Перед тем, как перейти к разбору кода, рекомендуется изучить базовый синтаксис языка Verilog.
Здесь вы можете найти обучающие материалы.
RAM
Шаг 1: объявление модуля с соответствующими входными/выходными сигналами
module ram ( input [word_size - 1:0] data, input [word_size - 1:0] addr, input wr, input clk, output response, output [word_size - 1:0] out ); parameter word_size = 32;
- data — данные для записи.
- addr — адрес к участку памяти в RAM.
- wr — статус (считывание/запись).
- clk — clock cycle системы.
- response — готовность RAM (1 — если RAM обработал запрос на считывание/запись, 0 — в противном случае).
- out — данные, считанные из RAM.
Данная реализация интегрировалась в FPGA Altera Max 10, которая имеет 32 разрядную архитектуру, в связи с чем размер для данных и адреса(word_size) 32 бита.
Шаг 2: объявление регистров внутри модуля
Объявление массива для хранения данных:
parameter size = 1<<32; reg [word_size-1:0] ram [size-1:0]; Также нам понадобится хранить предыдущие входные параметры с целью отслеживания их изменений в always блоке:
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg; И последние два регистра для обновления выходных сигналов после вычислений в always блоке:
reg [word_size-1:0] out_reg; reg response_reg; Инициализируем регистры:
initial begin response_reg = 1; data_reg = 0; addr_reg = 0; wr_reg = 0; end
Шаг 3: реализация логики always блока
always @(negedge clk) begin if ((data != data_reg) || (addr%size != addr_reg)|| (wr != wr_reg)) begin response_reg = 0; data_reg = data; addr_reg = addr%size; wr_reg = wr; end else begin if (response_reg == 0) begin if (wr) ram[addr] = data; else out_reg = ram[addr]; response_reg = 1; end end end Always блок срабатывает на negedje, т.е. в момент перехода clock-а с 1 на 0. Это сделано для правильной синхронизации RAM-а c кэшем. Иначе возможны случаи, когда RAM не успевает сбросить статус готовности с 1 на 0 и на следующем clock-е кэш решает, что RAM благополучно обработал его запрос, что в корне неверно.
Логика алгоритма always блока такова: если данные обновлены, сбрасываем статус готовности на 0 и записываем/считываем данные, если запись/считывание выполнены, обновляем статус готовности на 1.
В конце добавляем следующий участок кода:
assign out = out_reg; assign response = response_reg; Тип выходных сигналов нашего модуля — wire. Единственный способ изменения сигналов данного типа — долгосрочное присваивание, являющееся запрещённым внутри always блока. По этой причине в always блоке используются регистры, которые в дальнейшем присваиваются выходным сигналам.
Direct mapping cache
Direct mapping cache — один из наиболее простых видов кэша. В данной реализации кэш состоит из n элементов, а RAM условно делится на блоки по n, тогда i-ому элементу в кэше соответствуют все такие k-ые элементы в RAM, удовлетворяющие условию i = k % n.
На приведённом ниже рисунке изображён кэш размером 4 и RAM размером 16.
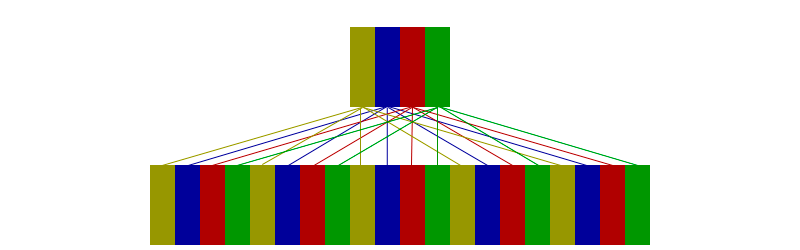
Каждый элемент кэша содержит следующую информацию:
- бит валидности — является ли информация в кэше актуальной.
- тэг — номер блока в RAM, где находится этот элемент.
- данные — информация, которую мы записываем/считываем.
При запросе на считывание кэш делит входной адрес на две части — тэг и индекс. При этом размер индекса — это log(n), где n — это размер кэша.
Шаг 1: объявление модуля с соответствующими входными/выходными сигналами
module direct_mapping_cache ( input [word_size-1:0] data, input [word_size-1:0] addr, input wr, input clk, output response, output is_missrate, output [word_size-1:0] out ); parameter word_size = 32; Объявление модуля кэша идентично RAM-у, за исключением нового выходного сигнала is_missrate. Этот выходной сигнал хранит информацию о том, был ли последний запрос на считывание missrate-ом.
Шаг 2: объявление регистров и RAM-а
Перед тем, как объявить регистры, определим размеры кэша и индекса:
parameter size = 64; parameter index_size = 6; Далее, объявляем массив, в котором и будут храниться данные, которые мы записываем и считываем:
reg [word_size-1:0] data_array [size-1:0]; Также нам нужно хранить биты валидности и тэги для каждого элемента в кэше:
reg validity_array [size-1:0]; reg [word_size-index_size-1:0] tag_array [size-1:0]; reg [index_size-1:0] index_array [size-1:0]; Регистры, в которые будет разбит входной адрес:
reg [word_size-index_size-1:0] tag; reg [index_size-1:0] index; Регистры, хранящие в себе входные значения на предыдущим clock-е(для отслеживания изменений входных данных):
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg; Регистры для обновления выходных сигналов после вычислений в always блоке:
reg response_reg; reg is_missrate_reg; reg [word_size-1:0] out_reg; Входные значения для RAM:
reg [word_size-1:0] ram_data; reg [word_size-1:0] ram_addr; reg ram_wr; Выходные значения для RAM:
wire ram_response; wire [word_size-1:0] ram_out; Объявление модуля RAM и подключение входных и выходных сигналов:
ram ram( .data(ram_data), .addr(ram_addr), .wr(ram_wr), .clk(clk), .response(ram_response), .out(ram_out)); Инициализация регистров:
initial integer i initial begin data_reg = 0; addr_reg = 0; wr_reg = 0; for (i = 0; i < size; i=i+1) begin data_array[i] = 0; tag_array[i] = 0; validity_array[i] = 0; end end
Шаг 3: реализация логики always блока
Начнём с того, что на каждый clock у нас есть два состояния — входные данные изменены, либо не изменены. Исходя из этого мы имеем следующее условие:
always @(posedge clk) begin if (data_reg != data || addr_reg != addr || wr_reg != wr) begin end //Блок 1: входные данные изменены else begin //Блок 2: входные данные не изменены end end Блок 1. В случае, если входные данные изменены, первым делом мы сбрасываем статус готовности на 0:
response_reg = 0; Далее мы обновляем регистры, хранившие входные значения предыдущего clock-а:
data_reg = data; addr_reg = addr; wr_reg = wr; Разбиваем входной адрес на тэг и индекс:
tag = addr >> index_size; index = addr; Для вычисления тэга используется побитовый сдвиг вправо, для индекса достаточно просто присвоить, т.к. лишние разряды адреса не учитываются.
Следующий шаг — выбор между записью и считыванием:
if (wr) begin // запись data_array[index] = data; tag_array[index] = tag; validity_array[index] = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end else begin // считывание if ((validity_array[index]) && (tag == tag_array[index])) begin // найден в кэше is_missrate_reg = 0; out_reg = data_array[index]; response_reg = 1; end else begin // не найден в кэше is_missrate_reg = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end end В случае записи первоначально мы изменяем данные в кэше, затем обновляем входные данные для RAM-а. В случае считывания мы проверяем наличие данного элемента в кэше и, если он есть, записываем его в out_reg, в противном случае обращаемся в RAM.
Блок 2. Если данные не были изменены с момента выполнения предыдущего clock-а, то мы имеем следующий код:
if ((ram_response) && (!response_reg)) begin if (wr == 0) begin validity_array [index] = 1; data_array [index] = ram_out; tag_array[index] = tag; out_reg = ram_out; end response_reg = 1; end Здесь мы ждём окончания выполнения обращения в RAM(в случае если обращения не было, ram_response равен 1), обновляем данные, если была команда на считывание и устанавливаем готовность кэша на 1.
И последнее, обновляем выходные значения:
assign out = out_reg; assign is_missrate = is_missrate_reg; assign response = response_reg;
ссылка на оригинал статьи https://habr.com/ru/post/461611/
Добавить комментарий