Java REST Service в Школе Программистов HeadHunter
Привет хабр, мы хотим рассказать об одном из проектов школы программистов Headhunter 2018. Ниже статья нашего выпускника, в которой он расскажет об опыте, полученном во время обучения.

Всем привет. В этом году я окончил Школу Программистов hh и в этом посте расскажу об учебном проекте, в котором участвовал. Во время обучения в школе, и в особенности на проекте, мне не хватало примера боевого приложения (а еще лучше гайда), в котором можно было бы подсмотреть, как правильно разделить логику и построить масштабируемую архитектуру. Все статьи, которые я находил, были трудны для понимания новичка, т.к. либо в них активно применяли IoC без исчерпывающих объяснений, как добавить новые компоненты или модифицировать старые, либо они были архаичными и содержали тонну конфигов на xml и фронтенда на jsp. Я же старался ориентироваться на свой уровень до обучения, т.е. практически нулевой с небольшими оговорками, так что эта статья должна стать полезной для будущих учеников школы, а также самоучек-энтузиастов, решивших начать писать на java.
Дано (постановка задачи)
Команда — 5 человек. Срок — 3 месяца, в конце каждого — демо. Цель — сделать приложение, помогающее HR сопровождать сотрудников на испытательном сроке, автоматизируя все процессы, какие получится. На входе нам объяснили, как сейчас устроен испытательный срок (ИС): как только становится известно, что выходит новый сотрудник, HR начинает пинать будущего руководителя, чтобы тот поставил задачи на ИС, причем это нужно успеть сделать до первого рабочего дня. В день выхода сотрудника на работу HR проводит welcome-встречу, рассказывает об инфраструктуре компании и вручает задачи на ИС. Спустя 1,5 и 3 месяца проводятся промежуточная и итоговая встречи HR, руководителя и сотрудника, на которых обсуждаются успехи прохождения и составляется бланк о результатах. В случае успеха, после итоговой встречи сотруднику вручают распечатанный опросник новичка (вопросы в стиле «оцените удовольствие от ИС») и заводят на HRов задачу в jira оформить сотруднику ДМС.
Десигн
Мы решили сделать для каждого сотрудника персональную страницу, на которой будет отображена общая информация (ФИО, отдел, руководитель, и т. п.), поле для комментариев и истории изменений, прикрепленные файлы (задачи на ИС, опросник) и воркфлоу сотрудника, отражающий уровень прохождения ИС. Воркфлоу было решено разбить на 8 этапов, а именно:
- 1-й этап — добавление сотрудника: становится выполненным сразу после регистрации нового сотрудника в системе HRом. При этом HRу отправляются три календаря на велком, промежуточную и итоговую встречу.
- 2-й этап — согласование задач на ИС: руководителю отправляется форма для постановки задач на ИС, которую после заполнения получит HR. Далее HR распечатывает их, подписывает и ставит в интерфейсе отметку о завершении этапа.
- 3-й этап — welcome-встреча: HR проводит встречу и нажимает кнопку «Этап завершен».
- 4-й этап — промежуточная встреча: аналогично третьему этапу
- 5-й этап — результаты промежуточной встречи: HR заполняет результаты на странице сотрудника и нажимает «Далее».
- 6-й этап — итоговая встреча: аналогично третьему этапу
- 7-й этап — результаты итоговой встречи: аналогично пятому этапу
- 8-й этап — завершение ИС: в случае успешного прохождения ИС сотруднику на e-mail высылается ссылка с формой опросника, а в jira автоматически создается задача на оформление ДМС (до нас задачу заводили руками).
У всех этапов есть время, по истечении которого этап считается просроченным и подсвечивается красным, а на почту приходит уведомление. Время окончания должно быть редактируемым, например, на случай, если промежуточная встреча выпадает на праздничный день или по каким-либо обстоятельствам встречу необходимо перенести.
К сожалению, нарисованных на листочке/досках прототипов не сохранилось, но в конце будут скриншоты готового приложения.
Эксплуатация
Одна из целей школы — подготовить учеников к работе в крупных проектах, поэтому процесс выпуска задач у нас был подобающим.
По окончании работы над задачей мы отдаем ее на ревью_1 другому ученику из команды для исправления очевидных ошибок/обмена опытом. Затем происходит ревью_2 — задачку проверяют два ментора, которые следят за тем, чтобы мы не выпускали говнокод на пару с ревьювером_1. Далее предполагалось тестирование, но этот этап не очень целесообразен, учитывая масштаб школьного проекта. Так что пройдя ревью мы считали, что задача готова к выпуску.
Теперь пару слов про деплой. Приложение должно быть все время доступно в сети с любых компьютеров. Для этого мы купили дешевенькую виртуалку (за 100 руб/мес), но, как я узнал позже, все можно было устроить бесплатно и по-модному в докере на AWS. Для непрерывной интеграции мы выбрали Travis. Если кто не знает (лично я до школы вообще не слышал про continuous integration), это такая крутая штука, которая будет мониторить ваш github и при появлении нового коммита (как настроите) собирать код в jar, отправлять на сервер и перезапускать приложение автоматически. Как именно проводить сборку, описывается в трэвисовском ямле в корне проекта, он достаточно похож на bash, так что думаю комментариев не потребуется. Также мы купили домен www.adaptation.host, чтобы не прописывать некрасивый айпишник в адресную строку на демо. Еще мы настроили postfix (для отправки почты), apache (не nginx, т. к. apache был из коробки) и сервер jira (trial). Фронтенд и бекенд сделали двумя отдельными сервисами, которые будут общаться по http (#2к18, #микросервисы). На этом часть статьи «в школе программистов HeadHunter» плавно заканчивается, и мы переходим к java rest service.
Бекенд
0. Введение
Мы использовали следующие технологии:
- JDK 1.8;
- Maven 3.5.2;
- Postgres 9.6;
- Hibernate 5.2.10;
- Jetty 9.4.8;
- Jersey 2.27.
В качестве фреймворка мы взяли NaB 3.5.0 от hh. Во-первых, он используется в HeadHunter, а во-вторых, из коробки содержит jetty, jersey, hibernate, embedded postgres, о чем написано на гитхабе. Уточню коротко для начинающих: jetty — это веб-сервер, который занимается идентификацией клиентов и организации сессии для каждого из них; jersey — фреймворк, помогающий удобно создавать RESTful сервис; hibernate — ORM для упрощения работы с базой; maven — сборщик java проекта.
Покажу простой пример, как с этим работать. Я создал небольшой тестовый репозиторий, в который добавил две сущности: пользователя и резюме, а также ресурсы их создания и получения со связью OneToMany/ManyToOne. Для запуска достаточно склонировать репозиторий и выполнить mvn clean install exec:java в корне проекта. Прежде чем комментировать код, расскажу про структуру нашего сервиса. Она выглядит примерно так:
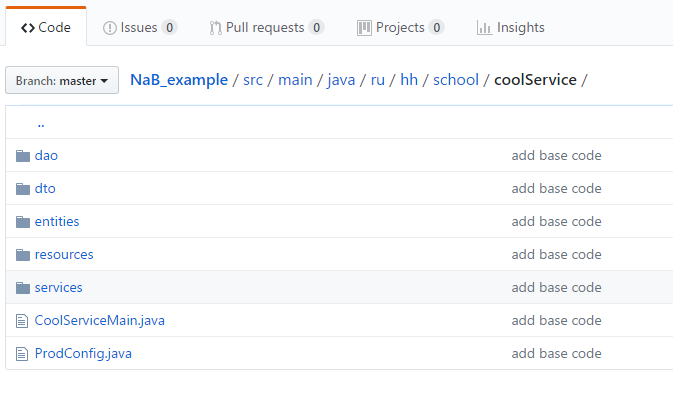
Основные директории:
- Services — главная директория в приложении, здесь хранится вся бизнес-логика. В других местах работы с данными без веских причин быть не должно.
- Resources — обработчики урлов, прослойка между сервисами и фронтендом. Здесь допускается валидация входящих данных и конвертация выходящих, но не бизнес-логика.
- Dao (Data Access Object) — прослойка между базой и сервисами. В дао должны содержаться только фундаментальные базовые операции: добавить, считать, обновить, удалить один/все.
- Entity — объекты, которыми ORM обменивается с базой. Как правило, они напрямую соответствуют таблицам и должны содержать все поля, что и сущность в базе с соответствующими типами.
- Dto (Data Transfer Object) — аналог энтити, только для ресурсов (фронта), помогает формировать json из данных, которые мы хотим отправить/получить.
1. База
По-хорошему следовало бы использовать рядом установленный postgres, как в основном приложении, но я хотел чтобы тестовый пример был простым и запускался одной командой, поэтому взял встроенную HSQLDB. Подключение базы в нашу инфраструктуру осуществляется путем добавления DataSource в ProdConfig (также не забудьте сказать hibernate, какую базу вы используете):
@Bean(destroyMethod = "shutdown") DataSource dataSource() { return new EmbeddedDatabaseBuilder() .setType(EmbeddedDatabaseType.HSQL) .addScript("db/sql/create-db.sql") .build(); }
Скрипт создания таблиц я вынес в файл create-db.sql. Вы можете добавить и другие скрипты, которые проинициализируют базу данными. В нашем легковесном примере с in_memory базой можно было обойтись вообще без скриптов. Если в настройках hibernate.properties указать hibernate.hbm2ddl.auto=create, то hibernate сам создаст таблицы по entity при запуске приложения. Но если понадобится иметь в базе что-то, чего в entity нет, то без файлика не обойтись. Лично я привык разделять базу и приложение, поэтому обычно не доверяю hibernate заниматься такими делами.
db/sql/create-db.sql:
CREATE TABLE employee ( id INTEGER IDENTITY PRIMARY KEY, first_name VARCHAR(256) NOT NULL, last_name VARCHAR(256) NOT NULL, email VARCHAR(128) NOT NULL ); CREATE TABLE resume ( id INTEGER IDENTITY PRIMARY KEY, employee_id INTEGER NOT NULL, position VARCHAR(128) NOT NULL, about VARCHAR(256) NOT NULL, FOREIGN KEY (employee_id) REFERENCES employee(id) );
2. Entity
entities/employee:
@Entity @Table(name = "employee") public class Employee { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) @Column(name = "id", nullable = false) private Integer id; @Column(name = "first_name", nullable = false) private String firstName; @Column(name = "last_name", nullable = false) private String lastName; @Column(name = "email", nullable = false) private String email; @OneToMany(mappedBy = "employee") @OrderBy("id") private List<Resume> resumes; //..geters and seters.. }
entities/resume:
@Entity @Table(name = "resume") public class Resume { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) private Integer id; @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "employee_id") private Employee employee; @Column(name = "position", nullable = false) private String position; @Column(name = "about") private String about; //..geters and seters.. }
Энтити ссылаются друг на друга не полем класса, а полностью объектом родителя/наследника. Таким образом, мы можем получить рекурсию, когда попытаемся взять из базы Employee, для которого вытянутся резюме, для которых… Чтобы этого не случилось, мы указали аннотации @OneToMany(mappedBy = "employee") и @ManyToOne(fetch = FetchType.LAZY). Они будут учтены в сервисе, при выполнении транзакции на запись/чтение из базы. Настройка FetchType.LAZY не обязательна, но использование ленивой связи облегчает транзакцию. Так, если в транзакции мы получаем из базы резюме и не обращаемся к его владельцу, то и сущность employee загружена не будет. Вы можете убедиться в этом сами: убрать FetchType.LAZY и посмотреть в дебаге, что возвращается из сервиса вместе с резюме. Но следует быть аккуратным — если мы не загрузили employee в транзакции, то обращение к полям employee вне транзакции может вызвать LazyInitializationException.
3. Dao
В нашем случае EmployeeDao и ResumeDao практически идентичны, поэтому приведу сюда только одну из них
EmployeeDao:
public class EmployeeDao { private final SessionFactory sessionFactory; @Inject public EmployeeDao(SessionFactory sessionFactory) { this.sessionFactory = sessionFactory; } public void save(Employee employee) { sessionFactory.getCurrentSession().save(employee); } public Employee getById(Integer id) { return sessionFactory.getCurrentSession().get(Employee.class, id); } }
Аннотация @Inject означает, что в конструкторе нашего dao, используется Dependency Injection. В моей прошлой жизни физика, который парсил файлики, строил графики по результатам числаков и худо-бедно разобрался в ООП, в гайдах по java подобные конструкции казались чем-то невменяемым. И в школе, пожалуй, именно эта тема является самой неочевидной, имхо. К счастью, о DI есть множество материалов в интернете. Если совсем лень читать, то первый месяц можно придерживаться правила: новые ресурсы/сервисы/дао регистрируем в нашем контекст-конфиге, энтити добавляем в маппинг. Если есть необходимость использовать одни сервисы/дао в других, их нужно добавить в конструкторе с аннотацией inject, как показано выше, и спринг инициализирует все за вас. Но потом разобраться с DI все равно придется.
4. Dto
Dto, как и dao, практически идентичны для employee и resume. Рассмотрим здесь только employeeDto. Нам понадобится два класса: EmployeeCreateDto, необходимый при создании сотрудника; EmployeeDto, использующийся при получении (содержит дополнительные поля id и resumes). Поле id добавлено, чтобы в будущим, по запросам снаружи, мы могли работать с employee, не проводя предварительный поиск сущности по email. Поле resumes, чтобы получать сотрудника вместе со всеми его резюме в одном запросе. Можно было бы обойтись и с одной dto на все операции, но тогда для списка всех резюме конкретного сотрудника нам бы пришлось создавать дополнительный ресурс, вроде getResumesByEmployeeEmail, загрязнять код кастомными запросами к базе и перечеркивать все удобства предоставляемые ORM.
EmployeeCreateDto:
public class EmployeeCreateDto { public String firstName; public String lastName; public String email; }
EmployeeDto:
public class EmployeeDto { public Integer id; public String firstName; public String lastName; public String email; public List<ResumeDto> resumes; public EmployeeDto(){ } public EmployeeDto(Employee employee){ id = employee.getId(); firstName = employee.getFirstName(); lastName = employee.getLastName(); email = employee.getEmail(); if (employee.getResumes() != null) { resumes = employee.getResumes().stream().map(ResumeDto::new).collect(Collectors.toList()); } } }
Еще раз обращаю внимание на то, что писать логику в dto настолько неприлично, что все поля обозначаются как public, чтобы не использовать геттеров и сеттеров.
5. Сервис
EmployeeService:
public class EmployeeService { private EmployeeDao employeeDao; private ResumeDao resumeDao; @Inject public EmployeeService(EmployeeDao employeeDao, ResumeDao resumeDao) { this.employeeDao = employeeDao; this.resumeDao = resumeDao; } @Transactional public EmployeeDto createEmployee(EmployeeCreateDto employeeCreateDto) { Employee employee = new Employee(); employee.setFirstName(employeeCreateDto.firstName); employee.setLastName(employeeCreateDto.lastName); employee.setEmail(employeeCreateDto.email); employeeDao.save(employee); return new EmployeeDto(employee); } @Transactional public ResumeDto createResume(ResumeCreateDto resumeCreateDto) { Resume resume = new Resume(); resume.setEmployee(employeeDao.getById(resumeCreateDto.employeeId)); resume.setPosition(resumeCreateDto.position); resume.setAbout(resumeCreateDto.about); resumeDao.save(resume); return new ResumeDto(resume); } @Transactional(readOnly = true) public EmployeeDto getEmployeeById(Integer id) { return new EmployeeDto(employeeDao.getById(id)); } @Transactional(readOnly = true) public ResumeDto getResumeById(Integer id) { return new ResumeDto(resumeDao.getById(id)); } }
Те самые транзакции, которые уберегают нас от LazyInitializationException (и не только). Для понимания транзакций в hibernate рекомендую отличный труд на хабре (читать далее…), который здорово помог мне в свое время.
6. Ресурсы
Наконец, добавим ресурсы создания и получения наших сущностей:
EmployeeResource:
@Path("/") @Singleton public class EmployeeResource { private final EmployeeService employeeService; public EmployeeResource(EmployeeService employeeService) { this.employeeService = employeeService; } @GET @Produces("application/json") @Path("/employee/{id}") @ResponseBody public Response getEmployee(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getEmployeeById(id)) .build(); } @POST @Produces("application/json") @Path("/employee/create") @ResponseBody public Response createEmployee(@RequestBody EmployeeCreateDto employeeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createEmployee(employeeCreateDto)) .build(); } @GET @Produces("application/json") @Path("/resume/{id}") @ResponseBody public Response getResume(@PathParam("id") Integer id) { return Response.status(Response.Status.OK) .entity(employeeService.getResumeById(id)) .build(); } @POST @Produces("application/json") @Path("/resume/create") @ResponseBody public Response createResume(@RequestBody ResumeCreateDto resumeCreateDto){ return Response.status(Response.Status.OK) .entity(employeeService.createResume(resumeCreateDto)) .build(); } }
Produces(“application/json”) нужен, чтобы json и dto корректно преобразовывались друг в друга. Он требует зависимости pom.xml:
<dependency> <groupId>org.glassfish.jersey.media</groupId> <artifactId>jersey-media-json-jackson</artifactId> <version>${jersey.version}</version> </dependency>
Другие json-конверторы почему-то выставляют невалидный mediaType.
7. Результат
Запустим и проверим, что у нас получилось (mvn clean install exec:java в корне проекта). Порт, на котором запускается приложение, указывается в service.properties. Создадим пользователя и резюме. Я делаю это с помощью curl, но вы можете использовать postman, если презираете консоль.
curl --header "Content-Type: application/json" \ --request POST \ --data '{"firstName": "Jason", "lastName": "Statham", "email": "jasonst@t.ham"}' \ http://localhost:9999/employee/create curl --header "Content-Type: application/json" \ --request POST \ --data '{"employeeId": 0, "position": "Voditel", "about": "Opyt raboty perevozchikom 15 let"}' \ http://localhost:9999/resume/create curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0 curl --header "Content-Type: application/json" --request GET http://localhost:9999/employee/0
Все работает отлично. Таким образом, мы получили бекенд, предоставляющий апи. Теперь можно запускать сервис с фронтендом и рисовать соответствующие формы. Это неплохой фундамент приложения, который вы можете использовать, чтобы стартовать свое, конфигурируя различные компоненты по мере развития проекта.
Заключение
Код основного приложения содержится в рабочем состоянии на гитхабе с инструкцией по запуску во вкладке wiki.Обещанные скриншоты:
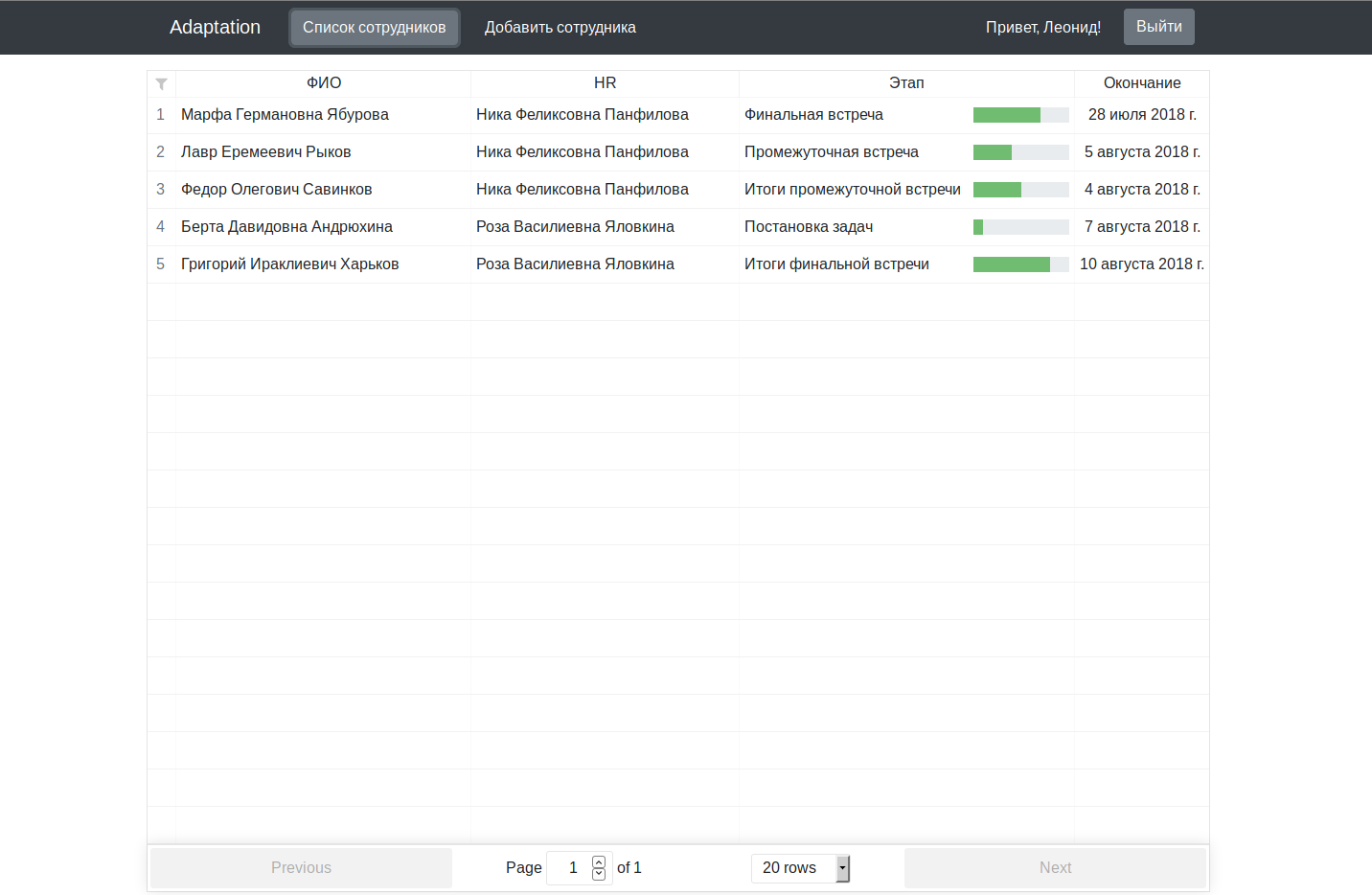
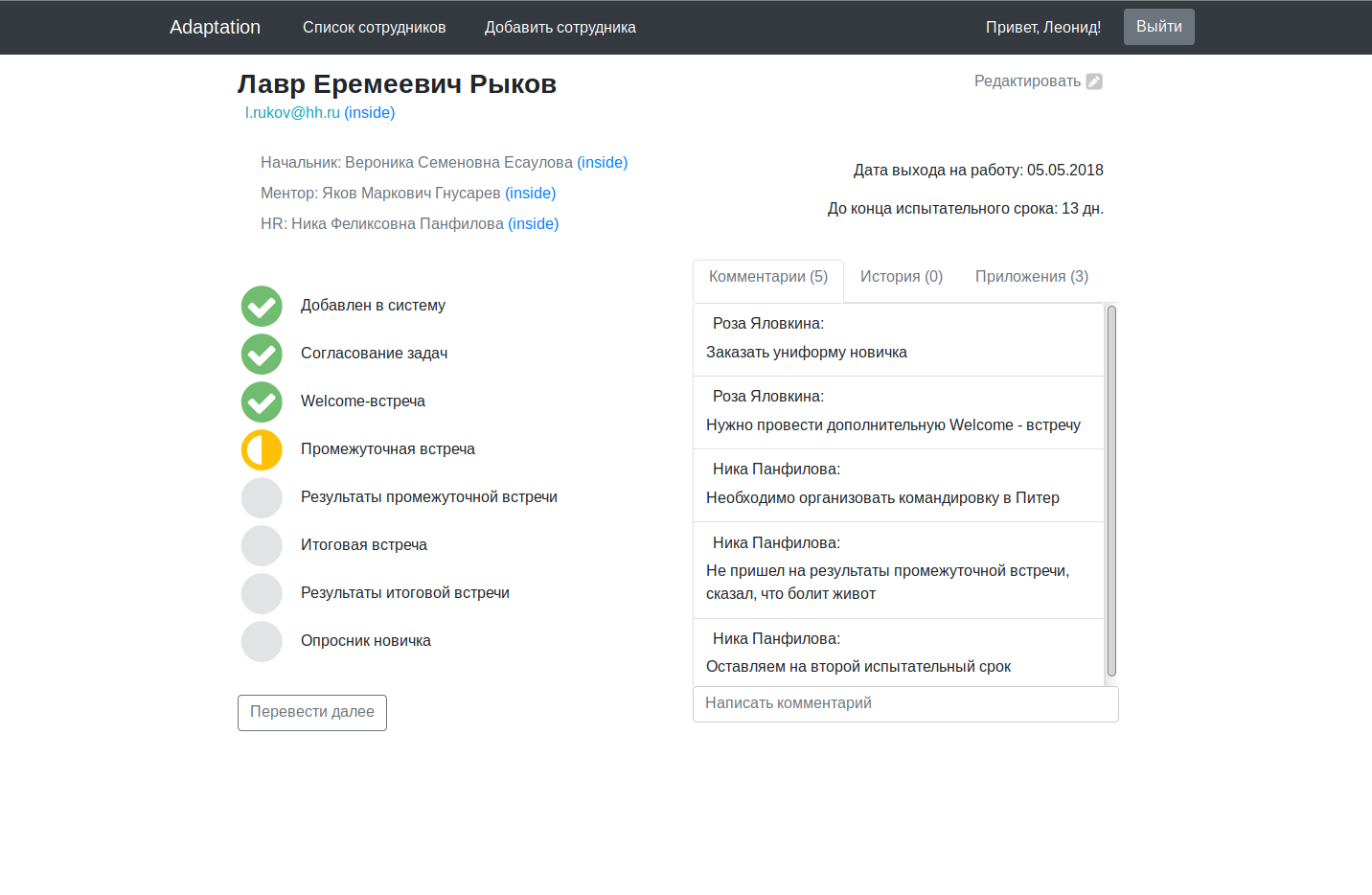
Для многомиллионного проекта выглядит немного сыровато, конечно, но в качестве оправдания напомню, что мы работали над ним в вечернее время, после работы/учебы.
Если количество заинтересовавшихся превысит количество тапков, в будущем могу превратить это в цикл статей, где расскажу про фронт, докеризацию и нюансы, встретившиеся нам при работе с почтой/жирой/док-файлами.
P.S. спустя некоторое время пережив шок от школы, остатки команды собрались и, проведя разбор полетов, решили сделать адаптацию 2.0, учтя все ошибки. Основная цель проекта та же — научиться делать серьезные приложения, строить продуманную архитектуру и быть востребованными специалистами на рынке. Вы можете следить за работой в том же репозитории. Пул-реквесты приветствуются. Спасибо за внимание и пожелайте нам удачи!
плюшки
ссылка на оригинал статьи https://habr.com/post/419599/
Добавить комментарий