Относительно недавно, в этом, 2019 году, NVIDIA анонсировала одноплатный компьютер совместимого с Raspberry Pi форм-фактора, ориентированный на AI и ресурсоемкие расчеты.

После его появления в продаже, стало интересно посмотреть, как это работает и что на нем можно делать. Стандартные бенчмарки использовать не так интересно, так что придумаем свои, для всех тестов в тексте приведены исходники. Для тех, кому интересно что получилось, продолжение под катом.
Hardware
Для начала, технические характеристики с сайта NVIDIA:

Из интересного, здесь можно отметить несколько моментов.
Первое — это GPU, имеющий 128 ядер, соответственно, на плате можно запускать GPU-ориентированные задачи, вроде CUDA (поддерживается и установлен из «коробки») или Tensorflow. Основной процессор 4х ядерный, и как будет показано ниже, вполне неплохой. Память 4Гб, общая между CPU и GPU.
Второе — это совместимость с Raspberry Pi. Плата имеет 40-пиновый разъем с различными интерфейсами (I2C, SPI и пр), также имеется разъем камеры, который тоже совместим с Raspberry Pi. Можно предположить, что большое количество уже имеющихся аксессуаров (экраны, платы управления моторами и пр) будут работать (возможно придется использовать удлиннительный кабель, т.к. Jetson Nano по размеру больше чем Raspberry Pi).
Третье — на плате имеется 2 HDMI-выхода, Gigabit-Ethernet и USB 3.0, т.е. Jetson Nano в целом даже чуть более функциональна чем «прообраз». Питание 5В, может браться как по Micro USB, так и через отдельный разъем, который рекомендуется для майнинга биткоинов ресурсоемких задач. Так же как и в Raspberry Pi, софт грузится с SD-карты, образ которой нужно предварительно записать. В целом, по идеологии, плата вполне похоже на Raspberry Pi, что видимо и задумывалось в NVIDIA. Но вот WiFi на плате нет, что есть определенный минус, желающим придется использовать USB-WiFi модуль.
Кстати о цене. Оригинальная цена Jetson Nano в США 99$, цена в Европе с наценкой в местных магазинах порядка 130Евро (если ловить скидки, наверно можно найти и дешевле). Сколько стоит Nano в России, неизвестно.
Software
Как упоминалось выше, загрузка и установка мало отличается от Raspberry Pi. Загружаем образ на SD-карту через Etcher или Win32DiskImager, попадаем в Linux, ставим необходимые библиотеки. Отличное по подробности пошаговое руководство есть здесь, я пользовался им. Перейдем сразу к тестам — попробуем запустить разные программы под Nano, и посмотрим как они работают. Для сравнения я использовал три компьютера — свой рабочий ноутбук (Core I7-6500U 2.5ГГц), Raspberry Pi 3B+ и Jetson Nano.
Тест CPU
Для начала, скриншот команды lscpu.
Raspberry Pi:
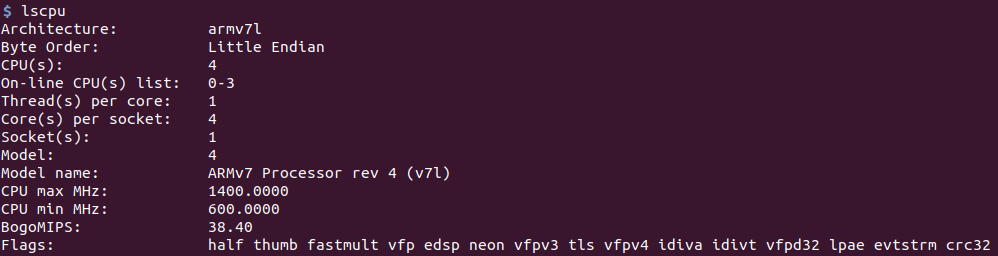
Jetson nano:
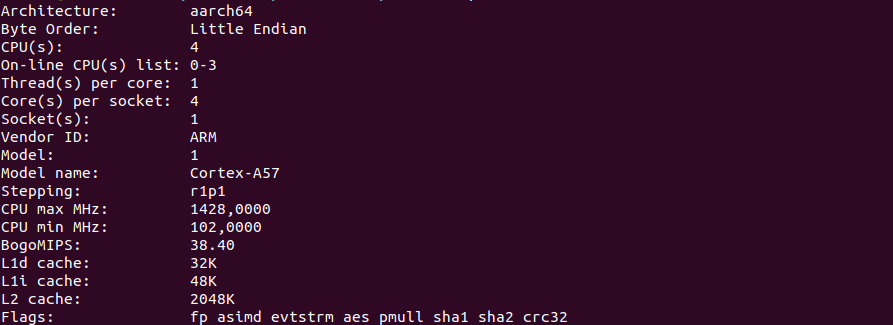
Для расчетов начнем с чего-нибудь простого, но требующего процессорного времени. Например, с вычисления числа Пи. Я взял несложную программу на Python со stackoverflow. Не знаю, является ли она оптимальной или нет, но нам это и не важно — нам интересно относительное время.
import time # Source: https://stackoverflow.com/questions/9004789/1000-digits-of-pi-in-python def make_pi(): q, r, t, k, m, x = 1, 0, 1, 1, 3, 3 for j in range(10000): if 4 * q + r - t < m * t: yield m q, r, t, k, m, x = 10*q, 10*(r-m*t), t, k, (10*(3*q+r))//t - 10*m, x else: q, r, t, k, m, x = q*k, (2*q+r)*x, t*x, k+1, (q*(7*k+2)+r*x)//(t*x), x+2 t1 = time.time() pi_array = [] for i in make_pi(): pi_array.append(str(i)) pi_array = pi_array[:1] + ['.'] + pi_array[1:] pi_array_str = "".join(pi_array) print("PI:", pi_array_str) print("dT:", time.time() - t1)
Как и ожидалось, программа работает не быстро. Результат для Jetson Nano: 0.8c.
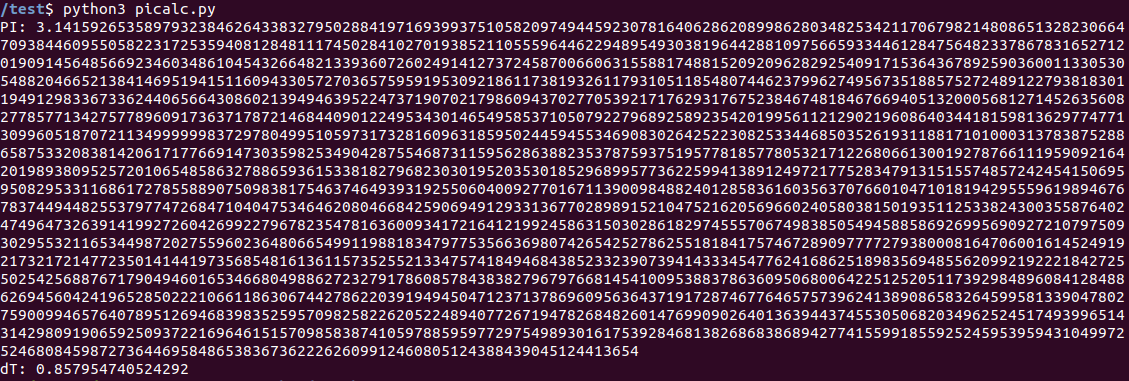
Raspberry Pi 3 показал заметно большее время: 3.06c. «Образцовый» ноутбук выполнил задачу за 0.27с. В общем, даже без использования GPU, основной процессор в Nano вполне неплох для своего форм-фактора. Желающие могут проверить на Raspberry Pi 4, у меня ее в наличии нет.
Наверняка найдутся желающие написать в комментариях, что Python не лучший выбор для таких расчетов, еще раз повторюсь, что нам важно было сравнить время, необходимости его минимизировать здесь нет. Понятно, что есть программы, вычисляющие число Пи гораздо быстрее.
PyCUDA
Перейдем к более интересному, расчетам с помощью GPU, для чего разумеется (плата ведь от NVIDIA), будем использовать CUDA. Библиотека PyCUDA потребовала некоторого шаманства при установке, она не находила cuda.h, помогло использование команды «sudo env „PATH=$PATH“ pip install pycuda», возможно есть другой способ (еще варианты обсуждались на форуме devtalk.nvidia.com).
Для теста я взял несложную программу SimpleSpeedTest для PyCUDA, которая просто в цикле считает синусы, ничего полезного такой тест не делает, но время оценить им вполне можно, и его код простой и понятный.
# SimpleSpeedTest.py # https://wiki.tiker.net/PyCuda/Examples/SimpleSpeedTest import pycuda.driver as drv import pycuda.autoinit from pycuda.compiler import SourceModule import numpy import time blocks = 64 block_size = 128 nbr_values = blocks * block_size n_iter = 100000 print("Calculating %d iterations" % (n_iter)) print() ##################### # SourceModule SECTION # create two timers so we can speed-test each approach start = drv.Event() end = drv.Event() mod = SourceModule("""__global__ void gpusin(float *dest, float *a, int n_iter) { const int i = blockDim.x*blockIdx.x + threadIdx.x; for(int n = 0; n < n_iter; n++) { a[i] = sin(a[i]); } dest[i] = a[i]; }""") gpusin = mod.get_function("gpusin") # create an array of 1s a = numpy.ones(nbr_values).astype(numpy.float32) # create a destination array that will receive the result dest = numpy.zeros_like(a) start.record() # start timing gpusin(drv.Out(dest), drv.In(a), numpy.int32(n_iter), grid=(blocks,1), block=(block_size,1,1) ) end.record() # end timing # calculate the run length end.synchronize() secs = start.time_till(end)*1e-3 print("PyCUDA time and first three results:") print("%fs, %s" % (secs, str(dest[:3]))) print() ############# # CPU SECTION # use numpy the calculate the result on the CPU for reference a = numpy.ones(nbr_values).astype(numpy.float32) t1 = time.time() for i in range(n_iter): a = numpy.sin(a) print("CPU time and first three results:") print("%fs, %s" % (time.time() - t1, str(a[:3])))
Как можно видеть, вычисление делается с помощью GPU через CUDA и с помощью CPU, через numpy.
Результаты:
Jetson nano — 0.67c GPU, 13.3c CPU.
Raspberry Pi — 41.85c CPU, GPU — данных нет, CUDA на RPi не работает.
Ноутбук — 0.05с GPU, 3.08c CPU.
Все вполне ожидаемо. Расчеты на GPU гораздо быстрее расчетов на CPU (все же 128 ядер), Raspberry Pi отстает весьма значительно. Ну и разумеется, сколько волка не корми, у слона все равно больше ноутбучная видеокарта гораздо быстрее карты в Jetson Nano — вполне вероятно, что вычислительных ядер в ней гораздо больше.
Заключение
Как можно видеть, плата у NVIDIA получилась вполне интересной и весьма производительной. Она немного больше по размеру и дороже, чем Raspberry Pi, но если кому-то нужна большая вычислительная мощность при компактном размере, то оно вполне стоит того.
В одну часть все задуманное не уместилось. Во второй части будут тесты AI-части — тесты Keras/Tensorflow и задач по классификации и распознаванию изображений.
ссылка на оригинал статьи https://habr.com/ru/post/460723/
Добавить комментарий