В наших решениях мы используем интеграцию и с помощью Kafka, и с помощью gRPC, и с помощью RabbitMQ.
В этой статье мы поделимся нашим опытом кластеризации RabbitMQ, ноды которого размещены в Kubernetes.

До RabbitMQ версии 3.7 его кластеризация в K8S была не очень тривиальной задачей, со множеством хаков и не очень красивых решений. В версии 3.6 использовался autocluster плагин из RabbitMQ Community. А в 3.7 появился Kubernetes Peer Discovery Backend. Он встроен плагином в базовую поставку RabbitMQ и не требует отдельной сборки и установки.
Мы опишем итоговую конфигурацию целиком, попутно комментируя происходящее.
В теории
У плагина существует репозиторий на гитхабе, в котором есть пример базового использования.
Этот пример не предназначен для Production, о чём явно указано в его описании, и более того, часть настроек в нём установлено вразрез с логикой использования в проде. Также в примере никак не упомянута персистентность хранилища, таким образом при любой нештатной ситуации наш кластер превратится в пшик.
На практике
Сейчас расскажем, с чем столкнулись сами и как установили и настроили RabbitMQ.
Опишем конфигурации всех частей RabbitMQ как сервиса в K8s. Сразу уточним, что мы устанавливали RabbitMQ в K8s как StatefulSet. На каждой ноде кластера K8s будет всегда функционировать один экземпляр RabbitMQ (одна нода в классической конфигурации кластера). Мы также установим в K8s панель управления RabbitMQ и дадим доступ до этой панели за пределы кластера.
Права и роли:
--- apiVersion: v1 kind: ServiceAccount metadata: name: rabbitmq --- kind: Role apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader rules: - apiGroups: [""] resources: ["endpoints"] verbs: ["get"] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1beta1 metadata: name: endpoint-reader subjects: - kind: ServiceAccount name: rabbitmq roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: endpoint-readerПрава доступа для RabbitMQ взяты целиком из примера, никаких изменений в них не требуется. Создаём ServiceAccount для нашего кластера и выдаём ему права на чтение Endpoints K8s.
Персистентное хранилище:
kind: PersistentVolume apiVersion: v1 metadata: name: rabbitmq-data-sigma labels: type: local annotations: volume.alpha.kubernetes.io/storage-class: rabbitmq-data-sigma spec: storageClassName: rabbitmq-data-sigma capacity: storage: 10Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle hostPath: path: "/opt/rabbitmq-data-sigma"В качестве персистентного хранилища здесь мы взяли самый простой случай — hostPath (обычную папку на каждой ноде K8s), но можно использовать любой из множества типов персистентных томов, поддерживаемых в K8s.
kind: PersistentVolumeClaim apiVersion: v1 metadata: name: rabbitmq-data spec: storageClassName: rabbitmq-data-sigma accessModes: - ReadWriteMany resources: requests: storage: 10GiСоздаём Volume Claim на томе, созданном в предыдущем шаге. Этот Claim затем будет использоваться в StatefulSet как хранилище постоянных данных.
Сервисы:
kind: Service apiVersion: v1 metadata: name: rabbitmq-internal labels: app: rabbitmq spec: clusterIP: None ports: - name: http protocol: TCP port: 15672 - name: amqp protocol: TCP port: 5672 selector: app: rabbitmqСоздаём внутренний headless сервис, через который будет работать Peer Discovery plugin.
kind: Service apiVersion: v1 metadata: name: rabbitmq labels: app: rabbitmq type: LoadBalancer spec: type: NodePort ports: - name: http protocol: TCP port: 15672 targetPort: 15672 nodePort: 31673 - name: amqp protocol: TCP port: 5672 targetPort: 5672 nodePort: 30673 selector: app: rabbitmqДля работы приложений в K8s с нашим кластером создаём сервис балансировщика.
Так как нам нужен доступ к кластеру RabbitMQ снаружи K8s, прокидываем NodePort. RabbitMQ будет доступен при обращении к любой ноде кластера K8s по портам 31673 и 30673. В реальной работе большой необходимости в этом нет. Вопрос удобства пользования админкой RabbitMQ.
При создании сервиса с типом NodePort в K8s также неявно создаётся сервис с типом ClusterIP для его обслуживания. Поэтому приложения в K8s, которым нужно работать с нашим RabbitMQ, смогут обращаться к кластеру по адресу amqp://rabbitmq:5672
Конфигурация:
apiVersion: v1 kind: ConfigMap metadata: name: rabbitmq-config data: enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. rabbitmq.conf: | cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 ### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true cluster_partition_handling = autoheal queue_master_locator=min-masters cluster_formation.randomized_startup_delay_range.min = 0 cluster_formation.randomized_startup_delay_range.max = 2 cluster_formation.k8s.service_name = rabbitmq-internal cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.localСоздаём конфигурационные файлы RabbitMQ. Основная магия.
enabled_plugins: | [rabbitmq_management,rabbitmq_peer_discovery_k8s]. Добавляем нужные плагины в разрешенные к загрузке. Теперь мы можем использовать автоматический Peer Discovery в K8S.
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s Выставляем в качестве backend для peer discovery нужный плагин.
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local cluster_formation.k8s.port = 443 Указываем адрес и порт, через которые можно достучаться до kubernetes apiserver. Здесь можно указать напрямую ip-адрес, но более красиво будет сделать так.
В namespace default обычно создан service с именем kubernetes, ведущий на k8-apiserver. В разных вариантах установки K8S namespace, имя сервиса и порт могут быть другими. Если что-то в конкретной установке отличается, нужно, соответственно, поправить здесь.
Например, мы столкнулись с тем, что в некоторых кластерах сервис на порту 443, а в некоторых на 6443. Понять, что что-то не так, можно будет в логах старта RabbitMQ, там явно выделен момент подключения по указанному здесь адресу.
### cluster_formation.k8s.address_type = ip cluster_formation.k8s.address_type = hostname По умолчанию в примере был указан тип адресации нод кластера RabbitMQ по ip-адресу. Но при перезапуске pod он каждый раз получает новый IP. Сюрприз! Кластер умирает в муках.
Меняем адресацию на hostname. StatefulSet гарантирует нам неизменность hostname в рамках жизненного цикла всего StatefulSet, что нас полностью устроит.
cluster_formation.node_cleanup.interval = 10 cluster_formation.node_cleanup.only_log_warning = true Поскольку при потере одной из нод мы предполагаем, что она рано или поздно восстановится, отключаем самоудаление кластером недоступных нод. В этом случае, как только нода вернётся в онлайн, она войдёт в кластер без потери своего предыдущего состояния.
cluster_partition_handling = autohealЭтим параметром определяем действия кластера при потере кворума. Тут стоит просто почитать документацию по этой теме и понять для себя, что ближе к конкретному сценарию использования.
queue_master_locator=min-mastersОпределяем выбор мастера для новых очередей. При данной настройке мастером будет выбираться нода с наименьшим количеством очередей, таким образом очереди будут распределяться равномерно по нодам кластера.
cluster_formation.k8s.service_name = rabbitmq-internalЗадаём имя headless сервиса K8s (созданного нами ранее), через который ноды RabbitMQ будут общаться между собой.
cluster_formation.k8s.hostname_suffix = .rabbitmq-internal.our-namespace.svc.cluster.localВажная штука для работы адресации в кластере по hostname. FQDN пода K8s формируется как короткое имя (rabbitmq-0, rabbitmq-1) + суффикс (доменная часть). Здесь мы и указываем этот суффикс. В K8S он выглядит как .<имя сервиса>.<имя namespace>.svc.cluster.local
kube-dns без какой-либо дополнительной настройки резолвит имена вида rabbitmq-0.rabbitmq-internal.our-namespace.svc.cluster.local в ip-адрес конкретного пода, что и делает возможной всю магию кластеризации по hostname.
Конфигурация StatefulSet RabbitMQ:
apiVersion: apps/v1beta1 kind: StatefulSet metadata: name: rabbitmq spec: serviceName: rabbitmq-internal replicas: 3 template: metadata: labels: app: rabbitmq annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } } spec: serviceAccountName: rabbitmq terminationGracePeriodSeconds: 10 containers: - name: rabbitmq-k8s image: rabbitmq:3.7 volumeMounts: - name: config-volume mountPath: /etc/rabbitmq - name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia ports: - name: http protocol: TCP containerPort: 15672 - name: amqp protocol: TCP containerPort: 5672 livenessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 60 periodSeconds: 10 timeoutSeconds: 10 readinessProbe: exec: command: ["rabbitmqctl", "status"] initialDelaySeconds: 10 periodSeconds: 10 timeoutSeconds: 10 imagePullPolicy: Always env: - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" - name: K8S_SERVICE_NAME value: "rabbitmq-internal" - name: RABBITMQ_ERLANG_COOKIE value: "mycookie" volumes: - name: config-volume configMap: name: rabbitmq-config items: - key: rabbitmq.conf path: rabbitmq.conf - key: enabled_plugins path: enabled_plugins - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-dataСобственно, сам StatefulSet. Отметим интересные моменты.
serviceName: rabbitmq-internalПрописываем имя headless-сервиса, через который общаются поды в StatefulSet.
replicas: 3Задаём количество реплик в кластере. У нас оно равно числу рабочих нод K8s.
annotations: scheduler.alpha.kubernetes.io/affinity: > { "podAntiAffinity": { "requiredDuringSchedulingIgnoredDuringExecution": [{ "labelSelector": { "matchExpressions": [{ "key": "app", "operator": "In", "values": ["rabbitmq"] }] }, "topologyKey": "kubernetes.io/hostname" }] } }При падении одной из нод K8s statefulset стремится сохранить количество экземпляров в наборе, поэтому создаёт по нескольку подов на одной и той же ноде K8s. Это поведение совершенно нежелательно и в принципе бессмысленно. Поэтому мы прописываем anti-affinity правило для подов из statefulset. Правило делаем жестким (Required), чтобы kube-scheduler не мог его нарушать при планировании подов.
Суть проста: планировщику запрещено размещать (в пределах namespace) более одного пода с тегом app:rabbitmq на каждой ноде. Ноды различаем по значению метки kubernetes.io/hostname. Теперь если по какой-то причине число работающих нод K8S меньше, чем требуемое количество реплик в StatefulSet, новые реплики не будут создаваться, пока снова не появится свободная нода.
serviceAccountName: rabbitmqПрописываем ServiceAccount, под которым работают наши поды.
image: rabbitmq:3.7Образ RabbitMQ совершенно стандартный и берётся с docker hub, не требует никакой пересборки и доработки напильником.
- name: rabbitmq-data mountPath: /var/lib/rabbitmq/mnesia Персистентные данные у RabbitMQ хранятся в /var/lib/rabbitmq/mnesia. Здесь мы монтируем наш Persistent Volume Claim в эту папку, чтобы при перезапуске подов/нод или даже всего StatefulSet данные (как служебные, в том числе о собранном кластере, так и пользовательские) оставались в целости и сохранности. Можно встретить некоторые примеры, когда персистентной делают папку /var/lib/rabbitmq/ целиком. Мы пришли к выводу, что это не самая лучшая идея, так как при этом начинает запоминаться и вся информация, заданная конфигами Rabbit. То есть для того, чтобы изменить что-то в конфигурационном файле, требуется почистить персистентное хранилище, что очень неудобно в эксплуатации.
- name: HOSTNAME valueFrom: fieldRef: fieldPath: metadata.name - name: NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: RABBITMQ_USE_LONGNAME value: "true" - name: RABBITMQ_NODENAME value: "rabbit@$(HOSTNAME).rabbitmq-internal.$(NAMESPACE).svc.cluster.local" Этим набором переменных окружения мы, во-первых, говорим RabbitMQ использовать в качестве идентификатора членов кластера FQDN-имя, а во-вторых, задаём формат этого имени. Формат описывался ранее при разборе конфига.
- name: K8S_SERVICE_NAME value: "rabbitmq-internal"Имя headless сервиса для общения членов кластера.
- name: RABBITMQ_ERLANG_COOKIE value: "mycookie"Содержимое Erlang Cookie должно быть одинаковым на всех нодах кластера, нужно прописать ваше собственное значение. Нода с отличающимся cookie не сможет войти в кластер.
volumes: - name: rabbitmq-data persistentVolumeClaim: claimName: rabbitmq-dataОпределяем подключаемый том из созданного ранее Persistent Volume Claim.
На этом мы закончили с настройкой в K8s. В результате получился кластер RabbitMQ, равномерно распределяющий очереди по нодам и устойчивый к проблемам в среде выполнения.
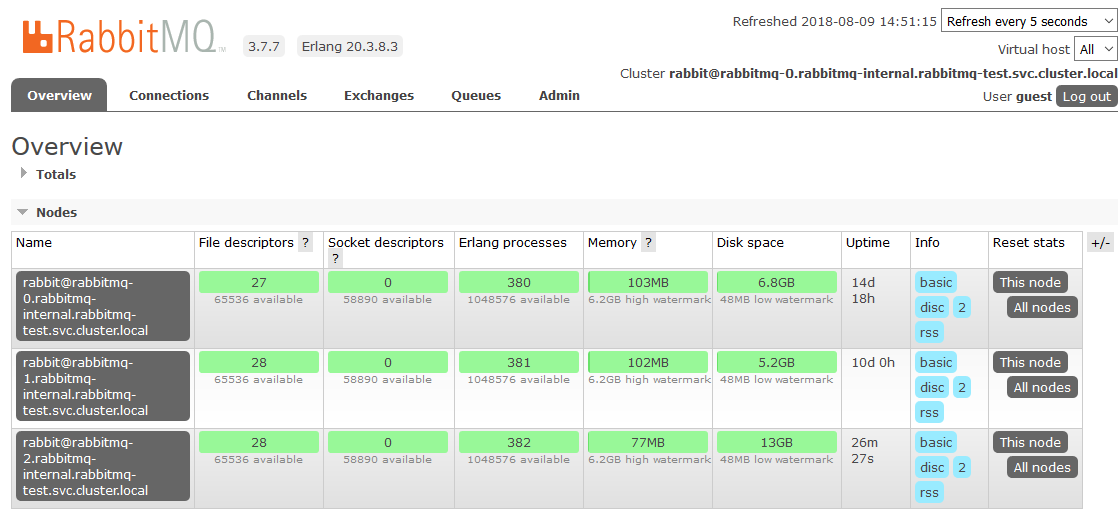
При недоступности одной из нод кластера, очереди, содержащиеся на ней, перестанут быть доступны, всё остальное продолжит работу. Как только нода вернётся в строй, она вернётся в кластер, и очереди, для которых она была Master’ом, снова станут работоспособными с сохранением всех содержащихся в них данных (если не сломалось персистентное хранилище, разумеется). Все эти процессы проходят полностью автоматически и не требуют вмешательства.
Бонус: настраиваем HA
В одном из проектов был нюанс. В требованиях звучало полное зеркалирование всех содержащихся в кластере данных. Это нужно, чтобы в ситуации, когда хотя бы одна нода кластера работоспособна, с точки зрения прикладного приложения всё продолжало работать. Этот момент никак не связан именно с K8s, описываем просто в качестве mini how-to.
Для включения полного HA необходимо в RabbitMQ dashboard на вкладке Admin -> Policies создать Policy. Имя произвольное, Pattern пустой (все очереди), в Definitions добавить два параметра: ha-mode: all, ha-sync-mode: automatic.
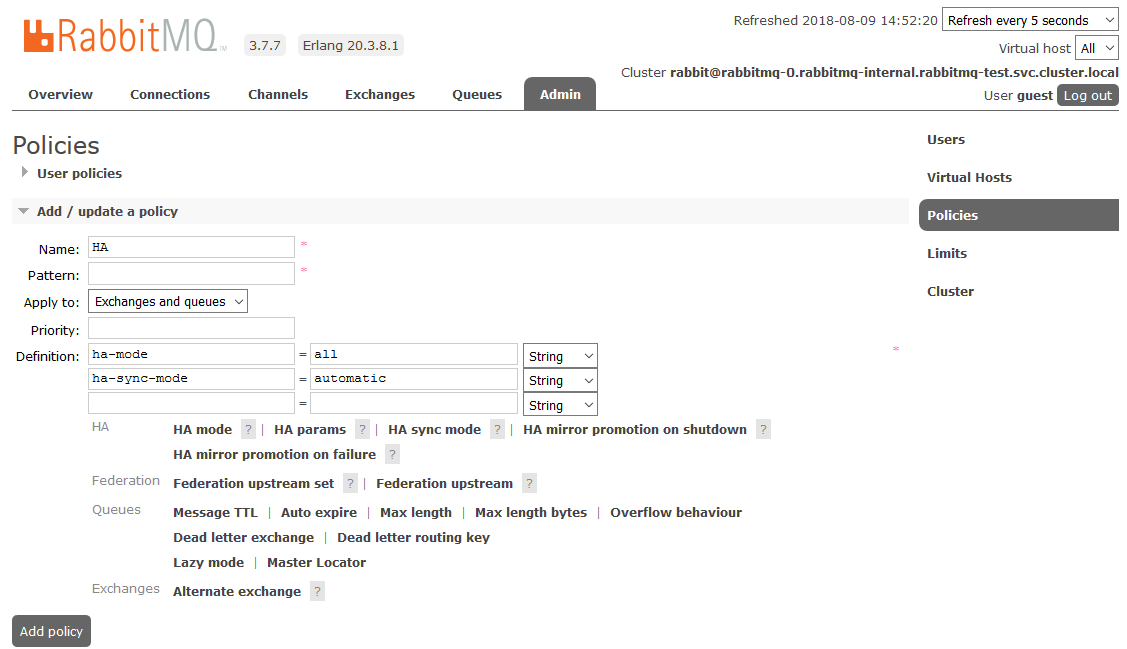
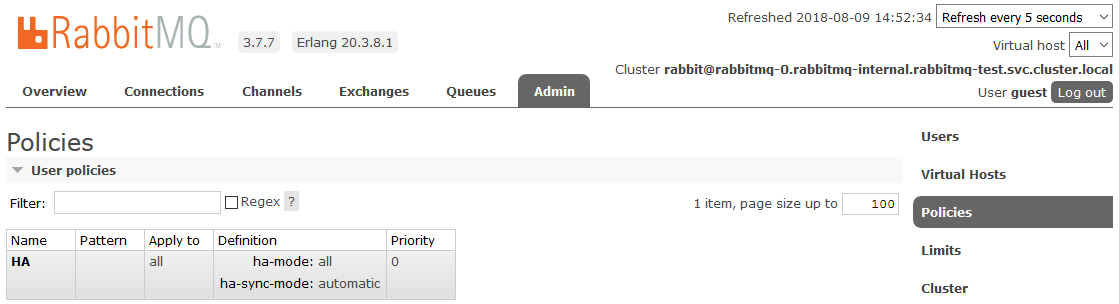
После этого все создаваемые в кластере очереди будут находиться в режиме High Availability: при недоступности Master-ноды новым мастером автоматически будет выбираться один из Slave’ов. А данные, поступающие в очередь, будут зеркалироваться на все ноды кластера. Что, собственно, и требовалось получить.
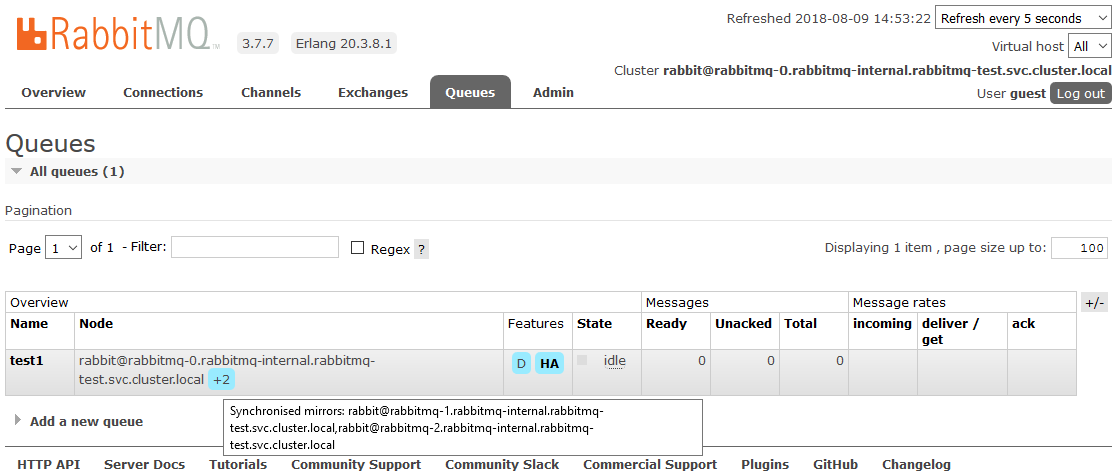
Подробнее прочитать о HA в RabbitMQ можно тут
Полезная литература:
- Репозиторий RabbitMQ Peer Discovery Kubernetes Plugin
- Пример конфигурации для деплоя RabbitMQ в K8S
- Описание принципов формирования кластера, механизма Peer Discovery и плагинов для него
- Эпичная дискуссия о правильной настройке hostname-based discovery
- Руководство по кластеризации RabbitMQ
- Описание split-brain проблем при кластеризации и способов их решения
- High Availability Queues в RabbitMQ
- Настройка Policies
Успехов!
ссылка на оригинал статьи https://habr.com/company/eastbanctech/blog/419817/
Добавить комментарий