
Почти 9 лет назад Cloudflare была крошечной компанией, а я не работал в ней, был просто клиентом. Через месяц после запуска Cloudflare я получил оповещение о том, что на моем сайтике jgc.org, похоже, не работает DNS. В Cloudflare внесли изменение в Protocol Buffers, а там был поломанный DNS.
Я сразу написал Мэтью Принсу (Matthew Prince), озаглавив письмо «Где мой DNS?», а он прислал длинный ответ, полный технических подробностей (всю переписку читайте здесь), на что я ответил:
От: Джон Грэхэм-Камминг
Дата: 7 октября 2010 года, 9:14
Тема: Re: Где мой DNS?
Кому: Мэтью ПринсКлассный отчет, спасибо. Я обязательно позвоню, если будут проблемы. Наверное, стоит написать об этом пост, когда соберете всю техническую инфу. Думаю, людям понравится открытый и честный рассказ. Особенно если приложить к нему графики, чтобы показать, как вырос трафик после запуска.
У меня на сайте хороший мониторинг, и мне приходит SMS о каждом сбое. Мониторинг показывает, что сбой был с 13:03:07 до 14:04:12. Тесты проводятся каждые пять минут.
Уверен, вы со всем разберетесь. Вам точно не нужен свой человек в Европе? 🙂
А он ответил:
От: Мэтью Принс
Дата: 7 октября 2010 года, 9:57
Тема: Re: Где мой DNS?
Кому: Джон Грэхэм-КаммингСпасибо. Мы ответили всем, кто написал. Я сейчас еду в офис, и мы напишем что-нибудь в блоге или закрепим официальный пост на нашей доске объявлений. Полностью согласен, честность — наше все.
Сейчас Cloudflare — реально большая компания, я работаю в ней, и теперь мне приходится открыто писать о нашей ошибке, ее последствиях и наших действиях.
События 2 июля
2 июля мы развернули новое правило в управляемых правилах для WAF, из-за которых процессорные ресурсы заканчивались на каждом ядре процессора, обрабатывающем трафик HTTP/HTTPS в сети Cloudflare по всему миру. Мы постоянно улучшаем управляемые правила для WAF в ответ на новые уязвимости и угрозы. В мае, например, мы поспешили добавить правило, чтобы защититься от серьезной уязвимости в SharePoint. Вся суть нашего WAF — в возможности быстрого и глобального развертывания правил.
К сожалению, обновление прошлого четверга содержало регулярное выражение, которое тратило на бэктрекинг слишком много процессорных ресурсов, выделенных для HTTP/HTTPS. От этого пострадали наши основные функции прокси, CDN и WAF. На графике видно, что процессорные ресурсы для обслуживания трафика HTTP/HTTPS доходят почти до 100% на серверах в нашей сети.
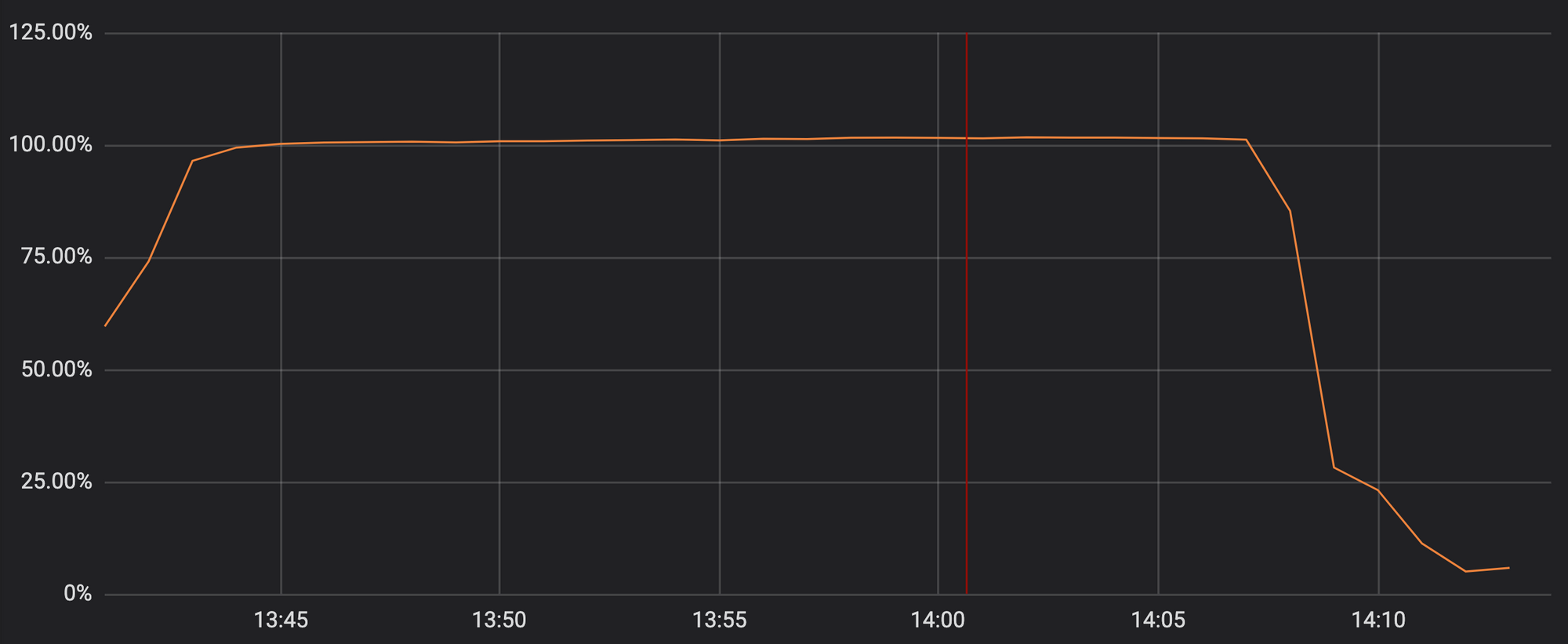
Использование процессорных ресурсов в одной из точек присутствия во время инцидента
В итоге наши клиенты (и клиенты наших клиентов) упирались в страницу с ошибкой 502 в доменах Cloudflare. Ошибки 502 генерировались фронтальными веб-серверами Cloudflare, у которых еще были свободные ядра, но они не могли связаться с процессами, обрабатывающими трафик HTTP/HTTPS.
Мы знаем, сколько неудобств это доставило нашим клиентам. Нам ужасно стыдно. И этот сбой мешал нам эффективно разобраться с инцидентом.
Если вы были одним из таких клиентов, вас это, наверное, напугало, рассердило и расстроило. Более того, у нас уже 6 лет не было глобальных сбоев. Высокий расход процессорных ресурсов произошел из-за одного правила WAF с плохо сформулированным регулярным выражением, которое привело к чрезмерному бэктрекингу. Вот виновное выражение: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Хотя оно само по себе интересное (и ниже я расскажу о нем подробнее), сервис Cloudflare отрубился на 27 минут не только из-за негодного регулярного выражения. Нам понадобилось время, чтобы описать последовательность событий, которые привели к сбою, поэтому ответили мы небыстро. В конце поста я опишу бэктрекинг в регулярном выражении и расскажу, что с этим делать.
Что случилось
Начнем по порядку. Все время здесь указано в UTC.
В 13:42 инженер из команды, занимающейся межсетевыми экранами, внес небольшие изменение в правила для обнаружения XSS с помощью автоматического процесса. Соответственно, был создан тикет запроса на изменение. Такими тикетами мы управляем через Jira (скриншот ниже).
Через 3 минуты появилась первая страница PagerDuty, сообщавшая о проблеме с WAF. Это был синтетический тест, который проверяет функциональность WAF (у нас таких сотни) за пределами Cloudflare, чтобы контролировать нормальную работу. Затем сразу последовали страницы с оповещениями о сбоях других сквозных тестов сервисов Cloudflare, глобальных проблемах с трафиком, повсеместных ошибках 502, и куча отчетов из наших точек присутствия (PoP) в городах по всему миру, которые указывали на нехватку процессорных ресурсов.


Я получил несколько таких оповещений, сорвался со встречи и уже шел к столу, когда руководитель нашего отдела разработки решений сказал, что мы потеряли 80% трафика. Я побежал к нашим SRE-инженерам, который уже работали над проблемой. Сначала мы подумали, что это какая-то неизвестная атака.

SRE-инженеры Cloudflare разбросаны по всему миру и контролируют ситуацию круглосуточно. Обычно такие оповещения уведомляют о конкретных локальных проблемах ограниченного масштаба, отслеживаются на внутренних панелях мониторинга и решаются много раз за день. Но такие страницы и уведомления указывали на что-то реально серьезное, и SRE-инженеры сразу объявили уровень серьезности P0 и обратились к руководству и системным инженерам.
Наши лондонские инженеры в этот момент слушали лекцию в главном зале. Лекцию пришлось прервать, все собрались в большом конференц-зале, позвали еще специалистов. Это не была обычная проблема, с которой SRE могли разобраться сами. Нужно было срочно подключать правильных спецов.
В 14:00 мы определили, что проблема с WAF и никакой атаки нет. Отдел производительности извлек данные о процессорах, и стало очевидно, что виноват WAF. Другой сотрудник подтвердил эту теорию с помощью strace. Еще кто-то увидел в логах, что с WAF беда. В 14:02 вся команда явилась ко мне, когда было предложено использовать global kill — механизм, встроенный в Cloudflare, который отключает один компонент по всему миру.
Как мы сделали global kill для WAF — это отдельная история. Все не так просто. Мы используем собственные продукты, а раз наш сервис Access не работал, мы не могли пройти аутентификацию и войти в панель внутреннего контроля (когда все починилось, мы узнали, что некоторые члены команды потеряли доступ из-за функции безопасности, которая отключает учетные данные, если долго не использовать панель внутреннего контроля).
И мы не могли добраться до своих внутренних сервисов, вроде Jira или системы сборки. Нужен был обходной механизм, который мы использовали нечасто (это тоже нужно будет отработать). Наконец, одному инженеру удалось отрубить WAF в 14:07, а в 14:09 уровень трафика и процессора везде вернулся в норму. Остальные защитные механизмы Cloudflare работали в штатном режиме.
Затем мы занялись восстановлением работы WAF. Ситуация была из ряда вон, поэтому мы выполнили негативные тесты (спросив себя, действительно ли проблема в этом изменении) и позитивные (убедившись, что откат сработал) в одном городе с помощью отдельного трафика, перенеся оттуда платных клиентов.
В 14:52 мы убедились, что поняли причину и внесли исправление, и снова включили WAF.
Как работает Cloudflare
В Cloudflare есть команда инженеров, которые занимаются управляемыми правилами для WAF. Они стараются повысить процент обнаружения, сократить количество ложноположительных результатов и быстро реагировать на новые угрозы по мере их появления. За последние 60 дней было обработано 476 запросов на изменения для управляемых правил для WAF (в среднем, по одному каждые 3 часа).
Это конкретное изменение нужно было развернуть в режиме симуляции, где реальный трафик клиента проходит через правило, но ничего не блокируется. Мы используем этот режим для проверки эффективности правил и измерения доли ложноположительных и ложноотрицательных результатов. Но даже в режиме симуляции правила должны фактически выполняться, а в этом случае правило содержало регулярное выражение, потреблявшее слишком много процессорных ресурсов.
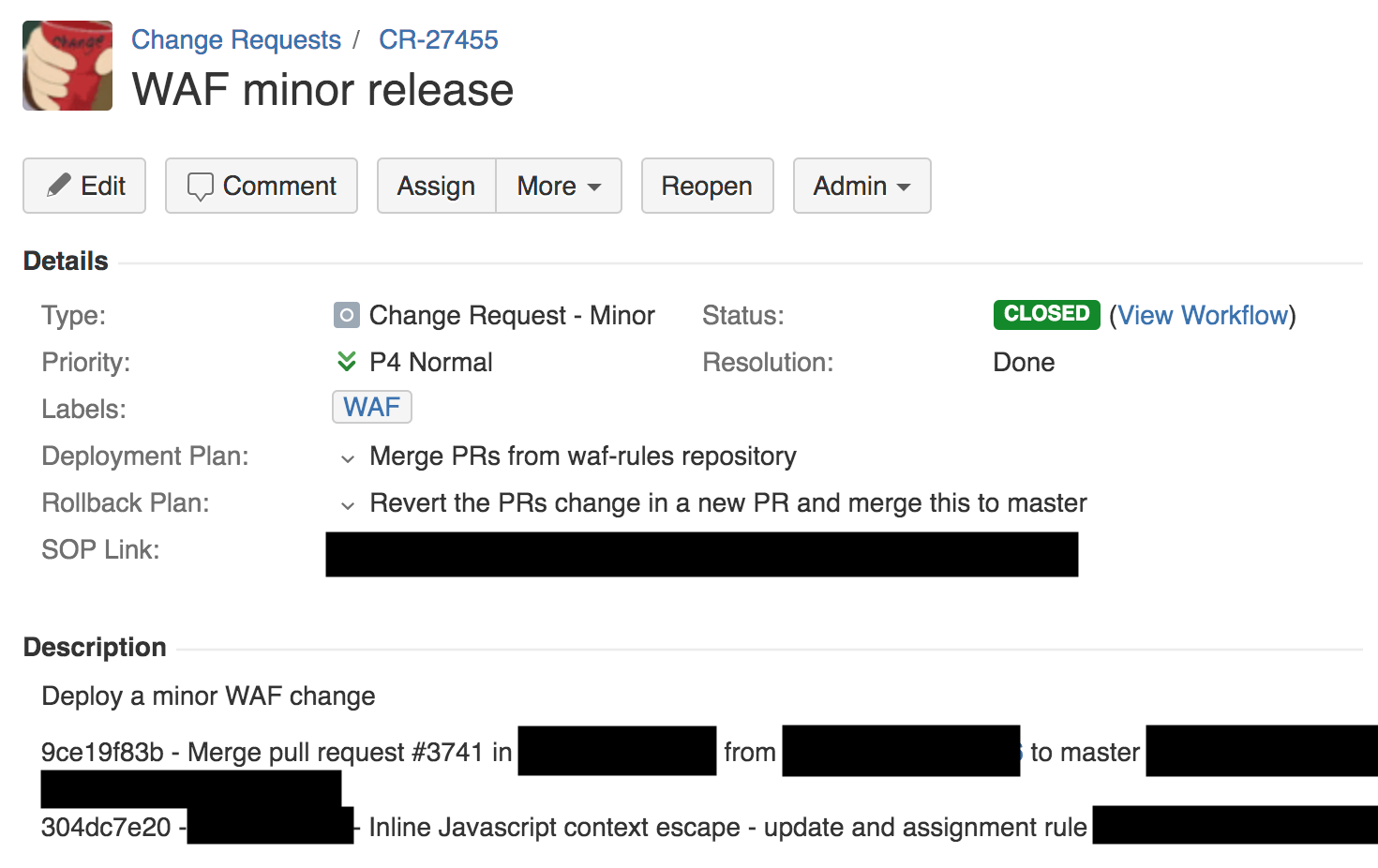
Как видно из запроса на изменение выше, у нас есть план развертывания, план отката и ссылка на внутреннюю стандартную рабочую процедуру (SOP) для этого типа развертывания. SOP для изменения правила разрешает публиковать его глобально. Вообще-то в Cloudflare все устроено совсем иначе, и SOP предписывает сначала отправить ПО на тестирование и внутреннее использование во внутреннюю точку присутствия (PoP) (которую используют наши сотрудники), потом небольшому количеству клиентов в изолированном месте, потом большому числу клиентов и только потом всему миру.
Вот как это выглядит. Мы используем git во внутренней системе через BitBucket. Инженеры, работающие над изменениями, отправляют код, который собирается в TeamCity, и когда сборка проходит, назначаются ревьюеры. Когда пул-реквест одобряется, код собирается и проводится ряд тестов (еще раз).
Если сборка и тесты завершаются успешно, создается запрос на изменение в Jira, и изменение должен одобрить соответствующий руководитель или ведущий специалист. После одобрения происходит развертывание в так называемый «PoP-зверинец»: DOG, PIG и Canary (собака, свинка и канарейка).
DOG PoP — это Cloudflare PoP (как любой другой из наших городов), который используют только сотрудники Cloudflare. PoP для внутреннего использования позволяет выловить проблемы еще до того, как в решение начнет поступать трафик клиентов. Полезная штука.
Если DOG-тест проходит успешно, код переходит на стадию PIG (подопытная свинка). Это Cloudflare PoP, где небольшой объем трафика бесплатных клиентов проходит через новый код.
Если все хорошо, код переходит в Canary. У нас три Canary PoP в разных точках мира. В них через новый код проходит трафик платных и бесплатных клиентов, и это последняя проверка на ошибки.

Процесс релиза ПО в Cloudflare
Если с кодом все нормально в Canary, мы его выпускаем. Прохождение через все стадии — DOG, PIG, Canary, весь мир — занимает несколько часов или дней, в зависимости от изменения кода. Благодаря многообразию сети и клиентов Cloudflare мы тщательно тестируем код перед глобальным релизом для всех клиентов. Но WAF специально не следует этому процессу, потому что на угрозы нужно реагировать быстро.
Угрозы WAF
В последние несколько лет в обычных приложениях угроз стало значительно больше. Это связано с большей доступностью инструментов тестирования ПО. Например, недавно мы писали про фаззинг).
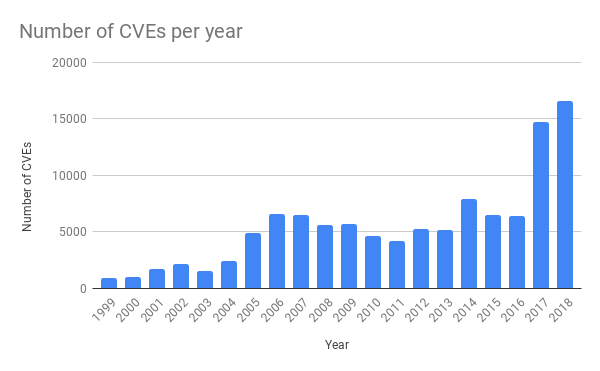
Источник: https://cvedetails.com/
Очень часто подтверждение концепции создается и тут же публикуется на Github, чтобы команды, которые обслуживают приложение, могли быстро протестировать его и убедиться, что оно адекватно защищено. Поэтому Cloudflare нужна возможность как можно быстрее реагировать на новые атаки, чтобы у клиентов была возможность исправить свое ПО.
Отличный пример быстрой реакции от Cloudflare — развертывание средств защиты от уязвимости SharePoint в мае (читайте здесь). Почти сразу после публикации объявлений мы заметили огромное количество попыток использовать уязвимость в установках SharePoint наших клиентов. Наши ребята постоянно отслеживают новые угрозы и пишут правила, чтобы защитить наших клиентов.
Правило, из-за которого в четверг возникла проблема, должно было защищать от межсайтового скриптинга (XSS). Таких атак тоже стало куда больше за последние годы.
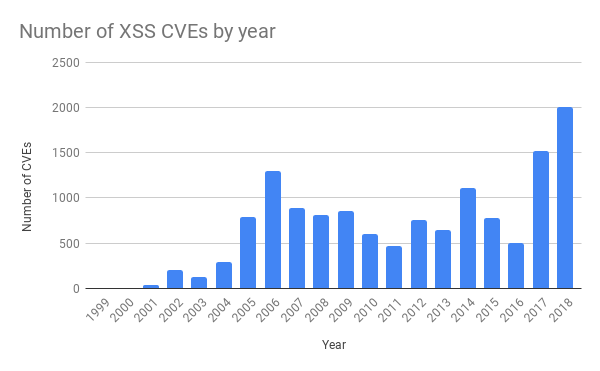
Источник: https://cvedetails.com/
Стандартная процедура для изменения управляемого правила для WAF предписывает проводить тестирование непрерывной интеграции (CI) до глобального развертывания. В прошлый четверг мы это сделали и развернули правила. В 13:31 один инженер отправил одобренный пул-реквест с изменением.
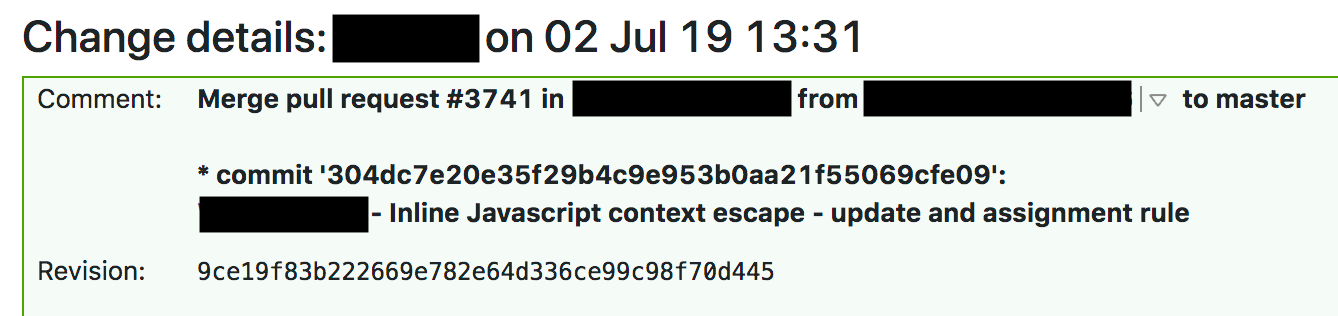
В 13:37 TeamCity собрал правила, прогнал тесты и дал добро. Набор тестов для WAF проверяет основной функционал WAF и состоит из большого количества модульных тестов для индивидуальных функций. После модульных тестов мы проверили правила для WAF с помощью огромного числа HTTP-запросов. HTTP-запросы проверяют, какие запросы должны блокироваться WAF (чтобы перехватить атаку), а какие можно пропускать (чтобы не блокировать все подряд и избежать ложноположительных результатов). Но мы не провели тесты на чрезмерное использование процессорных ресурсов, и изучение логов предыдущих сборок WAF показывает, что время выполнения тестов с правилом не увеличилось, и сложно было заподозрить, что ресурсов не хватит.
Тесты были пройдены, и TeamCity начал автоматически развертывать изменение в 13:42.
Quicksilver
Правила WAF направлены на срочное устранение угроз, поэтому мы развертываем их с помощью распределенного хранилища пар «ключ-значение» Quicksilver, которое распространяет изменения глобально за считанные секунды. Все наши клиенты используют эту технологию, когда меняют конфигурацию на панели мониторинга или через API, и именно благодаря ей мы молниеносно реагируем на изменения.
Мы мало говорили о Quicksilver. Раньше мы использовали Kyoto Tycoon как глобально распределенное хранилище пар «ключ-значение», но с ним возникли операционные проблемы, и мы написали свое хранилище, реплицированное более чем в 180 городах. Теперь с помощью Quicksilver мы отправляем изменения в конфигурацию клиентов, обновляем правила WAF и распространяем код JavaScript, написанный клиентами в Cloudflare Workers.
От нажатия кнопки на панели мониторинга или вызова API до внесения изменения в конфигурацию по всему миру проходит всего несколько секунд. Клиентам полюбилась эта скорость настройки. А Workers обеспечивает им почти моментальное глобальное развертывание ПО. В среднем Quicksilver распространяет около 350 изменений в секунду.
И Quicksilver работает очень быстро. В среднем мы достигли 99-го процентиля 2,29 с для распространения изменений на каждый компьютер по всему миру. Обычно скорость — это хорошо. Ведь когда вы включаете функцию или чистите кэш, это происходит почти мгновенно и повсюду. Отправка кода через Cloudflare Workers происходит с той же скоростью. Cloudflare обещает своим клиентам быстрые апдейты в нужный момент.
Но в этом случае скорость сыграла с нами злую шутку, и правила изменились повсеместно за считанные секунды. Вы, наверное, заметили, что код WAF использует Lua. Cloudflare широко использует Lua в рабочей среде и подробности Lua в WAF мы уже обсуждали. Lua WAF использует PCRE внутри и применяет бэктрекинг для сопоставления. У него нет механизмов защиты от выражений, вышедших из-под контроля. Ниже я подробнее расскажу об этом и о том, что мы с этим делаем.

До развертывания правил все шло гладко: пул-реквест был создан и одобрен, пайплайн CI/CD собрал и протестировал код, запрос на изменение был отправлен в соответствии с SOP, которая регулирует развертывание и откат, и развертывание было выполнено.

Процесс развертывания WAF в Cloudflare
Что пошло не так
Как я уже говорил, мы каждую неделю развертываем десятки новых правил WAF, и у нас есть множество систем защиты от негативных последствий такого развертывания. И когда что-то идет не так, обычно это стечение сразу нескольких обстоятельств. Если найти всего одну причину, это, конечно успокаивает, но не всегда соответствует действительности. Вот причины, которые вместе привели к сбою нашего сервиса HTTP/HTTPS.
- Инженер написал регулярное выражение, которое может привести к чрезмерному бэктрекингу.
- Средство, которое могло бы предотвратить чрезмерный расход процессорных ресурсов, используемых регулярным выражением, было по ошибке удалено при рефакторинге WAF за несколько недель до этого — рефакторинг был нужен, чтобы WAF потреблял меньше ресурсов.
- Движок регулярных выражений не имел гарантий сложности.
- Набор тестов не мог выявить чрезмерное потребление процессорных ресурсов.
- Процедура SOP разрешает глобальное развертывание несрочных изменений правил без многоэтапного процесса.
- План отката требовал выполнение полной сборки WAF дважды, а это долго.
- Первое оповещение о глобальных проблемах с трафиком сработало слишком поздно.
- Мы промедлили с обновлением страницы статуса.
- У нас были проблемы с доступом к системам из-за сбоя, а процедура обхода была недостаточно хорошо отработана.
- SRE-инженеры потеряли доступ к некоторым системам, потому что срок действия их учетных данных истек по соображениям безопасности.
- У наших клиентов не было доступа к панели мониторинга Cloudflare или API, потому что они проходят через регион Cloudflare.
Что изменилось с прошлого четверга
Сначала мы полностью остановили все работы над релизами для WAF и делаем следующее:
- Повторно вводим защиту от чрезмерного потребления процессорных ресурсов, которую мы удалили. (Готово)
- Вручную проверяем все 3868 правил в управляемых правилах для WAF, чтобы найти и исправить другие потенциальные случаи чрезмерного бэктрекинга. (Проверка завершена)
- Включаем в набор тестов профилирование производительности для всех правил. (Ожидается: 19 июля)
- Переходим на движок регулярных выражений re2 или Rust — оба предоставляют гарантии в среде выполнения. (Ожидается: 31 июля)
- Переписываем SOP, чтобы развертывать правила поэтапно, как и другое ПО в Cloudflare, но при этом иметь возможность экстренного глобального развертывания, если атаки уже начались.
- Разрабатываем возможность срочного вывода панели мониторинга Cloudflare и API из региона Cloudflare.
- Автоматизируем обновление страницы Cloudflare Status.
В долгосрочной перспективе мы отказываемся от Lua WAF, который я написал несколько лет назад. Переносим WAF в новую систему межсетевых экранов. Так WAF будет быстрее и получит дополнительный уровень защиты.
Заключение
Этот сбой доставил неприятности нам и нашим клиентам. Мы быстро отреагировали, чтобы исправить ситуацию, и сейчас работаем над изъянами процессов, из-за которых произошел сбой, а также копаем еще глубже, чтобы защититься от потенциальных проблем с регулярными выражениями в будущем, переходя на новую технологию.
Нам очень стыдно за этот сбой, и мы приносим извинения нашим клиентам. Надеемся, эти изменения гарантируют, что подобное больше не повторится.
Приложение. Бэктрекинг регулярных выражений
Чтобы понять, как выражение:
(?:(?:\"|'|\]|\}|\\|\d (?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\- |\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
съело все процессорные ресурсы, нужно немного знать о том, как работает стандартный движок регулярных выражений. Проблема тут в паттерне .*(?:.*=.*). (?: и соответствующая ) — это не захватывающая группа (то есть выражение в скобках группируется как одно выражение).
В контексте чрезмерного потребления процессорных ресурсов можно обозначить этот паттерн как .*.*=.*. В таком виде паттерн выглядит излишне сложным. Но что важнее, в реальном мире такие выражения (подобные сложным выражениям в правилах WAF), которые просят движок сопоставить фрагмент, за которым следует другой фрагмент, могут привести к катастрофическому бэктрекингу. И вот почему.
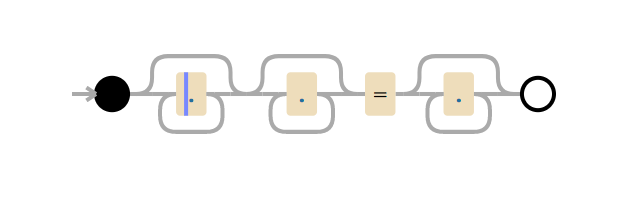
В регулярном выражении . означает, что нужно сопоставить один символ, .* — сопоставить ноль или более символов «жадно», то есть захватив максимум символов, так что .*.*=.* означает сопоставить ноль или более символов, потом сопоставить ноль или более символов, найти литеральный символ =, сопоставить ноль или более символов.
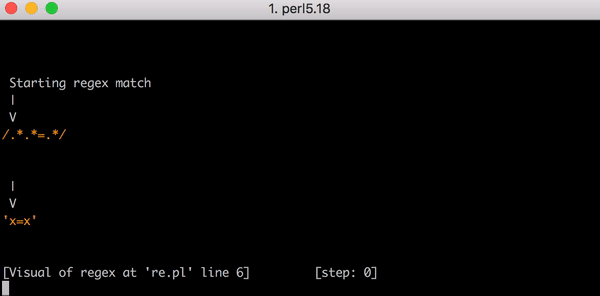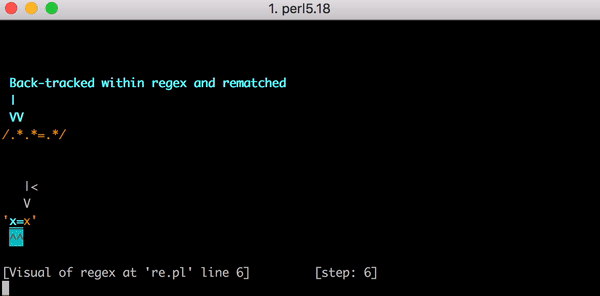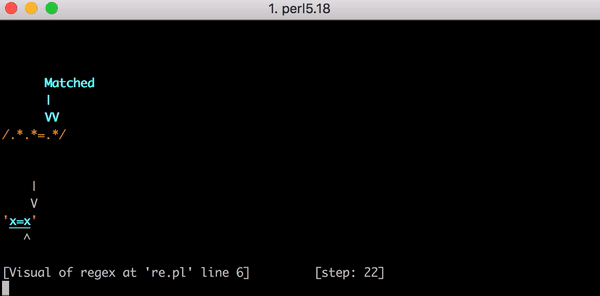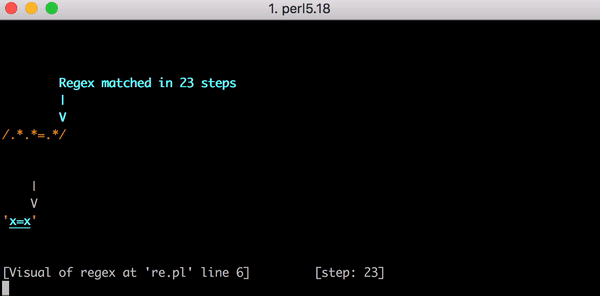
Возьмем тестовую строку x=x. Она соответствует выражению .*.*=.*. .*.* до знака равенства соответствует первому x (одна из групп .* соответствует x, а вторая — нулю символов). .* после = соответствует последнему x.
Для такого сопоставления нужно 23 шага. Первая группа .* в .*.*=.* действует «жадно» и сопоставляется всей строке x=x. Движок переходит к следующей группе .*. У нас больше нет символов для сопоставления, поэтому вторая группа .* соответствует нулю символов (это допускается). Потом движок переходит к знаку =. Символов больше нет (первая группа .* использовала все выражение x=x), сопоставление не происходит.
И тут движок регулярных выражений возвращается к началу. Он переходит к первой группе .* и сопоставляет ее с x= (вместо x=x), а затем берется за вторую группу .*. Вторая группа .* сопоставляется со вторым x, и у нас снова не осталось символов. И когда движок опять доходит до = в .*.*=.*, ничего не получается. И он снова делает бэктрекинг.
На этот раз группа .* все еще соответствует x=, но вторая группа .* больше не x, а ноль символов. Движок пытается найти литеральный символ = в паттерне .*.*=.*, но не выходит (ведь его уже заняла первая группа .*). И он снова делает бэктрекинг.
На этот раз первая группа .* берет только первый x. Но вторая группа .* «жадно» захватывает =x. Уже догадались, что будет? Движок пытается сопоставить литеральное =, терпит неудачу и делает очередной бэктрекинг.
Первая группа .* все еще соответствует первому x. Вторая .* занимает только =. Разумеется, движок не может сопоставить литеральное =, ведь это уже сделала вторая группа .*. И опять бэктрекинг. И это мы пытаемся сопоставить строку из трех символов!
В итоге первая группа .* сопоставляется только с первым x, вторая .* — с нулем символов, и движок наконец сопоставляет литеральное = в выражении с = в строке. Дальше последняя группа .* сопоставляется с последним x.
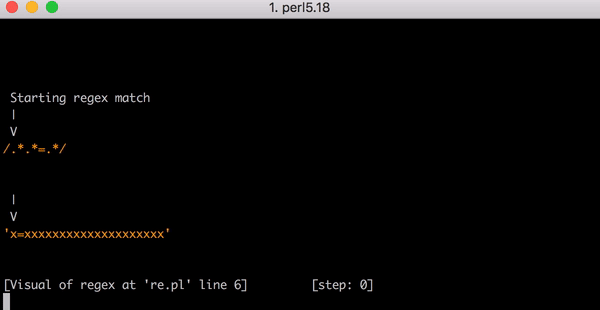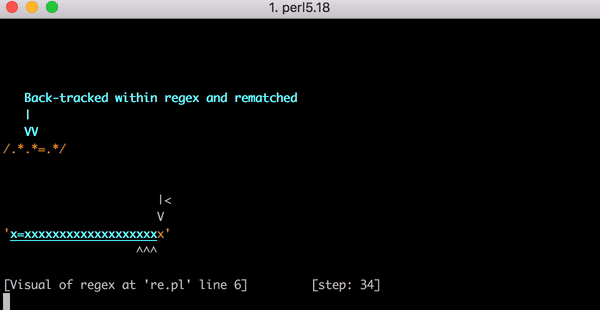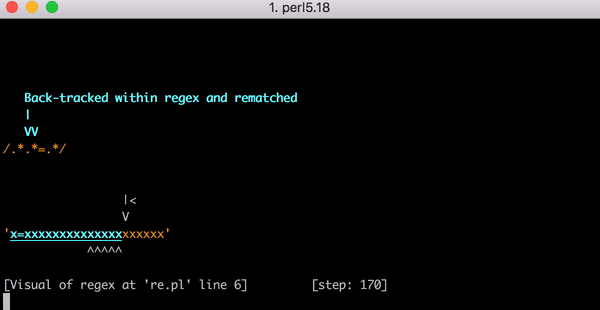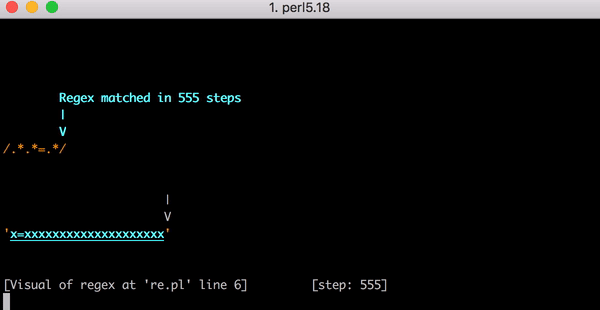
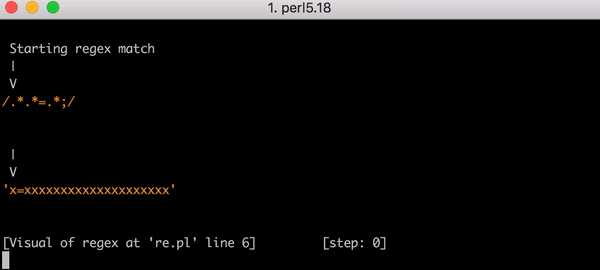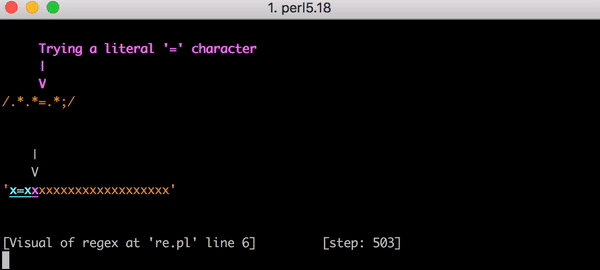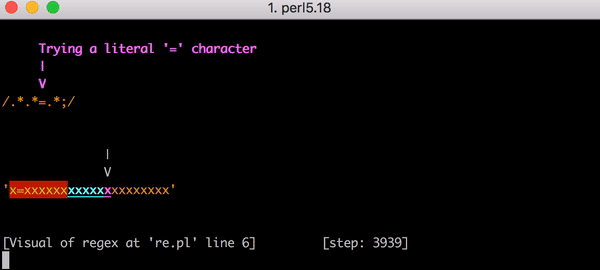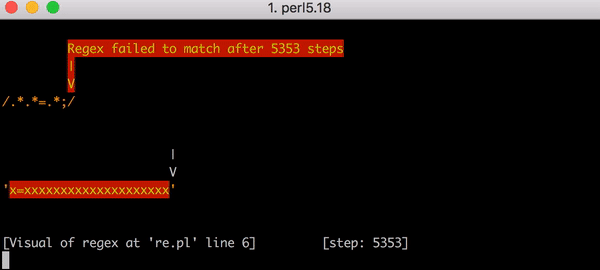
23 шага только для x=x. Посмотрите короткое видео об использовании Perl Regexp::Debugger, где показано, как происходят шаги и бэктрекинг.
Это уже немало работы, но что если вместо x=x у нас будет x=xx? Это 33 шага. А если x=xxx? 45. Зависимость не линейная. На графике показано сопоставление от x=x до x=xxxxxxxxxxxxxxxxxxxx (20 x после =). Если у нас 20 x после =, движок выполняет сопоставление за 555 шагов! (Мало того, если у нас потерялся x= и строка состоит просто из 20 x, движок сделает 4067 шагов, чтобы понять, что совпадений нет).
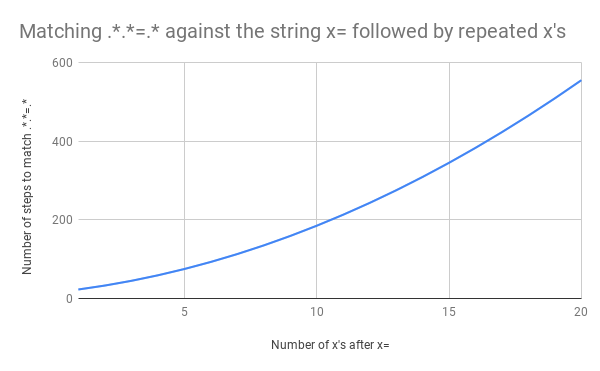
В этом видео показан весь бэктрекинг для сопоставления x=xxxxxxxxxxxxxxxxxxxx:
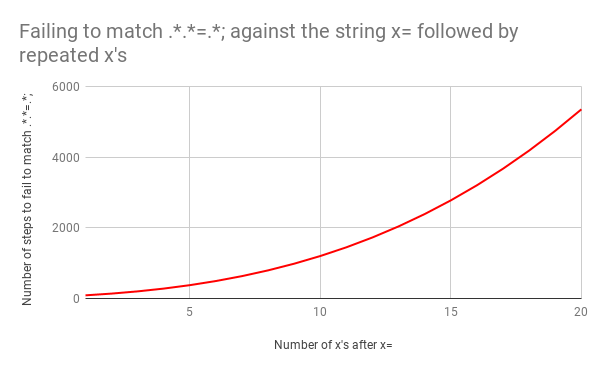
Беда в том, что при увеличении размера строки время сопоставления растет сверхлинейно. Но все может быть еще хуже, если регулярное выражение немного изменить. Допустим, у нас было бы .*.*=.*; (то есть в конце паттерна была литеральная точка с запятой). Например, для сопоставления с таким выражением, как foo=bar;.
И здесь бэктрекинг стал бы настоящей катастрофой. Для сопоставления x=x понадобится 90 шагов, а не 23. И это число быстро растет. Чтобы сопоставить x= и 20 x, нужно 5353 шага. Вот график. Посмотрите на значения по оси Y по сравнению с предыдущим графиком.
Если интересно, посмотрите все 5353 шага неудачного сопоставления x=xxxxxxxxxxxxxxxxxxxx и .*.*=.*;
Если использовать «ленивые», а не «жадные» сопоставления, масштаб бэктрекинга можно контролировать. Если изменить оригинальное выражение на .*?.*?=.*?, для сопоставления x=x понадобится 11 шагов (а не 23). Как и для x=xxxxxxxxxxxxxxxxxxxx. Все потому, что ? после .* велит движку сопоставить минимальное число символов, прежде чем идти дальше.
Но «ленивые» сопоставления не решают проблему бэктрекинга полностью. Если заменить катастрофический пример .*.*=.*; на .*?.*?=.*?;, время выполнения останется прежним. x=x все равно требует 555 шагов, а x= и 20 x — 5353.
Единственное, что можно сделать (кроме полного переписывания паттерна для большей конкретики) — отказаться от движка регулярных выражений с его механизмом бэктрекинга. Этим мы и займемся в следующие несколько недель.
Решение этой проблемы известно еще с 1968 года, когда Кент Томпсон написал статью Programming Techniques: Regular expression search algorithm («Методы программирования: алгоритм поиска регулярных выражений»). В статье описан механизм, которые позволяет преобразовать регулярное выражение в недетерминированные конечные автоматы, а после изменений состояния в недетерминированных конечных автоматах использовать алгоритм, время выполнения которого линейно зависит от сопоставляемой строки.

Методы программирования
Алгоритм поиска регулярных выражений
Кен Томпсон (Ken Thompson)
Bell Telephone Laboratories, Inc., Мюррей-Хилл, штат Нью-ДжерсиЗдесь описывается метод поиска определенной строки символов в тексте и обсуждается реализация этого метода в форме компилятора. Компилятор принимает регулярное выражение в качестве исходного кода и создает программу для IBM 7094 в качестве объектного кода. Объектная программа принимает входные данные в виде текста для поиска и подает сигнал каждый раз, когда строка из текста сопоставляется с заданным регулярным выражением. В статье приводятся примеры, проблемы и решения.
Алгоритм
Предыдущие алгоритмы поиска приводили к бэктрекингу, если частично успешный поиск не давал результата.В режиме компиляции алгоритм работает не с символами. Он передает инструкции в компилированный код. Выполнение происходит очень быстро — после передачи данных в верхнюю часть текущего списка автоматически выполняется поиск всех возможных последовательных символов в регулярном выражении.
Алгоритм компиляции и поиска включен в текстовый редактор с разделением времени как контекстный поиск. Разумеется, это далеко не единственное применение подобной процедуры поиска. Например, вариант этого алгоритма используется как поиск символов по таблице в ассемблере.
Предполагается, что читатель знаком с регулярными выражениями и языком программирования компьютера IBM 7094.Компилятор
Компилятор состоит из трех параллельно выполняющихся этапов. Первый этап — фильтрация по синтаксису, которая пропускает только синтаксически правильные регулярные выражения. На этом этапе также вставляется оператор «·» для сопоставления регулярных выражений. На втором этапе регулярное выражение преобразуется в постфиксную форму. На третьем этапе создается объектный код. Первые 2 этапа очевидны, и мы не будем на них останавливаться.
В статье Томпсона не говорится о недетерминированных конечных автоматах, но хорошо объяснен алгоритм линейного времени и представлена программа на ALGOL-60, которая создает код языка сборки для IBM 7094. Реализация мудреная, но сама идея очень простая.
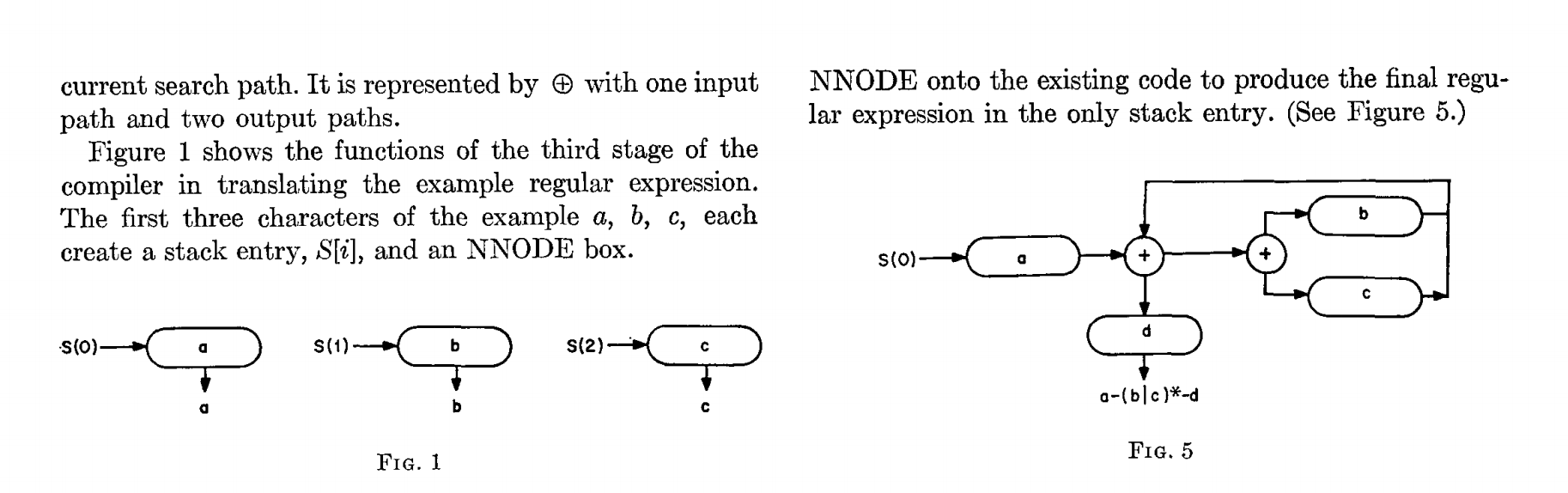
текущий путь поиска. Он представлен значком ⊕ с одним входом и двумя выходами.
На рисунке 1 показаны функции третьего этапа компиляции при преобразовании примера регулярного выражения. Первые три символа в примере — a, b, c, и каждый создает стековую запись S[i] и поле NNODE.NNODE к существующему коду, чтобы сгенерировать итоговое регулярное выражение в единственной стековой записи (см. рис. 5)
Вот как выглядело бы регулярное выражение .*.*=.*, если представить его, как на картинках из статьи Томпсона.
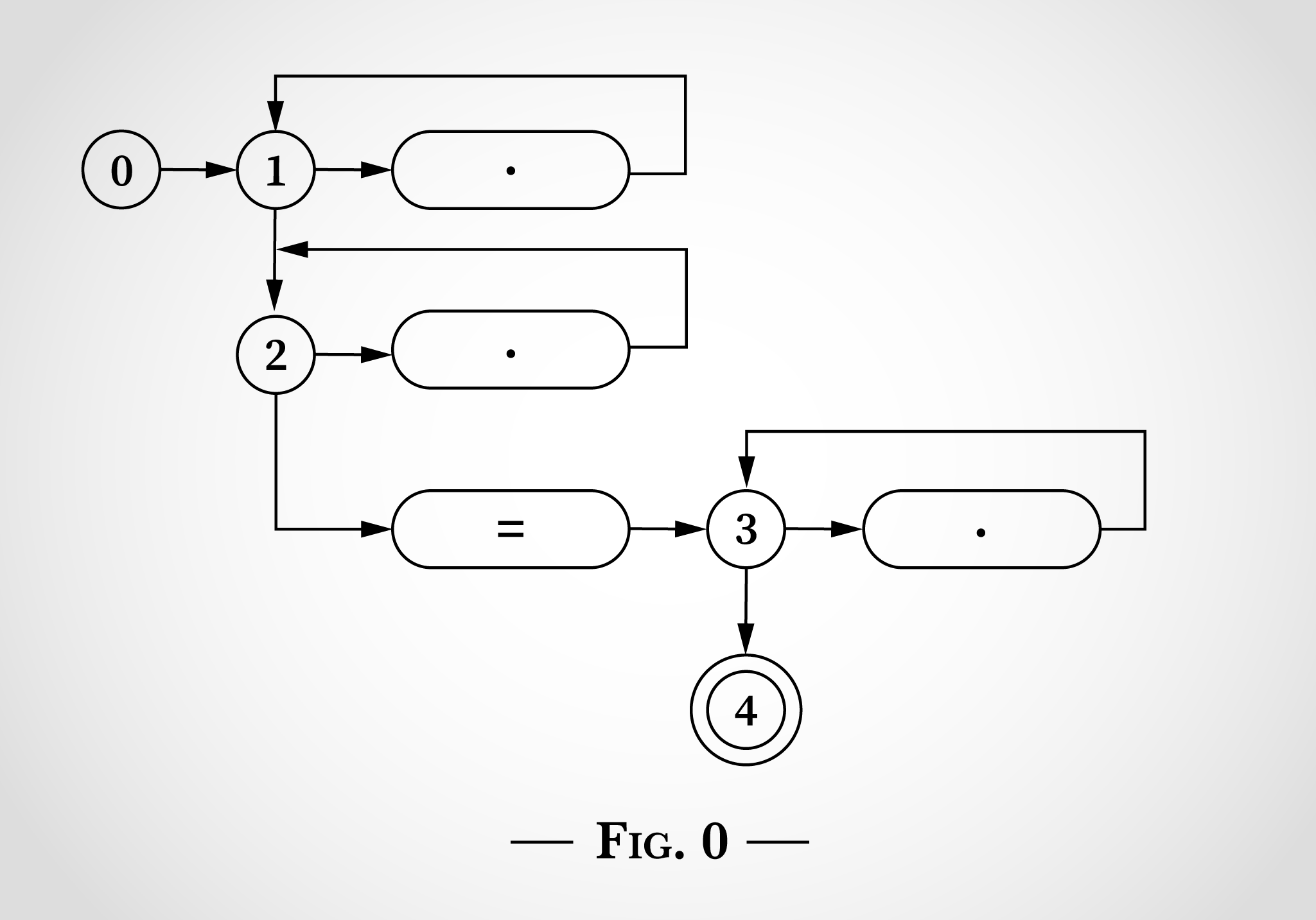
На рис. 0 есть пять состояний, начиная с 0, и 3 цикла, которые начинаются с состояний 1, 2 и 3. Эти три цикла соответствуют трем .* в регулярном выражении. 3 овала с точками соответствуют одному символу. Овал со знаком = соответствует литеральному символу =. Состояние 4 является конечным. Если мы его достигли, значит регулярное выражение сопоставлено.
Чтобы увидеть, как такую диаграмму состояний можно использовать для сопоставления регулярного выражения .*.*=.*, мы рассмотрим сопоставление строки x=x. Программа начинается с состояния 0, как показано на рис. 1.
Чтобы этот алгоритм работал, конечная машина должна находиться в нескольких состояниях одновременно. Недетерминированный конечный автомат сделает все возможные переходы одновременно.
Еще не успев считать входные данные, он переходит в оба первых состояния (1 и 2), как показано на рис. 2.
На рис. 2 видно, что происходит, когда он рассматривает первый x в x=x. x может сопоставиться с верхней точкой, перейдя из состояния 1 и обратно в состояние 1. Или x может сопоставиться с точкой ниже, перейдя из состояния 2 и обратно в состояние 2.
После сопоставления первого x в x=x мы по-прежнему в состояниях 1 и 2. Мы не можем достичь состояния 3 или 4, потому что нам нужен литеральный символ =.
Затем алгоритм рассматривает = в x=x. Как и x до этого, его можно сопоставить с любым из двух верхних циклов с переходом из состояния 1 и в состояние 1 или из состояния 2 в состояние 2, но при этом алгоритм может сопоставить литеральное = и перейти из состояние 2 в состояние 3 (и сразу 4). Это показано на рис. 3.
Затем алгоритм переходит к последнему x в x=x. Из состояний 1 и 2 те же переходы возможны обратно в состояния 1 и 2. Из состояния 3 x может сопоставиться с точкой справа и перейти обратно в состояние 3.
На этом этапе каждый символ x=x рассмотрен, а раз мы достигли состояния 4, регулярное выражение соответствует этой строке. Каждый символ обработан один раз, так что этот алгоритм линейно зависит от длины входной строки. И никакого бэктрекинга.
Очевидно, что после достижения состояния 4 (когда алгоритм сопоставил x=) все регулярное выражение сопоставлено, и алгоритм может завершиться, вообще не рассматривая x.
Этот алгоритм линейно зависит от размера входной строки.
ссылка на оригинал статьи https://habr.com/ru/company/southbridge/blog/460863/
Добавить комментарий