 Это вторая часть истории о портировании шаблонного движка Jinja2 на C++. Первую можно почитать здесь: Шаблоны третьего порядка, или как я портировал Jinja2 на C++. В ней речь пойдёт о процессе рендеринга шаблонов. Или, иначе говоря, о написании «с нуля» интерпретатора питоноподобного языка.
Это вторая часть истории о портировании шаблонного движка Jinja2 на C++. Первую можно почитать здесь: Шаблоны третьего порядка, или как я портировал Jinja2 на C++. В ней речь пойдёт о процессе рендеринга шаблонов. Или, иначе говоря, о написании «с нуля» интерпретатора питоноподобного языка.
Рендеринг как таковой
После парсинга шаблон превращается в дерево, содержащее узлы трёх типов: простой текст, вычисляемые выражения и управляющие конструкции. Соответственно, в процессе рендеринга простой текст должен без каких-либо изменений помещаться в выходной поток, выражения — вычисляться, преобразовываться в текст, который и будет помещён в поток, а управляющие конструкции — исполняться. С первого взгляда ничего сложного в том, чтобы реализовать процесс рендернга, не было: надо просто обойти все узлы дерева, всё вычислить, всё исполнить и сгенерировать текст. Всё просто. Ровно до тех пор, пока соблюдаются два условия: а) вся работа ведётся со строками только одного типа (string или wstring); б) используются только очень простые выражения и базовые. Собственно, именно с такими ограничениями и реализованы inja и Jinja2CppLight. В случае же моей Jinja2Cpp оба условия не срабатывают. Во-первых, мною изначально закладывалась прозрачная поддержка обоих типов строк. Во-вторых, вся разработка затевалась как раз ради поддержки спецификации Jinja2 почти в полном объёме, а это, в сущности, полноценный скриптовый язык. Поэтому с рендерингом пришлось поковыряться больше, чем с парсингом.
Вычисление выражений
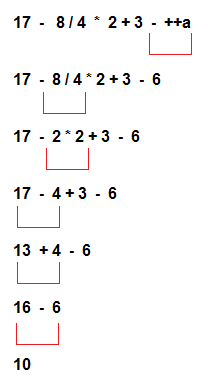 Шаблон не был бы шаблоном, если бы его нельзя было параметризовать. В принципе, Jinja2 допускает вариант шаблонов «в себе» — все нужные переменные можно задать внутри самого шаблона, а потом его отрендерить. Но работа в шаблоне с параметрами, полученными «снаружи», остаётся основным кейсом. Таким образом, результат вычисления выражения зависит от того, какие переменные (параметры) с каким значениями видны в точки вычисления. И загвоздка в том, что в Jinja2 есть не просто области видимости (которые могут быть вложенными), но ещё и с непростыми правилами «прозрачности». Например, вот есть шаблон:
Шаблон не был бы шаблоном, если бы его нельзя было параметризовать. В принципе, Jinja2 допускает вариант шаблонов «в себе» — все нужные переменные можно задать внутри самого шаблона, а потом его отрендерить. Но работа в шаблоне с параметрами, полученными «снаружи», остаётся основным кейсом. Таким образом, результат вычисления выражения зависит от того, какие переменные (параметры) с каким значениями видны в точки вычисления. И загвоздка в том, что в Jinja2 есть не просто области видимости (которые могут быть вложенными), но ещё и с непростыми правилами «прозрачности». Например, вот есть шаблон:
{% set param1=10 %} {{ param1 }}
В результате его рендеринга будет получен текст 10
Вариант чуть сложнее:
{% set param1=10 %} {{ param1 }} {% for param1 in range(10) %}-{{ param1 }}-{% endfor %} {{ param1 }}
Отрендерится уже в 10-0--1--2--3--4--5--6--7--8--9-10
Цикл порождает новый скоуп, в котором можно определить свои параметры-переменные, и эти параметры не будут видны за пределами скоупа, как и не будут перетирать значения одноименных параметров во внешнем. Ещё хитрее с конструкциями extends/block, но об этом уже лучше почитать в документации на Jinja2.
Таким образом, появляется контекст вычислений. А точнее, рендеринга вообще:
class RenderContext { public: RenderContext(const InternalValueMap& extValues, IRendererCallback* rendererCallback); InternalValueMap& EnterScope(); void ExitScope(); auto FindValue(const std::string& val, bool& found) const { for (auto p = m_scopes.rbegin(); p != m_scopes.rend(); ++ p) { auto valP = p->find(val); if (valP != p->end()) { found = true; return valP; } } auto valP = m_externalScope->find(val); if (valP != m_externalScope->end()) { found = true; return valP; } found = false; return m_externalScope->end(); } auto& GetCurrentScope() const; auto& GetCurrentScope(); auto& GetGlobalScope(); auto GetRendererCallback(); RenderContext Clone(bool includeCurrentContext) const; private: InternalValueMap* m_currentScope; const InternalValueMap* m_externalScope; std::list<InternalValueMap> m_scopes; IRendererCallback* m_rendererCallback; };
Контекст содержит в себе указатель на коллекцию значений, полученных при вызове функции рендеринга, список (стек) скоупов, текущий активный скоуп и указатель на callback-интерфейс, с различными полезными для рендеринга функциями. Но о нём чуть позже. Функция поиска параметра последовательно поднимается по списку контекстов вплоть до внешнего, пока не найдёт нужный параметр.
Теперь немного о самих параметрах. С точки зрения внешнего интерфейса (и его пользователей) Jinja2 поддерживает следующий список допустимых типов:
- Числа (int, double)
- Строки (narrow, wide)
- bool
- Массивы (больше похожие на безразмеиные кортежи)
- Словари
- Отрефлексированные C++-структуры
Всё это описывается специальным типом данных, созданным на базе boost::variant:
using ValueData = boost::variant<EmptyValue, bool, std::string, std::wstring, int64_t, double, boost::recursive_wrapper<ValuesList>, boost::recursive_wrapper<ValuesMap>, GenericList, GenericMap>; class Value { public: Value() = default; template<typename T> Value(T&& val, typename std::enable_if<!std::is_same<std::decay_t<T>, Value>::value>::type* = nullptr) : m_data(std::forward<T>(val)) { } Value(const char* val) : m_data(std::string(val)) { } template<size_t N> Value(char (&val)[N]) : m_data(std::string(val)) { } Value(int val) : m_data(static_cast<int64_t>(val)) { } const ValueData& data() const {return m_data;} ValueData& data() {return m_data;} private: ValueData m_data; };
Разумеется, элементы массивов и словарей могут быть любых из перечисленных типов. Но проблема в том, что для внутреннего использования этот набор типов слишком узкий. Для упрощения реализации нужна была поддержка следующих дополнительных типов:
- Строка в целевом формате. Может быть narrow или wide в зависимости от того, какой тип шаблона рендерится.
- callable-тип
- Узел AST-дерева
- Пара «ключ-значение»
Путем такого расширения появилась возможность передавать через контекст рендеринга служебные данные, которые иначе бы пришлось «светить» в публичных заголовках, а также более удачно обощать некоторые алгоритмы, работающие с массивами и словарями.
Boost::variant был выбран не случайно. Его богатые возможности используются для работы с параметрами конкретных типов. В Jinja2CppLight для этих же целей используются полиморфные классы, а в inja — система типов библиотеки nlohmann json. Обе эти альтернативы, увы, мне не подошли. Причина: возможность n-арной диспетчеризации для boost::variant (а теперь — и std::variant). Для вариантного типа можно сделать статический визитор, который принимает два конкретных хранимых типа, и натравить его на пару значений. И все сработает как надо! В случае же с полиморфными классами или простыми union’ами такого удобства не выйдет:
struct StringJoiner : BaseVisitor<> { using BaseVisitor::operator (); InternalValue operator() (EmptyValue, const std::string& str) const { return str; } InternalValue operator() (const std::string& left, const std::string& right) const { return left + right; } };
Вызывается такой визитор предельно просто:
InternalValue delimiter = m_args["d"]->Evaluate(context); for (const InternalValue& val : values) { if (isFirst) isFirst = false; else result = Apply2<visitors::StringJoiner>(result, delimiter); result = Apply2<visitors::StringJoiner>(result, val); }
Apply2 здесь — это обёртка над boost::apply_visitor, которая применяет визитор заданного шаблонном параметром типа к паре вариантных значений, делая предварительно некоторые преобразования, если это нужно. Если конструктору визитора требуются параметры — они передаются после объектов, к которым применяется визитор:
comparator = [](const KeyValuePair& left, const KeyValuePair& right) { return ConvertToBool(Apply2<visitors::BinaryMathOperation>(left.value, right.value, BinaryExpression::LogicalLt, BinaryExpression::CaseSensitive)); };
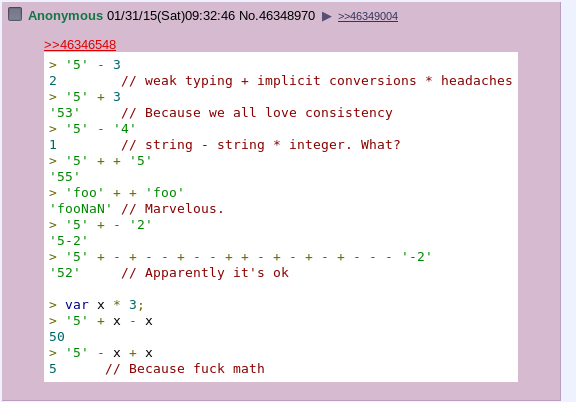 Таким образом, логика выполнения операций с параметрами выходит следующей: variant(ы) -> распаковка с помощью visitor’а -> выполнение нужного действия над конкретными значениями конкретных типов — > упаковка результата обратно в variant. И минимум подковерной магии. Можно было бы реализовать всё как в js: выполнять операции (например, сложения) в любом случае, выбрав некую систему преобразований строк в числа, чисел в строки, строки в списки и т. п. И получать при этом странные и неожиданные результаты. Я выбрал более простой и предсказуемый путь: если операция над значением (или парой значений) невозможна или алогична, то возвращается пустой результат. Поэтому при сложении числа со строкой можно в результате получить строку только в том случае, если используется операция конкатенации (‘~’). В противном случае результатом будет пустое значение. Приоритет операций определяется грамматикой, поэтому никаких дополнительных проверок при обработке AST делать уже не нужно.
Таким образом, логика выполнения операций с параметрами выходит следующей: variant(ы) -> распаковка с помощью visitor’а -> выполнение нужного действия над конкретными значениями конкретных типов — > упаковка результата обратно в variant. И минимум подковерной магии. Можно было бы реализовать всё как в js: выполнять операции (например, сложения) в любом случае, выбрав некую систему преобразований строк в числа, чисел в строки, строки в списки и т. п. И получать при этом странные и неожиданные результаты. Я выбрал более простой и предсказуемый путь: если операция над значением (или парой значений) невозможна или алогична, то возвращается пустой результат. Поэтому при сложении числа со строкой можно в результате получить строку только в том случае, если используется операция конкатенации (‘~’). В противном случае результатом будет пустое значение. Приоритет операций определяется грамматикой, поэтому никаких дополнительных проверок при обработке AST делать уже не нужно.
Фильтры и тесты
 То, что в других языках называется «стандартной библиотекой» в Jinja2 называется «фильтрами». В сущности, фильтр — это некая сложная операция над значением, стоящим слева от знака ‘|’, результатом работы которой будет новое значение. Фильтры можно выстраивать в цепочку, организуя пайплайн:
То, что в других языках называется «стандартной библиотекой» в Jinja2 называется «фильтрами». В сущности, фильтр — это некая сложная операция над значением, стоящим слева от знака ‘|’, результатом работы которой будет новое значение. Фильтры можно выстраивать в цепочку, организуя пайплайн:
{{ menuItems | selectattr('visible') | map(attribute='title') | map('upper') | join(' -> ') }}
Здесь из массива menuItems будут выбраны только те элементы, у которых атрибут visible выставлен в true, потом у этих элементов будет взят атрибут title, преобразован в верхний регистр, и получившийся список строк будет склеен с разделителем ‘ -> ‘ в одну строку. Или, скажем, во пример «из жизни»:
{% macro MethodsDecl(class, access) %} {% for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) %} {{ method.fullPrototype }}; {% endfor %} {% endmacro %}
{% macro MethodsDecl(class, access) %} {{ for method in class.methods | rejectattr('isImplicit') | selectattr('accessType', 'in', access) | map(attribute='fullPrototype') | join(';\n') }}; {% endmacro %}
Этот макрос перебирает все методы заданного класса, отбрасывает те, у которых атрибут isImplicit выставлен в true, из оставшихся выбирает те, у которых значение атрибута accessType совпадает с одним из заданных, и выводит их прототипы. Относительно наглядно. И уж всяко проще, чем трехэтажные циклы и if’ы городить. К слову, что-то похожее в C++ можно делать в рамках спецификации range v.3.
Собственно, основной промах по времени был связан с реализацией около сорока фильтров, которые я включил в базовый набор. С чего-то я взял, что справлюсь с этим за неделю-другую. Это было слишком оптимистично. И хотя типовая реализация фильтра довольно проста: взять значение и применить к нему некоторый функтор, их оказалось слишком много, и пришлось повозиться.
Отдельной интересной задачкой в процессе реализации стала логика обработки аргументов. В Jinja2, как и в питоне, передаваемые в вызов аргументы могут быть как именованные, так и позиционные. А параметры в объявлении фильтра могут быть как обязательные, так и опциональные (со значениями по-умолчанию). Причём, в отличие от C++, опциональные параметры могут находиться в любом месте объявления. Надо было придумать алгоритм совмещения этих двух списков с учётом разных кейсов. Вот, скажем, есть функция range: range([start, ]stop[, step]). Она может быть вызвана следующими способами:
range(10) // -> range(start = 0, stop = 10, step = 1) range(1, 10) // -> range(start = 1, stop = 10, step = 1) range(1, 10, 3) // -> range(start = 1, stop = 10, step = 3) range(step=2, 10) // -> range(start = 0, stop = 10, step = 2) range(2, step=2, 10) // -> range(start = 2, stop = 10, step = 2)
И так далее. И очень бы хотелось, чтобы в коде реализации функции фильтра не нужно было все эти кейсы учитывать. В итоге остановился на том, что в коде фильтра, тестера или функции параметры получаются строго по имени. И отдельная функция сопоставляет фактический список аргументов с ожидаемым списком параметров попутно проверяя, что все обязательные параметры тем или иным образом заданы:
ParsedArguments ParseCallParams(const std::initializer_list<ArgumentInfo>& args, const CallParams& params, bool& isSucceeded) { struct ArgInfo { ArgState state = NotFound; int prevNotFound = -1; int nextNotFound = -1; const ArgumentInfo* info = nullptr; }; boost::container::small_vector<ArgInfo, 8> argsInfo(args.size()); boost::container::small_vector<ParamState, 8> posParamsInfo(params.posParams.size()); isSucceeded = true; ParsedArguments result; int argIdx = 0; int firstMandatoryIdx = -1; int prevNotFound = -1; int foundKwArgs = 0; // Find all provided keyword args for (auto& argInfo : args) { argsInfo[argIdx].info = &argInfo; auto p = params.kwParams.find(argInfo.name); if (p != params.kwParams.end()) { result.args[argInfo.name] = p->second; argsInfo[argIdx].state = Keyword; ++ foundKwArgs; } else { if (argInfo.mandatory) { argsInfo[argIdx].state = NotFoundMandatory; if (firstMandatoryIdx == -1) firstMandatoryIdx = argIdx; } else { argsInfo[argIdx].state = NotFound; } if (prevNotFound != -1) argsInfo[prevNotFound].nextNotFound = argIdx; argsInfo[argIdx].prevNotFound = prevNotFound; prevNotFound = argIdx; } ++ argIdx; } int startPosArg = firstMandatoryIdx == -1 ? 0 : firstMandatoryIdx; int curPosArg = startPosArg; int eatenPosArgs = 0; // Determine the range for positional arguments scanning bool isFirstTime = true; for (; eatenPosArgs < posParamsInfo.size(); ++ eatenPosArgs) { if (isFirstTime) { for (; startPosArg < args.size() && (argsInfo[startPosArg].state == Keyword || argsInfo[startPosArg].state == Positional); ++ startPosArg) ; isFirstTime = false; continue; } int prevNotFound = argsInfo[startPosArg].prevNotFound; if (prevNotFound != -1) { startPosArg = prevNotFound; } else if (curPosArg == args.size()) { break; } else { int nextPosArg = argsInfo[curPosArg].nextNotFound; if (nextPosArg == -1) break; curPosArg = nextPosArg; } } // Map positional params to the desired arguments int curArg = startPosArg; for (int idx = 0; idx < eatenPosArgs && curArg != -1; ++ idx, curArg = argsInfo[curArg].nextNotFound) { result.args[argsInfo[curArg].info->name] = params.posParams[idx]; argsInfo[curArg].state = Positional; } // Fill default arguments (if missing) and check for mandatory for (int idx = 0; idx < argsInfo.size(); ++ idx) { auto& argInfo = argsInfo[idx]; switch (argInfo.state) { case Positional: case Keyword: continue; case NotFound: { if (!IsEmpty(argInfo.info->defaultVal)) result.args[argInfo.info->name] = std::make_shared<ConstantExpression>(argInfo.info->defaultVal); break; } case NotFoundMandatory: isSucceeded = false; break; } } // Fill the extra positional and kw-args for (auto& kw : params.kwParams) { if (result.args.find(kw.first) != result.args.end()) continue; result.extraKwArgs[kw.first] = kw.second; } for (auto idx = eatenPosArgs; idx < params.posParams.size(); ++ idx) result.extraPosArgs.push_back(params.posParams[idx]); return result; }
Вызывается он таким вот образом (для, скажем, range):
bool isArgsParsed = true; auto args = helpers::ParseCallParams({{"start"}, {"stop", true}, {"step"}}, m_params, isArgsParsed); if (!isArgsParsed) return InternalValue();
и возвращает следующую структуру:
struct ParsedArguments { std::unordered_map<std::string, ExpressionEvaluatorPtr<>> args; std::unordered_map<std::string, ExpressionEvaluatorPtr<>> extraKwArgs; std::vector<ExpressionEvaluatorPtr<>> extraPosArgs; ExpressionEvaluatorPtr<> operator[](std::string name) const { auto p = args.find(name); if (p == args.end()) return ExpressionEvaluatorPtr<>(); return p->second; } };
нужный аргумент из которой забирается просто по своему имени:
auto startExpr = args["start"]; auto stopExpr = args["stop"]; auto stepExpr = args["step"]; InternalValue startVal = startExpr ? startExpr->Evaluate(values) : InternalValue(); InternalValue stopVal = stopExpr ? stopExpr->Evaluate(values) : InternalValue(); InternalValue stepVal = stepExpr ? stepExpr->Evaluate(values) : InternalValue();
Аналогичный механизм применяется при работе с макросами и тестерами. И хотя, вроде бы, ничего сложного в том, чтобы описать аргументы каждого фильтра и теста, нет (как и реализовать его), но даже «базовый» набор, в который вошло примерно пятьдесят тех и других, оказался достаточно объёмным для реализации. И это при том условии, что в него не вошли всякие хитрые штуки, как форматирование строк под HTML (или C++), вывод значений в форматах типа xml или json, и тому подобные вещи.
В следующей части речь пойдёт о реализации работы с несколькими шаблонами (export, include, макросы), а также про увлекательные приключения с реализацией обработки ошибок и работе со строками разной ширины.
Традиционно, ссылки:
Спецификация Jinja2: http://jinja.pocoo.org/docs/2.10/templates/
Реализация Jinja2Cpp: https://github.com/flexferrum/Jinja2Cpp
ссылка на оригинал статьи https://habr.com/post/419011/
Добавить комментарий