общей переменной. Несогласованность действий привела к неправильному результату.
В общем случае синхронизация ядер состоит в том, что в определенных точках программного кода все ядра или требуемая их часть останавливают свою работу, уведомляют другие ядра о достижении данной точки (точки синхронизации) и не продолжают свою работу, пока все остальные ядра не достигнут этой точки синхронизации. Выполнив один параллельный фрагмент, ядра дожидаются друг друга и переходят к следующему фрагменту, скоординировав свою работу. Важно отметить, что синхронизация ядер (или параллельных потоков), подразумевает не только синхронизацию по исполняемому программному коду, но и по данным. Происходит синхронизация кэш-памяти: возврат данных, модифицированных в кэш, в основную память. Это очень важный момент, так как ядра в OpenMP-концепции в основном работают с общей памятью, фрагменты которой кэшируются в локальной памяти каждого ядра. В результате значение общей переменной, модифицированное одним ядром, может неправильно считываться другим ядром из-за рассинхронизации кэш-памяти первого ядра и общей (основной) памяти.
В OpenMP можно выделить два типа синхронизации: неявную и явную. Неявная синхронизация происходит автоматически в конце параллельных регионов, а также по окончании ряда директив, которые могут применяться внутри параллельных регионов, включая omp for, omp sections и так далее. При этом автоматически происходит и синхронизация кэш.
Если алгоритм решения задачи требует синхронизировать ядра в тех точках программы внутри параллельного региона, в которых автоматическая синхронизация не предусматривается, разработчик может использовать явную синхронизацию – указать компилятору OpenMP в явном виде с помощью специальных директив, что в этой точке программы требуется выполнить синхронизацию. Рассмотрим основные из этих директив.
Директива barrier
Директива barrier записывается в виде:
#pragma omp barrierи в явном виде устанавливает точку синхронизации параллельных потоков OpenMP внутри параллельного региона. Приведем следующий пример использования директивы:
#define CORE_NUM 8 float z[CORE_NUM]; void arr_proc(void) { omp_set_num_threads(CORE_NUM); int i, core_num; float sum; #pragma omp parallel private(core_num, i, sum) { core_num=omp_get_thread_num(); z[core_num]=core_num; #pragma omp barrier sum = 0; for(i=0;i<CORE_NUM;i++) sum=sum+z[i]; #pragma omp barrier z[core_num]=sum; } for(i=0;i<CORE_NUM;i++) printf("z[%d] = %f\n", i, z[i]); }В этой программе мы смоделировали следующую ситуацию. Пусть работа с сигналом включает этапы формирования данных в массиве z, обработки данных в массиве z, записи результата обработки в массив z. В случае нашей программы на первом этапе каждое ядро пишет свой номер в соответствующую ячейку массива z, расположенного в общей памяти. Далее все ядра выполняют одинаковую обработку входного массива: находят сумму его элементов. Далее все ядра записывают получившийся результат в ячейку массива z, соответствующую номеру ядра. В результате все ячейки массива должны оказаться одинаковыми. Однако без директив barrier этого не происходит. Все ячейки массива z оказываются разными и в общем случае произвольными. При переходе от первого этапа ко второму, ядра, не дожидаясь друг друга, начинают обрабатывать еще не готовые данные. При переходе от второго этапа к третьему, ядра начинают записывать свои результаты в массив z, хотя другие ядра еще могут читать значения этого массива, используя их для обработки. Только наличие обеих директив barrier гарантирует корректное выполнение программы и запись одинаковых результатов вычислений во все элементы массива z. Синхронизация по исполняемому коду подразумевает и синхронизацию по данным – синхронизацию кэш.
Директива critical
Директива critical записывается в виде:
#pragma omp critical [имя региона]И выделяет фрагмент кода внутри параллельного региона, который может исполняться одновременно только одним ядром.
Пусть работники нашей бригады выполняют очередное задание, одним из этапов которого является доклад бригадиру о состоянии дел. Пусть все этапы их работы могут проходить полностью независимо от других работников. В том числе и доклад бригадиру работники могут делать одновременно, однако, такой доклад будет, очевидно, мало полезен. Необходимо уточнить, что данное действие в один момент времени может выполнять только один из работников. Если докладчики оказываются готовыми к отчету в разные моменты времени, то вопросов об их синхронизации не возникает. Если же обстоятельства складываются так, что двое или более работников готовы дать отчет одновременно или один из работников приходит с отчетом в момент доклада другого работника, путаница должна быть исключена: тот, кто пришел позже, должен подождать; более одного работника не могут исполнять данный фрагмент задания одновременно.
В случае обработки сигнала ситуация аналогична. Если алгоритм обработки подразумевает, что некоторый фрагмент кода не может выполняться одновременно несколькими ядрами, то такой фрагмент можно выделить директивой critical. Пример применения данной директивы может выглядеть следующим образом:
#define CORE_NUM 8 #define N 1000 #define M 80 void crit_ex(void) { int i, j; int A[N]; int Z[N] = {0}; omp_set_num_threads(CORE_NUM); #pragma omp parallel for private (A) for (i = 0; i < M; i++) { poc_A(A, N); #pragma omp critical for (j=0; j<N; j++) Z[j] = Z[j] + A[j]; } }В данной программе в цикле М раз повторяется обработка (формирование) массива А и накопление результатов обработки в массиве Z. При переходе к многоядерной реализации итерации цикла обработки распределяются между 8 ядрами. При этом массив А обрабатывается как частный, то есть независимо на каждом ядре. Обработка может идти на всех ядрах параллельно, поскольку зависимостей между этими процедурами нет. При накоплении результаты работы всех ядер объединяются в общем массиве Z. Если не принять специальных мер по синхронизации ядер, то параллельные потоки будут обращаться к одному общему ресурсу и вносить ошибку в работу друг друга. Чтобы предотвратить ошибки, можно запретить параллельным потокам в этом месте выполняться параллельно. Первое ядро, завладевшее ресурсом (в данном случае фрагментом кода), будет владеть им полностью, пока не выполнит все действия. Остальные ядра будут ожидать освобождения ресурса в начале критической секции кода. Фактически, мы переходим к последовательной обработке внутри параллельного региона.
Заменим в нашем коде критическую секцию на следующую конструкцию.
#pragma omp critical (Z1add) for (j=0; j<N; j++) Z1[j] = Z1[j] + A[j]; #pragma omp critical (Z2mult) for (j=0; j<N; j++) Z2[j] = Z2[j] * A[j];Теперь мы имеем две критических секции. В одной идет объединение результатов работы ядер путем суммирования; в другой – путем умножения. Обе секции могут выполняться одновременно только на одном ядре, однако, разные секции могут выполняться одновременно на разных ядрах. Если в конструкцию директивы critical внести имя региона, то ядру будет отказано в доступе к коду, только если другое ядро работает именно в этом регионе. Если имена регионам не присвоены, то ядро не сможет войти ни в один из критических регионов, если другое ядро работает с любым из них, даже если они никак не связаны между собой.
Директива atomic
Директива atomic записывается в виде:
#pragma omp atomic [read | write | update | capture]В предыдущем примере разным ядрам запрещалось выполнять код из одного региона одновременно. Однако это может показаться не рациональным при более близком рассмотрении. Ведь конфликты доступа к общему ресурсу состоят в том, что разные ядра могут обратиться одновременно к одинаковым ячейкам памяти. Если же в рамках одного кода обращение идет к разным ячейкам памяти, искажения результата не последует. Привязать синхронизацию ядер к элементам памяти позволяет директива atomic. Она указывает, что в следующей за ней строке операция работы с памятью является атомарной – неразрывной: если какое-то ядро начало операцию работы с некоторой ячейкой памяти, доступ к этой ячейке памяти будет закрыт для всех других ядер, пока первое ядро не закончит работу с ней. При этом директива atomic сопровождается опциями, указывающими, какой тип операции производится с памятью: чтение/запись/модификация/захват. Выше рассмотренный пример в случае применения директивы atomic будет выглядеть следующим образом.
#define CORE_NUM 8 #define N 1000 #define M 80 void crit_ex(void) { int i, j; int A[N]; int Z[N] = {0}; omp_set_num_threads(CORE_NUM); #pragma omp parallel for private (A) for (i = 0; i < M; i++) { poc_A(A, N); for (j=0; j<N; j++) { #pragma omp atomic update Z[j] = Z[j] + A[j]; } }Теоретически, применение директивы atomic должно существенно сократить время обработки, поскольку от полностью последовательного выполнения цикла мы переходим к последовательному выполнению только отдельных операций обращения к памяти, когда номера запрашиваемых элементов массива совпадают для разных ядер. Однако на практике эффективность данной идеи будет зависеть от способа ее реализации. Если, например, синхронизация ядер с помощью директивы atomic сводится к чтению флага, расположенного в общей памяти, на каждой итерации цикла, то время выполнения цикла может существенно возрастать. Другими словами, в случае директивы critical время выполнения цикла составит MxT1 тактов процессора, где М – число ядер, а T1 – время выполнения цикла одним ядром; а в случае директивы atomic время выполнения цикла составит Т2 тактов процессора. При этом цикл с директивой atomic включает дополнительный код синхронизации, и время Т2 может оказываться более, чем в М раз больше времени Т1.
Заключительные замечания
В данной статье мы рассмотрели основные конструкции OpenMP – расширения языков программирования высокого уровня (Си/Си++), используемого для автоматического, выполняемого компилятором, распараллеливания программного обеспечения для реализации на многоядерных процессорах. Особенностью данной статьи является ориентация на системы цифровой обработки сигналов и иллюстрация выполнения примеров программ на 8-ядерном ЦСП TMS320C6678 фирмы Texas Instruments. Основное достоинство OpenMP – это простота перехода от одноядерной к многоядерной реализации. Все задачи по взаимодействию ядер, включая обмен данными и синхронизацию, выполняют стандартные функции OpenMP, подключаемые на этапе компиляции. Однако удобство разработки обычно чревато меньшей эффективностью получаемого решения. Вопросы издержек на инструментарий OpenMP не рассматриваются в рамках данной статьи. Планируется посвятить этому отдельную работу.
Тем не менее, можно отметить, что затраты на директивы OpenMP оказываются значительными, измеряемыми единицами и десятками тысяч тактов. Поэтому распараллеливание имеет смысл только на относительно высоком уровне, когда внутри параллельного региона вычислительная нагрузка оказывается значительной и основное время ядра работают над поставленными задачами, не взаимодействуя друг с другом.
Также следует отметить, что стандарт OpenMP закладывает общую идеологию. Эффективность же OpenMP зависит от реализации функций OpenMP для конкретной платформы процессоров. Так версии OpenMP 1 и 2, разработанные фирмой Texas Instruments для процессоров TMS320C6678 существенно отличаются. Вторая версия задействует многочисленные аппаратные механизмы ускорения взаимодействия ядер и оказывается существенно эффективнее первой версии. В последующих работах планируется раскрыть основные механизмы реализации функций OpenMP; провести анализ издержек, сопутствующих этим функциям; сформировать тестовые оценки времени реализации директив OpenMP; сформировать советы по повышению эффективности использования данного механизма.
2. L.J. Karam, I. AlKamal, A. Gatherer, G.A. Frantz, «Trends in multicore DSP platforms,» Signal Processing Magazine, vol. 26, no. 6, pp. 38-49, 2009.
3. A. Jain, R. Shankar. Software Decomposition for Multicore Architectures, Dept. of Computer Science and Engineering, Florida Atlantic University, Boca Raton, FL, 33431.
4. Web-сайт OpenMP Architecture Review Board (ARB): openmp.org.
5. OpenMP Application Programming Interface. Version 4.5 November 2015. OpenMP Architecture Review Board. P. 368.
6. OpenMP 4.5 API C/C++ Syntax Reference Guide. OpenMP Architecture Review Board. 2015.
7. J. Diaz, C. Muñoz-Caro, A. Niño. A Survey of Parallel Programming Models and Tools in the Multi and Many-Core Era. IEEE Transactions on Parallel and Distributed Systems. – 2012. – Vol. 23, Is. 8, pp. 1369 – 1386.
8. A. Cilardo, L. Gallo, A. Mazzeo, N. Mazzocca. Efficient and scalable OpenMP-based system-level design. Design, Automation & Test in Europe Conference & Exhibition (DATE). – 2013, pp. 988 – 991.
9. M. Chavarrías, F. Pescador, M. Garrido, A. Sanchez, C. Sanz. Design of multicore HEVC decoders using actor-based dataflow models and OpenMP. IEEE Transactions on Consumer Electronics. – 2016. – Vol. 62. – Is. 3, pp. 325 – 333.
10. M. Sever, E. Çavus. Parallelizing LDPC Decoding Using OpenMP on Multicore Digital Signal Processors. 45th International Conference on Parallel Processing Workshops (ICPPW). – 2016, pp. 46 – 51.
11. A. Kharin, S. Vityazev, V. Vityazev, N. Dahnoun. Parallel FFT implementation on TMS320c66x multicore DSP. 6th European Embedded Design in Education and Research Conference (EDERC). – 2014, pp. 46 – 49.
12. D. Wang, M. Ali, ―Synthetic Aperture Radar on Low Power Multi-Core Digital Signal Processor,‖ High Performance Extreme Computing (HPEC), IEEE Conference on, pp. 1 – 6, 2012.
13. В. П. Гергель, А. А. Лабутина. Учебно-образовательный комплекс по методам параллельного программирования. Н.Новгород, 2007, 138 с.
14. А. В. Сысоев. Высокопроизводительные вычисления в учебном процессе и научных исследованиях. Н. Новгород, 2006, 90 с.
15. А.С. Антонов. Параллельное программирование с использованием технологии OpenMP. Издательство Московского университета. 2009 г, 78 с.
16. М.П. Левин. Параллельное программирование с использованием OpenMP. М.: 2012, 121 с.
17. TMS320C6678 Multicore Fixed and Floating-Point Digital Signal Processor, Datasheet, SPRS691E, Texas Instruments, p. 248, 2014.
ссылка на оригинал статьи https://habrahabr.ru/post/318762/
Добавить комментарий