
В предыдущей статье на тему государственного риск-менеджмента мы прошлись по основам: зачем государственным органам управлять рисками, где их искать и какие существуют подходы к оценке. Сегодня поговорим о процессе анализа рисков: как выявить причины их возникновения и обнаружить нарушителей.
Оценка рисков
Чтобы оценить риск — хоть в рамках статического, хоть динамического подхода — нужно найти его причины, условия возникновения, и определить основные характеристики: вероятность и потенциальный ущерб от реализации.
Возьмём для примера таможенное оформление: при ввозе любого товара в страну кроме множества различных сведений (стоимость, вес, упаковка, отправитель, получатель и т. д.) в декларации нужно заявить код по специальному классификатору — товарной номенклатуре внешнеэкономической деятельности (ТН ВЭД). По этому коду для товара затем определяется пошлина согласно таможенному тарифу (ТН ВЭД + ставки).
Таможенный тариф — сложный классификатор: некоторые товары, на первый взгляд, можно отнести к разным кодам с разными ставками пошлины. Например, разобраться со сложным горным оборудованием можно, только углубившись в его чертежи. Отсюда возникает соблазн импортёра заявить неправильный (но похожий на правду) код, чтобы заплатить в бюджет меньше денег.
Так мы идентифицировали риск — заявление недостоверного кода товара в декларации с целью занижения таможенных платежей. Причина — наличие в классификаторе “пограничных” позиций с разными ставками пошлины.
Обнаружить условия возникновения такого риска — когда и с какими товарами это происходит на практике — сложнее. Для этого нужно провести анализ риска: изучить историю наблюдений за объектами контроля, узнать, когда и кто заявлял неверный код товара, и выделить какие-то общие характеристики этих случаев. Это позволит сформировать правила для обработки риска в будущем: какие объекты мы будем относить к риску и какой проверке подвергать.
Самый простой способ получить такие правила — довериться экспертным суждениям своих сотрудников.
Экспертные правила
Такие правила для выявления рисков составляют специалисты по предметной области. Они руководствуются своим опытом работы или обобщают мнения коллег, которые каждый день сталкиваются с нарушителями. В результате получаются простые суждения вида “если…то…”.
Вероятность возникновения риска и потенциальный ущерб от угрозы в этом случае определяется “на глазок” либо приблизительными расчётами.
Преимущество экспертных правил заключается в лёгкости их составления и интерпретации человеком. Недостаток — под действие правила одновременно может попадать большое число лиц — и нарушителей, и добропорядочных субъектов экономической деятельности. Поэтому результативность контроля будет невысокой. В то же время, мимо пройдёт часть нарушителей, по которым эксперт не смог обнаружить и учесть закономерности.
Например, экспертное правило для таможенного контроля говорит нам, что все партии яблок со стоимостью ниже определённого порога, относятся к рисковым поставкам:

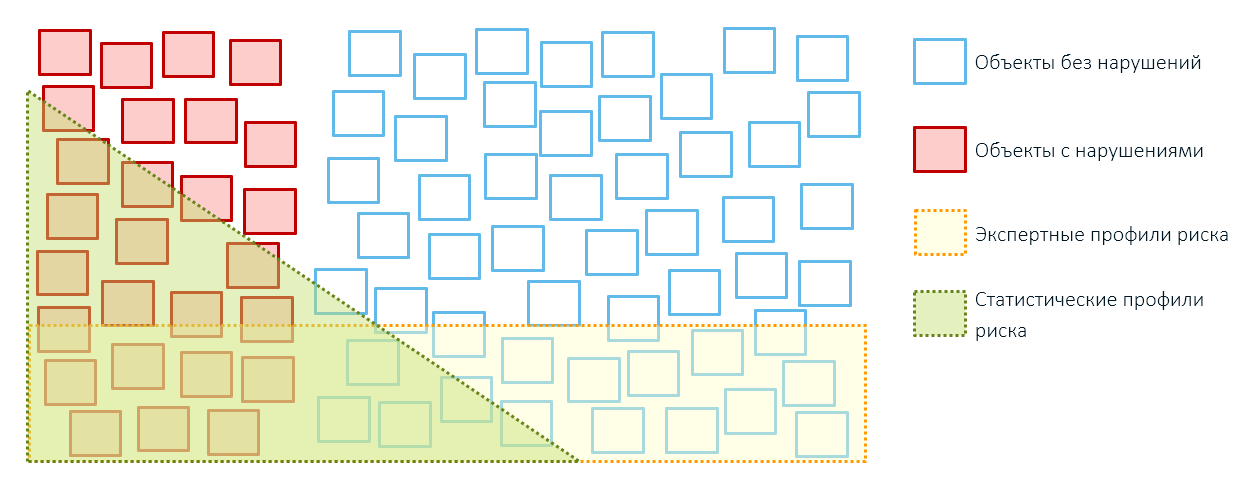
Когда мы проведём контроль, то обнаружим как товары с нарушениями (красные), так и вполне нормальные поставки (зеленые), низкая стоимость которых объясняется индивидуальными скидками, борьбой отправителя с затовариванием или экономической моделью предприятий.
Всё, что выше этого условного стоимостного порога (красная линия), окажется вне контроля (серые кружки). Но если мы их тоже проверим, то обнаружим как действительно законные поставки, так и поставки, реальная стоимость которых ещё выше, чем было заявлено в декларации (серые кружки с красным пунктирным контуром) и по которым таможенные платежи уплачены не в полном объёме.
Поэтому применение экспертных правил обычно приводит к избыточному охвату объектов контроля и небольшой результативности (помните, наши квадратики из первой статьи?):
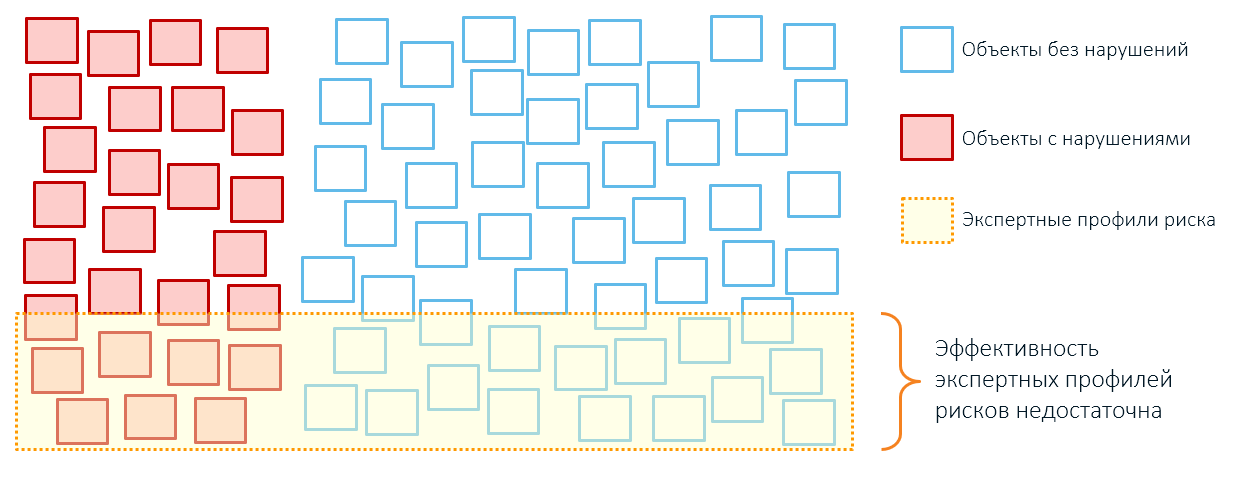
Не стоит винить экспертов: человеческое сознание ограничено в объектах, которыми оно может оперировать (когда-то на Хабре была опубликована любопытная статья, автор которой предположил, что их число ограничено семью). Отсюда и крупные мазки вместо точных деталей: скажем, риск пожара определяют только по году постройки здания, району нахождения и категории жильцов. Все эти характеристики однажды “сыграли”: в старом доме вспыхнул пожар, в неблагополучном районе загорелось помещёние. Поэтому эксперты ожидают в будущем угрозы именно от объектов подобного типа.
Но не все из таких “опасных” зданий в действительности собираются сгореть, даже если попадают под экспертное правило: многие старые и деревянные дома стоят, как ни в чём не бывало. Некоторые неблагополучные дома годами стоят без единого пожара. Просто эксперт не смог учесть какие-то тонкие индивидуальные особенности опасных объектов.
Здесь на сцену вступает машинное обучение, которое помогает создавать статистические профили рисков. Они формируются, когда мы применяем технологии анализа данных к истории нарушений и информации о контролируемых объектах.
Статистические профили рисков
В этом случае мы решаем задачу бинарной классификации: специализированный аналитический алгоритм сам определяет, какие характеристики объектов позволяют отнести их “плохим” или “хорошим”. Если всё сделать правильно, на выходе мы получим довольно точные оценки рисков: детальные условия и автоматически рассчитанные вероятность плюс потенциальный ущерб (которые при экспертном подходе определяются тоже как-то “экспертно”). Эти характеристики определяют “профиль риска” — что, где, когда и насколько страшно.
Статистические профили рисков создаются по-разному. В основе может лежать дерево решений или случайный лес. Можно применить хитрую нейросеть с большим числом скрытых слоёв.
Но мы в SAS считаем, что для целей госконтроля лучше создавать статистические профили рисков на базе интерпретируемых алгоритмов, например, регрессии или дерева решений. Практика показала, что государственному органу трудно ориентироваться пусть даже на точный, но непонятный прогноз машины, если он не объясняет, почему вот этот уважаемый человек отмечен, как негодяй.
Госоргану нужно понимать, какие именно факторы указывают на угрозу и у кого из нарушителей были обнаружены такие же характеристики, поскольку существуют процедуры утверждения управленческих решений (частным случаем которых являются профили рисков). Чиновник должен понимать, что именно он запускает “в бой”, поскольку ему отвечать за результат действия профиля риска.
Любая проверка должна быть обоснована и это обоснование следует выразить словами. Иначе потом придётся краснеть перед прокурором и объяснять, как вышло, что госорган “зажимает” отечественный бизнес на основе таинственных указаний deus ex machina.
Поэтому статистический профиль риска тоже выглядит как правило, которое можно прочитать и понять. Только перечень характеристик, которые описывают возможных нарушителей, больше и сложнее, чем у экспертных профилей:

* значения параметров профиля изменены и не соответствуют реальным
Набор индикаторов риска (условий) может показаться слегка причудливым. Но это не “великое колдунство” — просто с помощью технологий машинного обучения и тех ограниченных сведений, что у нас есть, мы описываем некий скрытый паттерн поведения людей, который приводит к нарушению.
То же в налоговом контроле — нарушителей могут выделять из общей массы налогоплательщиков определённые диапазоны сумм каких-то операций, сроки подачи деклараций, число сотрудников в штате компании, количество счетов и ещё набор из 30 разных параметров, совокупно описывающих недобросовестных предпринимателей, занижающих НДС.
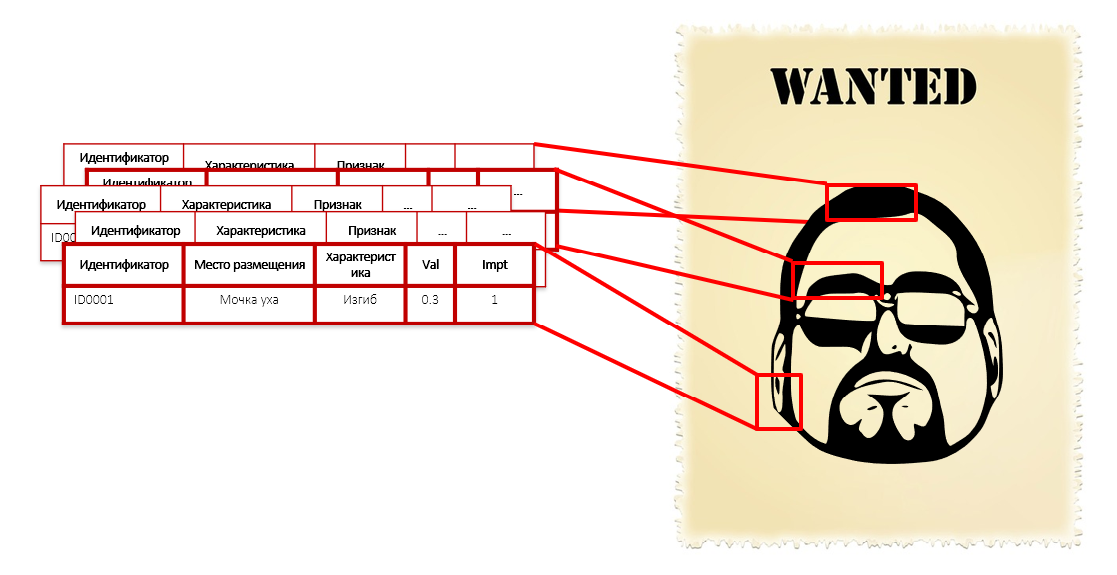
Человек не сможет сопоставить все эти характеристики, он обойдется тремя или пятью, которые проще понять. А программа — сможет. Настолько детально, насколько потребуется. При построении модели алгоритм автоматически перебирает массу данных и находит, что общего у нарушителей — даже если это любовь к красным галстукам в желтую сеточку.
Это похоже на описание преступника по его отдельным чертам: форме носа, ушей, изгибу бровей, цветам рубашек и длине стопы. Мы не знаем его лицо, рост и вес, но у нас есть тысяча его характеристик, включая длину волосков на фаланге левого мизинца. Каждый из таких параметров в отдельности не выдает преступных намерений — не нужно надевать наручники на человека только за радиус закругления его ушных раковин. Но весь набор этих характеристик в совокупности формирует довольно точный портрет нарушителя:
Когда мы переходим от применения экспертных правил к статистическому профилированию на основе анализа скрытых закономерностей, то избавляемся от заведомо нерезультативных проверок. Огромное поле сплошного контроля сужается до точечного воздействия на объекты, которые попадают под выявленный паттерн недобросовестного поведения.
Вспомним яблоки из таможенного примера выше по тексту. Подавая историю проведенных проверок на вход статистической модели, мы получаем профиль риска, который учитывает поведенческие характеристики импортеров-нарушителей вне зависимости от того, по какой цене они декларируют товары:
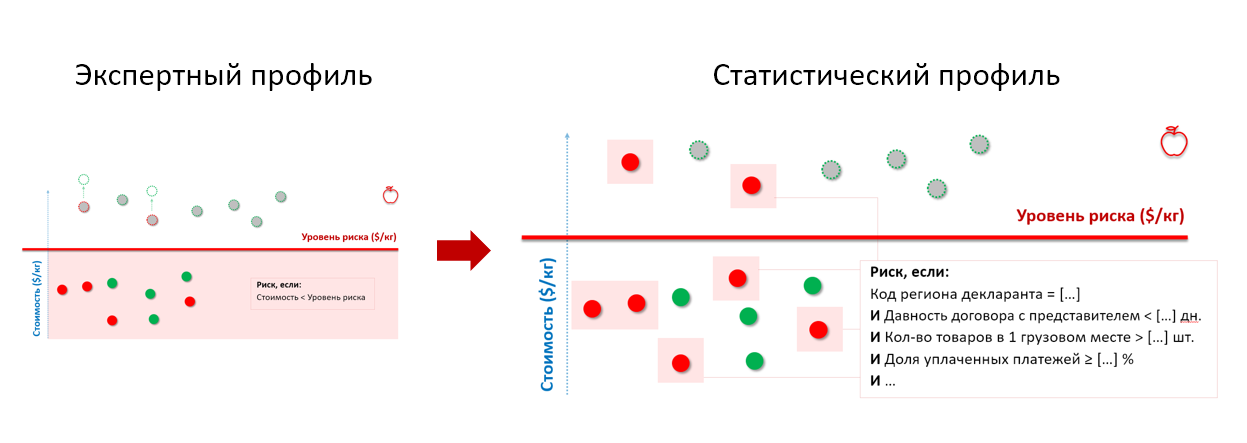
* набор параметров профиля риска изменен и не соответствует реальному
Вот так строится статистический профиль риска с помощью алгоритмов класса “дерево решений” — каждый его уровень все лучше разделяет совокупность проверяемых субъектов на “хороших” и “плохих” и показывает, какая характеристика для разделения оказалась наиболее значимой (на скриншоте SAS Visual Statistics):
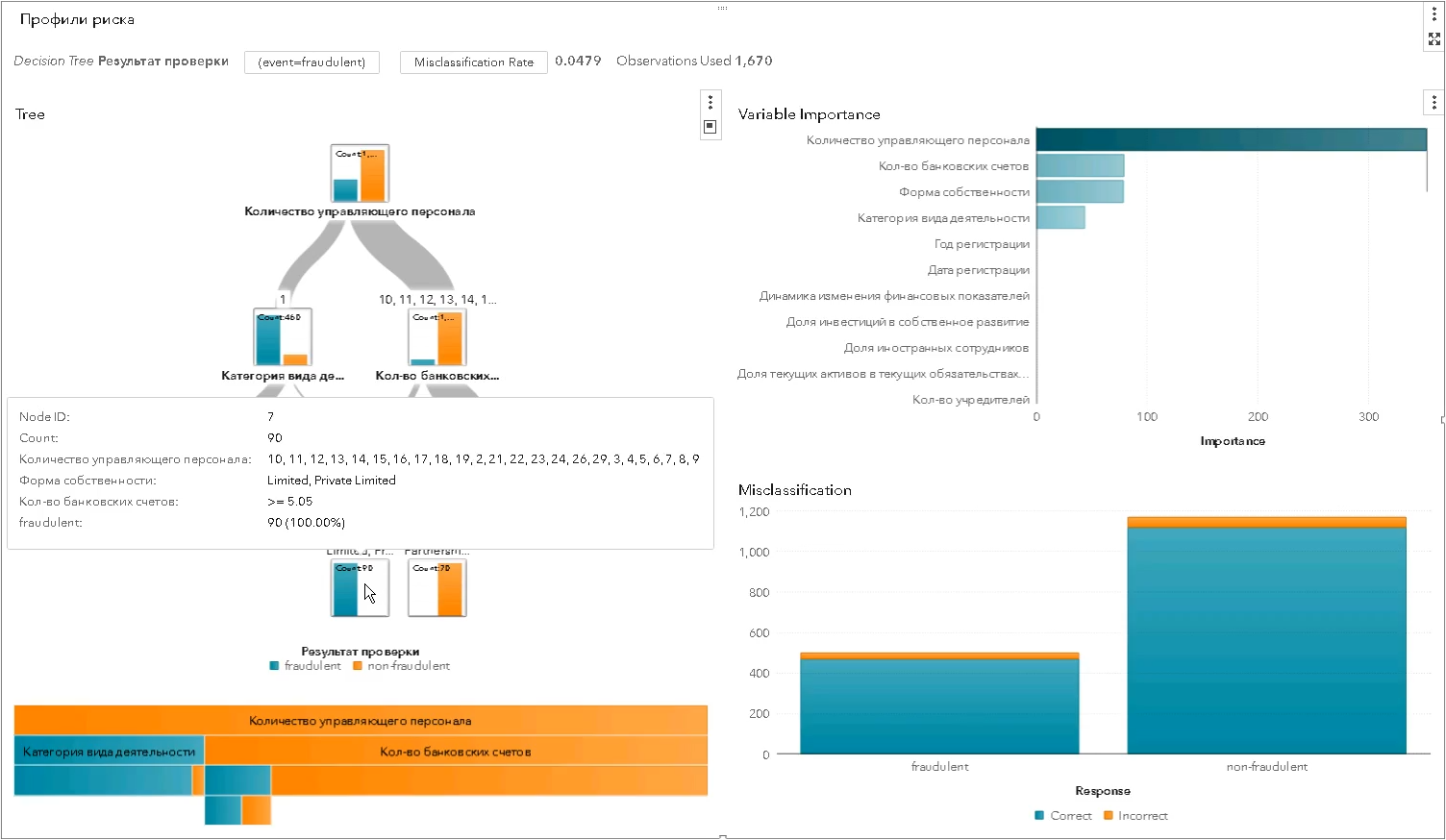
Статистические профили лучше, чем экспертные — точнее, избирательнее, беспристрастнее. Они помогают повысить результативность проверок, снизив число холостых “сработок”:
Недостаток статистических профилей в том, что они ориентируются на прошлый опыт выявления нарушений. На известные схемы.
Если в истории таможенного контроля выявлялись случаи занижения стоимости при ввозе товаров, алгоритм найдет признаки нарушителей и сформирует статистический профиль риска. Если же мы ищем некое новое нарушение, которое ещё не попадалось госоргану на глаза, и мы не знаем его характеристик, то приходится действовать “на ощупь” — методом проб и ошибок.
Поиск неизвестного
Пощупать неизвестность можно несколькими способами.
Первый — случайная выборка. Берём произвольный объект (в пределах своих полномочий) — товар, предприятие, здание или гражданина — и внимательно его рассматриваем. Подход достаточно беспристрастный, но не слишком эффективный — под “разбор полетов” может с равным успехом попасть и добропорядочный субъект. Силы госоргана и бюджетные деньги будут потрачены зря.
Второй — выявление аномалий. В это случае для проверки берут объект, параметры которого выделяются на фоне остальных. Когда мы анализируем аномальные события, а не просто наугад “тыкаем” в кучу объектов, вероятность найти нарушение выше.
Например, при проведении экологического надзора выясняется, что завод потребляет неожиданно много электроэнергии:
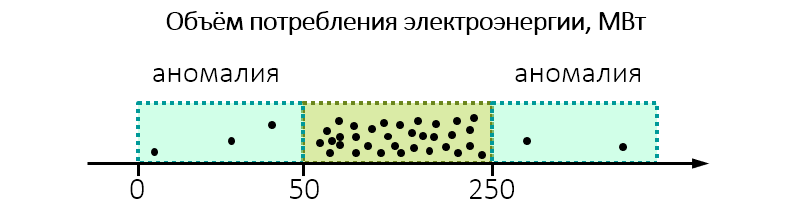
Пожалуй, стоит присмотреться к нему и проверить, не сбрасывает ли завод в воду или воздух больше допустимого.
Или товар на таможне имеет необычное соотношение веса товара и упаковки:
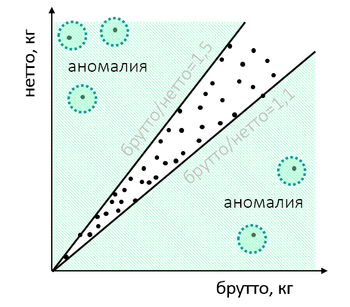
После проверки может оказаться, что импортёр “поиграл” весом, чтобы прикрыть какие-то нарушения: занизил стоимость и таким образом хотел подтянуть одну из проверочных величин или выдаёт одни товары под видом других. “Естественные” весовые характеристики, если хорошо копнуть, отличаются от выдуманных.
Впрочем, это самые простые примеры, которые в состоянии увидеть и человек. В реальности поиск аномалий происходит в многомерном пространстве атрибутов — их могут быть сотни. Алгоритм делает то, что не под силу человеку — находит объекты, которые значительно отличаются от остальных таких же одновременно по большому числу признаков, и определяет так называемые многомерные выбросы (на скриншоте SAS Visual Statistics):
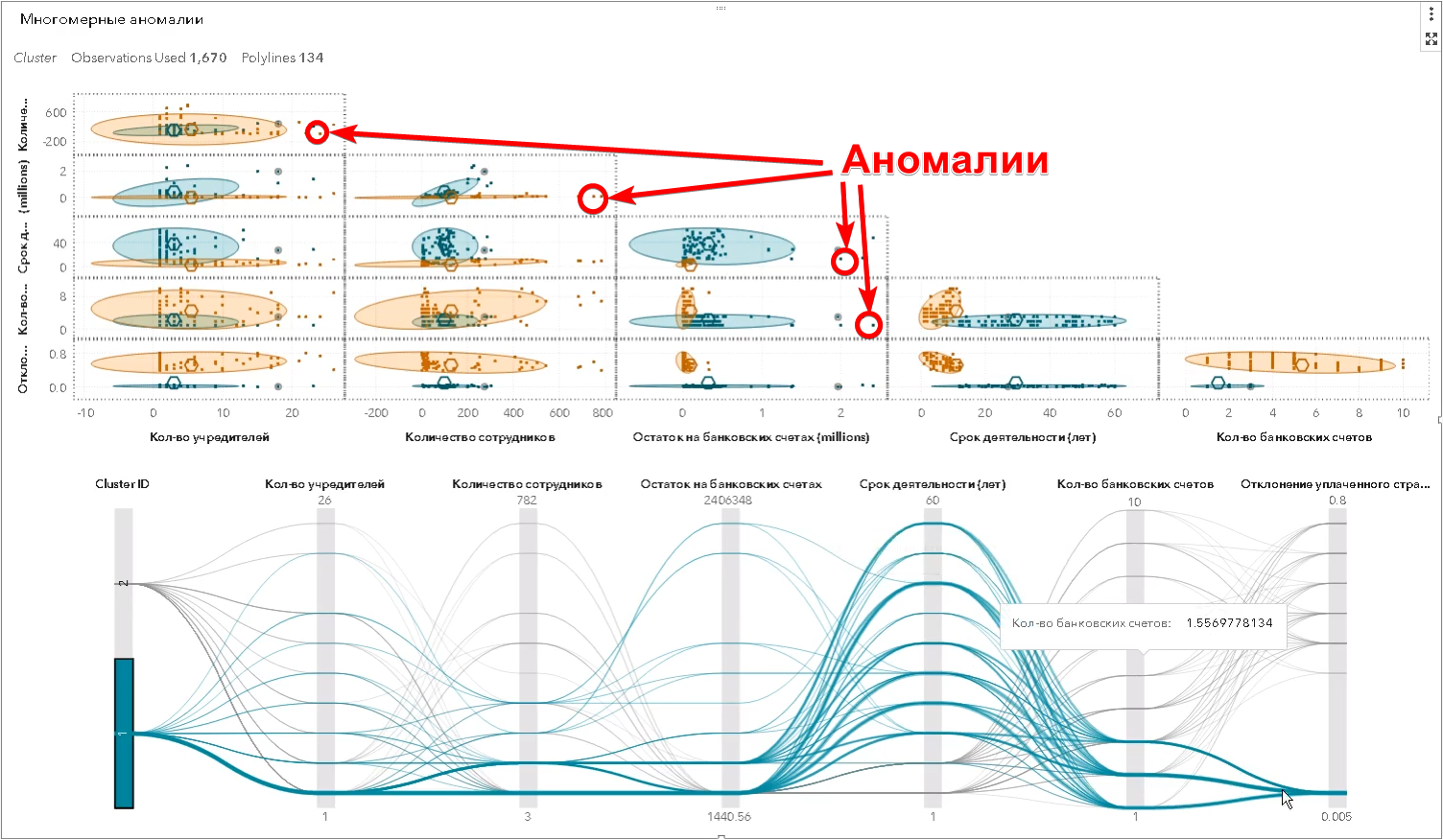
Также за пределами человеческого восприятия находится многообразие правоотношений между различными компаниями, которые визуализируются с помощью графа (на скриншоте SAS Social Network Analysis):
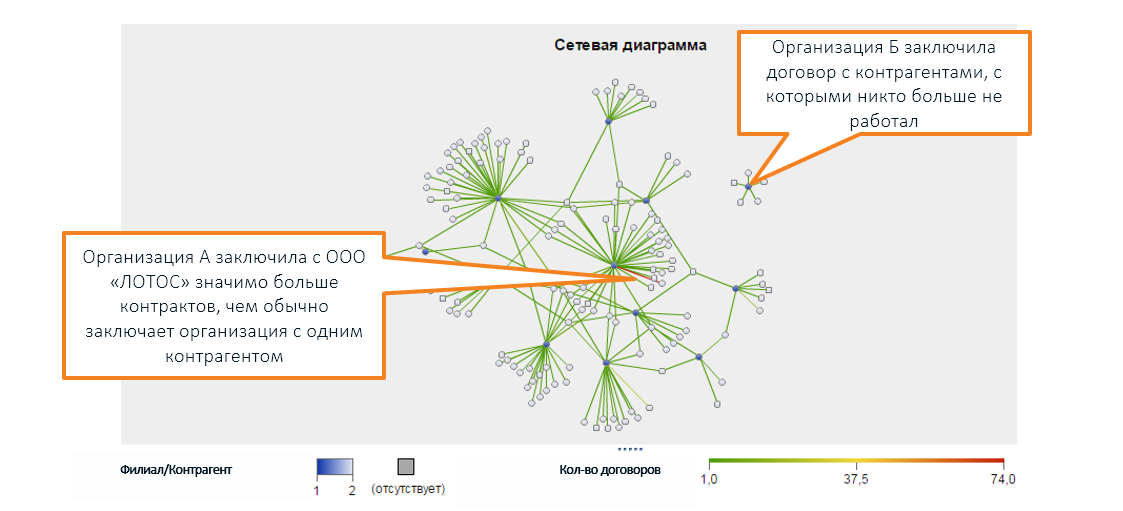
* названия организаций выдуманы, совпадения с реальными компаниями случайны
Необычные характеристики необязательно говорят о проблеме. Проверка может ничего не показать: да, показатели странные, но нарушения нет.
Аномалия — это не риск, это просто “что-то необычное”. Профили аномалий нужны, чтобы давать новое “сырьё” для построения экспертных или статистических профилей, так как результат проверки аномалии включается в историю наблюдений за объектами контроля.
Гибридный подход
Лучших результатов в контрольно-надзорной деятельности государственных органов (и не только в ней) можно добиться, объединив все три способа выявления рисков: экспертные правила, статистические профили рисков на базе технологий машинного обучения и профили аномалий. При этом охват объектов экспертными правилами лучше сократить, оставив их только для точечных административных воздействий (например, ввели санкции — блокируем товары из этих стран):
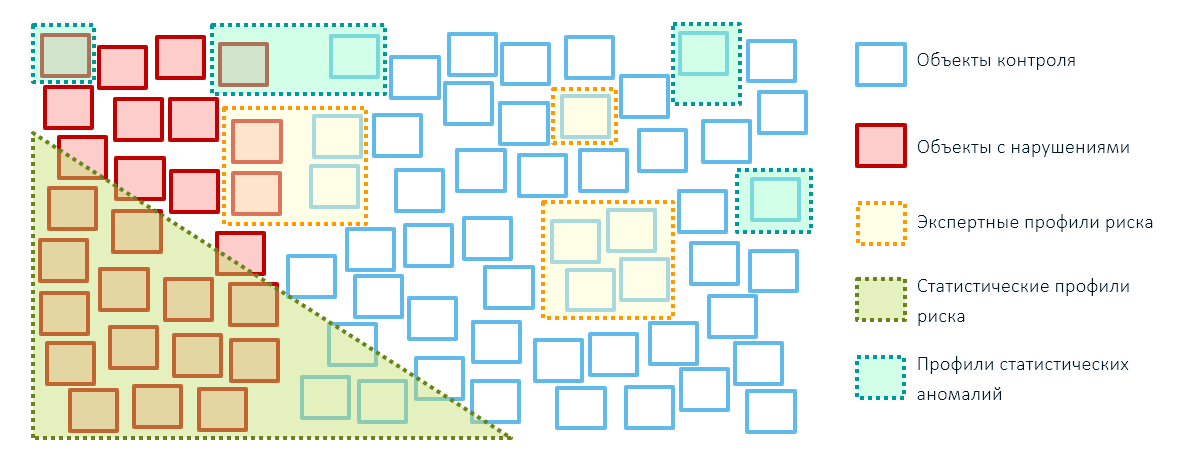
Без экспертных правил не обойтись на начальном этапе построения системы управления рисками, так как для создания аналитических моделей нужна база прецедентов. Чтобы её создать, потребуется провести проверки на основе экспертных профилей рисков и уже потом переходить к математическим моделям.
Мы в SAS считаем, что будущее контрольно-надзорной деятельности государства за гибридным подходом, который объединит опыт госорганов и экспертные знания его сотрудников с современными технологиями машинного обучения. В этом случае мы сводим в одну интегральную оценку риска результаты работы всех трёх модулей:
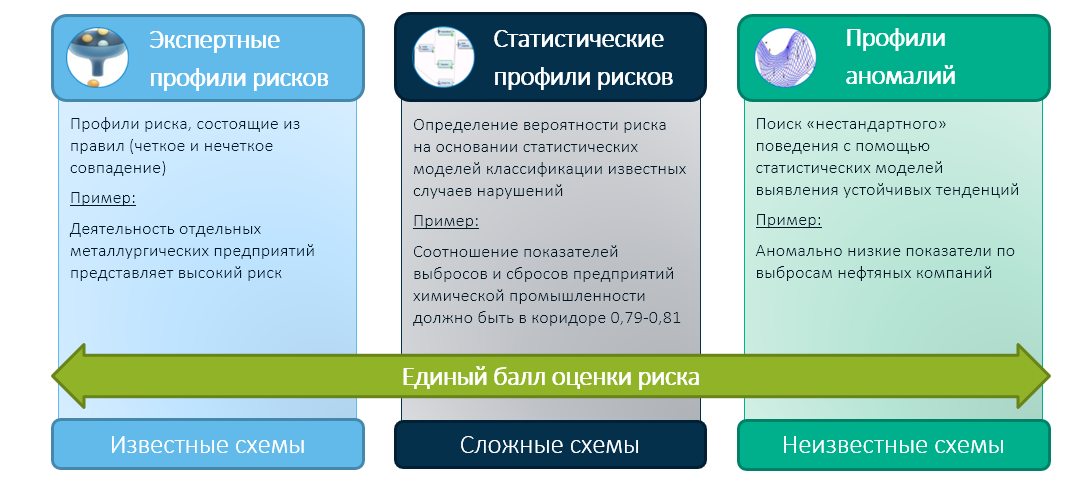
И уже интегральная оценка (например, на основе экспертной матрицы решений) определяет выбор контрольного органа — кого проверять, а кому доверять.
В следующей статье мы разберём методы минимизации выявленных угроз и подумаем над тем, почему так важна обратная связь и динамическая переоценка рисков.
ссылка на оригинал статьи https://habr.com/post/421677/
Добавить комментарий