Привет, Хабр!
Сегодня мы хотели бы поднять проблему нагрузочной балансировки в Облаке, а точнее обсудить новый подход к принятию решения о живой миграции виртуальных машин между хостами, предложенный Дорианом Минаролли, Артаном Мазрекай и Берндом Фрайслебеном в их исследовании «Tackling uncertainty in long-term predictions for host overload and underload detection in cloud computing». Вольный перевод этой статьи мы сегодня публикуем.
Абстрагируясь от особенностей облачных вычислений, данный подход может быть применён при решении проблем нагрузочной балансировки в других системах. Поэтому надеемся, статья будет интересна широкому кругу читателей.

Динамическими рабочими нагрузками в облачных вычислениях можно управлять с помощью живой миграции виртуальных машин с перегруженных или недогруженных хостов на другие узлы для экономии электроэнергии и снижения потерь за нарушение соглашения об уровне обслуживания (SLA). Проблемой является верное определение момента перегрузки хоста в будущем для своевременного проведения живой миграции.
Введение
Облачные вычисления — многообещающий подход, при котором ресурсы предоставляются в виде услуги, могут быть сданы в аренду и предоставлены пользователям через сеть по запросу. Одной из широко используемых бизнес-моделей облачных вычислений является инфраструктура как сервис (IaaS). Вычислительные ресурсы предоставляются в виде виртуальных машин (далее VM) пользователям, которые платят за потреблённые ресурсы. Средства виртуализации, такие как Xen и VMware, позволяют эффективно использовать инфраструктурные ресурсы. Виртуальные машины дают возможность распределять ресурсы динамически в соответствии с требованиями, оптимизируя производительность приложений и потребление электроэнергии.
Одной из основных возможностей для динамического перераспределения ресурсов является живая миграция виртуальных машин. Она позволяет облачным провайдерам перемещать виртуальные машины с перегруженных хостов, поддерживая их производительность при заданном SLA и динамически консолидировать виртуальные машины на наименьшем числе хостов, чтобы экономить электроэнергию при низкой загрузке. Используя «живую» миграцию и применяя онлайн-алгоритмы, которые позволяют принимать решения о миграции в реальном времени, можно эффективно управлять облачными ресурсами, адаптируя распределение ресурсов к нагрузкам VM, поддерживая уровни производительности VM в соответствии с SLA и снижая энергопотребление инфраструктуры.
Важной проблемой в контексте живой миграции является обнаружение состояния перегрузки или недогрузки хоста. Большинство современных подходов основаны на мониторинге использования ресурсов, и, если фактическое или прогнозируемое следующее значение превышает заданный порог, узел объявляется перегруженным. Тем не менее, живая миграция имеет свою цену, обоснованную нарушением производительности VM в процессе миграции. Проблема с существующими подходами заключается в том, что обнаружение перегрузки хоста по одному замеру использования ресурсов или нескольким будущим значениям может привести к поспешным решениям, излишним накладным расходам на живую миграцию и проблемам со стабильностью VM.
Более перспективным является подход принятия решений о живой миграции на основе прогнозов использования ресурсов на несколько шагов вперед. Это не только повышает стабильность, так как миграционные действия начинаются только когда нагрузка сохраняется в течение нескольких временных интервалов, но также позволяет облачным провайдерам прогнозировать состояние перегрузки до того, как это произойдёт. С другой стороны, прогнозирование более отдалённого будущего увеличивает ошибку прогнозирования и неопределенность, уменьшая при этом преимущества долгосрочного прогнозирования. Ещё одна важная проблема заключается в том, что живая миграция должна выполняться только в том случае, если штраф за возможные нарушения SLA превышает накладные расходы на миграцию.
В этой статье представлен новый подход к обнаружению перегруженности или недогруженности хоста, основанный на долгосрочных прогнозах использования ресурсов, которые учитывают неопределенность в прогнозировании и накладные расходы живой миграции. Сделано следующее:
- Представлен новый подход к динамическому распределению ресурсов для виртуальных машин в облачной среде. Он объединяет локальное и глобальное распределение ресурсов виртуальных машин. Локальное распределение ресурсов означает выделение общих ресурсов хоста для виртуальных машин в соответствии с текущей нагрузкой. Глобальное распределение ресурсов равносильно живой миграции, в случае перегрузки или недогрузки хоста, с целью обеспечения достаточной производительности VM или уменьшение количества хостов для экономии электроэнергии.
- Предложен новый подход, основанный на долгосрочных прогнозах использования ресурсов, с целью определить, когда узел перегружен или недогружен. Для долгосрочных прогнозов используется машинное обучение с учителем, основанное на гауссовских процессах.
- Для учёта неопределенности долгосрочных прогнозов при обнаружении перегрузок в режиме онлайн строится модель распределения ошибки предсказания с использованием метода ядерной оценки плотности вероятности.
- Для учёта накладных расходов на миграцию виртуальных машин, предлагается новый подход к решению проблемы, основанный на функции полезности. Он инициирует живую миграцию только тогда, когда ожидаемое значение полезности (штрафа) за нарушения SLA больше, чем стоимость дополнительных расходов на миграцию.
Предлагаемый подход экспериментально сопоставлен с другими подходами:
- с подходом, основанном на краткосрочных прогнозах;
- с подходом, который делает долгосрочные прогнозы без учета неопределенности;
- с подходом на основе долгосрочных прогнозов с учетом неопределенности прогноза, но без применения теории принятия решений для учёта накладных расходов на живую миграцию;
- с подход, основанном на методе локальной регрессии.
Архитектура диспетчера ресурсов
Эта работа фокусируется на управлении облаком IaaS, в котором несколько виртуальных машин работают на нескольких физических узлах. Общая архитектура диспетчера ресурсов и его основных компонентов показана на рис. 1. Существует агент VM для каждой виртуальной машины, который определяет распределение ресурсов на своей виртуальной машине в каждом временном интервале. Для каждого хоста есть хост-агент, который получает решения о распределении ресурсов всех агентов VM и определяет окончательные распределения, разрешая любые возможные конфликты. Он также обнаруживает, когда узел перегружен или недогружен, и передает эту информацию глобальному агенту. Глобальный агент инициирует решения о миграции виртуальной машины, перемещая виртуальные машины от перегруженных или недогруженных хостов на консолидирующие хосты для уменьшения потерь за нарушение SLA и сокращения количества физических узлов. В следующих разделах более подробно рассматривается каждый из компонентов диспетчера ресурсов.

Рис. 1 Архитектура диспетчера ресурсов
VM agent
Агент виртуальной машины отвечает за локальные решения о распределении ресурсов путем динамического определения общих ресурсов, которые должны быть распределены на его собственной виртуальной машине. Решения о распределении выполняются в дискретных временных интервалах, где в каждом интервале определяется доля ресурсов в следующем временном интервале. В этой работе временной интервал устанавливается в 10 секунд, чтобы быстро адаптироваться к изменяющейся нагрузке. Интервал не установлен на менее чем 10 секунд, поскольку при долгосрочном прогнозировании это увеличило бы количество шагов времени для прогнозирования в будущем, снижая точность прогноза. Установка большего интервала времени может привести к неэффективности и нарушениям SLA из-за отсутствия быстрой адаптации к изменению нагрузки. Наша работа сосредоточена на распределении CPU, но в принципе подход может быть распространен и на другие ресурсы. Для распределения ресурсов процессора используется настройка CPU CAP, которую предлагает большинство современных технологий виртуализации. CAP — это максимальная мощность CPU, которую может использовать VM, в процентах от общей ёмкости, что обеспечивает хорошую изоляцию производительности между виртуальными машинами.
Чтобы оценить долю CPU, выделенную каждой VM, сначала прогнозируется значение использования CPU для следующего временного интервала. Затем общий ресурс CPU рассчитывается как прогнозируемое использование CPU плюс 10% от мощности CPU. Установив CPU CAP на 10% больше, чем требуемое использование CPU, мы можем учесть ошибки прогнозирования и уменьшить вероятность нарушений SLA, связанных с производительностью. Для прогнозирования следующего значения использования CPU используется техника прогнозирования временных рядов, основанная на истории предыдущих значений использования CPU. В частности, используется машинное обучение, основанное на гауссовских процессах. Хотя для локального распределения ресурсов необходим только один шаг вперед, наш VM-агент прогнозирует на несколько шагов вперёд с целью обнаружения перегрузки.
Хост-агент
Одна из обязанностей хост-агента — играть роль арбитра. Он получает требования к процессору от всех агентов виртуальных машин, и, разрешая любые конфликты между ними, он решает об окончательных распределениях CPU для всех виртуальных машин. Конфликты могут возникать, когда требования CPU всех VM превышают общую мощность CPU. Если конфликты отсутствуют, окончательное распределение CPU совпадает с распределением, запрашиваемым агентами виртуальной машины. Если есть конфликт, главный агент вычисляет окончательные распределения CPU в соответствии со следующей формулой:
Финальная квота VM = (Запрашиваемая доля VM/Сумма запрашиваемых ресурсов всеми VM) * Общая мощность CPU
Другая обязанность хост-агента, которая является основным объектом этой работы, заключается в определении факта перегруженности или недогруженности хоста. Эта информация передается глобальному агенту, который затем инициирует живую миграцию для перемещения VM от перегруженных или недогруженных хостов в соответствии с алгоритмом глобального распределения.
Обнаружение перегрузки
Для обнаружения перегрузки используется долгосрочное прогнозирование временных рядов. В контексте этой работы это означает предсказание значений для 7 временных интервалов в будущем. Хост объявляется перегруженным, если фактическое и прогнозируемое общее использование CPU для 7 временных интервалов в будущем превышают порог перегрузки. Прогнозируемое общее использование CPU для будущего временного интервала оценивается путем суммирования прогнозируемых значений использования CPU всеми VM в соответствующем временном интервале. Значение 7 временных интервалов прогнозирования в будущем выбирается таким образом, чтобы оно было больше расчетного среднего времени живой миграции (около 4 временных интервалов). В этой работе среднее время живой миграции считается известным, и его значение, равное 4ём временным интервалам, оценивается путем усреднения по всем временам живой миграции VM в течение нескольких экспериментов. В реальных сценариях это значение заранее неизвестно, но его можно оценить на основе опыта. Другим более тонким подходом было бы применение метода прогнозирования времени живой миграции на основе текущих параметров VM.
Выполнение действий живой миграции для перегрузок, которые длятся меньше времени живой миграции, бесполезно, поскольку в этом случае живая миграция не сокращает время перегрузки. Использовать значение большее, чем 7 временных интервалов, тоже не очень полезно, поскольку это может привести к пропуску некоторых состояний перегрузки, которые не будут длиться долго, но которые могут быть устранены с помощью живой миграции. Некоторые предварительные эксперименты показали, что увеличение числа временных интервалов предсказания в будущем не повышает стабильность и эффективность подхода. Значение порога перегрузки определяется динамически на основе количества виртуальных машин и зависит от системы штрафов за нарушения SLA, что подробнее описано далее.
Обнаружение недостаточной загруженности
Хост-агент также определяет недостаточную загруженность хоста для применения динамической консолидации путём живой миграции всех своих виртуальных машин на другие узлы и отключения хоста для экономии электроэнергии. Здесь также используются долгосрочные прогнозы временных рядов использования CPU. Хост объявляется недогруженным, если фактическое и прогнозируемое общее использование CPU в течение 7 временных интервалов в будущем ниже порога недогрузки. Опять же, значение 7 временных интервалов достаточно, чтобы пропускать кратковременные состояния недогрузки, но не слишком велико, чтобы упустить любую возможность для консолидации. Пороговое значение является постоянным значением, и в этой работе оно установлено на 10% от мощности CPU, но оно может быть настроено администратором в соответствии с его предпочтениями в отношении агрессивности консолидации.
Обнаружение консолидирующих хостов
Чтобы принять решения о живой миграции, глобальному агенту необходимо знать хосты, которые не перегружены, чтобы использовать их в качестве хостов назначения для миграций. Хост объявляется как консолидирующий, если фактическое и прогнозируемое общее использование CPU в течение 7 временных интервалов в будущем меньше порога перегрузки. Фактическое и прогнозируемое общее использование CPU любого временного интервала оценивается путем суммирования фактического и прогнозируемого использования CPU всеми существующими виртуальными машинами, а также фактического и прогнозируемого использования CPU VM, которые планируется перенести на хост назначения. Цель состоит в том, чтобы проверить, не станет ли перегруженным косолидирующий узел после перенастройки виртуальных машин.
Неопределённость в долгосрочном прогнозировании
Долгосрочные прогнозы несут в себе ошибки предсказания, которые могут приводить к ошибочным решениям. Чтобы учесть неопределенность в долгосрочных прогнозах, вышеупомянутые механизмы обнаружения дополняются вероятностной моделью распределения ошибки прогнозирования.
Сначала оценивается функция плотности вероятности для ошибки предсказания в каждом интервале прогнозирования. Поскольку распределение вероятности ошибки предсказания заранее неизвестно, а различные нагрузки могут иметь разные распределения, для построения функции плотности требуется непараметрический метод. В этой работе используется непараметрический метод оценки функции плотности вероятности, основанный на ядерной оценке плотности ядра. Он оценивает функцию плотности вероятности ошибки прогнозирования каждый интервал времени, основываясь на предыдущих ошибках прогнозирования. В этой работе используется функция плотности вероятности абсолютного значения ошибки предсказания. Так как в будущем прогнозируется 7 временных интервалов, онлайн создаются 7 различных функций плотности вероятности для величины ошибки предсказания.
Вероятностное обнаружение перегрузки
На основе функции плотности вероятности для ошибки прогнозирования можно оценить будет ли будущее общее использование CPU больше, чем порог перегрузки, в каждом прогнозируемом временном интервале. Для этого воспользуемся алгоритмом 1, который возвращает значение true или false в зависимости от того, будет ли использование CPU в будущем превышать порог перегрузки с некоторой вероятностью.

Во-первых, алгоритм обнаруживает вероятность того, что использование CPU в будущем будет превышать порог перегрузки. Если прогнозируемое использование CPU больше порога перегрузки, то обнаруживается разница, называемая max_error, между прогнозируемым использованием CPU и порогом перегрузки. Для будущего использования CPU, превышающего пороговое значение перегрузки, модуль ошибки (т.е. разница между прогнозируемым и будущим значением) должен быть меньше max_error. На основе интегральной функции распределения ошибки предсказания найдена вероятность того, что ошибка прогнозирования (по модулю) меньше max_error, то есть вероятность того, что будущее использование CPU больше порогового значения перегрузки. Так как может случиться так, что будущее использование CPU будет больше порога перегрузки, при том, что ошибка прогнозирования будет больше max_error. Вероятность этого, заданная как (1-probability)/2, добавляется к вычисленной probability. Получаем конечную вероятность (probability+1)/2.
Если прогнозируемое использование CPU меньше порога перегрузки, то в этом случае, во-первых, будет найдена вероятность того, что будущее использование CPU будет меньше порога перегрузки. Она задается как (1-probability). Наконец, алгоритм возвращает true или false.
Алгоритм 1 возвращает условие перегрузки только для одного временного интервала прогнозирования. Поэтому для объявления хоста перегруженным, фактическое использование CPU должно превышать порог перегрузки, и алгоритм должен возвращать true для всех 7 временных интервалов прогнозирования.
Интерпретация необходимости учёта неопределенности прогнозирования при обнаружении перегрузки такова: хотя предсказание использования CPU может выдать значения, превышающие порог перегрузки, есть вероятность, что с учётом ошибки прогнозирования загрузка CPU будет ниже порога. Это означает, что в течение некоторого времени хост не будет считаться перегруженным, что повышает стабильность подхода. Об этом свидетельствует меньшее число живых миграций для вероятностного подхода к обнаружению перегрузки по сравнению с другими подходами (подробнее в разделе с экспериментами). Кроме того, когда предсказание использования CPU ниже порога перегрузки, существует некоторая вероятность того, что загрузка CPU будет больше, чем пороговое значение, и с учётом ошибки прогнозирования хост будет считаться перегруженным.
Таким образом, можно сказать, что хост считается перегруженным или нет пропорционально неопределенности прогноза, что является правильным подходом и подтверждается хорошими экспериментальными результатами по сравнению с подходами, не учитывающими неопределенность прогнозирования.
Чтобы определить, недогруженный хост, предлагается алгоритм 3.

Обнаружение перегрузок на основе теории принятия оптимальных решений
Вышеупомянутые усовершенствования позволяют учитывать неопределенность долгосрочных прогнозов в процессе обнаружения, но не учитывают накладные расходы, вызванные живой миграцией. В этом разделе представленный подход развивается в сторону теории принятия оптимальных решений. В результате живая миграция начинается только в случае, если потери за нарушение SLA из-за перегрузки хоста больше, чем потери, вызванные живой миграцией виртуальной машины.
Применяя теорию решений, мы должны определить функцию полезности, которую будем оптимизировать. В этом исследовании значение функции полезности представляет собой штраф за нарушение SLA хостом или накладные расходы, вызванные живой миграцией. SLA — это соглашение между облачным провайдером и потребителем, которое определяет, среди прочего, уровень доступности услуг (производительности) и систему штрафов за его нарушение. В этой работе нарушение SLA определяется как ситуация, когда общее использование CPU хостом превышает порог перегрузки в течение 4 последовательных интервалов времени. Штраф за нарушение SLA хоста — это процент мощности CPU, на который общее использование CPU превысило порог перегрузки в течение всех 4ёх последовательных временных интервалах. Штраф может быть преобразован в деньги с помощью некоторой функции преобразования, но здесь это процент мощности CPU.
Поскольку каждая миграция работающей виртуальной машины связана с некоторым снижением производительности, штраф для каждой миграции VM мог бы быть определен в соглашении SLA. Штраф за нарушение SLA, выраженный как процент от мощности CPU, определяется как сумма всех штрафов за нарушение SLA за все временные интервалы, в течение которых продолжается миграция VM.
Предложенный подход, основанный на теории принятия решений, пытается минимизировать штраф за нарушение SLA хостом (значение полезности) с учетом штрафа за нарушение SLA, вызванные живой миграцией. В дальнейшем вместо штрафа за нарушение SLA будет использован термин «полезность». Сначала оценивается ожидаемое значение полезности для будущего состояния перегрузки хоста. Ожидаемая полезность определяется суммой ожидаемых значений полезности всех 4 последовательных будущих временных интервалов от интервала 4 до интервала 7. Функция полезности рассчитывается с временного интервала 4 вместо временного интервала 1, чтобы зафиксировать состояние перегрузки до его возникновения и устранить эту возможность путём миграцию виртуальной машины, которая в среднем занимает 4 временных интервала.
Если будущее использование CPU известно, тогда полезность временного интервала — это разница между будущим использованием CPU и порогом перегрузки. Так как известно только предсказанное использование CPU, ожидаемое значение полезности одного временного интервала может быть рассчитано следующим образом:
Сначала интервал использования CPU между общей мощностью CPU и порогом перегрузки делится на фиксированное число уровней (5 в этой работе).
Затем вычисляется загрузка CPU выше порога перегрузки каждого уровня (т.е. значение полезности каждого уровня). Для этого используется Алгоритм 4.
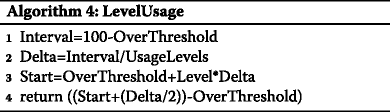
В Алгоритме 4, Interval — это интервал использования CPU над порогом перегрузки, Delta — это ширина интервала использования CPU соответствующего уровня, Level — номер уровня (от 0 до 4), значение полезности которого будет найдено, UsageLevels — общее количество уровней, Start — загрузка CPU в начале интервала этого уровня. Алгоритм возвращает в качестве значения полезности уровня загрузку CPU, взятую из середины интервала уровня. Алгоритм 4 запускается для каждого возможного уровня, чтобы найти его значение полезности.
Затем для любого временного интервала рассчитывается вероятность, что загрузка CPU на некотором уровне будет фактически будущим использованием CPU. Делает это алгоритм 5.

Start и Delta вычисляются в Алгоритме 4, Pred_Util — это общая прогнозируемая загрузка CPU соответствующего временного интервала, CumProbability () — интегральная функция распределения, используемая для определения вероятности того, что ошибка прогнозирования меньше определенного значения, а prob — это вероятность того, что загрузка CPU на этом уровне будет фактической будущей загрузкой CPU.
Расчёт схож с формулой расчёта математического ожидания. Ожидаемая полезность каждого временного интервала в будущем определяется суммой значений полезности на всех уровнях загрузки CPU, умноженные на соответствующие вероятности уровней. Ожидаемая полезность состояния перегрузки хоста дается как сумма ожидаемых полезностей 4 последовательных временных интервалов, начиная с 4ого. Хост объявляется перегруженным и миграции VM нужна, если ожидаемая полезность, которая является ожидаемым штрафом за нарушение SLA хоста, больше, чем штраф за нарушение SLA, вызванный живой миграцией.
Следует подчеркнуть, что это решение основано на краткосрочной оптимизации полезности и не учитывает накопление долгосрочного значения полезности, которое может быть результатом суммы значений полезности перегрузок, которые меньше, чем требуются для решения о миграции, но с течением времени может накопиться большое значение.
Для решения этой проблемы, накапливаются значения полезности состояний перегрузки, которые меньше, чем штраф за нарушение SLA из-за живой миграции, и на каждом временном интервале выполняется проверка. Если накопленное значение полезности больше, чем штраф за нарушение SLA из-за живой миграции, то миграция выполняется независимо от того, есть ли перегрузка в этом временном интервале.
Недогруженные хосты и хосты назначения определяются с помощью ранее упомянутых подходов, но также с модернизацией с помощью теории принятия оптимальных решений, целью которой является минимизация штрафов.
Глобальный агент
Глобальный агент принимает решения о распределении ресурсов провайдера с помощью живых миграций виртуальных машин с перегруженных или недогруженных хостов на другие узлы для снижения нарушений SLA и потребления энергии. Он получает уведомления от хост-агента, если узел будет перегружен или недогружен в будущем, и выполнит перенос VM, если оно того стоит.
Глобальный агент применяет алгоритм Power Aware Best Fit Decreasing (PABFD) для размещения VM со следующими корректировками. Для обнаружения перегрузки или недогрузки используются наши подходы, представленные выше. Для выбора виртуальной машины используется политика минимального времени миграции (MMT), но с модификацией, что для миграции в каждом раунде принятия решений выбрана только одна виртуальная машина, даже если хост может оставаться перегруженным после миграции. Это делается для уменьшения количества одновременных виртуальных миграций виртуальных машин и связанных с ними затрат. Для процесса консолидации, рассматриваются только недогруженные хосты, которые обнаруживаются предлагаемыми подходами на основе долгосрочного прогнозирования. Из списка недогруженных хостов сначала рассматриваются те, которые имеют более низкую среднюю загрузку CPU.
Нарушение SLA виртуальной машины
Поскольку облачному провайдеру трудно оценить показатели нарушения производительности за пределами виртуальных машин, которые зависят от показателей производительности различных приложений, таких как время ответа или пропускная способность, мы определили общий показатель нарушения SLA, который можно легко измерить за пределами виртуальных машин. Он основан только на использовании ресурсов VM. Более конкретно, это называется нарушением VM SLA и представляет собой штраф провайдеру облачных вычислений за нарушение производительности виртуальных машин потребителя. Производительность приложения, выполняющегося внутри VM потребителя, находится на приемлемом уровне, если требуемое использование ресурсов виртуальной машины меньше, чем выделенная доля ресурса.
В соответствии с предыдущим аргументом нарушение VM SLA существует, если разница между распределенной долей CPU и загрузкой CPU VM составляет менее 5% от мощности CPU в течение 4 последовательных временных интервалов.
Например, если доля CPU, выделенная для виртуальной машины, составляет 35% от мощности CPU, а фактическое использование CPU составляет более 30% в течение 4 последовательных интервалов времени, тогда возникает нарушение VM SLA. Идея этого определения заключается в том, что производительность приложения ухудшается по мере того, как требуемая загрузка CPU приближается к выделенным ресурсам CPU.
Штраф за нарушение VM SLA — это доля CPU, при которой фактическая зазгрузка CPU превышает пороговую разницу на 5% от выделенного CPU во всех 4 последовательных временных интервалах. Хотя штраф за нарушение SLA определен в процентах загрузки CPU, его можно легко преобразовать в деньги с помощью некоторой функции преобразования. Таким образом, одна из целей глобального агента состоит в том, чтобы уменьшить нарушения SLA VM, предоставив достаточную свободную мощность процессора путём миграции работающих VM. В итоге, каждая VM должна иметь на более чем 5% больше ресурсов CPU, чем требуется.
Определив метрику нарушения VM SLA, порог перегрузки может быть определен следующим образом. Он рассчитывается динамически на основе количества виртуальных машин. Определим N как количество виртуальных машин на хосте. Порог перегрузки рассчитывается как общая мощность процессора (100%) минус N*5%.
Эксперемент
Для проведения управляемых и повторяемых экспериментов в большой облачной инфраструктуре использался симулятор CloudSim. Это хорошо известный симулятор, который позволяет моделировать динамическое распределение ресурсов VM и потребление энергии в облаке. Мы внесли несколько изменений и расширений в CloudSim, чтобы интегрировать предлагаемый подход и получить поддержку настройки CPU CAP для виртуальных машин с целью локального распределения ресурсов.
В наших экспериментах моделируется виртуализированный центр обработки данных со 100 разнородными хостами. Моделируются два типа хостов, каждый из которых имеет 2 ядра процессора. Один хост имеет процессорные ядра с 2100 MIPS, а другой процессор имеет ядра с 2000 MIPS, оба имеют 8 ГБ ОЗУ. Один хост имитирует модель компьютера HpProLiantMl110G4 Xeon3040, а другой — HpProLiantMl110G5 Xeon3075.
В начале симуляции на каждом хосте в среднем запланировано 3 виртуальных машины (всего до 300 виртуальных машин). Используются четыре типа виртуальных машин, для каждой VM требуется один vCPU. Для трех типов виртуальных машин требуется максимальная емкость vCPU 1000 MIPS, а для другого типа VM требуется 500 MIPS. Для двух типов виртуальных машин требуется 1740 МБ ОЗУ, для одного требуется 870 МБ, а для последнего требуется 613 МБ. Для тестирования реалистичных рабочих нагрузок используются данные об использовании CPU реальных виртуальных машин, работающих в инфраструктуре PlanetLab. Каждая VM запускает одно приложение (облачко в терминологии CloudSim), и длина облачка, заданная как общее количество инструкций, устанавливается на достаточное значение, чтобы не дать облачным вычислениям завершиться до окончания эксперимента. Эксперимент выполняется в течение 116 временных интервалов, а продолжительность каждого — 10 секунд.
Методы обнаружения перегрузки, не использующие моделирование вероятности ошибки прогнозирования, дают одинаковые результаты каждый раз, когда эксперимент выполняется с одинаковой рабочей нагрузкой, в то время как вероятностные подходы приводят к различным результатам. Чтобы справедливо сравнить оба подхода, небольшое случайное значение из нормального распределения с М=0 и стандартным отклонением 0,001 добавляется к значению загрузки CPU в PlanetLab для каждого временного интервала. Это добавляет достаточное возмущение для эксперимента и возможность получить разные результаты для разных прогонов.
Для долгосрочного прогнозирования временных рядов через Java API используется платформа машинного обучения WEKA с гауссовскими процессами. История предыдущих загрузок CPU длиной в 20 выборок используется для обучения модели. Чтобы сохранить время моделирования на приемлемом уровне, модель прогнозирования проходит обучение каждые 5 интервалов времени с использованием новых данных о загрузке CPU. История ошибок прогнозирования длиной в 30 выборок используется для обучения модели функции плотности вероятности ошибки, которая пересчитывается в каждом временном интервале.
Результаты эксперимента
В этом разделе представлены экспериментальные результаты сравнения шести различных подходов.
- NO-Migrations (NOM) — это подход только локального перераспределения ресурсов CPU для виртуальных машин (без живой миграции).
- Краткосрочное прогнозирование, Short-Term Detection (SHT-D), определяет состояние перегрузки, если фактические и прогнозируемые значения загрузки CPU в следующих двух временных интервалах превышают порог перегрузки. Кроме того, тот же алгоритм используется для определения состояний без перегрузки и недогрузки. Как ожидается, подход будет весьма чувствительным к коротким скачкам нагрузки.
- Long-Term Detection (LT-D) основан на долгосрочных прогнозах использования CPU в следующих 7 контрольных интервалах.
- Long-Term Probabilistic Detection (LT-PD) основан на долгосрочном прогнозировании использования CPU в следующих 7 контрольных интервалах, но также учитывает неопределенность прогнозирования с помощью моделирования плотности распределения ошибки предсказания.
- Long-Term Decision Theory Detection (LT-DTD) — это LT-PD с применением теории принятия решений с целью минимизации издержек живой миграции.
- Последний подход, называемый Local Regression Detection (LR-D), является подходом, используемым в смежной работе другими авторами. Его выбрали как репрезентативную современную технологию, поскольку она обеспечивает наилучшую производительность, по сравнению с другими методами, по результатам смежного исследования на эту тему.
В оценке результатов используются следующие показатели эффективности:
- Нарушение VM SLA (VM SLA violation — VSV), описанное ранее, — это штраф провайдера облачных вычислений для каждой VM. Важно подчеркнуть, что нарушение VM SLA также может произойти из-за неправильного распределения ресурсов локального процессора. В экспериментах учитывается только нарушение VM SLA из-за нехватки мощности CPU в состоянии перегрузки хоста.
- Энергопотребление (E) центра данных за все время эксперимента, измеренное в кВтч.
- Количество живых миграций VM (Number of VM live migrations — NM) в течение всего эксперимента.
- Поскольку существует компромисс между энергопотреблением и нарушением SLA, рассчитывается еще один показатель, который объединяет нарушения SLA и энергопотребление в одном значении. Назовём его Utility и зададим с помощью следующей формулы:
Utility=CVSV/NOM_CVSV+Energy/NOM_Energy
Где CVSV — это совокупное значение VSV для всех VM в течение всего экспериментального времени, Energy — потребление энергии, NOM_CVSV — это совокупное значение VSV подхода NOM, NOM_Energy — потребление энергии подхода NOM. NOM_CVSV и NOM_Energy используются в качестве эталонных значений для нормализации соответствующих метрик. Нормализация выполняется, чтобы интегрировать две метрики с разными единицами измерения в одну функцию полезности. Наилучший подход — тот, который достигает минимального значения Utility.
- Другим показателем, который также использовался в смежной работе и фиксирует как затраты энергии, так и нарушения SLA VM, является ESV. Он определяется по формуле:
ESV=E∗CVSV
Где E — потребление энергии, а CVSV — это совокупное значение VSV всех VM в течение всего эксперимента.
Эксперимент запускается на двух разных уровнях нагрузки LOW и HIGH, и с тремя вариантами штрафа за нарушение SLA из-за живой миграции (migration penalties): mp = 2%, mp = 4% и mp = 6% (MP2, MP4, MP6). Под уровнем нагрузки подразумевается доля CPU, потребляемая каждой виртуальной машиной. Нагрузки LOW и HIGH рассчитываются путём умножения значений загрузки CPU из PlanetLab для каждого временного интервала на 8 и 14 соответственно. Эксперимент повторяется пять раз для каждой комбинации уровня нагрузки и варианта MP. Результаты подвергаются дисперсионному анализу ANOVA.
На рис. 2 показан суммарный штраф за нарушение VM SLA (совокупный VSV) для каждого подхода, усредненный по всем комбинациям уровней нагрузки и штрафов за миграцию. Из графика видно, что подходы LT-DTD и LT-PD, которые учитывают неопределенность прогнозирования, достигают наименьших уровней нарушения VM SLA со статистической значимостью. С другой стороны, мы видим, что LR-D работает лучше, чем SHT-D, но не имеет статистически значимой разницы с LT-D. Это ожидаемо, так как оба метода используют прогнозирование загрузки ресурсов в будущем, но без учета неопределенности прогнозирования. Можно сделать вывод, что учёт неопределенности долгосрочного прогнозирования при принятии решений полезен для снижения штрафов за нарушение SLA. Что еще более важно, подход LT-DTD достигает самого низкого уровня нарушений VM SLA по сравнению с другими подходами, подтверждая то, что применение теории принятия оптимального решений с учетом штрафа за живую миграцию может привести к повышению производительности. Например, подход LT-DTD уменьшает кумулятивное значение VSV относительно подхода LT-D на 27% и относительно LT-PD на 12%. Из сравнения LT-D с SHT-D можно сделать вывод, что применение долгосрочных прогнозов даже без учета ошибок прогнозирования может снизить нарушения VM SLA.
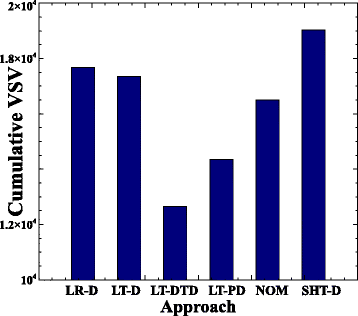
Рис.2 Накопительный VSV, усреднённый по всем нагрузкам и штрафам за миграцию
Чтобы увидеть влияние уровня загрузки на нарушения SLA VM, на рис. 3 показано суммарное значение VSV, усредненное по всем штрафам за миграцию, для каждого подхода и двух уровней загрузки. Во-первых, можно заметить, что для каждого подхода увеличение нагрузки увеличивает нарушения SLA VM, что ожидаемо, поскольку существует больше конфликтов за ресурсы. Опять же, мы можем видеть, что для обоих уровней загрузки подход LT-DTD достигает наименьшего значения VSV по сравнению с другими подходами. Что еще более важно, уменьшение значения VSV при переходе от высокой нагрузки к низкой нагрузке больше для подхода LT-DTD, чем для других подходов. Например, уменьшение значения VSV при переходе от высокой к низкой нагрузке для подхода LT-D составляет 40%, тогда как для LT-DTD оно составляет 59%. Кроме того, можно заметить, что при низкой нагрузке как LR-D, так и LT-D хуже даже по сравнению с случаем NOM, и только при высоких нагрузках они показывают лучшие результаты со статистической значимостью, что показывают тесты ANOVA. Из этого следует, что при низкой загрузке не стоит, по крайней мере, для минимизации нарушений SLA VM, выполнять живую миграцию без учёта неопределенности прогнозирования.

Рис.3 Усреднённый накопительный VSV по всем штрафам за миграцию для двух уровней нагрузки
Чтобы понять, как различаются подходы в зависимости от штрафа за миграцию, на рис. 4 обозначено кумулятивное значение VSV для каждого подхода, усредненное по двум уровням нагрузки и трём вариантам штрафа за миграцию. В общем, для всех подходов увеличение штрафа за миграцию приводит к увеличению значений VM SLA, что ожидается, поскольку штраф за миграцию является частью формулы расчёта значения нарушения VM SLA. Отметим, что LT-DTD более устойчив и не следует этой тенденции, о чем свидетельствуют статистически незначимые различия в кумулятивных значениях VSV между MP2 и MP4. Это объясняется тем, что только подход LT-DTD учитывает штрафы за миграцию при принятии решений о миграции.

Рис.4 Накопительный VSV по всем нагрузкам и трём вариантам штрафа за миграцию
На рисунке 5 показано общее число живых миграций VM для каждого подхода, усредненное по всем комбинациям уровней нагрузки и штрафов за миграцию. Можно заметить, что подход LT-DTD достигает наименьшего числа живых миграций с уменьшением на 46 и 29% по сравнению с LT-D и LT-PD соответственно. Во-первых, эти результаты показывают, что переход от краткосрочного прогнозирования к долгосрочному прогнозу повышает устойчивость подхода, уменьшая число живых миграций. Что еще более важно, принятие во внимание неопределенности долгосрочных прогнозов и штрафов за живую миграцию повышает стабильность и уменьшает число живых миграций в дальнейшем. Интересно отметить, что подход LR-D имеет наибольшее число живых миграций VM по сравнению с другими подходами. Это можно объяснить тем, что подход LR-D выполняет живую миграцию, если только одна прогнозируемая точка загрузки в будущем превышает порог, тогда как другие подходы проверяют несколько последовательных точек в будущем.
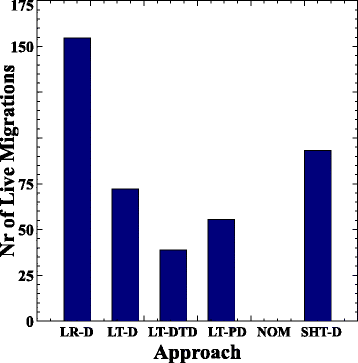
Рис.5 Среднее количество живых миграций по всем нагрузкам и штрафам за миграцию
На рисунке 6 мы показываем для каждого подхода, как количество живых миграций зависит от уровня нагрузки. В целом, кроме LT-DTD и LT-D, увеличение уровня загрузки увеличивает количество перемещений. Подход LT-DTD демонстрирует большую стабильность, не увеличивая количество живых миграций при увеличенной нагрузке, и, поскольку это все же приводит к лучшим значениям VSV по сравнению с другими подходами (как показано на рисунке 3), это предпочтительное поведение. LT-D подход показывает небольшое увеличение числа живых миграций, но это не статистически значимо, как показывает ANOVA.
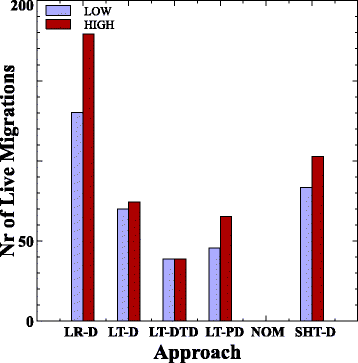
Рис.6 Среднее количество живых миграций по всем штрафам за миграцию для двух уровней нагрузки
На рисунке 7 показано, как для каждого подхода изменяется количество живых миграций, при изменении штрафа за миграцию. В отличие от других подходов, LT-DTD и LT-PD показывают снижение количества живых миграций при увеличения штрафа за миграцию. Подход LT-DTD показывает уменьшение количества «живых» миграций при переходе от MP2 к MP4, и это можно объяснить тем, что при принятии решений о живой миграции учитывается штраф за миграцию. Использование штрафа за миграцию применяется в качестве параметра для контроля агрессивности процесса консолидации. С другой стороны, уменьшенное число «живых» миграций для подхода LT-PD, по крайней мере для MP2 до MP6, которое является статистически значимым, не имеет очевидного объяснения, поскольку этот подход не учитывает штраф за миграцию при принятии решения. Единственное объяснение заключается в том, что это поведение вызвано тем, что подход LT-PD учитывает накопление значений полезности при принятии решений так же, как делает LT-DTD, что объяснялось ранее. Чтобы проверить эту гипотезу, был проведен эксперимент, в котором измерили количество живых миграций для трёх вариантов штрафа за миграцию при низкой нагрузке. Эксперимент выполняется для LT-PD и LT-DTD, но без учета накопления полезности.
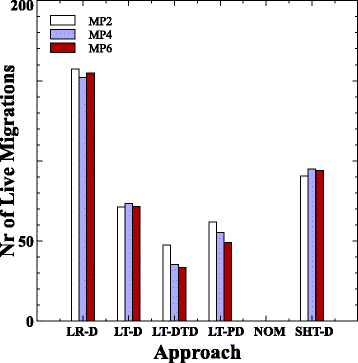
Рис.7 Количество живых миграций по всем нагрузкам и трём вариантам штрафа за миграцию
Результаты эксперимента показаны на рис. 8. Очевидно, что для LT-PD, увеличение штрафа за миграцию не изменяет количество живых миграций, подтверждая утверждение, что вышеупомянутое поведение вызвано только учётом накопления полезности в принятии решений. Однако для LT-DTD увеличение штрафа за миграцию уменьшает число живых миграций, показывая, что это поведение обусловлено подходом на основе теории принятия оптимальных решений.
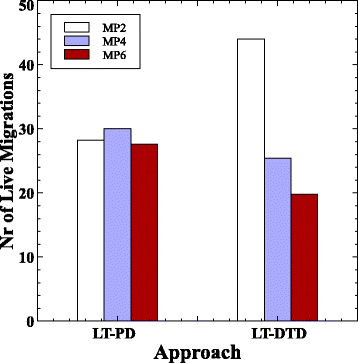
Рис.8 Число миграций для LT-PD и LT-DTD для трех вариантов миграционных штрафов
На рисунке 9 показано потребление энергии облачным центром обработки данных за весь период эксперимента для каждого подхода, усредненное по всем комбинациям уровней нагрузки и вариантам штрафа за миграцию. Очевидно, что подход LT-DTD показывает небольшое увеличение потребления энергии по сравнению с другими подходами. Например, увеличивает потребление энергии на 5 и 0,30% по сравнению с LT-D и NOM, соответственно. Хотя подход LT-DTD экономит меньше энергии, улучшение значений нарушения VM SLA перевешивает снижение энергосбережения, что показывают результаты метрики Utility. LR-D, LT-D и SHT-D достигают большей экономии энергии, чем подход LT-DTD, за счет более высоких нарушений VM SLA, что приводит к худшим значениям ESV и Utility.
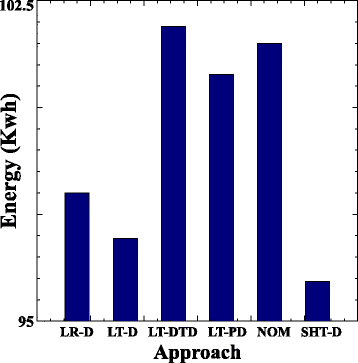
Рис.9 Энергия по всем уровням нагрузки и вариантам штрафа за миграцию
На рис. 10, мы показываем, как для каждого подхода потребление энергии зависит от уровня нагрузки. Как можно ожидать, можно наблюдать, что увеличение нагрузки увеличивает потребление энергии для всех подходов. Снижение потребления энергии при снижении уровня нагрузки объясняется тем, что низкая загрузка создает больше возможностей для консолидации и отключения части хостов.

Рис. 10 Энергия по всем вариантам штрафа за миграцию для двух уровней нагрузки
Из приведенного выше аргумента можно ожидать, что, уменьшив уровень нагрузки ещё больше, LT-DTD может сэкономить энергию по сравнению с NOM. Это вызвано тем, что при снижении нагрузки подход LT-DTD придает большее внимания процессу консолидации, уменьшая количество хостов и экономя электроэнергию. С другой стороны, когда увеличивается нагрузка, она уделяет больше внимания процессу балансировки нагрузки, экономя меньше энергии, но снижая нарушения VM SLA.
На рис.11 мы показываем, как для каждого подхода потребление энергии зависит от размера штрафа за миграцию. ANOVA показывает, что для подходов не существует статистически значимых различий в энергетической ценности между вариантами штрафов за миграцию. Поэтому размер штрафа за миграцию не оказывает существенного влияния на потребление энергии.
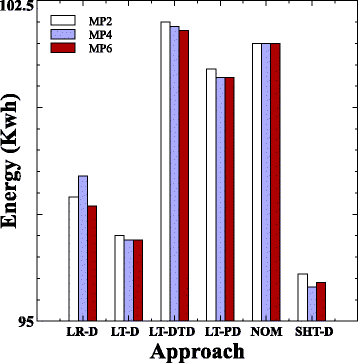
Рис.11 Энергия по всем уровням нагрузки для трёх вариантов миграционных штрафов
Чтобы лучше осознать борьбу между энергосбережением и производительностью виртуальных машин, на рис. 12 представляем усреднённый показатель Utility для каждого подхода по всем уровням нагрузки и вариантам штрафа за миграцию. Utility — это метрика, которая указывает на улучшение как в экономии энергии, так и уменьшение нарушений SLA VM. Она может служить метрикой общей производительности. Можно заметить, что подход LT-DTD достигает наименьшего значения Utility по сравнению с другими подходами со статистической значимостью. Это улучшает Utility примерно на 9,4% и 4,3% по сравнению с подходами LT-D и LT-PD соответственно. Это показывает, что, хотя подход LT-DTD обеспечивает немного меньшую экономию энергии, он снижает нарушения SLA, таким образом находит лучший компромисс между производительностью и энергопотреблением. Что касается других подходов, то LR-D работает лучше, чем подход SHT-D, но немного хуже, чем подход LT-D. Это объясняется тем, что подход LR-D обеспечивает меньшую экономию энергии, чем подход LT-D с аналогичными нарушениями SLA, как показано на рисунках 2 и 9.
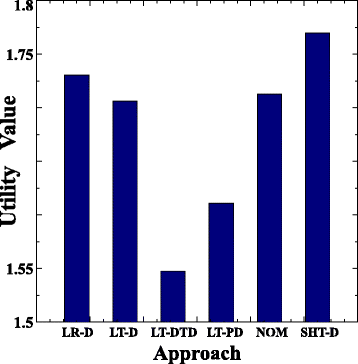
Рис.12 Усреднённое значение полезности для всех нагрузок и штрафов за миграцию
На рисунке 13 показано как на Utility влияют уровни нагрузки. Можно заметить, что увеличение нагрузки увеличивает значение Utility, поскольку увеличивается как потребление энергии, так и нарушения SLA VM. Для каждого уровня нагрузки подход LT-DTD достигает наименьшего значения Utility по сравнению с другими подходами.
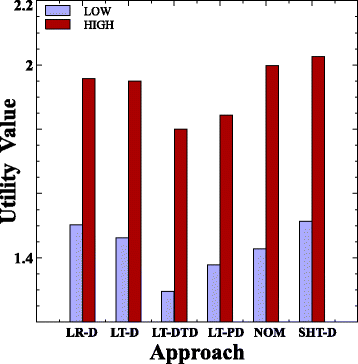
Рис.13 Значение полезности для двух уровней нагрузки
На рисунке 14 показано влияние, которое имеет размер штрафа за миграцию на Utility. В общем, для всех подходов можно заметить, что увеличение штрафа за миграцию увеличивает Utility, так как она увеличивает штраф за нарушение VM SLA. Однако, подход LT-DTD, кажется, более устойчивым. Это можно наблюдать, по крайней мере, в случае перехода от MP2 к MP4, где нет статистически значимых различий по результатам ANOVA.

Рис.14 Значение полезности для всех нагрузок для трех штрафов за миграцию
Значения ESV показывает ту же тенденцию, что и значение Utility.

Рис.15 Значение ESV по всем уровням нагрузки и трём вариантам штрафа за миграцию
Вывод
Учитывая неопределённость прогнозирования, дополнительные расходы на живую миграцию и применяя теорию принятия оптимальных решений, мы получили лучшее по сводным показателям решение и улучшение производительности.
Есть несколько нарпавлений для будущей работы.
Во-первых, подход основан на долгосрочной модели прогнозирования. Это означает, что модель прогнозирования не может легко предсказать внезапное и резкое увеличение нагрузки (то есть всплески нагрузки). Этот вопрос выходит за рамки исследования, но его можно решить, сосредоточив внимание на методах обнаружения всплесков нагрузки. Интересной областью будущей работы является комбинирование методов обнаружения всплесков нагрузки с использованием методов прогнозирования нагрузки для разработки широкого спектра моделей нагрузки.
Во-вторых, в дополнение к используемой в настоящее время схеме предсказания следующего значения загрузки CPU для локального распределения ресурсов могут быть изучены более сложные схемы, основанные на теории управления, Калмановской фильтрации или нечеткой логике.
В-третьих, следует изучить подход к распределению ресурсов, при котором каждый хост-агент принимает решения о живой миграции в сотрудничестве с ближайшими хост-агентами. Такой подход выглядит перспективно для крупномасштабных облачных инфраструктур, где важными факторами являются централизованная сложность оптимизации и единая точка отказа. В таких подходах проблема заключается в том, как хост-агенты с ограниченными данными должны координировать друг друга для достижения глобальной цели оптимизации.
Наконец, изучение долгосрочного прогнозирования распределения нескольких ресурсов (например, CPU, RAM, I/O) и их взаимозависимости является интересной областью для будущей работы.
Мы приглашаем всех обсудить вопрос распределения ресурсов в комментариях.
ссылка на оригинал статьи https://habrahabr.ru/post/329416/
Добавить комментарий