
Очень часто, созданию базы данных CDR отводится мало места в описаниях настройки. Как правило, все сводится к цитате SQL команд и обещанию, что если кинуть ее в консоль то «все будет ОК».
К примеру, первая же ссылка в гугле рекомендует создать табличку таким образом:
CREATE TABLE `cdr` (
`calldate` datetime NOT NULL default ‘0000-00-00 00:00:00’,
`clid` varchar(80) NOT NULL default »,
`src` varchar(80) NOT NULL default »,
`dst` varchar(80) NOT NULL default »,
`dcontext` varchar(80) NOT NULL default »,
`channel` varchar(80) NOT NULL default »,
`dstchannel` varchar(80) NOT NULL default »,
`lastapp` varchar(80) NOT NULL default »,
`lastdata` varchar(80) NOT NULL default »,
`duration` int(11) NOT NULL default ‘0’,
`billsec` int(11) NOT NULL default ‘0’,
`disposition` varchar(45) NOT NULL default »,
`amaflags` int(11) NOT NULL default ‘0’,
`accountcode` varchar(20) NOT NULL default »,
`userfield` varchar(255) NOT NULL default »
);ALTER TABLE `cdr` ADD INDEX ( `calldate` );
ALTER TABLE `cdr` ADD INDEX ( `dst` );
ALTER TABLE `cdr` ADD INDEX ( `accountcode` );
Сразу можно обратить внимание, что как минимум два индекса в базе бесполезны. Это calldate и accountcode. Первый в силу того, что при ежесекундном добавлении записей, размер индекса будет равен количеству записей в самой базе. Да, этот индекс отсортирован, и можно применить некоторые способы к ускорению поиска, но будет ли он эффективен? Второй индекс (accountcode) практически никогда и никем не используется. В качестве подопытной базы — база с 80 млн записей.
Выполним запрос:
SELECT * FROM CDR WHERE src=***** AND calldate>'2016-06-21' AND calldate<'2016-06-22'; /* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 00:09:36 */Почти 10 минут ожидания.
Другими словами, создание отчетов становится проблемой. Конечно, табличку можно ратировать, но зачем такие жертвы, если достаточно провести оптимизацию.
Внимание! Никогда не делай это в продакшене! Только на копии базы! База лочится на время от 1 часа до нескольких и возможны потери данных при аварийном завершении!
Итак, два шага к успеху эффективного хранения CDR:
- Разбить на партиции, чтобы ускорить выборку по периодам
- Эффективное индексирвоание
Шаг 0. Выбор движка хранения
Собственно есть два распространенных варианта — MyISAM и INNODB. Холиварить на эту тему можно бесконечно долго, но сравнение движков на реальной базе дало перевес в пользу MyISAM. Причин тут несколько:
- При чистой настройке сервера неопытным админом, именно MyISAM более корректно работает при индексации больших объемов. В то время, как INNODB требует тюнинга. В противном случае можно увидеть интересные ошибки о том, что индекс не может быть перестроен
- MyISAM при включении опции FIXED ROW приобретает дополнительные свойства, а именно:
- Устойчивость к сбоям даже при падении сервера
- Возможность читать файл напрямую из внешнего приложения, минуя сервер MySQL, что бывает полезно
- Скорость обращения к рандомным строкам выше, за счет того, что все строки имеют одинаковую длину
Другими словами, для логирования лучше всего (ИМХО) подойдет MyISAM.
Остановимся на нем.
Шаг 1. Партиции.
В виду того, что мы либо дополняем базу, либо читаем из нее, эффективно раз и навсегда поделить базу на файлы, чтобы уменьшить возможное количество обращений, при чтении определенных временных промежутков. Естественно, разбивать базу нужно по какому-то ключу. Но по какому? Определенно, это должно быть время, но эффективно ли бить базу по calldate? Думаю нет, поэтому вводим дополнительное поле, которое нам также пригодиться и в следующем шаге. А именно — дату. Просто дату, без времени.
Вводим дополнительное поле date, и делаем очень простой триггер на табличку, before update cdr:
BEGIN SET new.date=DATE(new.calldate); END Таким образом, в это поле у нас попадет только дата. И сразу разбиваем табличку на партиции по годам:
ALTER TABLE cdr PARTITION BY RANGE (YEAR(date)) (PARTITION old VALUES LESS THAN (2015) ENGINE = MyISAM, PARTITION p2015 VALUES LESS THAN (2016) ENGINE = MyISAM, PARTITION p2016 VALUES LESS THAN (2017) ENGINE = MyISAM, PARTITION p2018 VALUES LESS THAN (2018) ENGINE = MyISAM, PARTITION p2019 VALUES LESS THAN (2019) ENGINE = MyISAM, PARTITION p2020 VALUES LESS THAN (2020) ENGINE = MyISAM, PARTITION p2021 VALUES LESS THAN (2021) ENGINE = MyISAM, PARTITION p2022 VALUES LESS THAN (2022) ENGINE = MyISAM, PARTITION p2023 VALUES LESS THAN (2023) ENGINE = MyISAM, PARTITION pMAXVALUE VALUES LESS THAN MAXVALUE ENGINE = MyISAM) Готово, теперь если мы будем выборку делать с указанием диапазона даты, то MySQL не придется лопатить всю базу за все года. Небольшой плюсик уже есть.
Шаг 2. Индексируем базу.
Собственно, это самый важный шаг. Эксперименты показывают, что в 90% случаев возникает необходимость в индексах на 3 столбцах (по мере необходимости):
- date
- src
- dst
date
MySQL может использовать только один индекс за раз, поэтому некоторые администраторы пытаются создавать составные индексы. Эффектность их не очень высока, потому что как правило приходиться выбирать диапазоны, а в этом случае составные индексы игнорируются MySQL, т.е. происходит FullScan. Исправить поведение скуля мы не можем, но можем сделать так, чтобы количество строк для сканирования было минимальным и дать движку выбор, какой индекс использовать. С одной стороны, нам необходима максимальная подробность индекса, с другой стороны нам нужно затратить как можно меньше операций, чтобы получить диапазон, который мы будем перебирать. Именно поэтому и рекомендую использовать индекс по полю date, а не calldate. Количество элементов в индексе будет равно количеству дней, с момента начала ведения базы, что позволит базе быстро перейти к нужным строчкам.
Есть еще один споcоб помочь базе — сделать так, чтобы она могла вычислить положение строки в файле еще ДО открытия файла. Именно для этого можно использовать FIXED ROW. Положение строки в файле будет вычисляться умножение номера строки на длину строки, а не перебором. Естественно, у того подхода есть жертвы — база будет занимать на диске значительно больше места. Вот к примеру:

Размер базы вырос с 18 Гб до 53,8 Гб. Делать или нет — выбор каждого админа, но если место на сервере позволяет, то это будет еще одним плюсиком.
src,dst
Тут несколько меньше простора для оптимизаций. Точнее, один момент:
Если у вас не используется текстовых номеров, например в софтфонах, то данные поля можно преобразовать в BigInt, что тоже очень хорошо скажется на индексировании и выборке. Но если, Вы как и мы, используете текстовые номера, то данная оптимизация не для вас и придется смириться с более низкой производительностью.
В качестве вишенки на торте — подчищаем те поля, которые нас не интересуют и выставляем размер полей в ожидаемый для нашего случая. У меня получилось вот так:
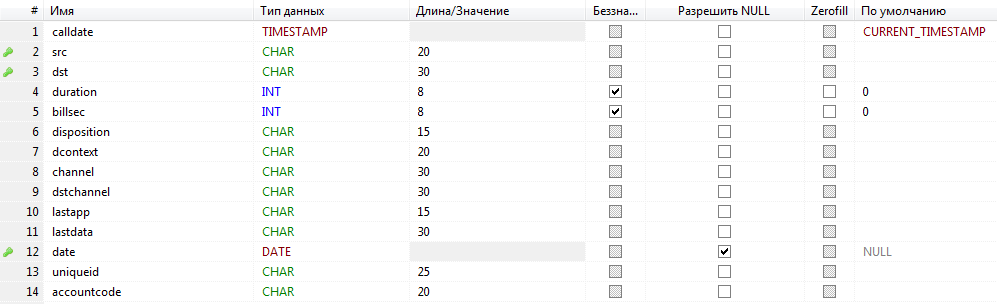
Ну и финальный запрос:
SELECT * FROM CDR WHERE src=***** AND date='2016-06-21'; /* Affected rows: 0 Найденные строки: 4 Предупреждения: 0 Длительность 1 query: 0,577 sec. */Прирост на два порядка.
Для примера еще, по диапазону:
SELECT * FROM CDR WHERE src=***** AND date>'2016-09-01' AND date<'2016-09-05'; /* Affected rows: 0 Найденные строки: 1 Предупреждения: 0 Длительность 1 query: 3,900 sec. */ссылка на оригинал статьи https://habrahabr.ru/post/318770/
Добавить комментарий