XGBoost и LightGBM. А так же читатель познакомится с библиотекой leaves для Go, которая позволяет делать предсказания для ансамблей деревьев, не используя при этом C API оригинальных библиотек.
Откуда растут деревья?
Рассмотрим сначала общие положения. Обычно работают с деревьями, где:
1. разбиение в узле происходит по одному признаку
2. дерево бинарно — у каждого узла есть левый и правый потомок
3. в случае вещественного признака решающее правило состоит из сравнения значения признака с пороговым значением
Данную иллюстрацию я взял из документации XGBoost
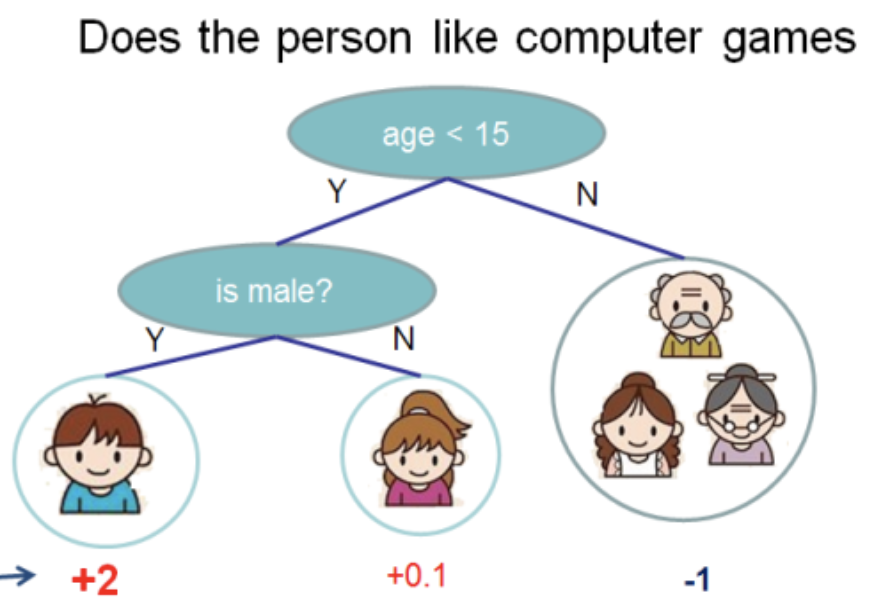
В данном дереве имеем 2 узла, 2 решающих правил и 3 листа. Под кружочками указаны значения — результат применения дерева к какому-то объекту. Обычно, к результату вычисления дерева или ансамбля деревьев применяют функцию трансформации. Например, сигмоиду для задачи бинарной классификации.
Для получения предсказаний от ансамбля деревьев, полученного методом градиентного бустинга, нужно сложить результаты предсказаний всех деревьев:
double pred = 0.0; for (auto& tree: trees) pred += tree->Predict(feature_values); Здесь и далее будет код на C++, т.к. именно на этом языке написаны XGBoost и LightGBM. Я буду опускать несущественные детали и стараться приводить максимально лаконичный код.
Далее рассмотрим, что скрывается в Predict, и как устроена структура данных дерева.
Деревья XGBoost
В XGBoost есть несколько классов (в смысле ООП) деревьев. Будем говорить об RegTree (см. include/xgboost/tree_model.h), которая со слов документации является основной. Если оставить только детали, важные для предсказаний, то члены класса выглядят максимально просто:
class RegTree { // vector of nodes std::vector<Node> nodes_; }; Решающее правило реализовано в функции GetNext. Код немного видоизменен, без влияния на результат вычислений:
// get next position of the tree given current pid int RegTree::GetNext(int pid, float fvalue, bool is_unknown) const { const auto& node = nodes_[pid] float split_value = node.info_.split_cond; if (is_unknown) { return node.DefaultLeft() ? node.cleft_ : node.cright_; } else { if (fvalue < split_value) { return node.cleft_; } else { return node.cright_; } } } Отсюда следуют две вещи:
-
RegTreeработает только с вещественными признаками (типfloat) - поддерживаются пропущенные значения признаков
Центральным местом является класс Node. В нем содержатся локальная структура дерева, решающее правило и значение листа:
class Node { public: // feature index of split condition unsigned SplitIndex() const { return sindex_ & ((1U << 31) - 1U); } // when feature is unknown, whether goes to left child bool DefaultLeft() const { return (sindex_ >> 31) != 0; } // whether current node is leaf node bool IsLeaf() const { return cleft_ == -1; } private: // in leaf node, we have weights, in non-leaf nodes, we have split condition union Info { float leaf_value; float split_cond; } info_; // pointer to left, right int cleft_, cright_; // split feature index, left split or right split depends on the highest bit unsigned sindex_{0}; }; Можно выделить следующие особенности:
- листы представлены как узлы, у которых
cleft_ = -1 - поле
info_представлено какunion, т.е. два типа данных (в данном случае одинаковые) делят один участок памяти в зависимости от типа узла - старший бит в
sindex_отвечает за то, куда спускается объект, у которого значение признака пропущено
Для того, чтобы можно было проследить путь от вызова метода RegTree::Predict до получения ответа, приведу недостающие две функции:
float RegTree::Predict(const RegTree::FVec& feat, unsigned root_id) const { int pid = this->GetLeafIndex(feat, root_id); return nodes_[pid].leaf_value; } int RegTree::GetLeafIndex(const RegTree::FVec& feat, unsigned root_id) const { auto pid = static_cast<int>(root_id); while (!nodes_[pid].IsLeaf()) { unsigned split_index = nodes_[pid].SplitIndex(); pid = this->GetNext(pid, feat.Fvalue(split_index), feat.IsMissing(split_index)); } return pid; } В функции GetLeafIndex мы в цикле спускаемся по узлам дерева, пока не попадем в лист.
Деревья LightGBM
В LightGBM нет структуры данных для узла. Вместо этого в структуре данных дерева Tree (файл include/LightGBM/tree.h) содержатся массивы значений, где в качестве индекса выступает номер узла. Значения в листьях также хранятся в отдельных массивах.
class Tree { // Number of current leaves int num_leaves_; // A non-leaf node's left child std::vector<int> left_child_; // A non-leaf node's right child std::vector<int> right_child_; // A non-leaf node's split feature, the original index std::vector<int> split_feature_; //A non-leaf node's split threshold in feature value std::vector<double> threshold_; std::vector<int> cat_boundaries_; std::vector<uint32_t> cat_threshold_; // Store the information for categorical feature handle and mising value handle. std::vector<int8_t> decision_type_; // Output of leaves std::vector<double> leaf_value_; }; LightGBM поддерживает категориальные признаки. Поддержка осуществляется с помощью битового поля, которое хранится в cat_threshold_ для всех узлов. В cat_boundaries_ хранит, к какому узлу какая часть битового поля соответствует. Поле threshold_ для категориального случая переводится в int и соответсвует индексу в cat_boundaries_ для поиска начала битового поля.
Рассмотрим решающее правило для категориального признака:
int CategoricalDecision(double fval, int node) const { uint8_t missing_type = GetMissingType(decision_type_[node]); int int_fval = static_cast<int>(fval); if (int_fval < 0) { return right_child_[node];; } else if (std::isnan(fval)) { // NaN is always in the right if (missing_type == 2) { return right_child_[node]; } int_fval = 0; } int cat_idx = static_cast<int>(threshold_[node]); if (FindInBitset(cat_threshold_.data() + cat_boundaries_[cat_idx], cat_boundaries_[cat_idx + 1] - cat_boundaries_[cat_idx], int_fval)) { return left_child_[node]; } return right_child_[node]; } Видно, что в зависимости от missing_type значение NaN автоматически спускает решение по правой ветви дерева. Иначе NaN заменяется на 0. Поиск значения в битовом поле осуществляется достаточно просто:
bool FindInBitset(const uint32_t* bits, int n, int pos) { int i1 = pos / 32; if (i1 >= n) { return false; } int i2 = pos % 32; return (bits[i1] >> i2) & 1; } т.е., например, для категориального признака int_fval=42 проверяется, выставлен ли 41-ый (нумерация с 0) бит в массиве.
Этот подход имеет один существенный недостаток: если категориальный признак может принимать большие значения, например 100500, то для каждого решающего правила для этого признака будет создано битовое поле размером до 12564 байт!
Поэтому желательно перенумеровать значения категориальных признаков, чтобы они шли непрерывно от 0 до максимального значения.
Со своей стороны я внес поясняющие правки в LightGBM и их приняли.
Работа с вещественными признаками мало чем отличается от XGBoost, и я пропущу это для краткости.
leaves — библиотека для предсказаний в Go
XGBoost и LightGBM очень мощные библиотеки для построения моделей градиентного бустинга на решающих деревьях. Для их использования в backend сервисе, где необходимы алгоритмы машинного обучения, необходимо решить следующие задачи:
- Периодическое обучение моделей в оффлайн
- Доставка моделей в backend сервис
- Опрос моделей онлайн
Для написания нагруженного backend сервиса популярным языком является Go. Тащить XGBoost или LightGBM через C API и cgo является не самым простым решением — усложняется сборка программы, из-за неосторожного обращения можно словить SIGTERM, проблемы с количеством системных потоков (OpenMP внутри библиотек vs потоки go runtime).
Поэтому я решил написать библиотеку на чистом Go для предсказаний с помощью моделей, построенных в XGBoost или LightGBM. Она называется leaves.

Основные возможности библиотеки:
- Для
LightGBMмоделей
- Чтение моделей из стандартного формата (текстовый)
- Поддержка вещественных и категориальных признаков
- Поддержка пропущенных значений
- Оптимизация работы с категориальными переменными
- Оптимизация предсказаний за счет структур данных, рассчитанных только на предсказания
- Для
XGBoostмоделей
- Чтение моделей из стандартного формата (бинарный)
- Поддержка пропущенных значений
- Оптимизация предсказаний
Приведу здесь минимальную программу на Go, которая загружает модель с диска и выводит на экран предсказание:
package main import ( "bufio" "fmt" "os" "github.com/dmitryikh/leaves" ) func main() { // 1. Открываем файл с моделью path := "lightgbm_model.txt" reader, err := os.Open(path) if err != nil { panic(err) } defer reader.Close() // 2. Читаем модель LightGBM model, err := leaves.LGEnsembleFromReader(bufio.NewReader(reader)) if err != nil { panic(err) } // 3. Делаем предсказание! fvals := []float64{1.0, 2.0, 3.0} p := model.Predict(fvals, 0) fmt.Printf("Prediction for %v: %f\n", fvals, p) } API библиотеки минималистичен. Для использования модели XGBoost достаточно вызвать метод leaves.XGEnsembleFromReader, вместо приведенного выше. Предсказания можно делать пачками, вызывая методы PredictDense или model.PredictCSR. Больше сценариев использования можно найти в тестах к leaves.
Несмотря на то, что язык Go работает медленней C++ (в основном из-за более тяжелого runtime и проверок времени выполнения), благодаря ряду оптимизаций удалось достичь скорости предсказаний, сопоставимой с вызовом C API оригинальных библиотек.
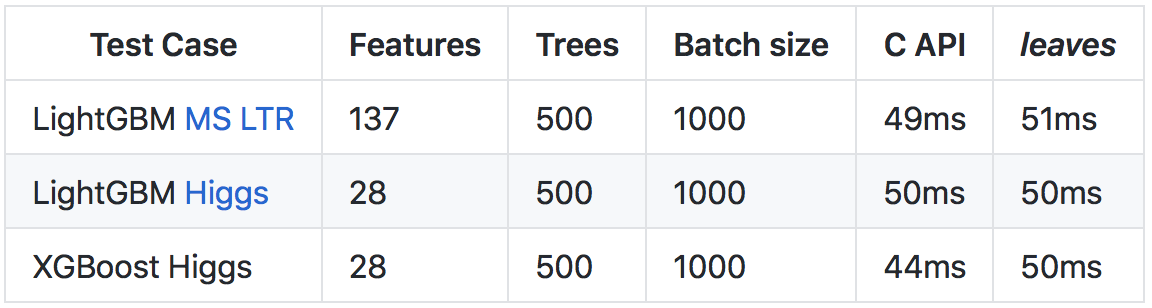
Более подробно о результатах и способе сравнений есть в репозитории на github.
Зри в корень
Надеюсь, данной статьей я приоткрыл дверцу в реализации деревьев в библиотеках XGBoost и LightGBM. Как видите, основные конструкции довольно просты, и я призываю читателей пользоваться преимуществом open source — изучать код, когда есть вопросы о том, как он работает.
Для тех же, кому интересна тема применения моделей градиентного бустинга в их сервисах на языке Go, рекомендую ознакомиться с библиотекой leaves. С помощью leaves можно довольно просто использовать leading edge решения в машинном обучении в вашей production среде, практически не проигрывая по скорости в сравнении с оригинальными реализациям на C++.
Успехов!
ссылка на оригинал статьи https://habr.com/post/423495/
Добавить комментарий