 Под «шаблонами» в контексте C++ обычно понимаются вполне конкретные языковые конструкции. Есть простые шаблоны, которые просто упрощают работу с однотипным кодом. Если у шаблона какой-то из параметров сам по себе шаблон, то это уже, можно сказать, шаблоны второго порядка и генерируют они другие шаблоны в зависимости от своих параметров. Но что если и их возможностей недостаточно и проще генерировать сразу исходный текст? Много исходного текста?
Под «шаблонами» в контексте C++ обычно понимаются вполне конкретные языковые конструкции. Есть простые шаблоны, которые просто упрощают работу с однотипным кодом. Если у шаблона какой-то из параметров сам по себе шаблон, то это уже, можно сказать, шаблоны второго порядка и генерируют они другие шаблоны в зависимости от своих параметров. Но что если и их возможностей недостаточно и проще генерировать сразу исходный текст? Много исходного текста?
Любителям Python а также HTML-вёрстки знакомо средство (движок, библиотека) для работы с текстовыми шаблонами под названием Jinja2. На вход этот движок получает файл-шаблон, в котором текст может быть перемешан с управляющими конструкциями, на выходе получается чистый текст, в котором все управляющие конструкции заменены текстом в соответствии с заданными извне (или изнутри) параметрами. Грубо говоря, это что-то вроде ASP-страниц (или C++-препроцессора), только язык разметки другой.
До сих пор реализация этого движка была только для Python. Теперь же она есть и для C++. О том, как и почему так вышло, и пойдёт речь в статье.
Зачем я вообще за это взялся
Действительно, а зачем? Ведь есть же Python, для него — отличная реализация, куча фичей, цельная спецификация на язык. Бери и пользуйся! Не нравится Python — можно взять Jinja2CppLight или inja, частичные порты Jinja2 на C++. Можно, в конце концов, взять C++-порт {{Mustache}}. Дьявол, как обычно, в деталях. Вот мне, скажем, понадобилась функциональность фильтров от Jinja2 и возможности конструкции extends, которая позволяет создавать расширяемые шаблоны (а ещё макросы и include, но это потом). И ни одна из упомянутых реализаций этого не поддерживает. Мог ли я обойтись без всего этого? Тоже хороший вопрос. Судите сами. Есть у меня проект, цель которого создание C++-to-C++ автогенератора boilerplate-кода. Этот автогенератор получает на вход, скажем, вручную написанный заголовочный файл со структурами или enum’ами и генерирует на его основе функции сериализации/десериализации или, скажем, конвертации элементов enum’ов в строки (и обратно). Подробнее об этой утилите можно послушать в моих докладах здесь (eng) или здесь (рус).
Так вот, типовая задача, решаемая в процессе работы над утилитой — это создание заголовочных файлов, у каждого из которых есть шапка (с ifdef’ами и include’ами), тело с основным содержимым и подвал. Причём основное содержимое — это сгенерированные декларации, распиханные по namespace’ам. В исполнении на C++ код создания такого заголовочного файла выглядит примерно так (и это ещё не всё):
void Enum2StringGenerator::WriteHeaderContent(CppSourceStream &hdrOs) { std::vector<reflection::EnumInfoPtr> enums; WriteNamespaceContents(hdrOs, m_namespaces.GetRootNamespace(), [this, &enums](CppSourceStream &os, reflection::NamespaceInfoPtr ns) { for (auto& enumInfo : ns->enums) { WriteEnumToStringConversion(os, enumInfo); WriteEnumFromStringConversion(os, enumInfo); enums.push_back(enumInfo); } }); hdrOs << "\n\n"; { out::BracedStreamScope flNs("\nnamespace flex_lib", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline const char* Enum2String($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } { hdrOs << out::new_line(1) << "template<>"; out::BracedStreamScope body("inline $enumFullQualifiedName$ String2Enum<$enumFullQualifiedName$>(const char* itemName)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::StringTo$enumName$(itemName);"; } } } { out::BracedStreamScope flNs("\nnamespace std", "\n\n", 0); hdrOs << out::new_line(1) << flNs; for (reflection::EnumInfoPtr enumInfo : enums) { auto scopedParams = MakeScopedParams(hdrOs, enumInfo); out::BracedStreamScope body("inline std::string to_string($enumFullQualifiedName$ e)", "\n"); hdrOs << out::new_line(1) << body; hdrOs << out::new_line(1) << "return $namespaceQual$::$enumName$ToString(e);"; } } } // Enum item to string conversion writer void Enum2StringGenerator::WriteEnumToStringConversion(CppSourceStream &hdrOs, const reflection::EnumInfoPtr &enumDescr) { auto scopedParams = MakeScopedParams(hdrOs, enumDescr); out::BracedStreamScope fnScope("inline const char* $enumName$ToString($enumScopedName$ e)", "\n"); hdrOs << out::new_line(1) << fnScope; { out::BracedStreamScope switchScope("switch (e)", "\n"); hdrOs << out::new_line(1) << switchScope; out::OutParams innerParams; for (auto& i : enumDescr->items) { innerParams["itemName"] = i.itemName; hdrOs << out::with_params(innerParams) << out::new_line(-1) << "case $prefix$$itemName$:" << out::new_line(1) << "return \"$itemName$\";"; } } hdrOs << out::new_line(1) << "return \"Unknown Item\";"; } // String to enum conversion writer void Enum2StringGenerator::WriteEnumFromStringConversion(CppSourceStream &hdrOs, const reflection::EnumInfoPtr &enumDescr) { auto params = MakeScopedParams(hdrOs, enumDescr); out::BracedStreamScope fnScope("inline $enumScopedName$ StringTo$enumName$(const char* itemName)", "\n"); hdrOs << out::new_line(1) << fnScope; { out::BracedStreamScope itemsScope("static std::pair<const char*, $enumScopedName$> items[] = ", ";\n"); hdrOs << out::new_line(1) << itemsScope; out::OutParams& innerParams = params.GetParams(); auto items = enumDescr->items; std::sort(begin(items), end(items), [](auto& i1, auto& i2) {return i1.itemName < i2.itemName;}); for (auto& i : items) { innerParams["itemName"] = i.itemName; hdrOs << out::with_params(innerParams) << out::new_line(1) << "{\"$itemName$\", $prefix$$itemName$},"; } } hdrOs << out::with_params(params.GetParams()) << R"( $enumScopedName$ result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "$enumName$"); return result;)"; } Причём код этот мало меняется от файла к файлу. Разумеется, для форматирования можно использовать clang-format. Но это не отменяет остальной ручной работы по генерации исходного текста.
И вот в один прекрасный момент я понял, что жизнь себе надо упрощать. Вариант с прикручиванием полноценного скриптового языка я не рассматривал из-за сложности поддержки итогового результата. А вот найти подходящий движок шаблонов — а почему бы и нет? Полез искать, нашёл, потом нашёл спецификацию на Jinja2 и понял, что это — именно то, что мне надо. Ибо в соответствии с этой спекой шаблоны для генерации заголовков выглядели бы так:
{% extends "header_skeleton.j2tpl" %} {% block generator_headers %} #include <flex_lib/stringized_enum.h> #include <algorithm> #include <utility> {% endblock %} {% block namespaced_decls %}{{super()}}{% endblock %} {% block namespace_content %} {% for enum in ns.enums | sort(attribute="name") %} {% set enumName = enum.name %} {% set scopeSpec = enum.scopeSpecifier %} {% set scopedName = scopeSpec ~ ('::' if scopeSpec) ~ enumName %} {% set prefix = (scopedName + '::') if not enumInfo.isScoped else (scopedName ~ '::' ~ scopeSpec ~ ('::' if scopeSpec)) %} inline const char* {{enumName}}ToString({{scopedName}} e) { switch (e) { {% for itemName in enum.items | map(attribute="itemName") | sort%} case {{prefix}}{{itemName}}: return "{{itemName}}"; {% endfor %} } return "Unknown Item"; } inline {{scopedName}} StringTo{{enumName}}(const char* itemName) { static std::pair<const char*, {{scopedName}}> items[] = { {% for itemName in enum.items | map(attribute="itemName") | sort %} {"{{itemName}}", {{prefix}}{{itemName}} } {{',' if not loop.last }} {% endfor %} }; {{scopedName}} result; if (!flex_lib::detail::String2Enum(itemName, items, result)) flex_lib::bad_enum_name::Throw(itemName, "{{enumName}}"); return result; } {% endfor %}{% endblock %} {% block global_decls %} {% for ns in [rootNamespace] recursive %} {% for enum in ns.enums %} template<> inline const char* flex_lib::Enum2String({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } template<> inline {{enum.fullQualifiedName}} flex_lib::String2Enum<{{enum.fullQualifiedName}}>(const char* itemName) { return {{enum.namespaceQualifier}}::StringTo{{enum.name}}(itemName); } inline std::string to_string({{enum.fullQualifiedName}} e) { return {{enum.namespaceQualifier}}::{{enum.name}}ToString(e); } {% endfor %} {{loop(ns.namespaces)}} {% endfor %} {% endblock %}  Была только одна проблема: ни один из найденных мною движков не поддерживал всего набора нужных мне фичей. Ну и, разумеется, каждый имел стандартный фатальный недостаток. Я подумал немного и решил, что ещё от одной реализации шаблонизатора миру сильно хуже не станет. Тем более что, по прикидкам, базовый функционал было реализовать не то чтобы сильно сложно. Ведь теперь в C++ есть regexp’ы!
Была только одна проблема: ни один из найденных мною движков не поддерживал всего набора нужных мне фичей. Ну и, разумеется, каждый имел стандартный фатальный недостаток. Я подумал немного и решил, что ещё от одной реализации шаблонизатора миру сильно хуже не станет. Тем более что, по прикидкам, базовый функционал было реализовать не то чтобы сильно сложно. Ведь теперь в C++ есть regexp’ы!
И так появился проект Jinja2Cpp. На счёт сложности реализации базового (совсем базового) функционала я почти угадал. В целом же — промахнулся аккурат на коэффициент Пи в квадрате: на написание всего нужного мне ушло чуть меньше трёх месяцев. Но когда всё было дописано, допилено и вставлено в “Автопрограммист” — я понял, что старался не зря. Фактически, утилита по генерации кода получила мощный скриптовый язык совмещённый с шаблонами, что открыло перед ней совершенно новые возможности для развития.
NB: У меня была мысль прикрутить Python (или Lua). Но никакой из существующих полноценных скриптовых движков не решает «из коробки» вопросы по генерации текста из шаблонов. То есть к Python пришлось бы всё равно прикручивать ту же Jinja2, а для Lua искать что-то своё. Зачем мне нужно было это лишнее звено?
Реализация парсера
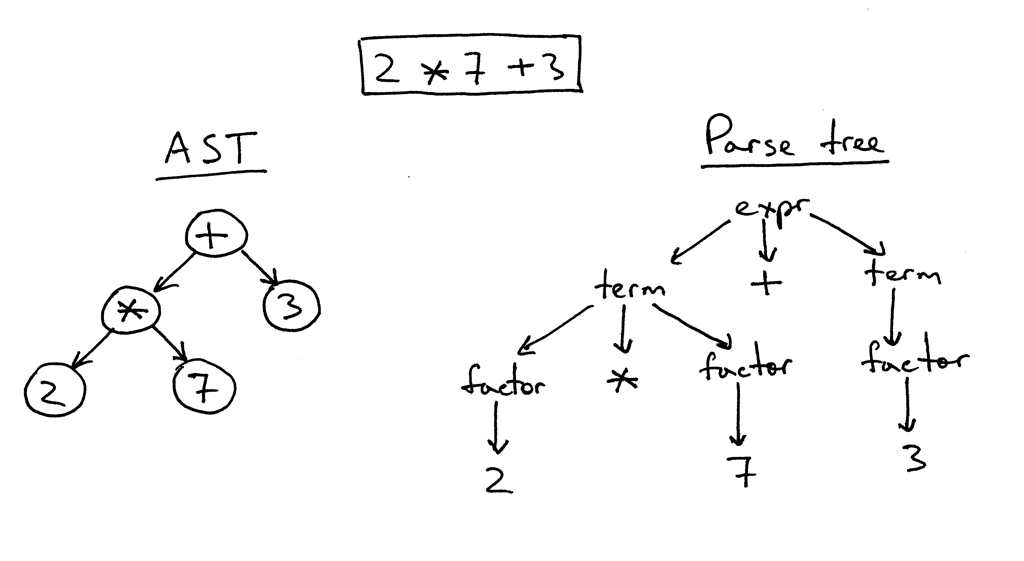 Идея структуры Jinja2-шаблонов довольно проста. Если в тексте встречается что-то, заключенное в пару «{{» / «}}» — то это «что-то» — выражение, которое должно быть вычислено, преобразовано в текстовое представление и вставлено в итоговый результат. Внутри пары «{%» / «%}» — операторы типа for, if, set и т. п. Ну а в «{#» / «#}» — комментарии. Изучив реализацию Jinja2CppLight, я решил, что пытаться вручную найти в тексте шаблона все эти управляющие конструкции — не очень удачная идея. Поэтому я вооружился довольно простым regexp’ом: ((\{\{)|(\}\})|(\{%)|(%\})|(\{#)|(#\})|(\n)), с помощью которого побил текст на нужные фрагменты. И назвал это грубой фазой парсинга. На начальном этапе работы идея показала свою эффективность (да, собственно, и до сих пор показывает), но, по-хорошему, в будущем её надо будет отрефакторить, так как сейчас на текст шаблона накладываются незначительные ограничения: экранирование пар «{{» и «}}» в тексте обрабатывается слишком «в лоб».
Идея структуры Jinja2-шаблонов довольно проста. Если в тексте встречается что-то, заключенное в пару «{{» / «}}» — то это «что-то» — выражение, которое должно быть вычислено, преобразовано в текстовое представление и вставлено в итоговый результат. Внутри пары «{%» / «%}» — операторы типа for, if, set и т. п. Ну а в «{#» / «#}» — комментарии. Изучив реализацию Jinja2CppLight, я решил, что пытаться вручную найти в тексте шаблона все эти управляющие конструкции — не очень удачная идея. Поэтому я вооружился довольно простым regexp’ом: ((\{\{)|(\}\})|(\{%)|(%\})|(\{#)|(#\})|(\n)), с помощью которого побил текст на нужные фрагменты. И назвал это грубой фазой парсинга. На начальном этапе работы идея показала свою эффективность (да, собственно, и до сих пор показывает), но, по-хорошему, в будущем её надо будет отрефакторить, так как сейчас на текст шаблона накладываются незначительные ограничения: экранирование пар «{{» и «}}» в тексте обрабатывается слишком «в лоб».
Во второй фазе детально парсится только то, что оказалось внутри «скобок». И вот тут пришлось повозиться. Что в inja, что в Jinja2CppLight, парсер выражений довольно простой. В первом случае — на тех же regexp’ах, во втором — рукописный, но поддерживающий только очень простые конструкции. О поддержке фильтров, тестеров, сложной арифметики или индексирования там речи даже не идёт. А именно этих возможностей Jinja2 мне и хотелось больше всего. Поэтому у меня не оставалось другого выхода, как напедалить полноценный LL(1)-парсер (местами — контекстно-зависимый), реализующий необходимую грамматику. Лет десять-пятнадцать назад я бы, наверное, взял бы для этого Bison или ANTLR и реализовал бы парсер с их помощью. Лет семь бы назад я бы попробовал Boost.Spirit. Сейчас же я просто реализовал нужный мне парсер, работающий методом рекурсивного спуска, без порождения лишних зависимостей и значительного увеличения времени компиляции, как это случилось бы в случае использования внешних утилит или Boost.Spirit. На выходе парсера я получаю AST (для выражений или для операторов), которое и сохраняется как шаблон, готовый для последующего рендеринга.
ExpressionEvaluatorPtr<FullExpressionEvaluator> ExpressionParser::ParseFullExpression(LexScanner &lexer, bool includeIfPart) { ExpressionEvaluatorPtr<FullExpressionEvaluator> result; LexScanner::StateSaver saver(lexer); ExpressionEvaluatorPtr<FullExpressionEvaluator> evaluator = std::make_shared<FullExpressionEvaluator>(); auto value = ParseLogicalOr(lexer); if (!value) return result; evaluator->SetExpression(value); ExpressionEvaluatorPtr<ExpressionFilter> filter; if (lexer.PeekNextToken() == '|') { lexer.EatToken(); filter = ParseFilterExpression(lexer); if (!filter) return result; evaluator->SetFilter(filter); } ExpressionEvaluatorPtr<IfExpression> ifExpr; if (lexer.PeekNextToken() == Token::If) { if (includeIfPart) { lexer.EatToken(); ifExpr = ParseIfExpression(lexer); if (!ifExpr) return result; evaluator->SetTester(ifExpr); } } saver.Commit(); return evaluator; } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalOr(LexScanner& lexer) { auto left = ParseLogicalAnd(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalOr) { lexer.ReturnToken(); return left; } auto right = ParseLogicalOr(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalOr, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalAnd(LexScanner& lexer) { auto left = ParseLogicalCompare(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); if (lexer.NextToken() != Token::LogicalAnd) { lexer.ReturnToken(); return left; } auto right = ParseLogicalAnd(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(BinaryExpression::LogicalAnd, left, right); } ExpressionEvaluatorPtr<Expression> ExpressionParser::ParseLogicalCompare(LexScanner& lexer) { auto left = ParseStringConcat(lexer); if (!left) return ExpressionEvaluatorPtr<Expression>(); auto tok = lexer.NextToken(); BinaryExpression::Operation operation; switch (tok.type) { case Token::Equal: operation = BinaryExpression::LogicalEq; break; case Token::NotEqual: operation = BinaryExpression::LogicalNe; break; case '<': operation = BinaryExpression::LogicalLt; break; case '>': operation = BinaryExpression::LogicalGt; break; case Token::GreaterEqual: operation = BinaryExpression::LogicalGe; break; case Token::LessEqual: operation = BinaryExpression::LogicalLe; break; case Token::In: operation = BinaryExpression::In; break; case Token::Is: { Token nextTok = lexer.NextToken(); if (nextTok != Token::Identifier) return ExpressionEvaluatorPtr<Expression>(); std::string name = AsString(nextTok.value); bool valid = true; CallParams params; if (lexer.NextToken() == '(') params = ParseCallParams(lexer, valid); else lexer.ReturnToken(); if (!valid) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<IsExpression>(left, std::move(name), std::move(params)); } default: lexer.ReturnToken(); return left; } auto right = ParseStringConcat(lexer); if (!right) return ExpressionEvaluatorPtr<Expression>(); return std::make_shared<BinaryExpression>(operation, left, right); }
class ExpressionFilter; class IfExpression; class FullExpressionEvaluator : public ExpressionEvaluatorBase { public: void SetExpression(ExpressionEvaluatorPtr<Expression> expr) { m_expression = expr; } void SetFilter(ExpressionEvaluatorPtr<ExpressionFilter> expr) { m_filter = expr; } void SetTester(ExpressionEvaluatorPtr<IfExpression> expr) { m_tester = expr; } InternalValue Evaluate(RenderContext& values) override; void Render(OutStream &stream, RenderContext &values) override; private: ExpressionEvaluatorPtr<Expression> m_expression; ExpressionEvaluatorPtr<ExpressionFilter> m_filter; ExpressionEvaluatorPtr<IfExpression> m_tester; }; class ValueRefExpression : public Expression { public: ValueRefExpression(std::string valueName) : m_valueName(valueName) { } InternalValue Evaluate(RenderContext& values) override; private: std::string m_valueName; }; class SubscriptExpression : public Expression { public: SubscriptExpression(ExpressionEvaluatorPtr<Expression> value, ExpressionEvaluatorPtr<Expression> subscriptExpr) : m_value(value) , m_subscriptExpr(subscriptExpr) { } InternalValue Evaluate(RenderContext& values) override; private: ExpressionEvaluatorPtr<Expression> m_value; ExpressionEvaluatorPtr<Expression> m_subscriptExpr; }; class ConstantExpression : public Expression { public: ConstantExpression(InternalValue constant) : m_constant(constant) {} InternalValue Evaluate(RenderContext&) override { return m_constant; } private: InternalValue m_constant; }; class TupleCreator : public Expression { public: TupleCreator(std::vector<ExpressionEvaluatorPtr<>> exprs) : m_exprs(std::move(exprs)) { } InternalValue Evaluate(RenderContext&) override; private: std::vector<ExpressionEvaluatorPtr<>> m_exprs; };
struct Statement : public RendererBase { }; template<typename T = Statement> using StatementPtr = std::shared_ptr<T>; template<typename CharT> class TemplateImpl; class ForStatement : public Statement { public: ForStatement(std::vector<std::string> vars, ExpressionEvaluatorPtr<> expr, ExpressionEvaluatorPtr<> ifExpr, bool isRecursive) : m_vars(std::move(vars)) , m_value(expr) , m_ifExpr(ifExpr) , m_isRecursive(isRecursive) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void SetElseBody(RendererPtr renderer) { m_elseBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: void RenderLoop(const InternalValue& val, OutStream& os, RenderContext& values); private: std::vector<std::string> m_vars; ExpressionEvaluatorPtr<> m_value; ExpressionEvaluatorPtr<> m_ifExpr; bool m_isRecursive; RendererPtr m_mainBody; RendererPtr m_elseBody; }; class ElseBranchStatement; class IfStatement : public Statement { public: IfStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void AddElseBranch(StatementPtr<ElseBranchStatement> branch) { m_elseBranches.push_back(branch); } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; std::vector<StatementPtr<ElseBranchStatement>> m_elseBranches; }; class ElseBranchStatement : public Statement { public: ElseBranchStatement(ExpressionEvaluatorPtr<> expr) : m_expr(expr) { } bool ShouldRender(RenderContext& values) const; void SetMainBody(RendererPtr renderer) { m_mainBody = renderer; } void Render(OutStream& os, RenderContext& values) override; private: ExpressionEvaluatorPtr<> m_expr; RendererPtr m_mainBody; }; Узлы AST имеют привязку только к тексту шаблона и преобразуются в итоговые значения в момент рендеринга с учётом текущего контекста рендеринга и его параметров. Это позволило сделать шаблоны thread-safe. Но подробнее об этом в части, касающейся собственно рендеринга.
В качестве первичного токенайзера я выбрал библиотеку lexertk. Она имеет нужную мне лицензию и header-only. Пришлось, правда, отрезать от неё все навороты по подсчёту баланса скобок и прочее и оставить только собственно токенайзер, который (после небольшой рихтовки напильником) научился работать не только с char, но и с wchar_t-символами. Сверху этот токенайзер был мною обёрнут ещё одним классом, выполняющим три основных функции: а) абстрагирует код парсера от типа символов, с которыми ведётся работа, б) распознаёт ключевые слова, специфичные для Jinja2 и в) предоставляет удобный интерфейс для работы с потоком токенов:
class LexScanner { public: struct State { Lexer::TokensList::const_iterator m_begin; Lexer::TokensList::const_iterator m_end; Lexer::TokensList::const_iterator m_cur; }; struct StateSaver { StateSaver(LexScanner& scanner) : m_state(scanner.m_state) , m_scanner(scanner) { } ~StateSaver() { if (!m_commited) m_scanner.m_state = m_state; } void Commit() { m_commited = true; } State m_state; LexScanner& m_scanner; bool m_commited = false; }; LexScanner(const Lexer& lexer) { m_state.m_begin = lexer.GetTokens().begin(); m_state.m_end = lexer.GetTokens().end(); Reset(); } void Reset() { m_state.m_cur = m_state.m_begin; } auto GetState() const { return m_state; } void RestoreState(const State& state) { m_state = state; } const Token& NextToken() { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur ++; } void EatToken() { if (m_state.m_cur != m_state.m_end) ++ m_state.m_cur; } void ReturnToken() { if (m_state.m_cur != m_state.m_begin) -- m_state.m_cur; } const Token& PeekNextToken() const { if (m_state.m_cur == m_state.m_end) return EofToken(); return *m_state.m_cur; } bool EatIfEqual(char type, Token* tok = nullptr) { return EatIfEqual(static_cast<Token::Type>(type), tok); } bool EatIfEqual(Token::Type type, Token* tok = nullptr) { if (m_state.m_cur == m_state.m_end) { if(type == Token::Type::Eof && tok) *tok = EofToken(); return type == Token::Type::Eof; } if (m_state.m_cur->type == type) { if (tok) *tok = *m_state.m_cur; ++ m_state.m_cur; return true; } return false; } private: State m_state; static const Token& EofToken() { static Token eof; eof.type = Token::Eof; return eof; } };Таким образом, несмотря на то, что движок может работать как с char, так и с wchar_t-шаблонами, основной код разбора от типа символа не зависит. Но подробнее об этом — в разделе, посвящённом приключениям с типом символов.
Отдельно пришлось повозиться с управляющими конструкциями. В Jinja2 многие из них — парные. Например, for/endfor, if/endif, block/endblock и т. п. Каждый элемент пары идёт в своих «скобках», а между элементами может быть куча всего: и просто текст, и другие управляющие блоки. Поэтому алгоритм разбора шаблона пришлось делать на основе стека, к текущему верхнему элементу которого «цепляются» все вновь найденные конструкции и инструкции, а также фрагменты простого текста между ними. Посредством этого же стека проверяется отсутствие разбалансировки типа if-for-endif-endfor. В результате всего этого код получился не такой «компактный» как, скажем, у Jinja2CppLight (или inja), где вся реализация — в одном исходнике (или заголовке). Но логика разбора и, собственно, грамматика в коде видны более явно, что упрощает его поддержку и расширение. По крайней мере именно к этому я стремился. Минимизировать количество зависимостей или объём кода всё равно не получится, значит надо делать его более понятным.
В следующей части речь пойдёт про процесс рендеринга шаблонов, а пока — ссылки:
Спецификация Jinja2: http://jinja.pocoo.org/docs/2.10/templates/
Реализация Jinja2Cpp: https://github.com/flexferrum/Jinja2Cpp
Реализация Jinja2CppLight: https://github.com/hughperkins/Jinja2CppLight
Реализация inja: https://github.com/pantor/inja
Утилита для генерации кода на основе шаблонов Jinja2: https://github.com/flexferrum/autoprogrammer/tree/jinja2cpp_refactor
ссылка на оригинал статьи https://habr.com/post/416581/
Добавить комментарий