Сегодня мы добавим в анализе еще один аспект — сегментацию и кластеризацию клиентской базы. Как я уже не раз писал, анализ клиентской базы остается не полным, если мы смотрим на наших клиентов, как на большую кучу одинаковых людей. Клиенты разделяются на типы и по-разному потребяют продукт. Кто-то покупает часто, но не много, кто-то быстро уходит, кто-то покупает много и часто. Для увеличения эффективности стоит выяснить, какие есть группы клиентов и затем разобраться, как ваши действия позволят вам привлечь нужных вам клиентов. Используют два основных способа разобраться в группам ваших клиентов: эвристики и кластеризация
Метод 1: Эвристики и экспертные оценки
В рамках этого подхода вы на основе опыта, логики использования вашего продукта и клиентских историй, придумываете различные портреты потребителей и затем оцениваете, сколько у вас клиентов попадают под эти определения. Или же можете использовать более численные подходы, основанные на анализе показателей клиентов. Несколько популярных численным эвристик подходов это:
ABC-XYZ
Основная идея разделить клиентов по общему вкладу в вашу выручку и по динамике роста показателей. ABC отвечает за вклад в выручку, XYZ отвечает за стабильность выручки. Это формирует 9 сегментов
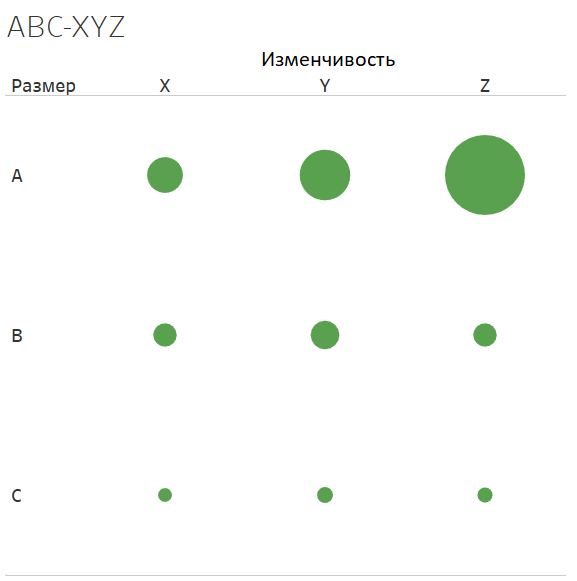
AX — самые большие и со стабильной выручкой
AZ — Большие, но они редко делают покупки, выручка не стабильна
CX — самые мелкие, но со стабильной выручкой
CZ — мелкие и выручка не стабильна, покупки совершают редко
В сегмент А определяют клиентов, кто формирует 80% выручки, в сегмент B, кто дает еще 15% и в сегмент C, кто дает 5%. В сегмент X — наименьшую вариативность выручки (можно взять 33 перцентиль), Z — наивысшая вариативность (соответственно верхний 33 перцентиль). Под вариативность я подразумеваю величину дисперсии выручки.
Что дает этот анализ: он позволяет разделить ваших клиентов на группы по степени важности для вашего бизнеса. Клиенты из группы AX, AY, AZ самые большие и вы должны уделять им больше всего внимания. Клиенты групп BX, BY требуют дополнительного внимания, их можно развивать. Внимание к группам в других категориях можно снижать. Особенно хорошо, если вам удастся выделить общности между клиентами в разных сегментах, что позволит вам таргетировать усилия по привлечению нужных клиентов.
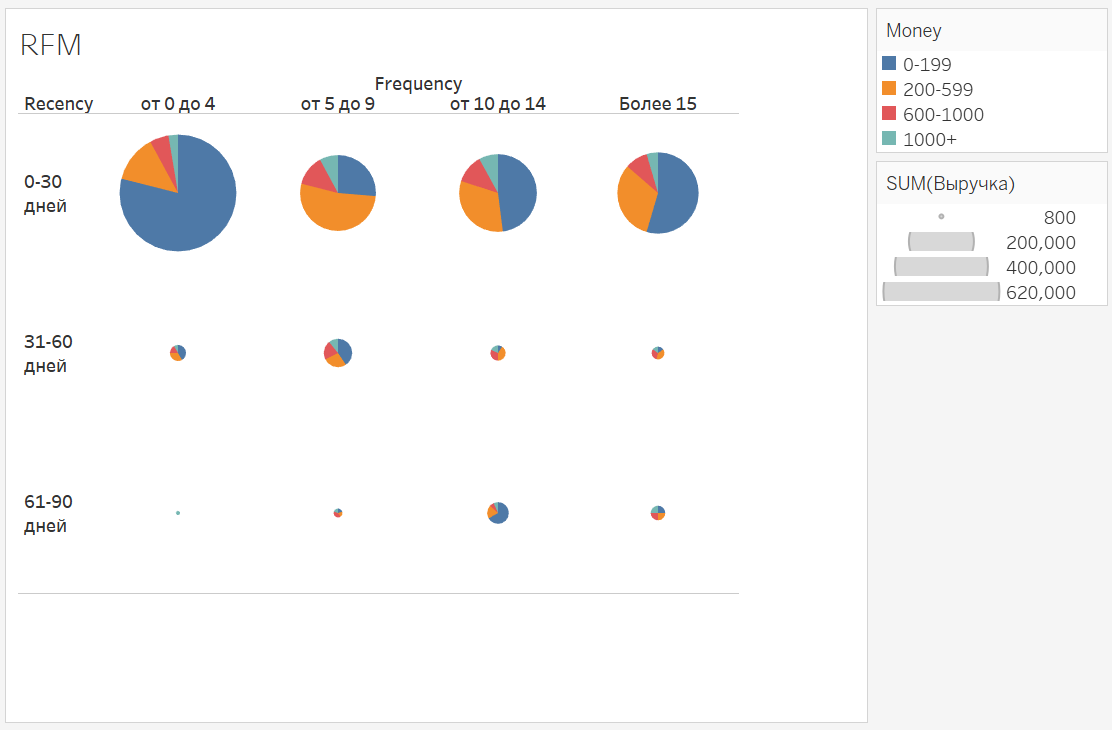
RFM (Recency-Frequency-Money)
Основная идея разделить клиентов по 3-м свойствам: как давно была продажа клиенту (recency), как часто он покупает товары (frequency), какой объем выручки он сгенерировал(money). В целом подход напоминает ABС-XYZ, но несколько под другим углом.
В рамках этого подхода вы разделяете клиентов по группам Recency, например:
- 0-30 дней
- 31-60 дней
- 61-90 дней
- 90+
По кол-ву покупок, например:
- Более 15
- 10-14
- 5-9
- 0-4
По объему выручки:
- 1000+
- 600-1000
- 200-599
- 0-199
Понятно, что для каждого конкретного продукта, приложения или товара вам нужно установить свои границы.
В итоге вы сможете разделить клиентов на множество сегментов, каждый из которых характеризует клиента по степени важности для вас.
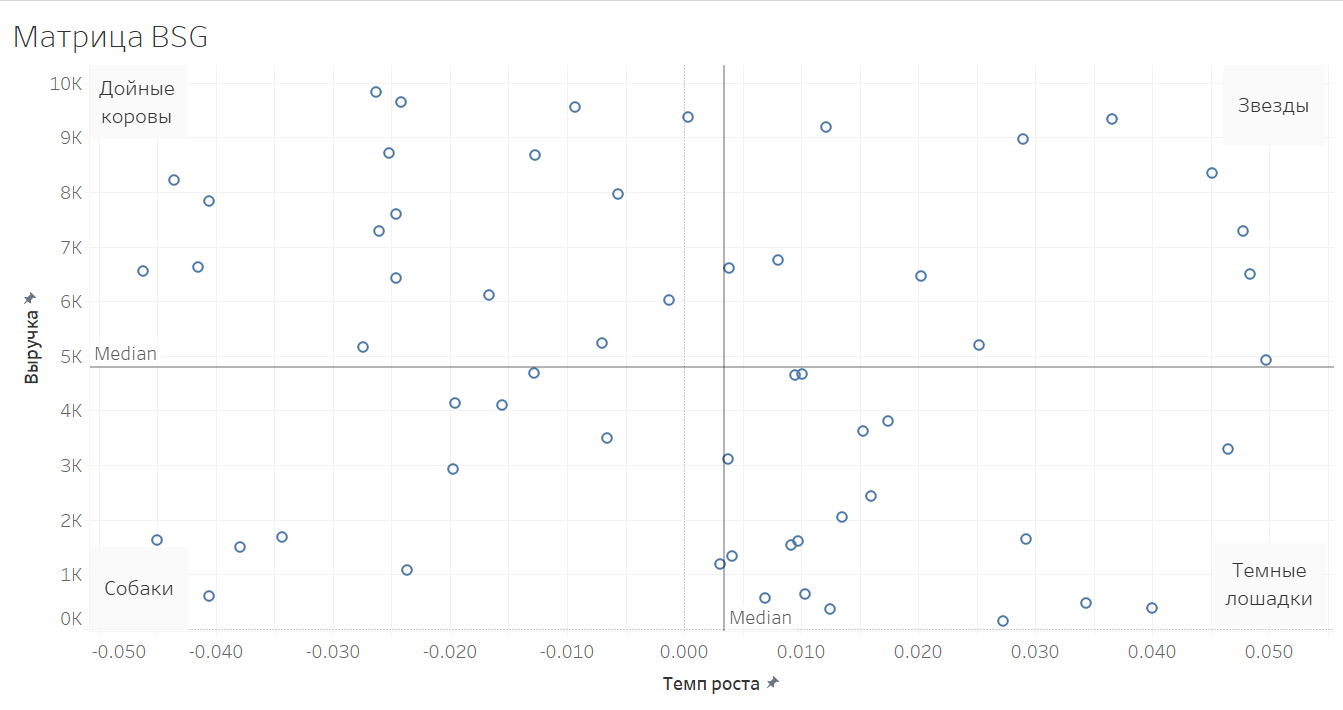
Матрица BCG
Основная идея разделить клиентов по категориям объема выручки и темпов роста выручки. Такой подход позволяет определить, кто большой и насколько быстро растет. Все клиенты раскладываются на 4 квадранта:
- Звезды — крупнейшие клиенты с высоким темпов роста выручки. Это клиенты, кому надо уделять наибольшее внимание. Это сильная точка роста
- Дойные коровы — крупные клиенты, с низкими или отрицательными темпами выручки. Эти клиенты будут формировать ядро вашей текущей выручки. Проглядите коров и потеряете бизнес.
- Темные лошадки — пока мелкие клиенты, но с большим темпом роста. Это группы клиентов, на кого надо обращать внимание, т.к. они могут вырасти до звезд или дойных коров.
- Собаки — мелкие клиенты с низкими или отрицательными темпами роста. Это клиенты, кому можно уделять наименьшее внимание и применять к ним массовые методы обслуживания, для сокращения издержек.
Преимущества всех эвристических методов — относительная простота реализации и возможность разделить своих клиентов на понятные с точки зрения бизнеса группы.
Недостатки в том, что мы используем всего лишь несколько свойств клиентов, для их описания и исключаем из рассмотрения прочие факторы. В добавок, чаще всего клиенты оказываются в сегментах временно, меняют позицию, а установить реальную общность внутри сегмента оказывается сложно.
Метод 2: Кластеризация
Основная идея — найти группы клиентов без использования предварительных гипотез о структуре клиентской базы, найти натуральные кластеры среди свойств клиентов исходя из имеющихся данных.
Существует набор методов (K-mean, C-mean, иерархическая кластеризация и т.п.), которые позволяют вам определить близость объектов друг друга на основании их свойств. В общем случае вы описываете вашего клиента как вектор, каждый элемент этого вектора описывает какую-то характеристику клиента (будь то выручка, кол-во месяцев сотрудничества, адрес регистрации, купленные продукты и т.п.). После чего вы преобразуете этот вектор в нужный формат для вашего алгоритма, натравливаете алгоритм на данные (и настраиваете его для кластеризации) и получаете на выходе разделение клиентов на кластеры.
Хотя процесс не выглядит сложным, детали методов и их интерпретация имеет большое значение. Выбранные метрики “расстояния”, способ трансформации данных и кол-во выбранных факторов могут сильно менять картину. Так как в конечном итоге в многомерных данных нет однозначно “правильного” решения задачи кластеризации, вам в конечном итоге придется самостоятельно оценивать качество кластеров, а именно в итоге искать для них “бизнес” интерпретацию, если вы собрались использовать эти кластеры в принятии решений людьми.
По опыту могу сказать, что не стоит использовать сложные и логически не связанные свойства клиентов, а также хитрые трансформации. Несмотря на вероятные, элегантные решения по линии алгоритмов на выходе вы можете получить сложно интерпретируемые кластеры, которые ничего вам не надут в бизнес контексте. Возможно ваш метод и хорош, если кластера будут использоваться для входных параметров другой системы машинного обучения. Но когда вы хотите разделить клиентскую базу и сформулировать маркетинговую стратегию, то такие хитрые кластера вас никуда не приведут.
Сам процесс кластеризации это итеративный процесс:
- Составьте вектор
- Трансформируйте данные
- Настройте параметры алгоритма
- Сделайте кластеризацию
- Оцените кластеры экспертно, можете ли вы их использовать
- Повторите п.1., если кластеры вас не удовлетворили
Преимущество этого подхода, что через множество итераций вы куда лучше будете понимать ваших клиентов и данных о них, т.к. Каждая попытка кластеризации покажет вам разрез поведения и свойств клиентов, на который вы никогда скорее всего не смотрели. Вы так же лучше поймете взаимосвязи и взаимоотношения между разными клиентами. Поэтому я советую проделать это упражнение и вывести свои собственные кластеры.
Прошлый статьи в цикле:
Это 6-ая статья в цикле статей по анализу продукта:
- Top-Down approach. Экономика продукта. Gross Profit
- Экономика продукта. Анализ выручки
- Погружаемся в динамику клиентской базы: когортный анализ и анализ потоков
- Собираем когортный анализ/анализ потоков на примере Excel
- Аналитика воронки продаж
- MPRU, выручка и как это связано с выручкой и динамикой клиентской базы
ссылка на оригинал статьи https://habr.com/post/423597/
Добавить комментарий