Equals, а также GetHashCode, чтобы избежать снижения производительности. Но что будет, если этого не сделать? Сегодня сравним производительность при двух вариантах настройки и рассмотрим инструменты, помогающие избегать ошибок.

Насколько серьезна эта проблема?
Не каждая потенциальная проблема с производительностью влияет на время выполнения приложения. Метод Enum.HasFlag не очень эффективен (*), но если не использовать его на ресурсоемком участке кода, то серьезных проблем в проекте не возникнет. Это верно и случае с защищенными копиями, созданными типами non-readonly struct в контексте readonly. Проблема существует, но вряд ли будет заметна в обычных приложениях.
(*) Исправлено в .NET Core 2.1, и, как я уже упоминал в предыдущей публикации, теперь последствия можно смягчить с помощью самостоятельно настроенных HasFlag для более старых версий.
Но проблема, о которой мы поговорим сегодня, особенная. Если в структуре не создаются методы Equals и GetHashCode, то используются их стандартные версии из System.ValueType. А они могут значительно снизить производительность конечного приложения.
Почему стандартные версии работают медленно?
Авторы CLR изо всех сил старались сделать стандартные версии Equals и GetHashCode максимально эффективными для типов значений. Но есть несколько причин, по которым эти методы проигрывают в эффективности пользовательской версии, написанной для определенного типа вручную (или сгенерированной компилятором).
1. Распределение упаковки-преобразования. CLR создан таким образом, что каждый вызов элемента, определенного в типах System.ValueType или System.Enum, запускает упаковку-преобразование (**).
(**) Если метод не поддерживает JIT-компиляцию. Например, в Core CLR 2.1 компилятор JIT распознает метод Enum.HasFlag и генерирует подходящий код, который не запускает упаковку-преобразование.
2. Потенциальные конфликты в стандартной версии метода GetHashCode. При реализации хэш-функции мы сталкиваемся с дилеммой: сделать распределение хэш-функции хорошо или быстро. В ряде случаев можно выполнить и то и другое, но в типе ValueType.GetHashCode это обычно сопряжено с трудностями.
Традиционная хэш-функция типа struct «объединяет» хэш-коды всех полей. Но единственный способ получить хэш-код поля в методе ValueType — использовать рефлексию. Вот почему авторы CLR решили пожертвовать скоростью ради распределения, и стандартная версия GetHashCode только возвращает хэш-код первого ненулевого поля и «портит» его идентификатором типа (***) (подробнее см. RegularGetValueTypeHashCode в coreclr repo на github).
(***) Судя по комментариям в репозитории CoreCLR, в будущем ситуация может измениться.
public readonly struct Location { public string Path { get; } public int Position { get; } public Location(string path, int position) => (Path, Position) = (path, position); } var hash1 = new Location(path: "", position: 42).GetHashCode(); var hash2 = new Location(path: "", position: 1).GetHashCode(); var hash3 = new Location(path: "1", position: 42).GetHashCode(); // hash1 and hash2 are the same and hash1 is different from hash3Это разумный алгоритм пока что-то не пойдет не так. Но если вам не повезло и значение первого поля вашего типа struct совпадают в большинстве экземпляров, то хэш-функция всегда будет выдавать одинаковый результат. Как вы уже догадались, если сохранить эти экземпляры в хэш-наборе или хэш-таблице, то производительность резко упадет.
3. Скорость реализации на основе рефлексии низкая. Очень низкая. Рефлексия — это мощный инструмент, если использовать его правильно. Но последствия будут ужасны, если запустить его на ресурсоемком участке кода.
Давайте посмотрим, как неудачная хэш-функция, которая может получиться из-за (2) и реализации на основе рефлексии, влияет на производительность:
public readonly struct Location1 { public string Path { get; } public int Position { get; } public Location1(string path, int position) => (Path, Position) = (path, position); } public readonly struct Location2 { // The order matters! // The default GetHashCode version will get a hashcode of the first field public int Position { get; } public string Path { get; } public Location2(string path, int position) => (Path, Position) = (path, position); } public readonly struct Location3 : IEquatable<Location3> { public string Path { get; } public int Position { get; } public Location3(string path, int position) => (Path, Position) = (path, position); public override int GetHashCode() => (Path, Position).GetHashCode(); public override bool Equals(object other) => other is Location3 l && Equals(l); public bool Equals(Location3 other) => Path == other.Path && Position == other.Position; } private HashSet<Location1> _locations1; private HashSet<Location2> _locations2; private HashSet<Location3> _locations3; [Params(1, 10, 1000)] public int NumberOfElements { get; set; } [GlobalSetup] public void Init() { _locations1 = new HashSet<Location1>(Enumerable.Range(1, NumberOfElements).Select(n => new Location1("", n))); _locations2 = new HashSet<Location2>(Enumerable.Range(1, NumberOfElements).Select(n => new Location2("", n))); _locations3 = new HashSet<Location3>(Enumerable.Range(1, NumberOfElements).Select(n => new Location3("", n))); _locations4 = new HashSet<Location4>(Enumerable.Range(1, NumberOfElements).Select(n => new Location4("", n))); } [Benchmark] public bool Path_Position_DefaultEquality() { var first = new Location1("", 0); return _locations1.Contains(first); } [Benchmark] public bool Position_Path_DefaultEquality() { var first = new Location2("", 0); return _locations2.Contains(first); } [Benchmark] public bool Path_Position_OverridenEquality() { var first = new Location3("", 0); return _locations3.Contains(first); } Method | NumOfElements | Mean | Gen 0 | Allocated | -------------------------------- |------ |--------------:|--------:|----------:| Path_Position_DefaultEquality | 1 | 885.63 ns | 0.0286 | 92 B | Position_Path_DefaultEquality | 1 | 127.80 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1 | 47.99 ns | - | 0 B | Path_Position_DefaultEquality | 10 | 6,214.02 ns | 0.2441 | 776 B | Position_Path_DefaultEquality | 10 | 130.04 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 10 | 47.67 ns | - | 0 B | Path_Position_DefaultEquality | 1000 | 589,014.52 ns | 23.4375 | 76025 B | Position_Path_DefaultEquality | 1000 | 133.74 ns | 0.0050 | 16 B | Path_Position_OverridenEquality | 1000 | 48.51 ns | - | 0 B | Если значение первого поля всегда одинаково, то по умолчанию хэш-функция возвращает равное значение для всех элементов и хэш-набор эффективно преобразуется в связанный список с O(N) операций вставки и поиска. Число операций заполнения коллекции становится равным O(N^2) (где N — количество вставок со сложностью O(N) для каждой вставки). Это означает, что вставка в набор 1000 элементов даст почти 500 000 вызовов ValueType.Equals. Вот последствия метода, использующего рефлексию!
Как показывает тест, производительность будет приемлемой, если вам повезет и первый элемент структуры будет уникальным (в случае Position_Path_DefaultEquality). Но если это не так, то производительность будет крайне низкой.
Реальная проблема
Думаю, теперь вы догадываетесь, с какой проблемой я недавно столкнулся. Пару недель назад я получил сообщение об ошибке: время выполнения приложения, над которым я работаю, увеличилось с 10 до 60 секунд. К счастью, отчет был весьма подробным и содержал трассировку событий Windows, поэтому проблемное место обнаружилось быстро — ValueType.Equals загружался 50 секунд.
После беглого просмотра кода стало ясно, в чем проблема:
private readonly HashSet<(ErrorLocation, int)> _locationsWithHitCount; readonly struct ErrorLocation { // Empty almost all the time public string OptionalDescription { get; } public string Path { get; } public int Position { get; } } Я использовал кортеж, который содержал пользовательский тип struct со стандартной версией Equals. И, к сожалению, он имел необязательное первое поле, которое почти всегда равнялось String.equals. Производительность оставалась высокой, пока значительно не увеличилось количество элементов в наборе. За считанные минуты инициализировалась коллекция с десятками тысяч элементов.
Всегда ли реализация ValueType.Equals/GetHashCode по умолчанию работает медленно?
И для ValueType.Equals, и для ValueType.GetHashCode есть специальные методы оптимизации. Если у типа нет «указателей» и он правильно упакован (я покажу пример через минуту), тогда используются оптимизированные версии: итерации GetHashCode выполняются над блоками экземпляра, используется XOR размером 4 байта, метод Equals сравнивает два экземпляра, используя memcmp.
// Optimized ValueType.GetHashCode implementation static INT32 FastGetValueTypeHashCodeHelper(MethodTable *mt, void *pObjRef) { INT32 hashCode = 0; INT32 *pObj = (INT32*)pObjRef; // this is a struct with no refs and no "strange" offsets, just go through the obj and xor the bits INT32 size = mt->GetNumInstanceFieldBytes(); for (INT32 i = 0; i < (INT32)(size / sizeof(INT32)); i++) hashCode ^= *pObj++; return hashCode; } // Optimized ValueType.Equals implementation FCIMPL2(FC_BOOL_RET, ValueTypeHelper::FastEqualsCheck, Object* obj1, Object* obj2) { TypeHandle pTh = obj1->GetTypeHandle(); FC_RETURN_BOOL(memcmp(obj1->GetData(), obj2->GetData(), pTh.GetSize()) == 0); } Сама проверка выполняется в ValueTypeHelper::CanCompareBits, она вызывается и из итерации ValueType.Equals, и из итерации ValueType.GetHashCode.
Но оптимизация – очень коварная вещь.
Во-первых, сложно понять, когда она включена; даже незначительные изменения в коде могут включать ее и выключать:
public struct Case1 { // Optimization is "on", because the struct is properly "packed" public int X { get; } public byte Y { get; } } public struct Case2 { // Optimization is "off", because struct has a padding between byte and int public byte Y { get; } public int X { get; } }Дополнительную информацию о структуре памяти см. в моем блоге «Внутренние элементы управляемого объекта, часть 4. Структура полей».
Во-вторых, сравнение памяти вовсе не обязательно даст вам правильный результат. Вот простой пример:
public struct MyDouble { public double Value { get; } public MyDouble(double value) => Value = value; } double d1 = -0.0; double d2 = +0.0; // True bool b1 = d1.Equals(d2); // False! bool b2 = new MyDouble(d1).Equals(new MyDouble(d2)); -0,0 и +0,0 равны, но имеют разные двоичные представления. Это значит, что Double.Equals окажется верным, а MyDouble.Equals — ложным. В большинстве случаев разница несущественна, но представьте, сколько часов вы потратите на исправление проблемы, вызванной этой разницей.
Как избежать подобной проблемы?
Вы можете спросить меня, как упомянутое выше может произойти в реальной ситуации? Один из очевидных способов запуска методов Equals и GetHashCode в типах struct — использование правила FxCop CA1815. Но есть одна проблема: это слишком строгий подход.
Приложение, для которого критически важна производительность, может иметь сотни типов struct, которые не обязательно используются в хэш-наборах или словарях. Поэтому разработчики приложения могут отключить правило, что вызовет неприятные последствия, если тип struct использует измененные функции.
Более правильный подход — предупреждать разработчика, если «неподходящий» тип struct с равными значениями элементов по умолчанию (определенный в приложении или сторонней библиотеке) хранится в хэш-наборе. Конечно же я говорю об ErrorProne.NET и о правиле, которое я туда добавил, как только столкнулся с этой проблемой:

Версия ErrorProne.NET не идеальна и будет «обвинять» правильный код, если в конструкторе используется пользовательский сопоставитель равенства:
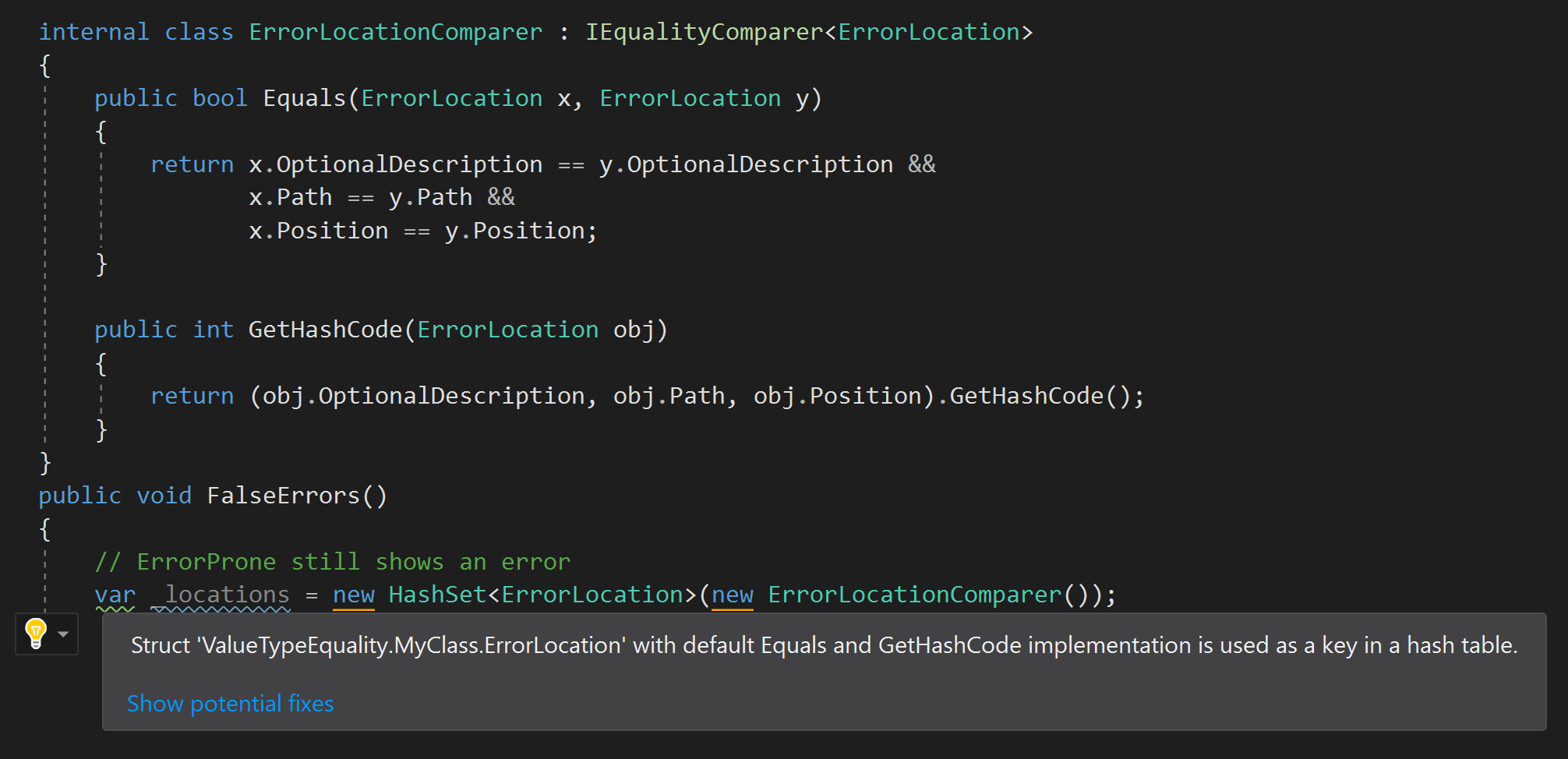
Но я все равно думаю, что стоит предупреждать, если тип struct с равными по умолчанию элементами используется не тогда, когда производится. Например, когда я проверил свое правило, то понял, что структура System.Collections.Generic.KeyValuePair <TKey, TValue>, определенная в mscorlib, не перезаписывает Equals и GetHashCode. Маловероятно, что сегодня кто-то определит переменную типа HashSet <KeyValuePair<string, int>>, но я считаю, что даже BCL может нарушить правило. Поэтому полезно обнаружить это, пока не поздно.
Заключение
- Реализация равенства по умолчанию для типов struct может привести к серьезным последствиям для вашего приложения. Это реальная, а не теоретическая проблема.
- Элементы равенства по умолчанию для типов значений основаны на рефлексии.
- Распределение, выполненное стандартной версией
GetHashCode, будет очень плохим, если первое поле многих экземпляров имеет одинаковое значение. - Для стандартных методов
EqualsиGetHashCodeсуществуют оптимизированные версии, но не стоит на них полагаться, поскольку их может выключить даже небольшое изменение кода. - Используйте правило FxCop, чтобы убедиться, что каждый тип struct переопределяет элементы равенства. Однако лучше предупредить проблему при помощи анализатора, если «неподходящая» структура хранится в хэш-наборе или в хэш-таблице.
Дополнительные ресурсы
ссылка на оригинал статьи https://habr.com/company/microsoft/blog/418515/
Добавить комментарий