
Миллионы пользователей ежемесячно отправляют миллиарды сообщений в Discord. Поиск в этих сообщениях стал одной из самых востребованных функций, какие мы сделали. Да будет поиск!
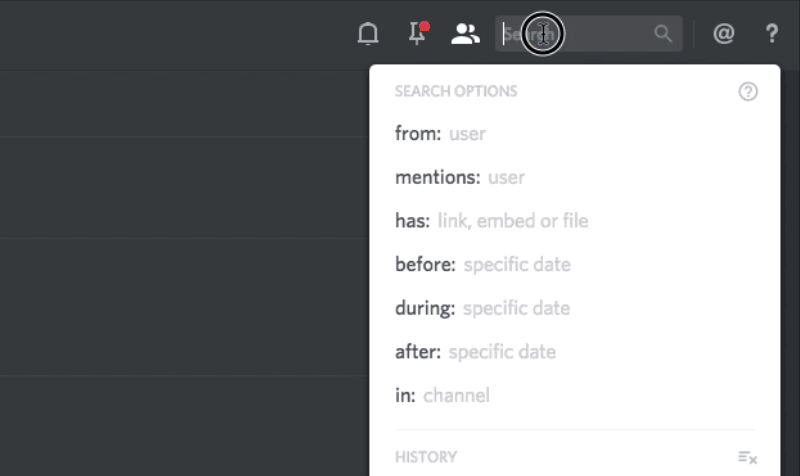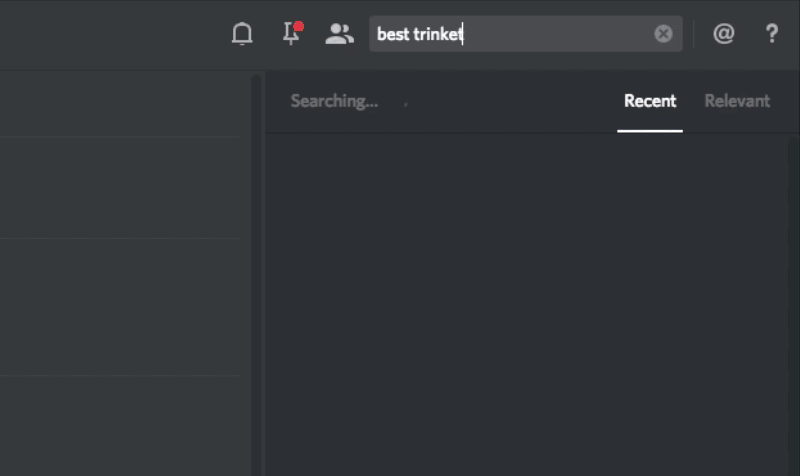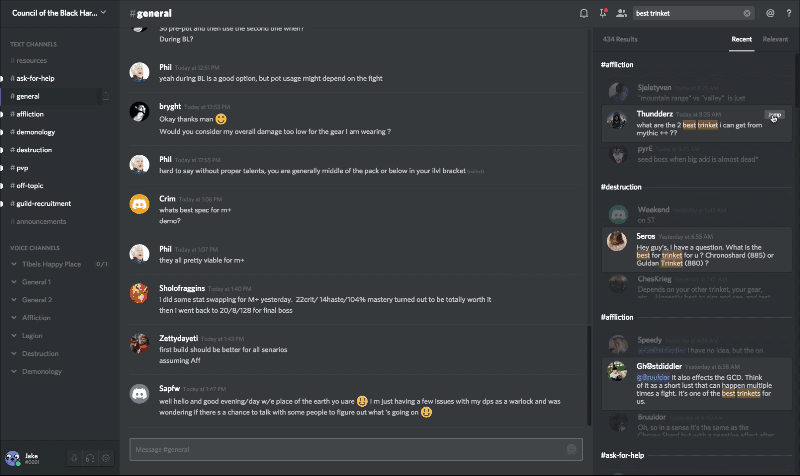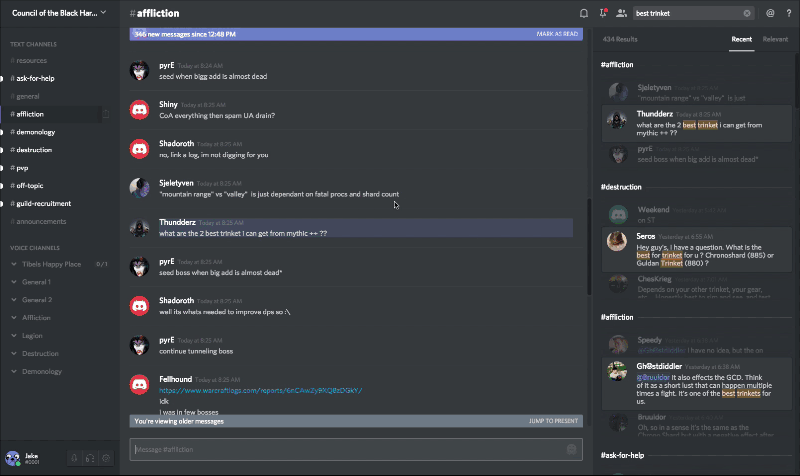
Требования
- Экономически эффективный: Основное взаимодействие пользователя с Discord — это наш текстовый и голосовой чат. Поиск — вспомогательная функция, и стоимость инфраструктуры должна отражать это. В идеале это значит, что поиск не должен стоить дороже, чем фактическое хранение сообщений.
- Быстрый и интуитивно понятный: Все создаваемые нами функции должны быть быстрыми и интуитивными, в том числе поиск. Он должен выглядеть и ощущаться по высшему стандарту.
- Самовосстановление: У нас нет отдела DevOps (пока), так что поиск должен выдерживать сбои с минимальным человеческим вмешательством или вообще без него.
- Линейно масштабируемый: Как и с хранением сообщений, увеличение ёмкости поисковой инфраструктуры должно предусматривать добавление нодов.
- Ленивая индексация: Не все пользуются поиском — мы не должны индексировать сообщения, пока кто-то не попытается хотя бы раз их найти. Вдобавок, после сбоя индекса должна быть возможность переиндексации серверов на лету.
Глядя на такие требования, мы задали себе два ключевых вопроса:
В. Можно передать поиск в управляемый SaaS? (простое решение)
О. Нет. Все рассмотренные нами решения управляемого поиска выходят за рамки нашего бюджета (на астрономическую сумму) для этой функции. Кроме того, нашим парням не очень нравится идея передачи сообщений за пределы нашего дата-центра. Осознавая риски, хочется сохранить контроль над безопасностью сообщений пользователей, а не доверяя это третьей стороне.
В. Есть подходящее нам open source решение для поиска?
О. Да! Мы всё изучили и после краткого обсуждения быстро пришли к выбору Elasticsearch vs Solr, поскольку обе системы могут вполне подойти для нашего случая. Elasticsearch имел преимущество:
- Обнаружение нодов в Solr требует ZooKeeper. У нас работает etcd, и мы не хотели множить инфраструктуру специально для Solr. А вот Zen Discovery в Elasticsearch самодостаточен.
- Elasticsearch поддерживает автоматическое восстановление равновесия шардов, что позволит добавлять новые ноды в кластер, тем самым «из коробки» выполняя наше требование о линейной масштабируемости.
- В Elasticsearch встроен структурированный DSL для запросов, а в Solr иначе пришлось бы программно создавать строку запросов, используя стороннюю библиотеку.
- У наших инженеров больше опыта работы с Elasticsearch.

Elasticsearch заработает?
Elasticsearch как будто подходит под все наши требования, и у наших инженеров есть опыт работы с ним. Он позволяет реплицировать данные между разными нодами, чтобы выдержать сбой каждой из них, масштабирует кластер добавлением новых нод и может проглатывать сообщения для индексации без устали. Но изучая тему, мы нашли несколько страшных рассказов об управлении большими кластерами Elasticsearch, а в реальности ни у кого из нашей группы бэкенда не было никакого опыта управления кластерами Elasticsearch, не считая нашей инфраструктуры для обработки логов.
Нам хотелось избежать проблем с громоздкими большими кластерами, и тут пришла идея делегировать шардинг и маршрутизацию на прикладной уровень, чтобы индексировать сообщения в пуле меньших кластеров Elasticsearch. Это означает ещё и то, что в случае отключения одного кластера для поиска станут недоступной только часть сообщений Discord, те, что находятся в выбывшем кластере. Это также даёт нам полезную возможность отказаться от данных целого кластера, если его невозможно восстановить (система лениво переиндексирует данные сервера в следующий раз, как только пользователь попытается поискать в них).
Компоненты
Elasticsearch любит индексировать документы в большом количестве. Это значит, что мы не можем индексировать сообщения по мере их публикации в реальном времени. Вместо этого мы спроектировали очередь, в которой воркер захватывает пачки сообщений и индексирует их едиными операциями. Мы решили, что небольшая задержка между публикацией сообщения и его доступностью для поиска является вполне разумным ограничением. В конце концов, большинство пользователей ищут сообщения, опубликованные в прошлом, а не только что сказанные.

На стороне приёма информации нужно было сделать пару вещей:
- Очередь сообщений: Нужно было сделать очередь, куда поступают все сообщения по мере публикации в онлайне (для разбора пулом воркеров).
- Воркеры индексации: Воркеры, которые делают реальную маршрутизацию и массовую вставку в Elasticsearch из очереди.
Мы ранее уже сделали систему постановки задач в очередь на базе Celedy, так что использовали её и для воркеров индексации истории.
- Воркеры индексации истории: Воркеры, в задачу которых входит перебор истории сообщений на заданном сервере и вставка в индекс Elasticsearch.
Нам ещё нужно было простое и быстрое картирование, какому кластеру Elasticsearch и индексу принадлежат сообщения каждого сервера Discord. Мы назвали эту пару «кластер + индекс» Шардом (не путать с нативными шардами Elasticsearch в индексе). Созданная нами система картирования состоит из двух слоёв:
- Постоянное картирование шардов: Его поместили в Cassandra, наше основное хранилище постоянных данных, как эталон.
- Кэш картирования шардов: При обработке сообщений воркерами запросы к Cassandra по поводу Шарда являются медленной операцией. Мы кэшируем эти карты в Redis, так что можем производить операции mget, чтобы быстро выяснить, куда маршрутизировать сообщение.
Если сервер индексируется впервые, тоже нужно выбрать, на какой Шард отправить сообщения этого сервера Discord. Поскольку Шарды являются абстракцией прикладного уровня, появляется возможность распределить их более интеллектуально. Используя мощь Redis, мы применили отсортированный набор для создания осведомлённого о загрузке распределителя шардов.
- Распределитель шардов: С помощью отсортированного набора в Redis мы храним набор Шардов с оценками, которые соответствуют их загрузке. Для ближайшего распределения выбирается шард, которому соответствует Шард с наименьшей оценкой. Эта оценка увеличивается при каждом распределении, а у каждого сообщения после индексации в Elasticsearch также есть вероятность увеличить оценку своего Шарда. Чем больше данных в Шарде, тем меньше шанс, что его выберут для распределения нового сервера Discord.
Конечно, вся поисковая инфраструктура была бы неполной без системы обнаружения кластеров и хостов с прикладного уровня.
- etcd: В других частях нашей системы используется etcd для обнаружения служб, так что мы применили его и для кластеров Elasticsearch. Ноды в кластере умеют сами объявлять о себе в etcd для всей остальной системы, так что не требуется намертво закреплять какие-то топологии Elasticsearch.
В конце концов, нужно было дать возможность клиентам реально искать сообщения.
- Search API: Программные интерфейсы, через которые приходят запросы от пользователей. Нужно было реализовать все проверки разрешений, чтобы пользователи могли искать только те сообщения, к которым имеют право доступа.

Индексирование и картирование данных
На действительно высоком уровне в Elasticsearch у нас есть концепция «индекса», внутри которого содержатся «шарды». В данном случае шард представляет собой индекс Lucene. Elasticsearch отвечает за распределение данных в индексе перед шардом, принадлежащим этому индексу. Если хотите, можно контролировать, как данные распределяются среди шардов, при помощи «ключа маршрутизации». В индексе также хранится «фактор репликации», который означает количество нодов, на которые индекс (и шарды в нём) должны быть реплицированы. Если нода, на которой располагается индекс, выходит из строя, то её реплицированная копия возьмёт нагрузку на себя. (Кстати, эти копии способны также обслуживать поисковые запросы, так что вы можете масштабировать пропускную способность поиска добавляя больше реплицированных копий).
Поскольку мы передали всю логику шардов на прикладной уровень (наши Шарды), то шардинг на стороне Elasticsearch в реальности не имел смысла. Однако мы могли использовать его для репликации и балансировки индексов между нодами в кластере. Чтобы Elasticsearch автоматически создавал индекс, используя правильную конфигурацию, мы использовали шаблон индекса, который содержит конфигурацию индекса и картирование данных. Конфигурация индекса достаточно проста:
- Индекс должен содержать только один шард (не делай за нас никакого шардинга)
- Индекс должен реплицироваться на одну ноду (выдерживать сбой основной ноды, несущей индекс)
- Индекс должен обновляться один раз в 60 минут (почему это пришлось сделать, объясним ниже)
- Индекс содержит единственный тип документа:
message
Хранение исходных данных сообщений в Elasticsearch не имело особого смысла, потому что в таком формате данных сообщения трудно поддаются поиску. Вместо этого мы решили взять каждое сообщение и преобразовать его в набор полей с метаданными, которые можно индексировать для поиска:
INDEX_TEMPLATE = { 'template': 'm-*', 'settings': { 'number_of_shards': 1, 'number_of_replicas': 1, 'index.refresh_interval': '3600s' }, 'mappings': { 'message': { '_source': { 'includes': [ 'id', 'channel_id', 'guild_id' ] }, 'properties': { # This is the message_id, we index by this to allow for greater than/less than queries, so we can search # before, on, and after. 'id': { 'type': 'long' }, # Lets us search with the "in:#channel-name" modifier. 'channel_id': { 'type': 'long' }, # Lets us scope a search to a given server. 'guild_id': { 'type': 'long' }, # Lets us search "from:Someone#0001" 'author_id': { 'type': 'long' }, # Is the author a user, bot or webhook? Not yet exposed in client. 'author_type': { 'type': 'byte' }, # Regular chat message, system message... 'type': { 'type': 'short' }, # Who was mentioned, "mentions:Person#1234" 'mentions': { 'type': 'long' }, # Was "@everyone" mentioned (only true if the author had permission to @everyone at the time). # This accounts for the case where "@everyone" could be in a message, but it had no effect, # because the user doesn't have permissions to ping everyone. 'mention_everyone': { 'type': 'boolean' }, # Array of [message content, embed title, embed author, embed description, ...] # for full-text search. 'content': { 'type': 'text', 'fields': { 'lang_analyzed': { 'type': 'text', 'analyzer': 'english' } } }, # An array of shorts, specifying what type of media the message has. "has:link|image|video|embed|file". 'has': { 'type': 'short' }, # An array of normalized hostnames in the message, traverse up to the domain. Not yet exposed in client. # "http://foo.bar.com" gets turned into ["foo.bar.com", "bar.com"] 'link_hostnames': { 'type': 'keyword' }, # Embed providers as returned by oembed, i.e. "Youtube". Not yet exposed in client. 'embed_providers': { 'type': 'keyword' }, # Embed type as returned by oembed. Not yet exposed in client. 'embed_types': { 'type': 'keyword' }, # File extensions of attachments, i.e. "fileType:mp3" 'attachment_extensions': { 'type': 'keyword' }, # The filenames of the attachments. Not yet exposed in client. 'attachment_filenames': { 'type': 'text', 'analyzer': 'simple' } } } } }Можете заметить, что в набор полей мы не включили метку времени, и если помните из нашего прошлого поста, наши ID созданы в формате Snowflake, то есть по своей сути содержат метку времени (которую можно использовать для реализации функции выбора результатов поиска по времени, выбирая соответствующий диапазон ID).
Однако эти поля не «хранятся» в таком виде в Elasticsearch, скорее, они хранятся только в инвертированном индексе. Единственные реально хранящиеся и возвращаемые поля — это сообщение, канал и ID сервера, на котором было опубликовано сообщение. Это значит, что данные сообщений не дублируются в Elasticsearch. Компромисс в том, что нам придётся забирать данные из Cassandra при возвращении результатов поиска, но это абсолютно нормально, потому что нам бы в любом случае пришлось забирать из Cassandra контекст сообщения (два сообщения до и после) для отображения в интерфейсе. Хранение реального объекта сообщения вне Elasticsearch означает, что нам не нужно тратить на него дополнительное дисковое пространство. Однако это означает также, что мы не можем использовать Elasticsearch для подсветки совпадений в результатах поиска. Придётся встроить токенайзеры и лингвистические анализаторы в клиенсткую программу для подсветки совпадений (что было действительно легко сделать).
Реализация
Мы решили, что микросервис для поиска, вероятно, не требуется — а вместо этого выставили для Elasticsearch библиотеку, в которую была обёрнута логика маршрутизации и запросов. Понадобилось запустить только единственный дополнительный сервис — это воркеры индексирования (которые будут использовать эту библиотеку, чтобы делать реальную работу по индексированию). Часть программных интерфейсов, выставленная для остальной команды, была тоже минимальна, так что если бы понадобилось перейти на собственный сервис, её можно было бы легко обернуть в слой RPC. Библиотеку можно импортировать в наши API-воркеры, и она может реально выполнять поисковые запросы и возвращать результаты пользователю по HTTP.
Для остальной команды библиотека показывает минимальную часть для поиска сообщений:
results = router.search(SearchQuery( guild_id=112233445566778899, content="hey jake", channel_ids=[166705234528174080, 228695132507996160] )) results_with_context = gather_results(results, context_size=2)Постановка сообщения в очередь для индексации или удаления:
# When a message was created or updated: broker.enqueue_message(message) # When a message was deleted: broker.enqueue_delete(message)Массовое индексирование сообщений (почти) в реальном времени воркером:
def gather_messages(num_to_gather=100): messages = [] while len(messages) < num_to_gather: messages.append(broker.pop_message()) return messages while True: messages = gather_messages() router.index_messages(messages)Для индексирования старых сообщений на сервере создаётся задание исторической индексации, которое осуществляет единицу работы и создаёт новое задание для продолжения индексации этого сервера. Каждое задание представляет собой указатель на место в истории сообщений сервера и фиксированную единицу объёма индексации (в данном случае по умолчанию установленную на 500 сообщений). Задание возвращает новый указатель на следующую пачку сообщений для индексации или значение None, если больше нечего делать. Чтобы быстро получить результаты для большого сервера, мы разбили историческую индексацию на две фазы: «начальная» и «глубокая». В «начальной» фазе индексируются сообщения за последние 7 дней — и индекс становится доступен для пользователей. После этого мы начинаем «глубокую» фазу, которая исполняется с низким приоритетом. В этой статье объясняется, как это выглядит для пользователя. Задания исполняются в пуле воркеров, что позволяет планировать их среди прочих заданий, которые выполняют воркеры. Это выглядит примерно так:
@task() def job_task(current_job) # .process returns the next job to execute, or None if there are no more jobs to execute. next_job = current_job.process(router) if next_job: job_task.delay(next_job, priority=LOW if next_job.deep else NORMAL) initial_job = HistoricalIndexJob(guild_id=112233445566778899) job_task.delay(initial_job)
Тестирование в продакшне

После кодирования всего вышеперечисленного и тестирования в среде разработки мы решили, что пришло время посмотреть, как оно работает в продакшне. Мы подняли единственный кластер Elasticsearch с тремя нодами, запустили воркеров индексации и назначили для индексации 1000 крупнейших серверов Discord. Всё вроде работало, но когда мы посмотрели на показатели кластера, то заметили две вещи:
- Использование CPU оказалось выше, чем мы ожидали.
- Потребление дискового пространства росло слишком быстро для того объёма сообщений, которое реально проиндексировалось.
Это нас довольно сильно удивило, и продолжив какое-то время работу с использованием слишком большого объёма дискового пространства мы отменили задания индексации и решили разобраться на следующий день. Что-то явно было не в порядке.
Когда мы вернулись на утро, то заметили ЗНАЧИТЕЛЬНОЕ высвобождение дискового пространства. Неужели Elasticsearch выбросил наши данные? Мы попробовали запустить поисковый запрос на одном из наших серверов, который был проиндексирован и где был зарегистрирован один из наших сотрудников. Есть! Результаты отлично возвращались — и очень быстро! Что за дела?
Использование дискового пространства быстро растёт, а потом сокращается
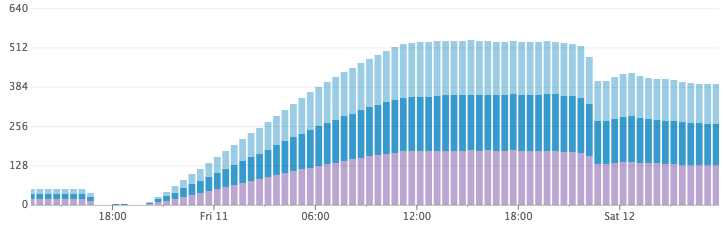
Нагрузка на CPU
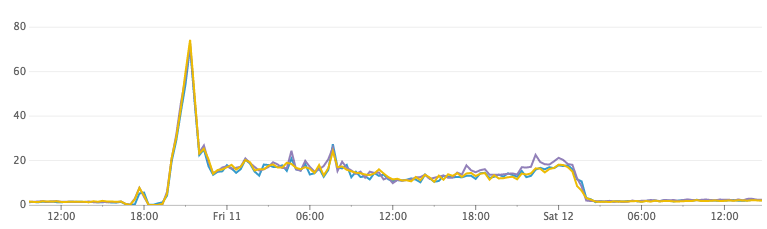
После небольшого расследования у нас появилась гипотеза! По умолчанию Elasticsearch обновляет индекс 1 раз в секунду. Это то что обеспечивает поиск «почти в реальном времени». Каждую секунду (в каждом из тысяч индексов) Elasticsearch заполнял буфер в памяти сегментом Lucene и открывал его, чтобы сделать доступным для поиска. За ночь во время простоя Elasticsearch объединил большое количество маленьких фрагментов и сгенерировал гораздо бóльшие фрагменты (и намного более эффективные по дисковому пространству).
Проверка гипотезы была довольно простой. Мы сбросили все индексы в кластере, установили интервал обновления на произвольно большое число, а затем назначили для индексации те же самые серверы. Использование CPU упало до ничтожных значений, в то время как документы продолжали обрабатываться, а потребление дискового пространства не росло угрожающе высокими темпами. Ура!
Использование дискового пространства после увеличения интервала обновления
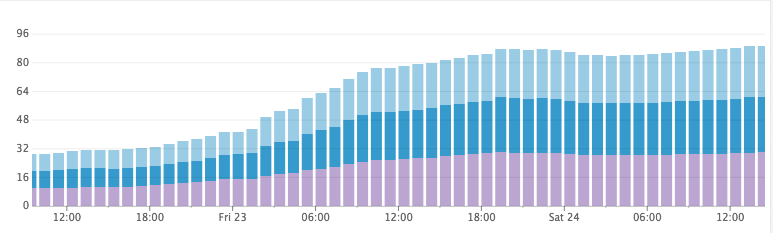
Нагрузка на CPU
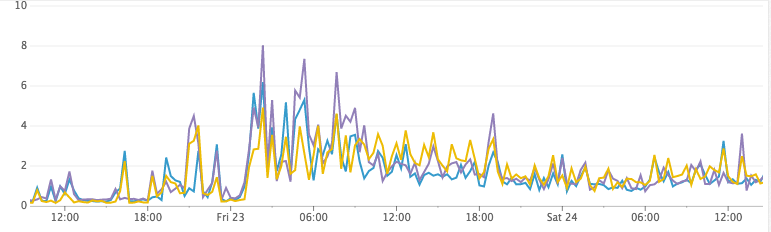
К сожалению, однако, полное отключение интервала обновления не сработало на практике…
Беды с интервалом обновления
Стало очевидно, что автоматическая функция индексации почти в реальном времени Elasticsearch не удовлетворяет нашим нуждам. Бывает, что сервер часами работает без единого поискового запроса. Нам нужно было найти способ управления интервалом обновления из прикладного слоя. Мы сделали это с помощью устаревающей хэш-карты на Redis. Поскольку серверы Discord разделены шардами на общие индексы в Elasticsearch, мы можем построить быструю карту, которая изменяется вместе с индексом и отслеживает, нуждается ли индекс в обновлении — в зависимости от сервера, на котором вы осуществляете поиск. Структура данных простая: ключ Redis, хранящий хэш-карту, prefix + shard_key, к хэш-карте значений guild_id, к сигнальному значению, которое говорит о том, что индекс нужно обновить. В ретроспективе, вероятно, это могло бы быть множество.
Цикл индексации превращается в такое:
- Взять N сообщений из очереди.
- Выяснить, куда нужно направить эти сообщения, по их
guild_id. - Выполнить операцию массовой вставки в соответствующие кластеры.
- Обновить карту Redis, обозначив, что шард и обновлённые
guild_idна Шарде стали грязными. Этот ключ должен истечь через 1 час (Elasticsearch к тому времени совершит автоматическое обновление).
А цикл поиска превратился в такое:
- Найти Шард, на котором нужно запросить
guild_id. - Проверить карту Redis на предмет того, что Шард, А ТАКЖЕ
guild_id, грязные. - Если грязные, то провести обновление индекса Elasticsearch для Шарда, и обозначить целый Шард как чистый.
- Выполнить поисковый запрос и вернуть результаты.
Можете заметить, что хотя мы сейчас явно контролируем логику обновления Elasticsearch, у нас всё равно основной индекс обновляется каждый час. Если в картах Redis произойдёт потеря данных, то система максимум за час скорректируется автоматически.
Будущее
С момента развёртывания в январе наша инфраструктура Elasticsearch выросла до 14 нод в двух кластерах, используя типы инстансов n1-standard-8 на GCP с накопителями Provisioned SSD на 1 ТБ на каждом. Общее количество документов — почти 26 млрд. Скорость индексирования достигает пиковых значений примерно 30 000 сообщений в секунду. Elasticsearch справляется с этим без усилий, сохранив показатель 5-15% CPU на протяжении всего срока развёртывания нашего поиска.
До сих пор мы добавляли ноды в кластеры без труда. В какой-то момент мы развернём новые кластеры, так что новые индексируемые серверы Discord попадут туда (благодаря нашей автоматической системе распределения шардов). В существующих кластерах понадобится ограничить число главных избранных нод по мере того, как мы добавим больше нод с данными в кластер.

Мы также наткнулись на четыре основных показателя, которые используем для определения, когда следует увеличить кластер:
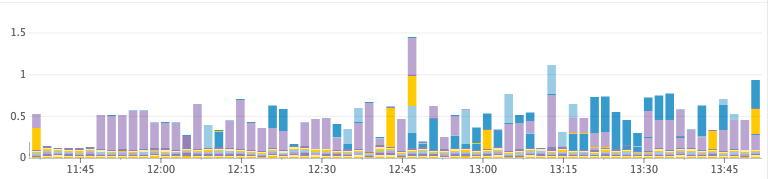
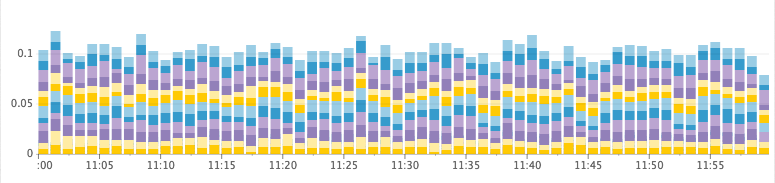
- heap_free: (aka heap_committed — heap_used). Когда у нас заканчивается место в куче, JVM вынуждена остановиться, чтобы сборщик мусора быстро освободил пространство. Если он не может освободить достаточно пространства, то происходит сбой ноды. Перед этим JVM входит в состояние, когда она непрерывно останавливается, потому что куча переполнена, и во время каждого прохода сборщика мусора высвобождается слишком мало памяти. Мы отслеживаем это вместе со статистикой сборщика мусора, чтобы проверять, сколько времени тратится на сборку мусора.
- disk_free: Очевидно, нужно добавлять новые ноды, когда заканчивается место на диске или требуется больше места для индексации новых документов. Это очень легко делается на GCP, поскольку мы можем просто увеличить дисковое пространство без перезагрузки инстанса. Выбор между добавлением новой ноды или изменением размера диска зависит от других параметров, упомянутых здесь. Например, если использование дискового пространства на высоком уровне, но остальные показатели в норме, то мы выберем расширение дискового пространства, а не добавление новой ноды.
- cpu_usage: Если мы достигли порогового значения использования CPU в пиковые часы.
- io_wait: Если операции ввода-вывода в кластере стали слишком медленными.
Нездоровый кластер (заканчивается куча)
Свободная куча (МиБ)
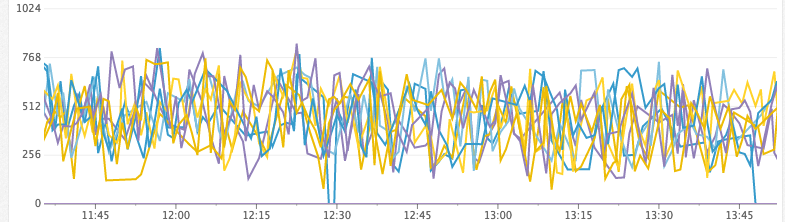
Время на сборку мусора, GC в секунду
Здоровый кластер
Свободная куча (ГиБ)
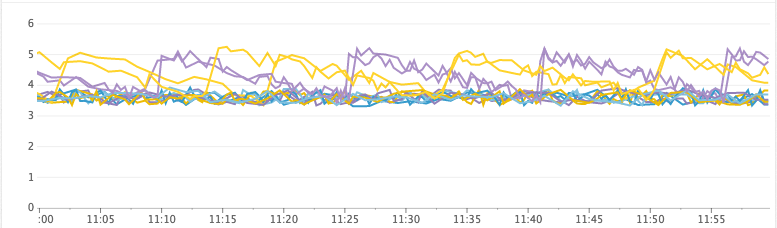
Время на сборку мусора, GC в секунду
Заключение
Прошло чуть больше трёх месяцев с того момента, когда мы запустили функцию поиска, и с тех пор система работает практически или вообще без проблем.
Elasticsearch показал стабильную и уверенную производительность от 0 до 26 млрд документов на примерно 16 000 индексах и миллионах серверов Discord. Мы продолжим масштабирование, добавляя новые кластеры или больше нод в существующие кластеры. В какой-то момент мы можем подумать о написании кода, который позволит переносить индексы между кластерами как способ снизить нагрузку на кластер или выделить серверу Discord собственный индекс, если это исключительно болтливый сервер (хотя наша система шардинга с распределением весов хорошо справляется, так что тяжёлые серверы Discord и так обычно получают собственные шарды).
Мы набираем сотрудников, так что обращайтесь, если подобные задачки щекочут ваше воображение.
ссылка на оригинал статьи https://habrahabr.ru/post/324902/
Добавить комментарий