Введение
В этой статье мы, как вы уже догадались, поговорим про Screen Capture API. Этот API появился на свет в 2014 году и новым его назвать сложно, однако поддержка браузерами все еще достаточно слабая. Тем не менее, его вполне можно использовать для персональных проектов или там где эта поддержка не так важна.
Немного ссылок для начала:
На случай если ссылка с демо отвалится (или если вам лень туда перейти) — вот так выглядит готовое демо:
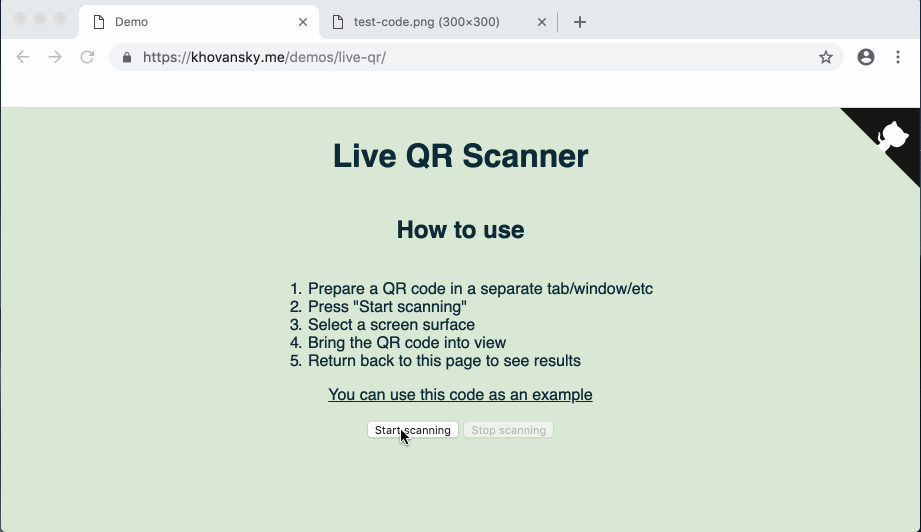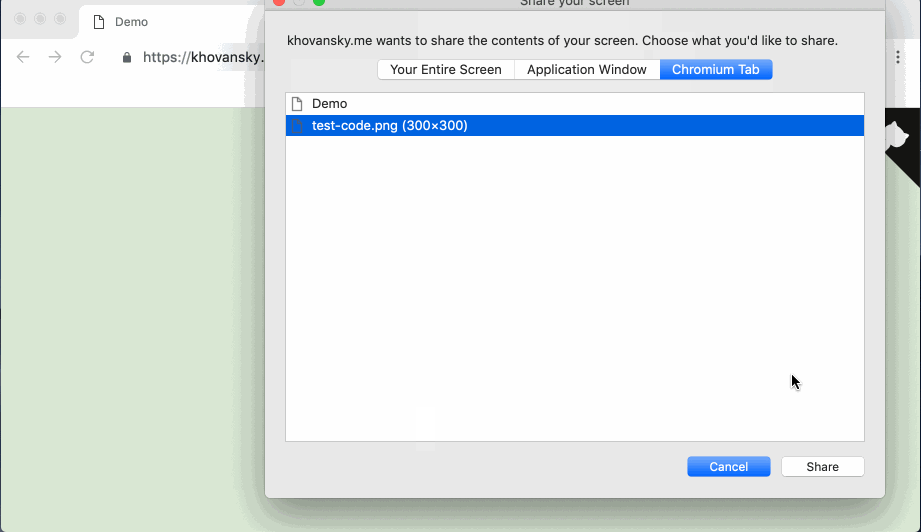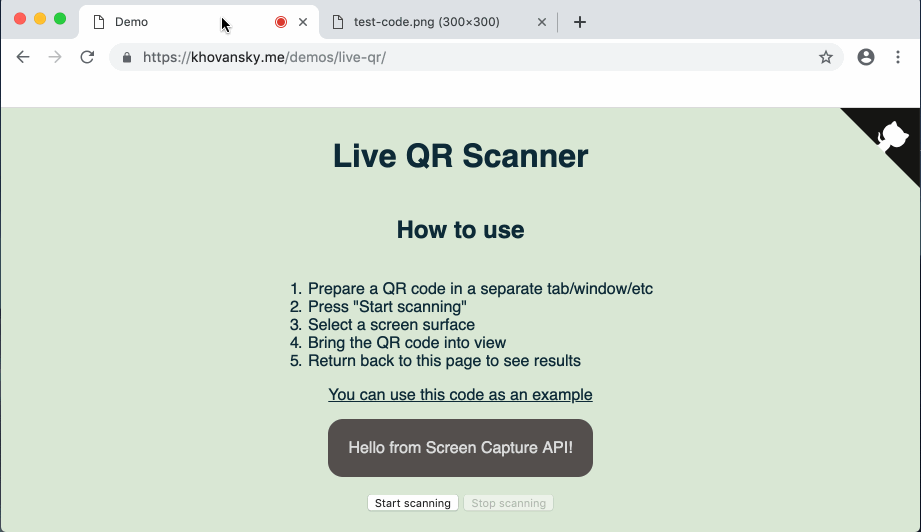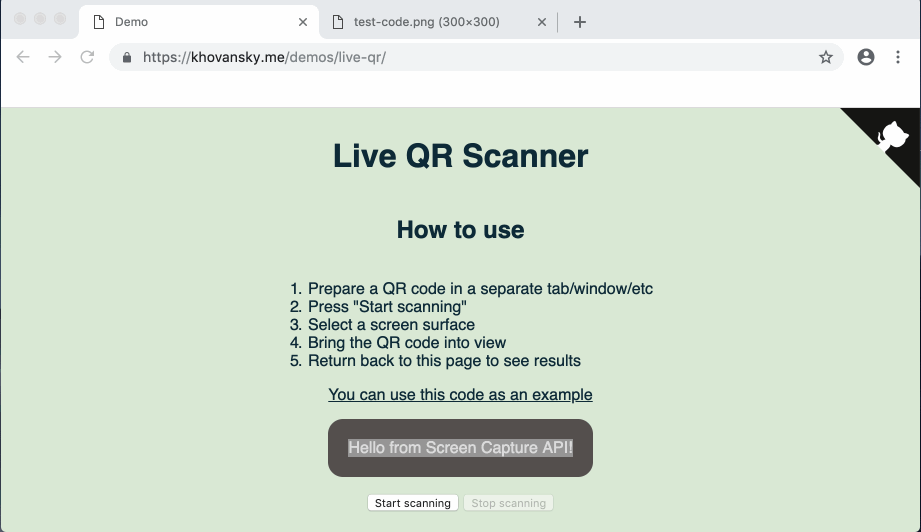
Приступим.
Мотивация
Недавно у меня возникла идея веб-приложения, которое использует в своей работе QR-коды. И хотя они обычно удобны для передачи сложных данных или длинных ссылок в реальном мире, где на них можно направить телефон, на десктопе все несколько сложнее. Если QR код находится на экране того же устройства, на котором его нужно прочитать — нужно возиться с сервисами для распознавания, или распознать с телефона и переправить данные обратно на ПК. Неудобно.
Некоторые продукты, такие как, например, 1Password — включают в себя интересное решение для этой ситуации. При необходимости настроить аккаунт из QR-кода они открывают полупрозрачное окно, которое можно перетащить поверх изображения с кодом и он автоматически распознается. Вот как это выглядит:
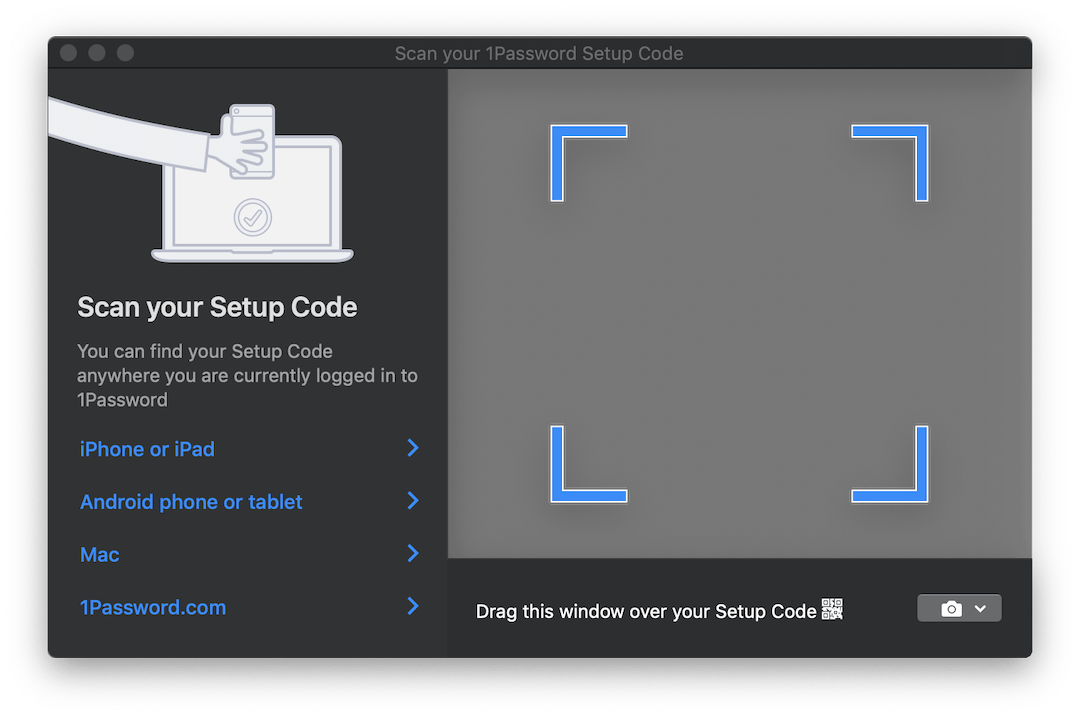
Было бы идеально, если бы мы могли реализовать что-то подобное для нашего приложения. Но, наверное, в браузере так не выйдет…
Встречайте — getDisplayMedia
Ну почти. Здесь нам и поможет Screen Capture API с его единственным методом getDisplayMedia. getDisplayMedia — это как getUserMedia, только для экрана устройства, вместо его камеры. К сожалению, поддержка браузерами, как уже было сказано выше, далеко не такая распространенная как у доступа к камере. Согласно MDN использовать его можно в Firefox, Chrome, Edge (правда там оно находится в неправильном месте — сразу в navigator, а не в navigator.mediaDevices) + Edge Mobile и… Opera for Android.
Довольно любопытная подборка мобильных браузеров рядом с ожидаемой большой двойкой.
Само по себе API крайне простое. Оно работает также как и getUserMedia, но позволяет захватывать видеопоток с одной из определенных display surface:
- c монитора (экран целиком)
- с окна или всех окон определенного приложения
- с браузера, или точнее с конкретного документа. В Chrome этим документом является отдельная вкладка, а в FF такая опция отсутствует.
Браузерное API, которое позволяет заглянуть за пределы браузера… Звучит знакомо и обычно сулит одни неприятности, но в данном случае может быть достаточно удобно. Можно захватывать картинку из других окон и, например, в реальном времени распознавать и переводить текст, как Google Translate Camera. Ну и, наверное, есть еще много интересных применений.
Собираем
Итак, с возможностями, которые нам дает API, разобрались. Что дальше?
А дальше нам нужно перегнать этот видеопоток в изображения, над которыми можно работать. Для этого мы используем элементы <video>, <canvas> и еще немного JS.
Крупным планом процесс выглядит примерно так:
- Направить поток в
<video> - С определенной частотой рисовать содержимое
<video>в<canvas> - Забирать объект
ImageDataиз<canvas>используя метод 2D контекстаgetImageData
Вся эта процедура может звучать немного странно из-за такого длинного пайплайна, но этот способ достаточно популярен и использовался еще для захвата данных с веб-камер в getUserMedia.
Опуская все не относящееся к делу, чтобы запустить поток и вытащить из него фрейм нам понадобится примерно следующий код:
async function run() { const video = document.createElement('video'); const canvas = document.createElement('canvas'); const context = canvas.getContext('2d'); const displayMediaOptions = { video: { cursor: "never" }, audio: false } video.srcObject = await navigator.mediaDevices.getDisplayMedia(displayMediaOptions); const videoTrack = video.srcObject.getVideoTracks()[0]; const { height, width } = videoTrack.getSettings(); context.drawImage(video, 0, 0, width, height); return context.getImageData(0, 0, width, height); } await run();
Как и говорилось выше — сначала мы создаем элементы <video> и <canvas>, и просим у канваса 2D контекст (CanvasRenderingContext2D).
Затем мы определяем ограничения/условия потока. В отличие от потоков с камеры, тут их немного. Мы говорим, что не хотим видеть курсор, и что нам не нужно аудио. Хотя на момент написания этой статьи захват аудио все равно никем не поддерживается.
После этого мы цепляем полученный поток типа MediaStream к элементу <video>. Обратите внимание, что getDisplayMedia возвращает Promise.
Наконец, из полученных данных о потоке мы запоминаем разрешение видео, чтобы правильно отрисовать его на канвас, отрисовываем фрейм и вытаскиваем из канваса объект ImageData.
Для полноценного использования вам, скорее всего, захочется обрабатывать кадры в цикле, нежели один раз. Например, пока вы ждете что необходимое изображение появится в кадре. И здесь нужно сказать пару слов.
Когда речь заходит об «обработке чего-то в DOM в постоянном цикле» первое что приходит на ум — это, скорее всего, requestAnimationFrame. Однако в нашем случае использовать его не выйдет. Все дело в том, что когда вкладка перестает быть активной — браузеры ставят обработку циклов rAF на паузу. В нашем случае, зачастую именно в это время мы будем хотеть обрабатывать изображения.
В связи с этим вместо rAF мы будем использовать старый добрый setInterval. Но и с ним не так все гладко. В неактивной вкладке интервал между срабатываниями коллбэка составляет минимум 1 секунду. Тем не менее, нам этого достаточно.
Наконец, добравшись до кадров мы можем обрабатывать их как нам заблагорассудится. Для целей этого демо мы будем использовать библиотеку jsQR. Она крайне проста: на вход принимает ImageData, ширину и высоту изображения. Если в полученном изображении есть QR-код — назад вы получите JS-объект с распознанными данными.
Давайте дополним наш предыдущий пример еще буквально парой строк кода:
const imageData = await run(); const code = jsQR(imageData.data, streamWidth, streamHeight);
Готово!
NPM
Я подумал, что основной код за этим примером можно упаковать в npm-библиотеку и сэкономить в последующем использовании немного времени на первоначальную настройку. Библиотека очень проста, на данном этапе она всего лишь принимает коллбэк, на который будет отправляться ImageData и один дополнительный параметр — частоту отправки данных. Весь процессинг нужно приносить свой. Я подумаю, есть ли смысл расширять ее функционал.
Библиотека называется stream-display: NPM | Github.
Ее использование сводится буквально к трем строчкам кода и коллбэку:
const callback = imageData => {...} // do whatever with those images const capture = new StreamDisplay(callback); // specify where the ImageData will go await capture.startCapture(); // when ready capture.stopCapture(); // when done
Демо можно посмотреть здесь. Также есть CodePen версия для быстрых экспериментов. Оба примера используют упомянутый выше NPM-пакет.
Немного о тестировании
Упаковывая этот код в библиотеку мне пришлось задуматься о том, как же ее тестировать. Совершенно не хотелось тянуть 50МБ безголового Chrome чтобы запускать в нем несколько маленьких тестов. И хотя идея писать заглушки для всех составных частей казалась слишком мучительной, в итоге я так и поступил.
В качестве тест-раннера был выбран tape. Вот что в итоге пришлось имитировать:
- объект
documentи DOM-элементы. Для этого я взял jsdom - некоторые методы jsdom, у которых отсутствует имплементация —
HTMLMediaElement#play,HTMLCanvasElement#getContextandnavigator.mediaDevices#getDisplayMedia - Время. Для этого я воспользовался
useFakeTimersбиблиотеки sinon, которая под капотом зоветlolex. Она устанавливает свои заменыsetInterval,requestAnimationFrameи многим другим функциям, работающим со временем, а также позволяет управлять течением этого фальшивого времени. Но будьте осторожны: jsdom в одном месте своего процесса инициализации использует течение времени и если сначала включить sinon — все зависнет.
Также я использовал sinon для всех заглушек функций, за вызовами которых нужно было следить. Остальное было реализовано пустыми JS-функциями.
Разумеется, вы вольны выбирать тот инструментарий, с которым уже знакомы. Но, надеюсь, этот список позволит его заранее подготовить, так как теперь вы знаете с чем придется иметь дело.
Конечный результат можно увидеть в репозитории библиотеки. Выглядит не слишком красиво, но работает.
Заключение
Решение получилось не столь элегантным, как упомянутое в начале статьи прозрачное окно, но, возможно, однажды веб дойдет и до этого. Остается только надеяться, что когда браузеры научатся видеть сквозь свои окна — эти возможности будут строго подконтрольны нам. А пока что помните, что когда вы шарите экран в Chrome — его могут парсить, записывать, и т.д. Так что не шарьте больше, чем нужно!
Надеюсь, кто-то после этой статьи выучил для себя новый трюк. Если у вас есть идеи, для чего еще это может быть использовано — пишите в комментариях. И до новых встреч.
ссылка на оригинал статьи https://habr.com/ru/post/460825/
Добавить комментарий