 В наш век облачных сервисов, AWS Lambda и прочих
В наш век облачных сервисов, AWS Lambda и прочих TL;DR> объединение, балансировка, rr limit, вот это вот всё.
Собственно, текст далее не про то, что это вообще возможно или ноу-хау какое-то. Интернет полон статьями для чайников (вот здесь ставим галочки, затем Next, Next, Done) о том, как подать дисковую ёмкость по iSCSI. Пишу как раз для того, чтобы исключить «ошибки выживших» и поделиться моментами, когда «всё пойдёт не так» (а оно пойдёт, Мерфи был прав), и при попытке нагрузить решение оно просто падает.
Итак, мы попробуем раздушить наш «бытовой гипервизор» внешним дисковым массивом, подключенным по сети. Поскольку у нас всё крутится вокруг «недорого», пусть это будет FreeNAS и 4 SATA-диска, которые обслуживает средненький 3 ГГц 45-нм проц. Смотрим на Ebay, и за сравнимые с б/у RAID-контроллером деньги тащим оттуда пару сетевых карточек i350-T4. Это четырёхпортовые гигабитные адаптеры от Intel. По ним и будем связывать хранилку с гипервизором.
Немножко посчитаем. Средняя скорость передачи данных среднего SATA диска — 160-180 МБ/сек при ширине интерфейса в 6 Гбит/с. Фактически, реальная скорость передачи данных с HDD не превышает 2 Гбит/с. Не такая уж большая цифра, учитывая, что связь мы планируем по 4м гигабитным портам (как именно превратить 4×1Гбит в 4 Гбит — обсудим далее). Намного хуже все со скоростями произвольного доступа — здесь всё падает чуть ли не до уровня дискет.
Учитывая, что профиль дисковой нагрузки от множества гостевых ОС — далёк от линейного, хотелось бы видеть более веселые цифры. Для исправления ситуации в файловой системе гипервизора ( VMFS v6) размер блока составляет 1 МБ, что способствует уплотнению множества случайных операций и ускоряет доступ к данным на виртуальных дисках. Но даже с этим одного физического диска будет недостаточно для обработки операций ввода-вывода от всех «гостей».
Сразу оговорюсь — всё дальнейшее имеет смысл, если у вас адаптеров для «сети хранения» больше двух. ESXi с бесплатной однопроцессорной лицензией умеет подключаться, кроме локальных дисков, к хранилищам двух типов — NFS и iSCSI. NFS предполагает доступ файлового уровня и тоже по-своему хорош. На нем можно развернуть гостей, нетребовательных к дисковой производительности. Бэкапить их — одно удовольствие, т.к. можно открыть эту же NFS шару ещё куда-либо и копировать снапшоты вм. В общем, с одним сетевым интерфейсом (если это не 10GE, конечно) — NFS ваш выбор.
У iSCSI есть ряд преимуществ перед NFS. Для того, чтобы реализовать их в полной мере, мы уже подготовились — заложив для сети хранения аж 4 гигабитных порта. Как обычно происходит расширение пропускной способности сети при известной скорости интерфейсов? Правильно, агрегацией. Но для полной утилизации агрегированного канала нужен целый ряд условий, и это подходит больше для связи коммутаторов между собой либо для сетевого аплинка гипервизора. Реализация протокола iSCSI предусматривает такую функцию, как multipathing (дословно, много путей) — возможность подключения одного и того же тома через разные сетевые интерфейсы. Само собой, про возможность балансировки нагрузки там тоже есть, хотя основное назначение — отказоустойчивость сети хранения. (Справедливости ради, NFSv4.1 поддерживает session trunking на базе совершеннейшей магии типа RDMA и MPTCP, но это попытка переложить проблемы файлового доступа с больной головы на здоровую на нижние уровни.)
Итак, для начала опубликуем наш таргет. Считаем, что FreeNAS установлен, IP-адрес управления исправно отгружает нам web-интерфейс, массив и zvol на нём мы нарезали в полном соответствии с нашими внутренними убеждениями. В нашем случае это 4 х 500ГБ диска, объединённых в raidz1 (что даёт всего 1,3 ТиБ эффективной ёмкости), и zvol размером в 1 ТБ ровно. Настроим сетевые интерфейсы i350, для простоты принимаем, что все будут принадлежать разным подсетям.

Затем настраиваем iSCSI-шару методом «Next, Next, Done». При настройке портала не забываем добавить туда все сетевые интерфейсы, выделенные для iSCSI. Выглядеть должно примерно так, как на картинках.


Чуть больше внимания потребуется уделить настройке extent — при презентации тома необходимо форсировать размер блока 512 байт. Без этого инициатор ESXi вообще отказывался опознавать презентованные тома. Для верности лучше отключить проброс размеров физ блока (которого на zvol нет и быть не может) и включить режим поддержки Xen.
С FreeNAS пока всё.
На стороне ESXi немного сложнее с настройкой сети. Опять же, считаем, что сам гипервизор установлен и также управляется по отдельному порту. Потребуется выделить 4 интерфейса VM Kernel, принадлежащих 4м разным порт-группам в 4х разных виртуальных коммутаторах. Каждому из этих коммутаторов выделяем свой физический порт аплинка. Адреса vmk# берём, разумеется, в соответствующих подсетях, аналогично настройке портов хранилища. Порядок настройки адресов, в общем случае, важен — либо мы соединяем карточки «порт-в-порт» без коммутатора, либо отдаём разные линки в разные сети (ну, это если по-взрослому), поэтому физическое соответствие портов имеет значение.
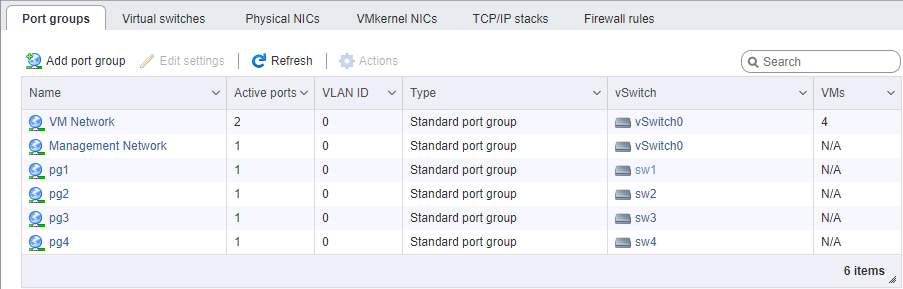
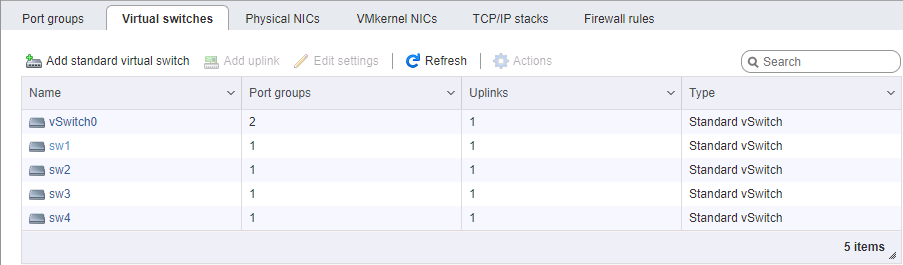
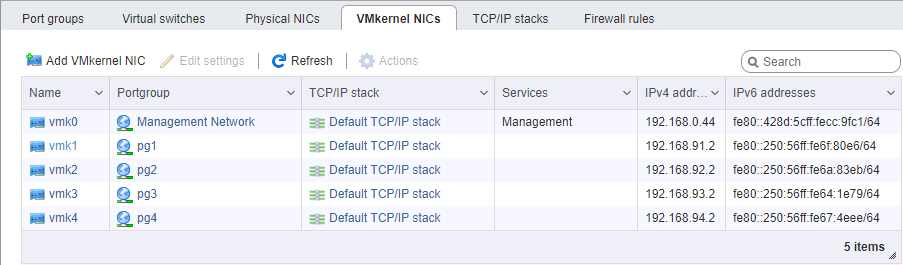
Особое внимание при настройке сети под iSCSI уделяем параметру MTU. Это как раз тот случай, когда «размер имеет значение» — берём максимум, который позволяют установить все компоненты сети. Если карточки соединены напрямую, можно указать mtu 9000 на обоих сторонах, на ESXi и FreeNAS. Впрочем, нормальные коммутаторы это значение поддержат. Пингуем, видим, что сеть у нас в норме, и пакеты требуемого размера проходят. Отлично. Поджигаем инициатор.
Включаем iSCSI, добавляем IP-адреса в динамическую секцию настройки (Storage -> Adapters -> Configure iSCSI -> Dynamic targets). После сохранения будет выполнен опрос iSCSI порталов по этим адресам, инициатор определит, что за каждым из них стоит один и тот же том, и подключится к нему по всем доступным адресам (тот самый multipath). Дальше нам потребуется создать datastore на появившемся устройстве.
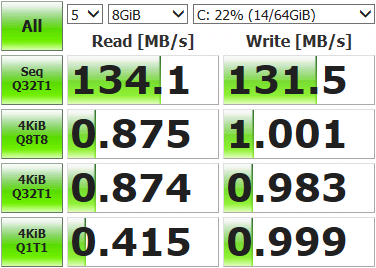
После этого можно раскатать виртуальную машинку и замерить, что у нас получилось.

Не такие уж впечатляющие результаты. Открываем консоль хранилища, выводим текущее состояние сети и запускаем тесты.
root@freenas:~ # systat -ifstat
/0 /1 /2 /3 /4 /5 /6 /7 /8 /9 /10 Load Average Interface Traffic Peak Total lo0 in 0.319 KB/s 0.893 KB/s 3.041 MB out 0.319 KB/s 0.893 KB/s 3.041 MB alc0 in 0.478 KB/s 1.233 KB/s 3.934 MB out 0.412 KB/s 1.083 KB/s 2.207 MB igb3 in 0.046 KB/s 0.105 KB/s 181.434 KB out 0.073 KB/s 0.196 KB/s 578.396 KB igb2 in 0.046 KB/s 0.105 KB/s 120.963 KB out 0.096 KB/s 0.174 KB/s 517.221 KB igb1 in 4.964 MB/s 121.255 MB/s 10.837 GB out 6.426 MB/s 120.881 MB/s 3.003 GB igb0 in 0.046 KB/s 0.105 KB/s 139.123 KB out 0.073 KB/s 0.210 KB/s 869.938 KB
Утилизирован лишь один сетевой порт из четырёх (igb1). Происходит это потому, что механизм балансировки, предусмотренный по умолчанию для multipath, с каждым пакетом данных выбирает один и тот же адаптер. Нам же надо задействовать из все.
Подключаемся к гипервизору по SSH и командуем.
Для начала глянем, какой ID у луна с multipath, и как он работает:
[root@localhost:~] esxcfg-mpath -b
naa.6589cfc000000b478db42ca922bb9308 : FreeNAS iSCSI Disk (naa.6589cfc000000b478db42ca922bb9308)
[root@localhost:~] esxcli storage nmp device list -d naa.6589cfc000000b478db42ca922bb9308 | grep PSP
Path Selection Policy: VMW_PSP_MRU
Политика выбора путей — MRU, то бишь most recently used. Все данные идут в один и тот же порт, перевыбор пути происходит только при недоступности сетевого соединения. Меняем на round-robin, при которой все интерфейсы меняются по очереди после какого-то числа операций:
[root@localhost:~] esxcli storage nmp device set -d naa.6589cfc000000b478db42ca922bb9308 -P VMW_PSP_RR
Перезагружаем ESXi, открываем мониторинг, запускаем тесты. Видим, что нагрузка распределяется по сетевым адаптерам равномерно (как минимум, пиковые значения, лишнее поскипано), результаты теста тоже повеселее.
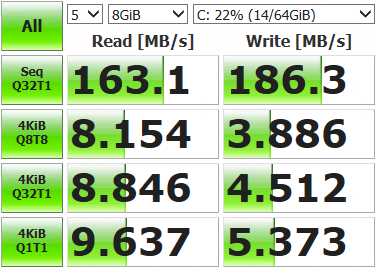
Interface Peak igb3 in 43.233 MB/s out 46.170 MB/s igb2 in 42.806 MB/s out 45.773 MB/s igb1 in 43.495 MB/s out 45.489 MB/s igb0 in 43.208 MB/s out 46.079 MB/sЕсть некоторые отклонения по портам, это возникает из-за лимитов Path Selection Policy — числа операций либо байт, после которого происходит переключение на другой порт. По умолчанию 1000 IOPS, то есть если обмен данными уложился в 999 операций — он пройдет через один сетевой порт. Можно менять, сравнивать и подбирать подходящее значение. Можно не менять, дефолта достаточно для большинства задач.
Делаем замеры, тестируем, работаем. Полученные результаты ощутимо превосходят возможности одиночного диска, так что теперь наши виртуальные машинки могут не толкаться локтями на операциях ввода-вывода. Итоговые значения скоростей и отказоустойчивость массива будут зависеть от железа и того, как выполнена конфигурация тома.
ссылка на оригинал статьи https://habr.com/post/423513/
Добавить комментарий