Однажды томным вечером, сидя напротив мелькающей ленты tjournal и попивая ромашковый чай, внезапно обнаружил себя за чтением статьи про советскую лампочку, которая освещала чей-то подъезд уже 80 лет. Да, весьма интересно, но все же я предпочитаю статьи про политику достижения ИИ в игре дум, приключения ракет SpaceX и, в конце концов, — с наибольшим кол-вом просмотров. А какие вообще статьи набирают внушительные рейтинги? Посты размером с твит про какую-то политическую акцию или же талмуды с детальным анализом российской киноиндустрии? Ну что же, тогда самое время расчехлять свой Jupyter notebook и выводить формулу идеальной статьи.

Итак, задача стоит такая — предсказать кол-во просмотров статьи, исходя из ее содержания. Для реализации всего этого будем использовать Python 3.*, стандартный сет из библиотек для машинного обучения и обработки данных (pandas, numpy, scipy, scikit-learn), а писать и запускать все это будем в Jupyter notebook. Ссылка на все исходники тут.
Сбор базы
Для начала работы стоит раздобыть данные. Поскольку TJ не имеет своего API, то и собирать статьи будем старым добрым скрапингом голого html с помощью requests и вытаскиванием из него полезных данных с помощью BeautifulSoup. На выходе мы получаем 39116 статей с 2014 года. Однако стоит отметить, что сама статья записывается в виде html блока со всеми присущими ей кучей тэгов, а не как простой текст. Сам скрипт тут.
Feature Engineering
После часа работы скрипта у нас на руках есть почти 39000 статей, и пришло время вытаскивать из них фичи всех степеней важности. Но сначала импортируем все необходимое:
import json import datetime import numpy as np import pandas as pd import snowballstemmer from bs4 import BeautifulSoup import itertools from scipy.sparse import csr_matrix, hstack from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer from sklearn.cross_validation import train_test_split from sklearn.decomposition import LatentDirichletAllocation from gensim.models import Word2Vec import lightgbm as lgb from sklearn.metrics import r2_score, mean_absolute_error import seaborn as sns import matplotlib.pyplot as plt %matplotlib inline
Читаем наш датасет и смотрим его содержимое:
dataframe = pd.read_json("data/tj_dataset.json") dataframe.head()
Поскольку из доступных данных для тренировки мы имеем только контент поста и дату публикации, то и большая часть инженеринга фич будет крутиться вокруг текстовых данных. Из самого поста можно выудить два типа фич: структурные и смысловые (да-да, названия придумал сам). К структурным относятся те, которые, не поверите, определяют структуру поста: кол-во ссылок на ютуб, на твиттер, кол-во слов в названии поста, среднее кол-во слов в текстовых блоках и т.п. Все значения, которые не удалось выловить (обычно из-за малого кол-ва текстовых данных), просто заменям на -9999, градиентный бустинг нас поймет.
Начнем с временных фич. И тут все как нельзя просто — вытаскиваем год, месяц, день, часы и минуты, из инженеринга фич тут только день недели:
def get_time(x): time = x.split()[-1] h, m = time.split(":") return int(h)*60 + int(m) m_keys = { 'января': 1, 'февраля': 2, 'марта': 3, 'апреля': 4, 'мая': 5, 'июня': 6, 'июля': 7, 'августа': 8, 'сентября': 9, 'октября': 10, 'ноября': 11, 'декабря': 12, }
dataframe['month'] = dataframe.date.apply(lambda x: m_keys[x.split()[1]]) dataframe['time'] = dataframe.date.apply(get_time) dataframe['day'] = dataframe.date.apply(lambda x: int(x.split()[0])) dataframe['year'] = dataframe.date.apply(lambda x: int(x.split()[2][:-1])) dataframe["weekday"] = dataframe[["year", "month", "day"]].apply(lambda x: datetime.date(*x).weekday(), axis=1)
А вот теперь началась самая творческая часть работы, где можно дать волю фантазии и собрать из текстов все, что душе угодно.
Для начала стоит вытащить из html блока голые куски текста, токенизировать их и пропустить через стеммер полученные слова:
stemmer = snowballstemmer.RussianStemmer() rus_chars = set([chr(i) for i in range(1072, 1104)]) def tokenize_sent(sent): sent = sent.lower() sent = "".join([i if i in rus_chars else " " for i in sent]) words = stemmer.stemWords(sent.split()) return words
Недолго думая, к списку фич добавляем кол-во слов в посте и заголовке, кол-во html тэгов, среднее и среднеквадратичное отколнение кол-ва слов в блоках. Посты на tj пестрят картинками, видео, референсами на твиттер и ссылками на другие ресурсы, что также можно использовать:
def get_p_data(article): html = BeautifulSoup(article, "lxml") data = html.findAll("p") return [i.text for i in data] def get_p_count(article): html = BeautifulSoup(article, "lxml") data = html.findAll("p") return len(data) def get_p_sizes(article): html = BeautifulSoup(article, "lxml") data = html.findAll("p") return [len(preprocess_sent(i.text)) for i in data] def get_tags_count(article): html = BeautifulSoup(article, "lxml") data = html.findAll() return len(data) def mean_p(x): if not len(x): return -9999 return np.mean(x) def std_p(x): if not len(x): return -9999 return np.std(x)
dataframe['p_list'] = dataframe.article.apply(get_p_data) dataframe['text_chained'] = dataframe.p_list.apply(lambda x: "\n".join(x)) dataframe['p_list_tokenized'] = dataframe.p_list.apply(lambda x: [tokenize_sent(i) for i in x]) dataframe['p_list_tokenized_joined'] = dataframe.p_list_tokenized.apply(lambda x: list(itertools.chain(*x))) dataframe['title_tokenized'] = dataframe.title.apply(tokenize_sent) dataframe['images_count'] = dataframe.article.apply(lambda x: x.count("wrapper-image")) dataframe['wide_labels_count'] = dataframe.article.apply(lambda x: x.count("wrapper-wide")) dataframe['link_widget_count'] = dataframe.article.apply(lambda x: x.count("link-widget")) dataframe['links_count'] = dataframe.article.apply(lambda x: x.count("a href")) - \ (dataframe.images_count + dataframe.link_widget_count) dataframe['youtube_count'] = dataframe.article.apply(lambda x: x.count("wrapper-video")) dataframe['tweets_count'] = dataframe.article.apply(lambda x: x.count("wrapper-tweet")) dataframe["tags_count"] = dataframe.article.apply(get_tags_count) dataframe["p_count"] = dataframe.p_list.apply(len) dataframe["text_sizes"] = dataframe.p_list_tokenized.apply(lambda x: [len(i) for i in x]) dataframe["text_sizes_mean"] = dataframe.text_sizes.apply(mean_p) dataframe["text_sizes_std"] = dataframe.text_sizes.apply(std_p) dataframe["text_words_count"] = dataframe.p_list_tokenized.apply(lambda x: len(list(itertools.chain(*x)))) dataframe["title_words_count"] = dataframe.title_tokenized.apply(lambda x: len(x))
Вот с семантическими фичами дело обстоит сложнее. И первое, что приходит на ум: tf-idf — классика в обработке текстовых данных. Но один лишь tf-idf не внушает доверия, так что подключим еще Latent Dirihlet Allocation (LDA) для уменьшения размерности поста до 10-50-и элементного вектора. На всякий случай попробуем взять три LDA по 10, 20 и 50 топиков соответственно.
count_vec = CountVectorizer(tokenizer = tokenize_sent, min_df=10, max_df=0.95) text_count_vec = count_vec.fit_transform(dataframe.text_chained) text_tfidf_vec = TfidfTransformer().fit_transform(text_count_vec).toarray() lda_features = [] topic_counts = [10, 20, 50] for topics in topic_counts: lda = LatentDirichletAllocation(topics, n_jobs=7, learning_method="batch") feats = lda.fit_transform(text_count_vec) lda_features.append(feats) lda_features = np.concatenate(lda_features, axis=1)
Можно ли что-то еще интересное добавить? Разумеется, word2vec:
w2v = Word2Vec(dataframe.p_list_tokenized_joined, size=300, workers=7, min_count=5) w2v_dict = {key:w2v.wv.syn0[val.index] for key, val in w2v.wv.vocab.items()} vectors = list(w2v_dict.values()) words = list(w2v_dict.keys()) words_set = set(words)
На выходе у нас есть куча векторов слов по 300 элементов в каждом. Теперь нужно их как-то использовать для векторизации поста. Для этого можно использовать 2 техники: вычисление среднего вектора среди всех векторов слов и более сложная, с использованием кластеров.
С первой все понятно — есть матрица c векторами слов, просто берем среднее значение по первой оси, алгоритм обработки пустых постов примерно такой же, как выше :
def get_mean_vec(sent): matrix = [w2v_dict[i] for i in sent if i in words_set] if not matrix: return np.full((300,), -9999) return np.mean(matrix, axis=0)
Со второй нужно построить некоторое кол-во кластеров по всем векторам слов и затем присвоить каждому слову в тексте принадлежность к тому или иному кластеру, т.е. получится что-то вроде CountVectorizer-а на стероидах. Так же, как и в случае с LDA, попробуем взять несколько KMeans с разным кол-вом кластеров:
kmeans = [] clusters_counts = [10, 50, 100, 500, 1000] for clusters in clusters_counts: kmeans.append(KMeans(clusters, precompute_distances=True, n_jobs=7).fit(vectors))
word_mappings = [] for kmean in kmeans: labels = kmean.labels_ word_mappings.append(dict(zip(words, labels))) def get_centroids_vec(sent): words = [i for i in sent if i in words_set] if not words: return np.full((sum(clusters_counts),), -9999) result_total = np.asarray([]) for cnt, mapper in zip(clusters_counts, word_mappings): result = np.zeros((cnt, )) for word in words: result[mapper[word]] += 1 result_total = np.concatenate([result_total, result]) return result_total
mean_texts = np.asarray([get_mean_vec(s) for s in dataframe.p_list_tokenized_joined.tolist()]) mean_titles = np.asarray([get_mean_vec(s) for s in dataframe.title_tokenized.tolist()]) clusters_texts = np.asarray([get_centroids_vec(s) for s in dataframe.p_list_tokenized_joined.tolist()]) clusters_titles = np.asarray([get_centroids_vec(s) for s in dataframe.title_tokenized.tolist()])
Все фичи собрали, осталось только скомпоновать их вместе в одну большую матрицу:
feats = ["time", "day", "weekday", "month", "images_count", "wide_labels_count", "link_widget_count", "links_count", "youtube_count", "tweets_count", "tags_count", "p_count", "text_sizes_mean", "text_sizes_std", "text_words_count", "title_words_count"] X = dataframe[feats].as_matrix() preprocessed_df = np.concatenate([X, mean_texts, mean_titles, lda_features, clusters_texts, clusters_titles], axis=1) full_df = hstack([csr_matrix(preprocessed_df), text_tfidf_vec]).tocsr()
Тренировка модели
Поскольку у нас здесь есть кол-во просмотров и рейтинг, то тут прям напрашивается задача регрессии. А если у нас регрессия, то стоит проверить целевые значения на предмет скоса их распределения направо-налево:
dataframe.hits.hist(bins=200)

Ну что же, вполне ожидамо — такое обычно лечится либо логарифмом:
dataframe.hits.apply(np.log).hist(bins=200)
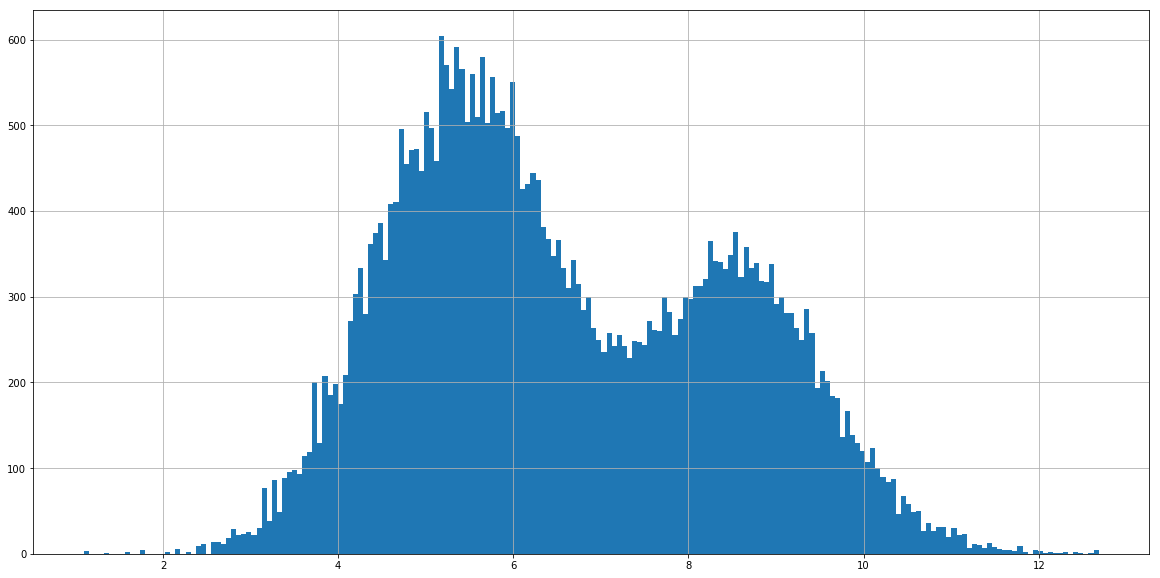
Уже намного лучше, хоть немного и смущают эти две горы. Но это еще не все, ведь с каждым месяцем количесво подписчиков на tj возрастает, а это значит, что возрастает и кол-во просмотров. Т.е. нужно как-то нормализовать кол-во просмотров, при этом минимизируя влияние выбросов. Для нормализации одного поста можно взять среднее и среднеквадратичное отклонение из предыдущих 200 постов, скалировать текущее значение, при этом убрав все, что находится за первой и 99-ой перцентилями:
hits_y = dataframe.hits step = 200 new_hits = [] for i in range(step, dataframe.shape[0]): hits = hits_y.iloc[i-step: i+1] perc_high = np.percentile(hits, 99) perc_low = np.percentile(hits, 1) hits = hits[(hits > perc_low)&(hits < perc_high)] mean = hits.mean() std = hits.std() val = max(min(hits_y.iloc[i], perc_high), perc_low) new_hits.append((val - mean)/std) hits_y = np.asarray(new_hits) full_df = full_df[step:] min_val = hits_y.min() hits_log = np.log(hits_y - min_val+1e-6)
Самое сложное позади, осталось только выбрать модель, поставить ее на обучение и молиться на правильный выбор гиперпараметров. Обычно над выбором модели долго не заморачиваются и сразу берут xgboost, что имеет смысл, ибо он уже завоевал свою популярность на kaggle и повсеместно используется как новичками, так и гуру. Но однажды, случайно наткнувшись на сравнение бенчмарков двух реализаций градиентного бустинга, меня привлек внимание LigthGBM от Microsoft своими аппетитными результатами тестов, которые и заставили отложить старичка xgboost как запасной вариант.
В целом, тренировка проходит так же, как и на xgboost — тыкаем туда-сюда max_depth и регуляризацию для избежания оверфита, подбираем наилучшее кол-во деревьев под допустимо минимальный learning_rate.
Датасет для LigthGBM необходимо для начала привести в местный формат:
features = (feats + list(itertools.chain(*[[f"lda_{lda}_{i}" for i in range(lda)] for lda in topic_counts])) + [f"mean_matrix_body_{i}" for i in range(300)] + [f"mean_matrix_title_{i}" for i in range(300)] + list(itertools.chain(*[[f"clusters_body_{i}_{j}" for j in range(i)] for i in clusters_counts])) + list(itertools.chain(*[[f"clusters_title_{i}_{j}" for j in range(i)] for i in clusters_counts])) + [f"tf_idf_{i}" for i in range(text_tfidf_vec.shape[1])])
X_train, X_test, y_train, y_test = train_test_split(full_df, hits_log, test_size=0.2, random_state=753) train_data = lgb.Dataset(X_train, label=y_train, feature_name=features) test_data = train_data.create_valid(X_test, label=y_test)
Параметры градиентного бустинга (получены после долгих часов тренировок):
param = {'num_trees': 100000, 'application':'regression', 'learning_rate': 0.01, 'num_threads': 7, 'max_depth': 10, 'lambda_l2': 1e-3} param['metric'] = 'mae'
Непосредственно сама тренировка:
bst = lgb.train(param, train_data, param['num_trees'], valid_sets=[test_data], early_stopping_rounds=200)
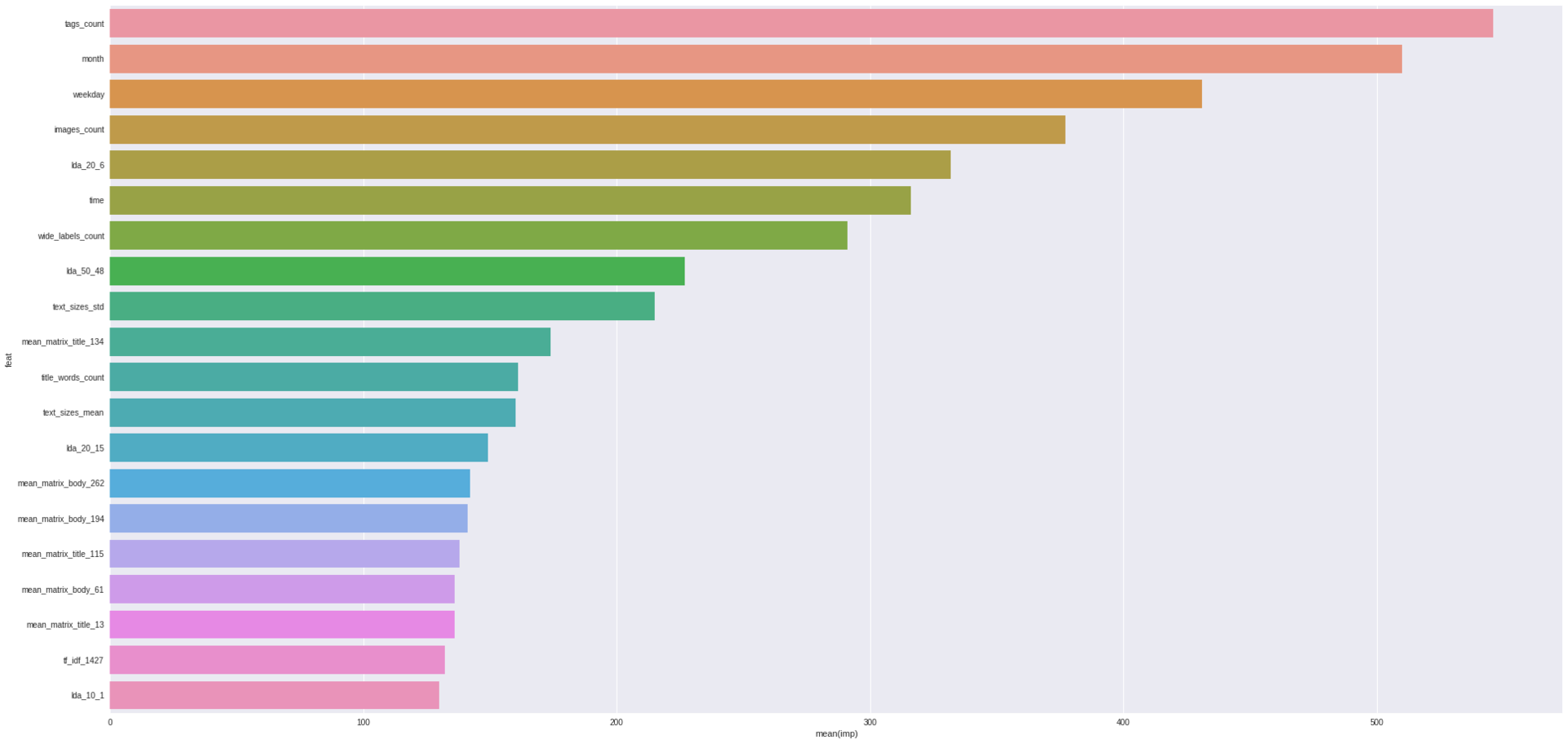
Важной особенностью деревьев является то, что есть возможность оценить важность фич:
importance = sorted(zip(features, bst.feature_importance()), key=lambda x: x[1], reverse=True) for imp in importance[:20]: print("Feature '{}', importance={}".format(*imp))
Feature 'tags_count', importance=546 Feature 'month', importance=510 Feature 'weekday', importance=431 Feature 'images_count', importance=377 Feature 'lda_20_6', importance=332 Feature 'time', importance=316 Feature 'wide_labels_count', importance=291 Feature 'lda_50_48', importance=227 Feature 'text_sizes_std', importance=215 Feature 'mean_matrix_title_134', importance=174 Feature 'title_words_count', importance=161 Feature 'text_sizes_mean', importance=160 Feature 'lda_20_15', importance=149 Feature 'mean_matrix_body_262', importance=142 Feature 'mean_matrix_body_194', importance=141 Feature 'mean_matrix_title_115', importance=138 Feature 'mean_matrix_body_61', importance=136 Feature 'mean_matrix_title_13', importance=136 Feature 'tf_idf_1427', importance=132 Feature 'lda_10_1', importance=130
importance = pd.DataFrame([{"imp": imp, "feat": feat} for feat, imp in importance]) sns.barplot(x="imp", y="feat", data=importance.iloc[:20])
И вот наши результаты:
predictions = bst.predict(X_test) print("r2 score = {}".format(r2_score(y_test, predictions))) print("mae error = {}".format(mean_absolute_error(y_test, predictions)))
r2 score = 0.3166155559972065 mae error = 0.4209721870443455
Итоги
C такими параметрами и фичами точность по r2 score получилась 0.317, а по absolute mean error — 0.42. Хороший ли это результат? Вполне неплохо даже с учетом того, что существуют еще пути для улучшения модели. Например, попробовать нейросети (как реккурентные, так и сверточные, с Embedding слоем и весами word2vec), к LDA добавить еще PCA, NMF и прочую декомпозицию, в конце концов, попробовать выделить другие фичи из разряда "отношение кол-ва пунктуации к кол-ву переносов строк". Но дальнейшие изыскания уже оставляю вам.
ссылка на оригинал статьи https://habrahabr.ru/post/327072/
Добавить комментарий