Об этом мы поговорили с Андреем Кармацким, гендиректором компании Urbica. Компания специализируется на визуализации городских данных. Среди ее проектов — редизайн карты для MAPS.ME, интерактивная визуализация статистики поездок для «Велобайка» и визуализация для запуска системы наземного городского транспорта «Магистраль».
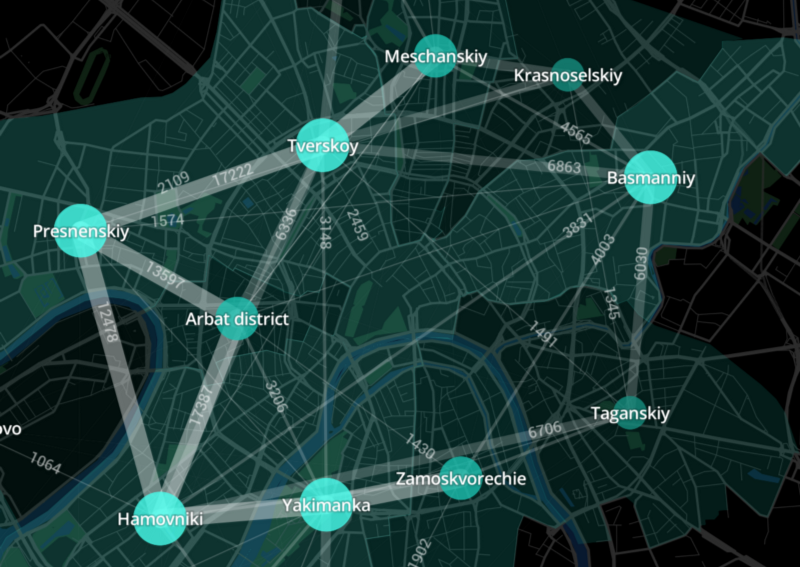
Велосипедный трафик между районами в центре Москвы. Источник изображений — блог «Урбики» на Medium

Во многих своих проектах Urbica отслеживает перемещения людей внутри города. Какие типы данных вы при этом используете?
Мы не собираем данные самостоятельно. Для каждого проекта мы используем данные заказчика либо организуем их сбор (например, полевые исследования и наблюдения на улице для валидации данных).
Для визуализации поездок на «Яндекс.Такси» мы использовали данные о перемещениях такси, для «Велобайка» использовались анонимизированные данные о перемещениях пользователей сервиса, для транспортного планирования сети маршрутов наземного транспорта «Магистраль» — данные о перемещениях пассажиров на транспорте, данные мобильных операторов, телеметрические данные движения транспортных средств (все автобусы, троллейбусы и трамваи оборудованы датчиками ГЛОНАСС).
Естественно, передаваемые нам данные уже агрегированы и не нарушают законодательство о персональных данных.
Интерактивная карта живет по адресу urbica.co/bikes
Наша история с «Велобайком» началась с визуализации перемещения велосипедов по итогам сезона для стенда на Московском урбанистическом форуме. Эти визуализации также использовались для спецпроекта «Афиши» в онлайне.Визуализировав данные, мы нашли очень много интересного: мы наглядно показали, чем отличаются сценарии использования прокатных велосипедов на различных тарифах, в различное время суток, в различных районах города. Проще говоря, визуализация данных (до этого момента вся аналитика была у «Велобайка» была в Excel) позволила увидеть разницу между станцией проката в центре города, и, например, рядом с Битцевским парком — это совершенно разные сценарии использования велосипеда, и, как следствие, различные модели спроса.
Среди любопытных наблюдений в данных мы увидели проблему, которую можно решить с помощью аналитики. Спрос на станции велопроката неравномерный. Это означает, что можно прийти к станции и не обнаружить свободных велосипедов или не найти свободного места, чтобы запарковать уже арендованный велосипед. «Велобайк» решает эту проблему с помощью небольшого парка грузовичков, которые ребалансируют систему проката между 450 станциями. Мы решили разработать систему предсказания спроса и внедрить эту систему в процесс диспетчеризации водителей, чтобы улучшить городской сервис проката и оптимизировать затраты на обслуживание.
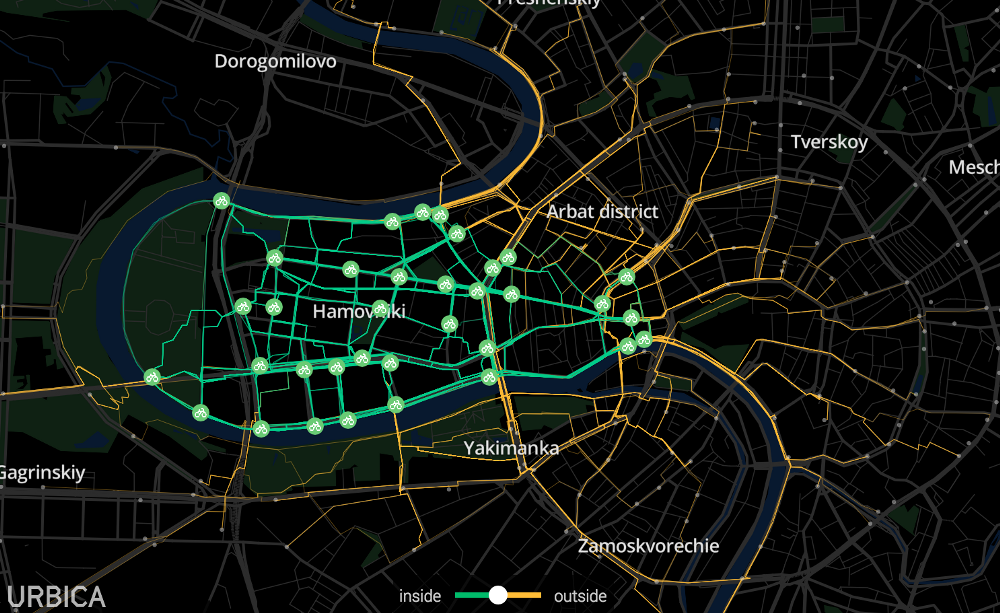
Как работает предсказательная система для диспетчеров «Велобайка»? Какие методы в ней используются для расчетов?
Для создания модели предсказания спроса на велосипеды мы использовали статистику загруженности станций (сколько велосипедов доступно) за все предыдущие сезоны, классифицировали районы города по признакам изменения плотности населения и рабочих мест в различные дни недели и время суток, учли рельеф (он очень влияет на баланс отправлений-прибытий велосипедистов на станцию). Предсказательная модель использует метод XGBoost и даёт прогнозное значение загруженности станции (потенциальный спрос) на час вперёд — именно за такой временной интервал водитель может приехать на станцию и забрать или привезти велосипеды.
Для общения с системой водители должны были использовать чат-бота в «Телеграме». Пришлось ли менять способ коммуникации из-за блокировок?
Мы планировали внедрение чат-бота для водителей системы этим летом, чтобы не вовлекать диспетчера в этот процесс, так как модель в большинстве случаев не требует участия человека. К сожалению, из-за блокировок этой весной чат-бот не был внедрён.
Какие еще городские данные имеет смысл прогонять через подобные алгоритмы? Где это принесет наибольшую выгоду?
Эту конкретную модель, кажется, применить можно только к станциям велопроката, однако в городе очень много интересных задач, где аналитика данных могла бы помочь. Например, нам кажется интересной задача выявлять неоптимальные маршруты наземного транспорта и создавать более эффективную сеть маршрутов.
Общий интерфейс «диспетчерской»Компания Urbica — один из экспонентов AI Conference:
«Мы покажем инструменты и технологии визуализации больших массивов данных, которые мы разработали и используем в нашей компании. Это будет интересно компаниям, у которых возникают задачи визуального анализа больших массивов информации».
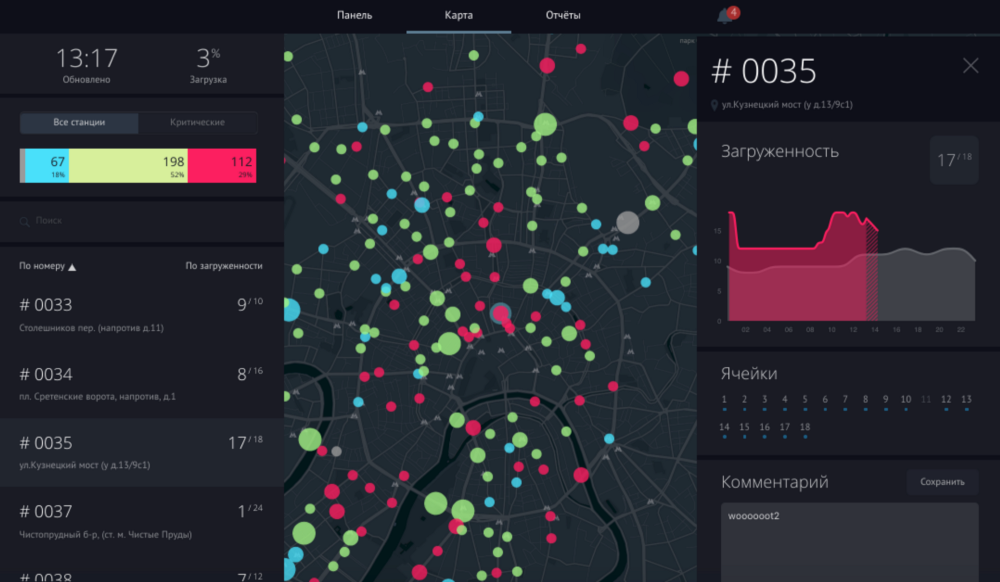
Поговорим про дизайнерскую составляющую вашей работы. Какие тенденции сейчас есть в сфере визуализации данных? Какое оформление выглядит как явно устаревшее?
Вопрос, наверное, не про оформление, а скорее про удобство и информативность. Аналитические интерфейсы, где нужна визуализация, в первую очередь решают прикладные задачи, и основная цель дизайна интерфейсов с большими массивами данных — создать удобный инструментарий для решения задачи.
Занимаясь визуализацией данных, очень легко забыть про исходную задачу и увлечься самим процессом визуализации. Многие хорошие проекты с городскими данными стоит воспринимать как дата-арт, это другой путь и цель визуализации другая.
Оцените работу коллег: какие крутые проекты в вашей области вышли в последнее время?
Нам очень нравится работа коллег из команды визуализации компании Uber. Они создали собственный инструмент визуализации данных Kepler.GL, сделали его доступным для всех пользователей и опубликовали его код в open-source.
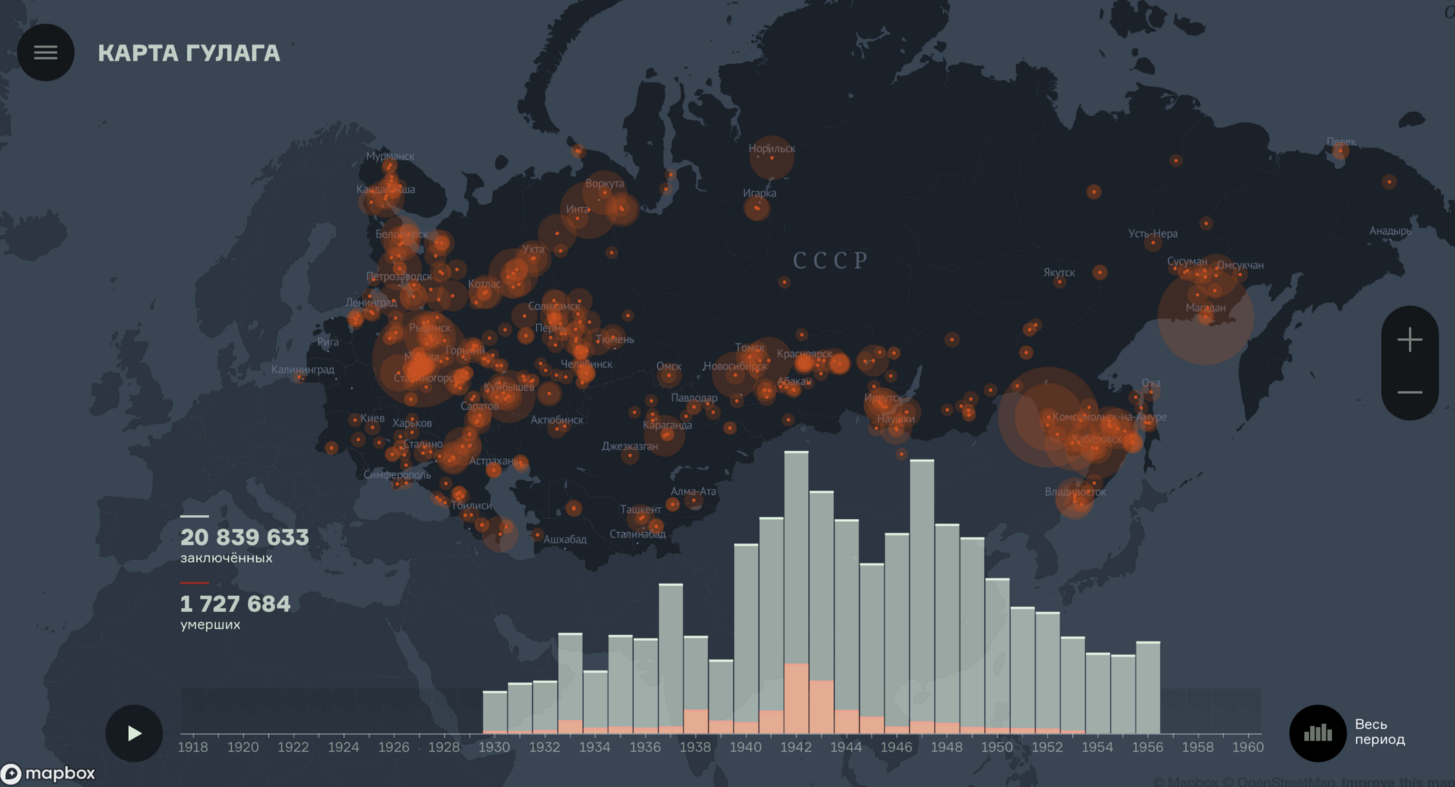
Составление интерактивной карты ГУЛАГа заняло два года. См. gulagmap.ru
Среди всех ваших проектов и тематически, и по количеству затраченного времени выделяется проект с интерактивной картой ГУЛАГа. Чем отличался процесс работы над ней?
Работа для Государственного музея истории ГУЛАГа по созданию интерактивной карты лагерей для нас очень важна. Конечный пользователь этой карты или посетитель музея (в декабре эта карта будет представлена в обновлённой экспозиции) смотрит на карту и видит лишь временной слайдер и меняющуюся по годам статистику количества заключённых. Это самый верхний слой проекта. Чтобы создать этот интерфейс, нужно было собрать большое количество данных, которые до этого момента существовали только на бумаге. Совместно с научным отделом музея мы разработали специальную базу данных и инструменты сбора данных, чтобы перенести крупицы сведений из архивов на карту. Этот проект важен и в социальном плане — таким образом мы можем привлечь внимание к истории нашей страны. О таких страшных вещах как ГУЛАГ нужно знать, их невозможно забыть.
Какие изменения претерпел проект от первой версии до финальной?
Сам интерфейс карты и стиль, пожалуй, менялся незначительно. Мы создали прототип и последовательными итерациями разрабатывали интерфейс для пользователей. А вот внутреннее наполнение проекта менялось сильно — первая версия не предполагала системы заполнения данных в базу. По ходу проекта мы вместе с музеем учились, познавали новые потребности и возможности для улучшения «начинки» карты.
Для этой карты вы разработали собственный компонент, React Map GL. Чем он лучше готовых решений?
Мы активно используем технологии от компании Mapbox, она предоставляет лучшие, на мой взгляд, инструменты разработчиков картографических проектов. При этом на фронтенде мы используем React.js. Мы изучили имеющиеся решения карты Mapbox в React.js и поняли, что нам необходим свой компонент.
Примерно так же вышло с проектом визуализации данных исследования городских агломераций: мы увидели, что имеющиеся готовые решения нас не устраивают и разработали собственный сервер векторных тайлов, который мы продемонстрируем на AI Conference.
Какие технологии вы чаще всего используете в своей работе?
Как уже сказал, для фронтенд-разработки React/Redux, для бэкенда — Node.js / Rust / Python, для аналитики данных — Pyhton, для хранения данных и геообработки — PostgreSQL/PostGIS. Наверное, тут нет каких-то супер-экзотичных технологий.
Что для вас самое важное в вашей работе? Какую глобальную задачу вы стараетесь решить?
Самое важное — нести ценность и видеть результаты своей работы в окружающем нас городском пространстве: музей это, велопрокат или общественный транспорт. Основная идея создания «Урбики» осталась неизменной — мы делаем интерфейсы, в которых сложные массивы данных становятся понятными и простыми для понимания.
ссылка на оригинал статьи https://habr.com/company/smileexpo/blog/428223/
Добавить комментарий