Машинное и глубокое обучение стали новой эффективной стратегией, которую для увеличения доходов используют многие инвестиционные фонды. В статье я объясню, как нейронные сети помогают спрогнозировать ситуацию на фондовом рынке — например, цену на акции (или индекс). В основе текста мой проект, написанный на языке Python. Полный код и гайд по программе можно найти на GitHub. Другие статьи по теме читайте в блоге на Medium.
Нейронные сети в экономике
Изменения в сфере финансов происходят нелинейно, и иногда может показаться, что цены на акции формируются совершенно случайным образом. Традиционные методы временных рядов, такие как модели ARIMA и GARCH эффективны, когда ряд является стационарным — его основные свойства со временем не изменяются. А для этого требуется, чтобы ряд был предварительно обработан с помощью log returns или приведён к стационарности по-другому. Однако главная проблема возникает при реализации этих моделей в реальной торговой системе, так как при добавлении новых данных стационарность не гарантируется.
Решением такой проблемы могут быть нейронные сети, которые не требуют стационарности. Нейронные сети изначально очень эффективны в поиске связей между данными и способны на их основе прогнозировать (или классифицировать) новые данные.
Обычно data science проект состоит из следующих операций:
- Сбор данных — обеспечивает набор необходимых свойств.
- Предварительная обработка данных — часто пугающий, но необходимый шаг перед использованием данных.
- Разработка и реализация модели — выбор типа нейронной сети и её параметров.
- Модели бэктестинга (тестирование на исторических данных) — ключевой шаг любой торговой стратегии.
- Оптимизация — поиск подходящих параметров.
Входные данные для нашей нейронной сети — данные о ценах на акции за последние 10 дней. С их помощью мы спрогнозируем цены на следующий день.
Сбор данных
К счастью, необходимые для этого проекта данные можно найти на Yahoo Finance. Данные можно собрать, используя их Python API pdr.get_yahoo_data(ticker, start_date, end_date) или напрямую с сайта.
Предварительная обработка данных
В нашем случае данные нужно разбить на обучающие наборы, состоящие из 10-ти прошлых цен и цены следующего дня. Для этого я определил класс Preprocessing, который будет работать с обучающими и тестовыми данными. Внутри класса я определил метод get_train(self, seq_len), который преобразовывает обучающие входные и выходные данные в NumPy массивы, задавая определенную длину окна (в нашем случае 10). Весь код выглядит так:
def gen_train(self, seq_len): """ Generates training data :param seq_len: length of window :return: X_train and Y_train """ for i in range((len(self.stock_train)//seq_len)*seq_len - seq_len - 1): x = np.array(self.stock_train.iloc[i: i + seq_len, 1]) y = np.array([self.stock_train.iloc[i + seq_len + 1, 1]], np.float64) self.input_train.append(x) self.output_train.append(y) self.X_train = np.array(self.input_train) self.Y_train = np.array(self.output_train) Аналогично я определил метод, который преобразовывает тестовые данные X_test и Y_test.
Модели нейронных сетей
Для проекта я использовал две модели нейронных сетей: Многослойный перцептрон Румельхарта (Multilayer Perceptron — MLP) и модель Долгой краткосрочной памяти (Long Short Term Model — LSTM). Кратко расскажу о том, как работают эти модели. Подробнее о MLP читайте в другой статье, а о работе LSTM — в материале Джейкоба Аунгиерса.
MLP — самая простая форма нейронных сетей. Входные данные попадают в модель и с помощью определённых весов значения передаются через скрытые слои для получения выходных данных. Обучение алгоритма происходит от обратного распространения через скрытые слои, чтобы изменить значение весов каждого нейрона. Проблема этой модели — недостаток «памяти». Невозможно определить, какими были предыдущие данные и как они могут и должны повлиять на новые. В контексте нашей модели различия за 10 дней между данными двух датасетов могут иметь значение, но MLP не способны анализировать такие связи.
Для этого используется LSTM или Рекуррентные нейронные сети (Recurrent Neural Networks — RNN). RNN сохраняют определенную информацию о данных для последующего использования, это помогает нейронной сети анализировать сложную структуру связей между данными о ценах на акции. Но с RNN возникает проблема исчезающего градиента. Градиент уменьшается, потому что количество слоев повышается и уровень обучения (значение меньше единицы) умножается в несколько раз. Решают эту проблему LSTM, увеличивая эффективность.
Реализация модели
Для реализации модели я использовал Keras, потому что там слои добавляются постепенно, а не определяют всю сеть сразу. Так мы можем быстро изменять количество и тип слоев, оптимизируя нейронную сеть.
Важный этап работы с ценами на акции — нормализация данных. Обычно для этого вы вычитаете среднюю погрешность и делите на стандартную погрешность. Но нам нужно, чтобы эту систему можно было использовать в реальной торговле в течение определенного периода времени. Таким образом, использование статистики может быть не самым точным способом нормализации данных. Поэтому я просто разделил все данные на 200 (произвольное число, по сравнению с которым все другие числа малы). И хотя кажется, что такая нормализация ничем не обоснована и не имеет смысла, она эффективна, чтобы убедиться, что веса в нейронной сети не становятся слишком большими.
Начнем с более простой модели — MLP. В Keras строится последовательность и поверх неё добавляются плотные слои. Полный код выглядит так:
model = tf.keras.models.Sequential() model.add(tf.keras.layers.Dense(100, activation=tf.nn.relu)) model.add(tf.keras.layers.Dense(100, activation=tf.nn.relu)) model.add(tf.keras.layers.Dense(1, activation=tf.nn.relu)) model.compile(optimizer="adam", loss="mean_squared_error")С помощью Keras в пяти строках кода мы создали MLP со скрытыми слоями, по сто нейронов в каждом. А теперь немного об оптимизаторе. Популярность набирает метод Adam (adaptive moment estimation) — более эффективный оптимизационный алгоритм по сравнению с стохастическим градиентным спуском. Есть два других расширения стохастического градиентного спуска — на их фоне сразу видны преимущества Adam:
AdaGrad — поддерживает установленную скорость обучения, которая улучшает результаты при расхождении градиентов (например, при проблемах с естественным языком и компьютерным зрением).
RMSProp — поддерживает установленную скорость обучения, которая может изменяться в зависимости от средних значений недавних градиентов для веса (например, насколько быстро он меняется). Это значит, что алгоритм хорошо справляется с нестационарными проблемами (например, шумы).
Adam объединяет в себе преимущества этих расширений, поэтому я выбрал его.
Теперь подгоняем модель под наши обучающие данные. Keras снова упрощает задачу, нужен только следующий код:
model.fit(X_train, Y_train, epochs=100)Когда модель готова, нужно проверить её на тестовых данных, чтобы определить, насколько хорошо она сработала. Это делается так:
model.evaluate(X_test, Y_test)Информацию, полученную в результате проверки, можно использовать, чтобы оценить способность модели прогнозировать цены акций.
Для модели LSTM используется похожая процедура, поэтому я покажу код и немного объясню его:
model = tf.keras.Sequential() model.add(tf.keras.layers.LSTM(20, input_shape=(10, 1), return_sequences=True)) model.add(tf.keras.layers.LSTM(20)) model.add(tf.keras.layers.Dense(1, activation=tf.nn.relu)) model.compile(optimizer="adam", loss="mean_squared_error") model.fit(X_train, Y_train, epochs=50) model.evaluate(X_test, Y_test)Обратите внимание, что для Keras нужны данные определенного размера, в зависимости от вашей модели. Очень важно изменить форму массива с помощью NumPy.
Модели бэктестинга
Когда мы подготовили наши модели с помощью обучающих данных и проверили их на тестовых, мы можем протестировать модель на исторических данных. Делается это следующим образом:
def back_test(strategy, seq_len, ticker, start_date, end_date, dim): """ A simple back test for a given date period :param strategy: the chosen strategy. Note to have already formed the model, and fitted with training data. :param seq_len: length of the days used for prediction :param ticker: company ticker :param start_date: starting date :type start_date: "YYYY-mm-dd" :param end_date: ending date :type end_date: "YYYY-mm-dd" :param dim: dimension required for strategy: 3dim for LSTM and 2dim for MLP :type dim: tuple :return: Percentage errors array that gives the errors for every test in the given date range """ data = pdr.get_data_yahoo(ticker, start_date, end_date) stock_data = data["Adj Close"] errors = [] for i in range((len(stock_data)//10)*10 - seq_len - 1): x = np.array(stock_data.iloc[i: i + seq_len, 1]).reshape(dim) / 200 y = np.array(stock_data.iloc[i + seq_len + 1, 1]) / 200 predict = strategy.predict(x) while predict == 0: predict = strategy.predict(x) error = (predict - y) / 100 errors.append(error) total_error = np.array(errors) print(f"Average error = {total_error.mean()}")Однако, это упрощенная версия тестирования. Для полной системы бэктестинга нужно учитывать такие факторы, как «ошибка выжившего» (survivorship bias), тенденциозность (look ahead bias), изменение ситуации на рынке и транзакционные издержки. Так как это только образовательный проект, хватает и простого бэктестинга.
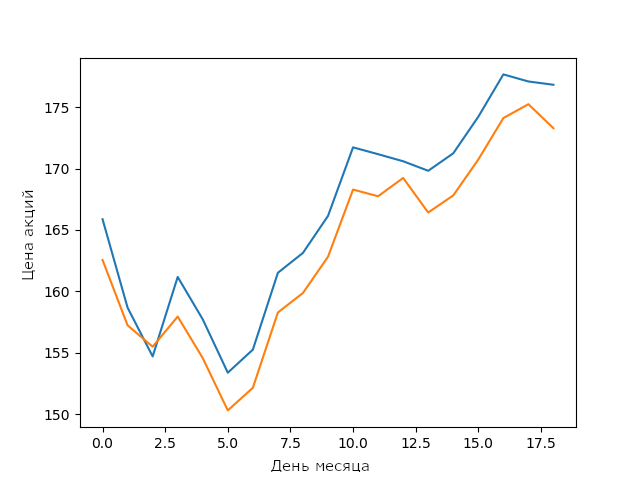
Прогноз моей модели LSTM на цены акций Apple в феврале
Для простой LSTM модели без оптимизации это очень хороший результат. Он показывает, что нейронные сети и модели машинного обучения способны строить сложные устойчивые связи между параметрами.
Оптимизация гиперпараметров
Для улучшения результатов модели после тестирования часто нужна оптимизация. Я не включил её в версию с открытым исходным кодом, чтобы читатели могли сами попробовать оптимизировать модель. Тем, кто не умеет оптимизировать, придется найти гиперпараметры, которые улучшат производительность модели. Есть несколько методов поиска гиперпараметров: от подбора параметров по сетке до стохастических методов.
Я уверен, с оптимизацией моделей знания в сфере машинного обучения выходят на новый уровень. Попробуйте оптимизировать модель так, чтобы она работала лучше моей. Сравните результат с графиком выше.
Вывод
Машинное обучение непрерывно развивается — каждый день появляются новые методы, поэтому очень важно постоянно обучаться. Лучший способ для этого — создавать интересные проекты, например, строить модели для прогноза цен на акции. И хотя моя LSTM-модель недостаточно хороша для использования в реальной торговле, фундамент, заложенный при разработке такой модели, может помочь в будущем.
От редакции
Курсы «Нетологии» по теме:
- онлайн-профессия «Аналитик данных»
- онлайн-профессия «Data Scientist»
ссылка на оригинал статьи https://habr.com/company/netologyru/blog/428227/
Добавить комментарий