Вы знаете, сколько вам недоплачивают? А может быть, переплачивают? Каково соотношение резюме и вакансий на позицию, схожую с вашей?
Отвечая на этот вопрос, можно врать себе, можно нагло врать, а можно оперировать статистикой.
На самом деле, каждая уважающая себя контора регулярно проводит мониторинг заработных плат, чтобы ориентироваться в интересующем ее сегменте рынка труда. Однако несмотря на то, что задача нужная и важная, не все готовы за это платить сторонним сервисам.
В этом случае, чтобы избавить HR от необходимости регулярно перебирать вручную сотни вакансий и резюме, эффективнее один раз написать небольшое приложение, которое будет делать это самостоятельно, а на выходе предоставлять результат в виде красивого дашборда с таблицами, графиками, возможностью фильтрации и выгрузки данных. Например, такого:
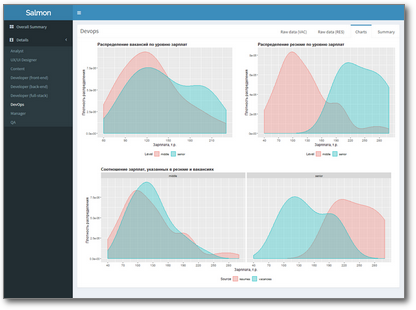
Посмотреть вживую (и даже понажимать кнопки) можно здесь.
В этой статье я расскажу о том, как писала такое приложение, и с какими подводными камнями столкнулась по пути.
Постановка задачи
Требуется написать приложение, которое будет собирать с hh.ru данные по вакансиям и резюме на определенные позиции (Back-end/Front-end/Full-stack developer, DevOps, QA, Project Manager, Systems Analyst, etc.) в Санкт-Петербурге и выдавать минимальное, среднее и максимальное значение зарплатных ожиданий и предложений для специалистов уровня junior, middle и senior для каждой из указанных профессий.
Обновлять данные предполагалось приблизительно раз в полгода, но не чаще, чем раз в месяц.
Первый прототип
Написанный на чистом shiny, с красивой бутстраповской схемой, на первый взгляд он вышел очень даже ничего: простой, а главное — понятный. Главная страница приложения содержит самое необходимое: для каждой специальности доступно среднее значение зарплат и зарплатных ожиданий (уровень middle), также есть дата последнего обновления данных и кнопка Update. Табы в хедере — по количеству рассматриваемых специальностей — содержат таблицы с полными собранными данными и графики.
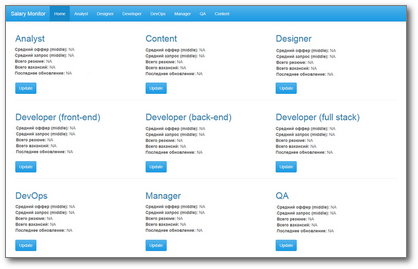
Если пользователь видит, что данные не обновлялись слишком давно, он жмет кнопку «Update» у соответствующей специальности. Приложение уходит в бессознанку думать минут на 5, сотрудник уходит пить кофе. По возвращении его ждут обновленные данные на главной странице и на соответствующей табе.
Как минимум, то, что для обновления данных по всем девяти специальностям пользователю нужно нажать кнопку Update у каждой плитки — и так девять раз.
Почему бы не сделать одну кнопку «Update» на все? Дело в том, — и это вторая проблема — что на каждый запрос («обновить и обработать данные по менеджерам», «обновить и обработать данные по QA» и т.д.) уходило по 5-10 минут, что само по себе непозволительно долго. Единый запрос на обновление всех данных превратил бы 5 минут в 45, а то и во все 60. Пользователь не может столько ждать.
Даже несколько функций withProgress(), оборачивавших процессы сбора и обработки данных, и делавших таким образом пользовательское ожидание более осмысленным, не слишком спасали ситуацию.
Третья проблема этого прототипа в том, при добавлении еще десятка профессий (ну а вдруг) мы столкнулись бы с тем, что место в хедере заканчивается.
Этих трех причин мне было достаточно, чтобы полностью переосмыслить подход к построению приложения и UX. Если найдете больше — велком в комменты.
Были у этого прототипа и сильные стороны, а именно:
- Обобщенный подход к интерфейсу и бизнес-логике: вместо того, чтобы копипастить, выносим одинаковые куски в отдельную функцию с параметрами.
Например, вот так выглядит «плитка» одной специальности на главной странице:
tile <- function(title, midsal = NA, midsalres = NA, total.res = NA, total.vac = NA, updated = NA) { return( column(width = 4, h2(title), strong("Средний оффер (middle):"), midsal, br(), strong("Средний запрос (middle):"), midsalres, br(), strong("Всего резюме:"), total.res, br(), strong("Всего вакансий: "), total.vac, br(), strong("Последнее обновление: "), updated, br(), br(), actionButton(inputId = paste0(tolower(prof), "Btn"), label = "Update", class = "btn-primary") ) ) }
- Динамическое формирование UI вплоть до айдишников (inputId) в коде, через
inputId = paste0(параметр, "Btn"), см. пример выше. Этот подход показал себя крайне удобным, потому что предстояло проинициализировать с десяток элементов управления, помноженный на количество профессий. - Он работал 🙂
Собранные данные складывались в файлики .csv по разным профессиям (append = TRUE), а затем читались оттуда при запуске приложения. При появлении новых данных они добавлялись в соответствующий файл, а средние значения пересчитывались.
Пара слов о разделителях
Важный нюанс: стандартные разделители для csv-файлов — запятая или точка с запятой — не слишком подходят для нашего случая, ведь нередко можно встретить вакансии и резюме с заголовками вроде «Швец, жнец, игрец (дуда; html/css)». Поэтому я сразу решила выбрать что-нибудь более экзотичное, и мой выбор пал на |.
Все шло хорошо до тех пор, пока при очередном запуске я не обнаружила дату в столбце с валютой и далее съехавшие столбцы и, как следствие, запоротые графики. Стала разбираться. Как выяснилось, мою систему сломала прекрасная девушка-«Data Analyst | Business Analyst». С тех пор я использую в качестве разделителя \x1B — символ ESC. До сих пор не подводил.
Assign или не assign?
Во время работы над этим проектом функция assign стала для меня настоящим открытием: можно динамически формировать имена переменных и прочих дата фреймов, круто же!
Разумеется, я хочу держать исходные данные в отдельных data frames для разных вакансий. А писать «designer.vac = data.frame(…), analyst.vac = data.frame(…)» не хочу. Поэтому код инициализации этих объектов при запуске приложения у меня выглядел так:
profs <- c("analyst", "designer", "developer", "devops", "manager", "qa") for (name in profs) { if (!exists(paste0(name, ".vac"))) assign(x = paste0(name, ".vac"), value = data.frame( URL = character() # ссылка на вакансию , id = numeric() # id вакансии , Name = character() # название вакансии , City = character() , Published = character() , Currency = character() , From = numeric() # ниж. граница зарплатной вилки , To = numeric() # верх. граница , Level = character() # jun/mid/sen , Salary = numeric() , stringsAsFactors = FALSE )) }
Но радость моя длилась не долго. Обращаться к таким объектам в дальнейшем через некий параметр уже не получалось, и это волей-неволей приводило к дублированию кода. При этом количество объектов росло в геометрической прогрессии, и в итоге стало легко запутаться в них и в вызовах assign.
Поэтому пришлось использовать другой подход, в конечном итоге оказавшийся гораздо более простым: использование списков.
profs <- list( devops = "devops" , analyst = c("systems+analyst", "business+analyst") , dev.full = "full+stack+developer" , dev.back = "back+end+developer" , dev.front = "front+end+developer" , designer = "ux+ui+designer" , qa = "QA+tester" , manager = "project+manager" , content = c("mathematics+teacher", "physics+teacher") ) for (name in names(profs)) { proflist[[name]] <- data.frame( URL = character() # ссылка на вакансию , id = numeric() # id вакансии , Name = character() # название вакансии , City = character() , Published = character() , Currency = character() , From = numeric() # ниж. граница зарплатной вилки , To = numeric() # верх. граница , Level = character() # jun/mid/sen , Salary = numeric() , stringsAsFactors = FALSE ) }
Обратите внимание, что вместо обычного вектора с названиями профессий, как раньше, я использую список, в который заодно вшила поисковые запросы, по которым ищутся данные по вакансиям и резюме для конкретной профессии. Так мне удалось избавиться от уродливого switch при вызове функции поиска вакансий.
Тоже, в общем-то, несложно. Вот вам сферический в вакууме пример для server.R:
lapply(seq_along(my.list.of.data.frames), function(x) { output[[paste0(names(my.list.of.data.frames)[x], ".dt")]] <- renderDataTable({ datatable(data = my.list.of.data.frames[[names(my.list.of.data.frames)[x]]]() , style = 'bootstrap', selection = 'none' , escape = FALSE) }) output[[paste0(names(my.list.of.data.frames)[x], ".plot")]] <- renderPlot( ggplot(na.omit(my.list.of.data.frames[[names(my.list.of.data.frames)[x]]]()), aes(...)) ) })
Отсюда вывод: списки — крайне удобная штука, позволяющая сократить количество кода и время на его обработку. (Поэтому — не assign.)
И в тот момент, когда я отвлеклась от рефакторинга на выступление Джо Ченга о дашбордах, пришло…
Переосмысление
Оказывается, в R есть специальный пакет, заточенный под создание дашбордов — shinydashboard. Он также использует bootstrap и помогает чуть проще организовать UI с лаконичным сайд-баром, который можно и вовсе скрыть безо всяких conditionalPanel(), позволяя пользователю сфокусироваться на изучении данных.
Оказывается, если HR проверяет данные раз в полгода, кнопка Update им не нужна. Вообще никакая. Это не совсем «static dashboard», но близкое к тому. Скрипт обновления данных можно реализовать совсем отдельно от shiny-приложения и запускать его по расписанию стандартным Scheduler’ом винды вашей ОС.
Это решает сразу две проблемы: долгого ожидания (если регулярно гонять скрипт в фоновом режиме, пользователь даже не заметит его работы, а только будет видеть всегда свежие данные) и избыточных действий, требовавшихся от пользователя, чтобы обновить данные. Раньше требовалось девять кликов (по одному на каждую специальность), теперь требуется ноль. Кажется, мы вышли на прирост эффективности, стремящийся к бесконечности!
Оказывается, код в разных частях приложения исполняется неодинаковое количество раз. Не буду останавливаться на этом подробно, при желании лучше ознакомиться с наглядным разъяснением в докладе. Обозначу лишь основную идею: манипуляции с данными внутри ggplot(), на лету — зло, и чем больше кода удастся вынести на верхние уровни приложения, тем лучше. Производительность при этом вырастает в разы.
На самом деле, чем дальше я смотрела доклад, тем яснее понимала, насколько не по фен-шую был организован код в моем первом прототипе, и в какой-то момент стало очевидно, что проект проще переписать, чем отрефакторить. Но как бросить свое детище, когда в него вложено столько сил?
То, что мертво, умереть не может
— подумала я и переписала проект с нуля, причем в этот раз
- вынесла весь код сбора данных по вакансиям и резюме (по сути — весь ETL-процесс) в отдельный скрипт, который можно запускать независимо от shiny-приложения, избавив пользователя от томительного ожидания;
- использовала reactiveFileReader() для чтения заранее собранных данных из csv-файлов, обеспечив актуальность исходных данных в моем приложении без необходимости перезапуска и лишних действий пользователя;
- избавилась от assign() в пользу работы со списками и активно использовала lapply() там, где раньше были циклы;
- переработала UI приложения с использованием пакета shinydashboard, в качестве бонуса — не нужно беспокоиться о нехватке места на экране;
- в несколько раз сократила суммарный объем приложения (с ~1800 до 360 строк кода).
Теперь решение работает следующим образом.
- ETL-скрипт запускается раз в месяц (здесь инструкция, как это сделать) и добросовестно проходит по всем профессиям, собирая с hh сырые данные по вакансиям и резюме.
Причем данные по вакансиям берутся через API сайта (мне удалось частично переиспользовать код из предыдущего проекта), а вот за каждым резюме пришлось парсить веб-страницы силами пакета rvest, потому что доступ соответствующему методу API теперь стал платным. Можно догадаться, как это отразилось на скорости работы скрипта. - Собранные данные причесываются — подробно и с примерами кода процесс описан здесь. Обработанные данные сохраняются на диск в отдельные файлы вида hist/profession-hist-vac.csv и hist/profession-hist-res.csv. Кстати, выбросы в данных вроде таких могут приводить к курьезам, будьте бдительны 🙂
Для каждой профессии скрипт берет дополненный файл с историческими данными, выбирает наиболее актуальные — те, что не старше месяца с даты последнего обновления — и формирует новые csv-файлы вида data.res/profession-res-recent.csv и data.vac/profession-vac-recent.csv. С этими-то данными и работает итоговое приложение… - … которое после запуска считывает содержимое фолдеров резюме и вакансий (data.res и data.vac соответственно), а затем каждый час проверяет, не было ли в файлах изменений. Делать это с помощью reactiveFileReader() гораздо эффективнее по затрачиваемым ресурсам и скорости выполнения, чем с используя invalidateLater(). Если в файлах были изменения, тогда таблицы с исходными данными автоматически обновляются, а средние значения и графики пересчитываются, потому что зависят от reactiveValues(), то есть никакого дополнительного кода для обработки этой ситуации не требуется.
- На главной странице теперь находится таблица, в которой приводятся min, median и max значения зарплатных ожиданий и предложений по каждой специальности для каждого из найденных уровней (все по ТЗ). Кроме того, можно посмотреть графики на табах с подробной информацией и выгрузить данные в формате .xlsx (мало ли для чего HR потребуются эти цифры).
{kind=link}
Всё. Получается, единственная кнопка, доступная теперь пользователю на нашем дашборде, это кнопка Download. И это к лучшему: чем меньше у пользователя кнопок, тем меньше шансов вызвать необработанное исключение в них запутаться.
Вместо эпилога
Сегодня приложение собирает и анализирует данные только по Санкт-Петербургу. Учитывая то, что главный стейкхолдер осталась довольна, а самая частая реакция — «здорово, а на Москву такое можно сделать?», эксперимент считаю удавшимся.
Посмотреть приложение можно по этой ссылке, а весь исходный код (вместе с примерами готовых файлов) доступен здесь.
Кстати, приложение называется Salary Monitor, сокращенно Salmon — «лосось».

ссылка на оригинал статьи https://habr.com/post/417991/
Добавить комментарий