Автор материала, перевод которого мы сегодня публикуем, говорит, что хочет рассказать здесь обо всём, что нужно знать для грамотной подготовки материалов веб-проектов к работе. Во-первых, речь пойдёт о том, как подобрать такую стратегию разделения файлов сайта, которая наилучшим образом подойдёт для конкретного проекта и для его пользователей. Во-вторых — будут рассмотрены средства реализации выбранной стратегии.

Общие сведения
В соответствии с глоссарием Webpack, существуют две стратегии разделения файлов. Это — разделение бандла (bundle splitting) и разделение кода (code splitting). Эти термины могут показаться взаимозаменяемыми, но таковыми они не являются.
- Разделение бандла — это методика разбиения больших бандлов на несколько частей, представляющих собой файлы меньшего размера. Такие файлы, в любом случае, как и при работе с единственным бандлом, будут загружаться всеми пользователями сайта. Сильная сторона этой методики заключается в улучшении использования браузерных механизмов кэширования.
- Разделение кода — это подход, который подразумевает динамическую загрузку кода по мере возникновения необходимости в нём. Это приводит к тому, что пользователь загружает только тот код, который необходим ему для работы с некоей частью сайта в определённый момент времени.
Разделение кода, как кажется, выглядит гораздо интереснее, чем разделение бандла. И, на самом деле, возникает такое ощущение, что во многих статьях по нашей теме основное внимание уделяется именно разделению кода, эта методика рассматривается как единственный стоящий способ оптимизации материалов сайтов.
Однако мне хотелось бы сказать, что для многих сайтов гораздо более ценным оказывается именно первая стратегия — разделение бандлов. И, пожалуй, от её внедрения способны выиграть буквально все веб-проекты.
Поговорим об этом подробнее.
Разделение бандлов
В основе методики разделения бандлов лежит весьма простая идея. Если у вас имеется один огромный файл и вы меняете в нём одну единственную строчку кода, постоянному пользователю придётся, при очередном посещении сайта, загрузить весь этот файл. Однако если разделить этот файл на два файла, тогда такому же пользователю нужно будет загрузить лишь тот из них, в который внесены изменения, а второй файл будет взят из браузерного кэша.
Стоит отметить, что так как оптимизация материалов сайта путём разделения бандлов завязана на кэшировании, пользователям, посещающим сайт впервые, в любом случае, придётся загружать все материалы, поэтому для них нет разницы — будут ли эти материалы представлены в виде одного файла или в виде нескольких.
Мне кажется, что слишком много разговоров о производительности веб-проектов посвящено пользователям, которые посещают сайт впервые. Возможно, это так, отчасти, из-за важности первого впечатления, которое проект произведёт на пользователя, а также от того, что объёмы данных, передаваемые пользователям при первом посещении сайта, просто и удобно измерять.
Когда же дело доходит до регулярных посетителей, может оказаться сложным измерить воздействие на них применяемых техник оптимизации материалов. Но мы просто обязаны знать о том, к каким последствиям приводят подобные оптимизации.
Для анализа таких вещей потребуется нечто вроде электронной таблицы. Также нужно будет сформировать строгий перечень условий, в которых мы можем протестировать каждую из исследуемых стратегий кэширования.
Вот сценарий, подходящий под общее описание, данное в предыдущем абзаце:
- Алиса посещает наш сайт раз в неделю в течение 10 недель.
- Мы обновляем сайт один раз в неделю.
- Мы, каждую неделю, обновляем страницу со списком товаров (product list).
- Кроме того, у нас есть страница с подробными сведениями о товаре (product details), но мы пока над ней не работаем.
- На пятой неделе мы добавляем в материалы проекта новый npm-пакет.
- На восьмой неделе мы обновляем один из уже используемых в проекте npm-пакетов.
Есть такие люди (вроде меня), которые попытаются сделать подобный сценарий настолько реалистичным, насколько это возможно. Но делать так не нужно. Реальный сценарий тут особого значения не имеет. Почему это так — мы скоро выясним.
▍Исходные условия
Предположим, общий размер нашего JavaScript-пакета составляет немалых 400 Кб и мы, в текущих условиях, передаём всё это пользователю в виде одного файла main.js. У нас имеется конфигурация Webpack, которая, в общих чертах, подобна нижеприведённой (то, что к нашему разговору не относится, я оттуда убрал):
const path = require('path'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, }; Webpack называет результирующий файл main.js в том случае, когда в конфигурации имеется единственная запись entry.
Если вы не очень хорошо себе представляете работу с кэшем, учитывайте, что каждый раз, когда я пишу тут main.js, я на самом деле имею в виду нечто вроде main.xMePWxHo.js. Безумная последовательность символов — это хэш содержимого файла, то, что в конфигурации называется contenthash. Использование такого подхода приводит к тому, что, при изменении кода, меняются и имена файлов, что принуждает браузер к загрузке новых файлов.
В соответствии с вышеописанным сценарием, когда мы, каждую неделю, вносим в код сайта какие-то изменения, строка contenthash пакета меняется. В результате, посещая еженедельно наш сайт, Алиса вынуждена загружать новый файл размером 400 Кб.
Если сделать симпатичную табличку (с бесполезной пока строкой итогов), содержащую данные о еженедельном объёме загрузки данных, приходящихся на этот файл, то у нас получится следующее.

Объём данных, загруженных пользователем
В результате оказывается, что пользователь, за 10 недель, загрузил 4.12 Мб кода. Этот показатель можно улучшить.
▍Отделение пакетов сторонних разработчиков от основного кода
Разделим большой пакет на две части. Наш собственный код будет в файле main.js, а код сторонних разработчиков в файле vendor.js. Сделать это несложно, в этом нам поможет следующая конфигурация Webpack:
const path = require('path'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, optimization: { splitChunks: { chunks: 'all', }, }, };Webpack 4 старается максимально облегчить жизнь разработчику, поэтому он делает всё, что может, и при этом не требует, чтобы ему сообщали о том, как именно нужно разбивать бандлы на части.
Такое вот автоматическое поведение программы приводит к немногочисленным восторгам, вроде: «Ну что за прелесть этот Webpack», и к множеству вопросов в духе: «А что это тут делается с моими бандлами?».
В любом случае, добавление в конфигурацию конструкции optimization.splitChunks.chunks = 'all' сообщает Webpack о том, что нам надо, чтобы он взял всё из node_modules и поместил бы это в файл vendors~main.js.
После того, как мы провели такое вот базовое разделение бандла, Алиса, регулярно посещающая наш сайт еженедельно, будет загружать при каждом визите файл main.js размером 200 Кб. А вот файл vendor.js она загрузит лишь три раза. Произойдёт это во время визитов в первую, пятую и восьмую недели. Вот соответствующая таблица, в которой, волею судьбы, размеры файлов main.js и vendor.js в первые четыре недели совпадают и равняются 200 Кб.

Объём данных, загруженных пользователем
В результате получается, что объём загруженных пользователем за 10 недель данных составил 2.64 Мб. То есть, в сравнении с тем, что было до разделения бандла, объём уменьшился на 36%. Не такой уж и плохой результат, достигнутый добавлением нескольких строк в конфигурационный файл. Кстати, прежде чем читать дальше — сделайте то же самое в своём проекте. А если вам надо обновиться с Webpack 3 на 4 — делайте это и не беспокойтесь, так как процесс это довольно простой и всё ещё бесплатный.
Мне кажется, что рассматриваемое тут улучшение выглядит несколько абстрактно, так как оно растянуто на 10 недель. Однако если считать объём данных, отправленных лояльному пользователю, то это честное сокращение этого объёма на 36%. Это очень хороший результат, но его можно улучшить.
▍Выделение пакетов в отдельные файлы
Файл vendor.js страдает от той же проблемы, что и исходный main.js. Заключается она в том, что изменение любого пакета, входящего в этот файл, приводит к необходимости повторной загрузки постоянным пользователем всего этого файла.
Почему бы нам не сформировать самостоятельные файлы для каждого npm-пакета? Сделать это совсем несложно, поэтому давайте разложим наши react, lodash, redux, moment, и прочее подобное, по отдельным файлам. В этом нам поможет следующая конфигурация Webpack:
const path = require('path'); const webpack = require('webpack'); module.exports = { entry: path.resolve(__dirname, 'src/index.js'), plugins: [ new webpack.HashedModuleIdsPlugin(), // в результате хэши не будут неожиданно меняться ], output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash].js', }, optimization: { runtimeChunk: 'single', splitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 0, cacheGroups: { vendor: { test: /[\\/]node_modules[\\/]/, name(module) { // получает имя, то есть node_modules/packageName/not/this/part.js // или node_modules/packageName const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]; // имена npm-пакетов можно, не опасаясь проблем, использовать // в URL, но некоторые серверы не любят символы наподобие @ return `npm.${packageName.replace('@', '')}`; }, }, }, }, }, };В документации можно найти отличное разъяснение использованных здесь конструкций, но я, всё же, посвящу немного времени рассказу о некоторых вещах, так как для того, чтобы правильно ими воспользоваться, у меня ушло немало времени.
- В Webpack есть вполне разумные стандартные установки, которые, на деле, оказываются не такими уж и разумными. Например, максимальное количество выходных файлов установлено в значение 3, минимальный размер файла — в 30 Кб (то есть, файлы меньшего размера будут объединяться). Я это переопределил.
cacheGroups— это место, где мы задаём правила того, как Webpack должен сгруппировать данные в выходных файлах. У меня тут есть одна группа,vendor, которая будет использоваться для любого модуля, загруженного изnode_modules. Обычно имя (name) для выходного файла задают в виде строки. Но я задалnameв виде функции, которая будет вызываться для каждого обработанного файла. Затем я беру имя пакета из пути к модулю. В результате у нас получается один файл для каждого пакета. Например,npm.react-dom.899sadfhj4.js.- Имена пакетов, для того, чтобы их можно было опубликовать в npm, должны подходить для использования их в URL, поэтому нам не нужно выполнять операцию
encodeURIдля имёнpackageName. Однако я столкнулся с проблемой, которая заключается в том, что .NET-сервер отказывается работать с файлами, в именах которых есть символ@(такие имена используются для пакетов с заданной областью действия имени, так называемых scoped packages), поэтому я, в соответствующем фрагменте кода, от подобных символов избавляюсь.
Вышеприведённая конфигурация Webpack хороша тем, что её можно один раз настроить, а потом о ней забыть. Она не требует обращения к конкретным пакетам по именам, поэтому, после её создания, она, даже при изменении состава пакетов, остаётся актуальной.
Алиса, наш постоянный посетитель, всё ещё каждую неделю заново загружает 200-килобайтный main.js, а при первом посещении сайта вынуждена загружать 200 Кб npm-пакетов, однако ей не придётся дважды загружать одни и те же пакеты.
Ниже показана новая версия таблицы со сведениями об объёмах еженедельных загрузок данных. По странному стечению обстоятельств размер каждого файла с npm-пакетами составляет 20 Кб.
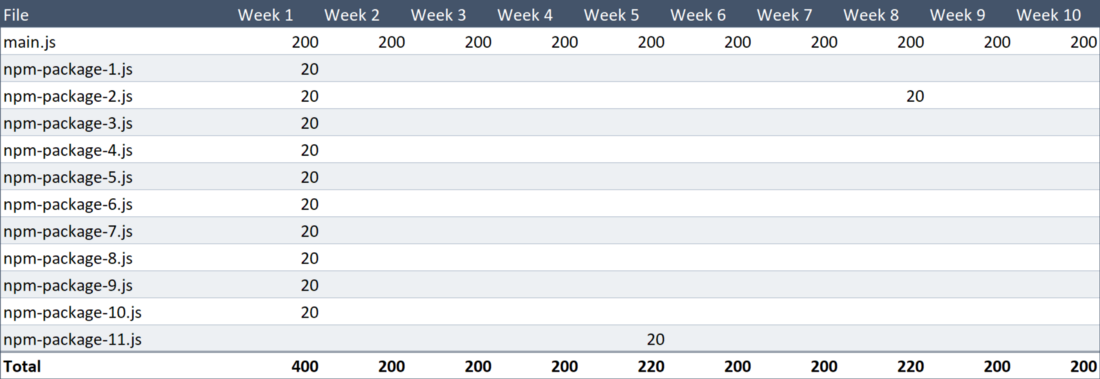
Объём данных, загруженных пользователем
Теперь объём загруженных за 10 недель данных составляет 2.24 Мб. Это значит, что мы улучшили базовый показатель на 44%. Результат это уже весьма приличный, но тут возникает вопрос о том, можно ли сделать так, чтобы добиться результата, превышающего 50%. Если подобное получится — это будет просто здорово.
▍Разбиение кода приложения на фрагменты
Вернёмся к файлу main.js, который несчастной Алисе приходится загружать постоянно.
Выше я говорил о том, что на нашем сайте имеется два самостоятельных раздела. Первый — это список товаров, второй — страница с подробными сведениями о товаре. Размер кода, уникального для каждого из них, составляет 25 Кб (а 150 Кб кода применяется и там и там).
Страница со сведениями о товаре не подвергается изменениям, так как мы уже довели её до совершенства. Поэтому, если мы выделим её код в отдельный файл, этот файл, большую часть времени работы с сайтом, будет загружаться в браузер из кэша.
Кроме того, как оказалось, у нас имеется огромный встроенный SVG-файл, используемый для рендеринга значков, который весит целых 25 Кб и изменяется редко.
С этим надо что-то делать.
Мы вручную создали несколько входных точек, сообщая Webpack о том, что ему нужно создать отдельный файл для каждой из этих сущностей.
module.exports = { entry: { main: path.resolve(__dirname, 'src/index.js'), ProductList: path.resolve(__dirname, 'src/ProductList/ProductList.js'), ProductPage: path.resolve(__dirname, 'src/ProductPage/ProductPage.js'), Icon: path.resolve(__dirname, 'src/Icon/Icon.js'), }, output: { path: path.resolve(__dirname, 'dist'), filename: '[name].[contenthash:8].js', }, plugins: [ new webpack.HashedModuleIdsPlugin(), // в результате хэши не будут неожиданно меняться ], optimization: { runtimeChunk: 'single', splitChunks: { chunks: 'all', maxInitialRequests: Infinity, minSize: 0, cacheGroups: { vendor: { test: /[\\/]node_modules[\\/]/, name(module) { // получает имя, то есть node_modules/packageName/not/this/part.js // или node_modules/packageName const packageName = module.context.match(/[\\/]node_modules[\\/](.*?)([\\/]|$)/)[1]; // имена npm-пакетов можно, не опасаясь проблем, использовать // в URL, но некоторые серверы не любят символы наподобие @ return `npm.${packageName.replace('@', '')}`; }, }, }, }, }, }; Трудолюбивый Webpack, кроме того, создаст файлы для того, что является общим, например, у ProductList и ProductPage, то есть, дублирующегося кода тут не будет.
То, что мы только что сделали, позволит Алисе экономить почти каждую неделю по 50 Кб трафика. Обратите внимание на то, что файл с описанием значков мы отредактировали на шестой неделе. Вот наша традиционная таблица.
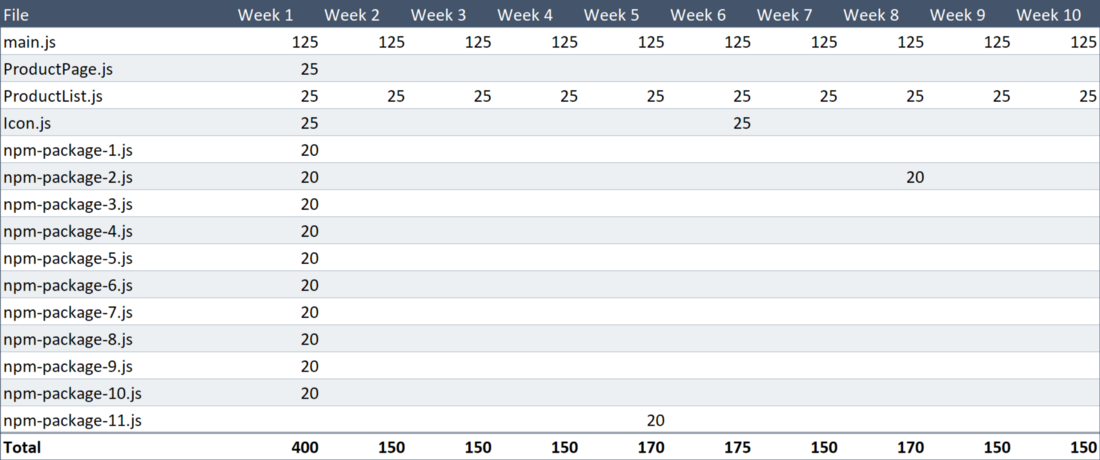
Объём данных, загруженных пользователем
Теперь за десять недель загружено всего 1.815 Мб данных. Это означает, что экономия трафика составила впечатляющие 56%. В соответствии с нашим теоретическим сценарием постоянный пользователь всегда будет работать с таким уровнем экономии.
Всё это сделано за счёт изменений, внесённых в конфигурацию Webpack. Код приложений мы для достижения таких результатов не меняли.
Выше я говорил о том, что конкретный сценарий, по которому проводится подобный тест, на самом деле, особой роли не играет. Сказано это из-за того, что, вне зависимости от используемого сценария, вывод из всего, о чём мы говорили, будет одним и тем же: разбиение приложения на небольшие файлы, имеющие смысл в применении к его архитектуре, позволяет снизить объёмы данных сайта, загружаемых его постоянными пользователями.
Совсем скоро мы перейдём к разговору о разделении кода, но сначала мне бы хотелось ответить на три вопроса, над которыми вы, наверняка, сейчас размышляете.
▍Вопрос №1. Разве необходимость выполнения множества запросов не вредит скорости загрузки сайта?
На этот вопрос можно дать простой короткий ответ: «Нет, не вредит». Подобная ситуация выливалась в проблему в былые времена, когда в ходу был протокол HTTP/1.1, а при использовании HTTP/2 это уже неактуально.
Хотя, надо отметить, что в этом материале, опубликованном в 2016 году, и в этой статье Khan Academy 2015 года делаются выводы о том, что даже при использовании HTTP/2, использование слишком большого количества файлов замедляет загрузку. Но в обоих этих материалах «слишком большое количество» означает «несколько сотен». Поэтому стоит помнить о том, что если вам приходится работать с сотнями файлов, на скорость их загрузки могут повлиять ограничения на параллельную обработку данных.
Если интересно, поддержка HTTP/2 имеется в IE 11 в Windows 10. Кроме того, я проводил всестороннее исследование среди тех, кто пользуется более старыми системами. Они единодушно заявили, что их скорость загрузки веб-сайтов особенно не заботит.
▍Вопрос №2. В Webpack-бандлах есть вспомогательный код. Создаёт ли он дополнительную нагрузку на систему?
Да, это так.
▍Вопрос №3. При работе с множеством маленьких файлов ухудшается уровень их сжатия, не так ли?
Да, это тоже так. На самом деле, мне хотелось бы сказать вот что:
- Больше файлов — значит больше вспомогательного Webpack-кода.
- Больше файлов — это меньший уровень сжатия.
Давайте с этим разберёмся для того, чтобы понять, насколько это плохо.
Только что я провёл испытание, в ходе которого код из файла размером 190 Кб был разбит на 19 частей. Это добавило примерно 2% к объёму данных, отправляемых в браузер.
В итоге получается, что при первом посещении сайта пользователь загрузит на 2% больше данных, а при последующих — на 60% меньше, и продолжаться это будет очень и очень долго.
Так стоит ли об этом беспокоиться? Нет, не стоит.
Когда я проводил сравнение системы, использующей 1 файл, и системы с 19 файлами, я испытал её с использованием различных протоколов, в том числе и HTTP/1.1. Нижеприведённая таблица очень сильно поддерживает идею о том, что больше файлов — значит лучше.

Данные о работе с 2 версиями сайта, размещённого на статическом хостинге Firebase, код которого имеет размеры 190 Кб, но, в первом случае, упакован в 1 файл, а во втором — разбит на 19
При работе в 3G и 4G-сетях на загрузку варианта сайта с 19 файлами ушло на 30% меньше времени, чем на загрузку сайта с одним файлом.
В данных, представленных в таблице, много шума. Например, один сеанс загрузки сайта по 4G (Run 2 в таблице) занял 646 мс, ещё один (Run 4) — 1116 мс, что на 73% дольше. Поэтому возникает ощущение, что говорить о том, что HTTP/2 «на 30% быстрее» — это несколько нечестно.
Я создал эту таблицу для того, чтобы посмотреть, что даёт использование HTTP/2. Но, на самом деле, единственное, что тут можно сказать, заключается в том, что применение HTTP/2, вероятно, не особо заметно влияет на загрузку страниц.
Настоящим сюрпризом стали две последних строчки в этой таблице. Тут представлены результаты для не самой новой версии Windows с IE11 и HTTP/1.1. Я, если бы заранее пытался предсказать результаты испытания, точно сказал бы, что такая конфигурация будет загружать материалы гораздо медленнее других. Правда, тут использовалось очень быстрое сетевое подключение, и мне, для подобных испытаний, вероятно, стоит пользоваться чем-то более медленным.
А теперь расскажу вам одну историю. Я, чтобы исследовать мой сайт на совсем уж древней системе, загрузил виртуальную машину Windows 7 с сайта Microsoft. Там был установлен IE8, который я решил обновить до IE9. Для этого я пошёл на страницу Microsoft, предназначенную для загрузки IE 9. Но сделать этого мне не удалось.
Вот незадача…
Кстати, если говорить об HTTP/2, хочется отметить, что этот протокол интегрирован в Node.js. Если вы хотите поэкспериментировать — можете воспользоваться написанным мной небольшим HTTP/2 сервером с поддержкой кэша ответов, gzip и brotli.
Пожалуй, о методике разделения бандлов я сказал всё, что хотел. Думаю, что единственный минус такого подхода, при использовании которого пользователям приходится загружать очень много файлов, на самом деле, не является таким уж «минусом».
Теперь поговорим о разделении кода.
Разделение кода
Основная идея методики разделения кода звучит так: «Не загружайте ненужный код». Мне говорили, что использование этого подхода имеет смысл лишь для некоторых сайтов.
Я предпочитаю, когда речь идёт о разделении кода, использовать правило 20/20, которое я только что сформулировал. Если есть какая-то часть сайта, которую посещают лишь 20% пользователей, и её функционал обеспечивают более 20% JavaScript-кода сайта, тогда этот код нужно загружать только по запросу.
Это, конечно, не абсолютные цифры, их можно подстроить под конкретную ситуацию, и в реальности существуют гораздо более сложные сценарии, чем вышеописанный. Самое важное тут заключается в балансе, и совершенно нормально совсем не пользоваться разделением кода, если для вашего сайта это не имеет смысла.
▍Разделять или нет?
Как найти ответ на вопрос о том, нужно вам разделение кода или нет? Предположим, у вас имеется интернет-магазин, и вы размышляете о том, надо ли отделить от остального кода тот код, который используется для приёма оплаты от покупателей, так как лишь 30% посетителей у вас что-то покупают.
Что тут сказать? Во-первых — вам стоило бы поработать над наполнением магазина и продавать что-то такое, что окажется интересным большему количеству посетителей сайта. Во-вторых — нужно понять то, какой объём кода совершенно уникален для того раздела сайта, где принимается оплата. Так как перед «разделением кода» следует всегда выполнять «разделение бандла», и вы, надеюсь, так и делаете, то вы, вероятно, уже знаете о том, какие размеры имеет интересующий нас код.
Возможно, этот код может оказаться меньше, чем вы думаете, поэтому, прежде чем радоваться новой возможности оптимизации сайта, стоит всё спокойно посчитать. Если у вас, например, имеется React-сайт, тогда хранилище, редьюсеры, система маршрутизации, действия, будут совместно использоваться всеми частями сайта. Уникальный для разных частей сайта код будет, в основном, представлен компонентами и вспомогательными функциями для них.
Итак, вы выяснили, что совершенно уникальный код раздела сайта, используемого для оплаты покупок, занимает 7 Кб. Размер остального кода сайта — 300 Кб. В подобной ситуации я не стал бы заниматься разделением кода по нескольким причинам:
- Если загрузить эти 7 Кб заранее, сайт это не замедлит. Помните, что файлы загружаются параллельно и попробуйте измерить разницу, необходимую для загрузки 300 Кб и 307 Кб кода.
- Если вы будете загружать этот код позже, тогда пользователю придётся ждать после нажатия на кнопку «Оплатить». А это ведь тот самый момент, когда вам надо, чтобы всё прошло настолько гладко, насколько это возможно.
- Разделение кода требует внесения изменений в приложение. В коде, в тех местах, где раньше всё делалось синхронно, появляется асинхронная логика. Конечно, космических сложностей в подобных преобразованиях кода не наблюдается, но это всё равно дополнительный объём работы, который, как мне кажется, должен выполняться ради ощутимого улучшения впечатления пользователя от работы с сайтом.
Собственно говоря, причины, по которым разделение кода может вам не подойти, мы обсудили.
А теперь рассмотрим пару примеров применения этой технологии.
▍Полифиллы
Я начинаю именно с этого примера, так как то, что мы тут рассмотрим, просто реализуется и применимо к большинству сайтов.
Я использую на своём сайте множество полезных штуковин в виде полифиллов. Поэтому у меня имеется файл, в котором всё это подключается. Он состоит из следующих восьми строчек:
require('whatwg-fetch'); require('intl'); require('url-polyfill'); require('core-js/web/dom-collections'); require('core-js/es6/map'); require('core-js/es6/string'); require('core-js/es6/array'); require('core-js/es6/object'); Этот файл импортируется в самом начале кода файла index.js, который является точкой входа в приложение:
import './polyfills'; import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } render(); // да, смысла во мне пока нетБлагодаря использованию конфигурации Webpack из предыдущего раздела, материалы полифиллов будут автоматически разделены на четыре файла, так как для их реализации используются четыре npm-пакета. Их размер составляет примерно 25 Кб, 90% браузеров они не нужны, поэтому имеет смысл загружать их динамически.
Благодаря применению Webpack 4 и использованию конструкции import() (не путайте её с ключевым словом import), организовать условную загрузку полифиллов очень просто:
import React from 'react'; import ReactDOM from 'react-dom'; import App from './App/App'; import './index.css'; const render = () => { ReactDOM.render(<App />, document.getElementById('root')); } if ( 'fetch' in window && 'Intl' in window && 'URL' in window && 'Map' in window && 'forEach' in NodeList.prototype && 'startsWith' in String.prototype && 'endsWith' in String.prototype && 'includes' in String.prototype && 'includes' in Array.prototype && 'assign' in Object && 'entries' in Object && 'keys' in Object ) { render(); } else { import('./polyfills').then(render); } Как видите, если всё, что нам надо, поддерживается — мы просто переходим к рендерингу. Если нет — импортируем полифиллы и уже после этого вызываем render(). Когда этот код выполняется в браузере, механизмы Webpack займутся загрузкой наших четырёх npm-пакетов, а когда они окажутся загружены и разобраны, будет осуществлён вызов render() и работа продолжится.
Кстати сказать, для использования import() вам понадобится плагин Babel dynamic-import. Кроме того, как сказано в документации к Webpack, команда import() использует промисы, поэтому полифилл для данной возможности нужно загружать отдельно от других полифиллов.
Как я и говорил, это очень просто. Рассмотрим теперь пример посложнее.
▍Динамическая загрузка материалов в React, основанная на маршрутах
Вернёмся к примеру с Алисой. Предположим, теперь на нашем сайте есть закрытый раздел для администраторов магазинов, куда они могут входить для того, чтобы управлять своими товарами.
В этом разделе имеется множество замечательных возможностей, куча графиков и здоровенная npm-библиотека для работы с ними. Так как на сайте уже применяется разделение бандлов, я могу понять, что всё это занимает более 100 Кб.
В настоящий момент настройки маршрутизации сайта таковы, что, когда пользователь просматривает URL /admin, рендерится <AdminPage>. Webpack разделил всё по бандлам, поэтому ему нужно найти конструкцию import AdminPage from './AdminPage.js' и включить это в первоначальную загрузку сайта.
Однако нам это не нужно. Нам надо поместить ссылку на материалы для административной страницы в команду, выполняющую динамический импорт, наподобие import('./AdminPage.js'), в результате Webpack будет знать о том, что загружать эти материалы надо динамически.
Причём, для этого не нужно заниматься конфигурированием.
Поэтому, вместо того, чтобы ссылаться на AdminPage напрямую, я могу создать другой компонент, который будет рендериться при переходе пользователя по URL /admin. Например, выглядеть он может так:
import React from 'react'; class AdminPageLoader extends React.PureComponent { constructor(props) { super(props); this.state = { AdminPage: null, } } componentDidMount() { import('./AdminPage').then(module => { this.setState({ AdminPage: module.default }); }); } render() { const { AdminPage } = this.state; return AdminPage ? <AdminPage {...this.props} /> : <div>Loading...</div>; } } export default AdminPageLoader; В основе всего этого лежит весьма простая идея. Когда данный компонент монтируется (предполагается, что пользователь перешёл по URL /admin), мы динамически загружаем ./AdminPage.js, после чего сохраняем ссылку на этот компонент в состоянии приложения.
В методе render() мы просто выводим, ожидая загрузки <AdminPage>, надпись <div>Loading...</div>, или выводим <AdminPage> после того, как эта сущность будет загружена и сохранена в состоянии.
Я сделал всё это своими силами ради интереса, но в реальных проектах достаточно воспользоваться react-loadable, как описано в документации React по разделению кода.
Итоги
Полагаю, я рассказал всё, что хотел (хотя, надо отметить, мы не говорили тут о CSS). Подведём краткие итоги:
- Если пользователи вашего сайта посещают его более одного раза — разделяйте код на множество небольших файлов.
- Если на вашем сайте есть крупные разделы, которые не посещает большинство пользователей — загружайте их код динамически.
Уважаемые читатели! Используете ли вы разделение бандлов и разделение кода в своих проектах?

ссылка на оригинал статьи https://habr.com/post/423483/
Добавить комментарий