Пару лет назад главными трендами были автоматизация, DevOps-практики и ускорение поставки ценностей на рынок. Банк Хоум Кредит решил не отставать и взял курс на развитие технологий, тем более что по опенспейсу всё громче разносился недовольный шепоток пользователей, уставших по несколько дней ждать новых ресурсов для своих важных проектов.
Мы решили начать с процесса согласования заявок подразделениями, который, как и во многих крупных компаниях, требовал сил и времени. В качестве первой задачи выбрали процесс создания виртуальной машины безотносительно среды виртуализации. Составляя список задач, мы поняли, что нужно будет интегрироваться с другими системами, используемыми в инфраструктуре нашего банка, например по API.

Наиболее подходящим оказалось решение ManageIQ. Это проект, который приобрела компания Red Hat в 2012 году и на его базе создала коммерческий продукт Red Hat CloudForms. При этом ManageIQ остался в статусе open-source продукта и развивается параллельно с CloudForms.
ManageIQ написан на языке Ruby и поддерживает большое количество разных провайдеров виртуализации, публичных облаков и контейнеризации. В данный момент у нас в Хоуме используется версия Gaprindashvili в High-Availability конфигурации.
Как изменился процесс
Раньше от каждой команды требовались отдельные настройки в своей зоне ответственности. После предварительной подготовки все данные собирались и отправлялись администратору, который разворачивал и настраивал виртуальную машину. Затем нужно было сообщить, например, команде мониторинга, что появился новый хост, который нужно добавить на мониторинг. Задержки коммуникации, загруженность специалистов, ошибки, вызванные человеческим фактором, могли растянуть этот процесс до нескольких дней.
Уместив весь процесс в ManageIQ, мы получили следующие результаты:
| Тип виртуального ресурса | До внедрения ManageIQ | После внедрения ManageIQ |
|---|---|---|
| Виртуальная машина Linux в VMware/oVirt | До одной | ~ 10 минут |
| Виртуальная машина для окружения Rancher | рабочей | ~ 15 минут |
| Виртуальная машина Windows в VMware | недели | ~ 25 минут |
Разница во времени обусловлена тем, что во втором случае требуется дополнительное время, чтобы подготовить хост для работы с Docker, скачать и затегировать образы для инфраструктурных контейнеров из Artifactory, потому что на данном этапе ещё нет доступа в Docker Hub. В случае с Windows, разница достигается за счёт того, что, во-первых, время создания ВМ Linux без кастомизации составляет примерно 2 минуты, а ВМ Windows – 6 минут. Во-вторых, сама кастомизация Windows занимает около 10 минут, против 2 минут для Linux.
10 минут – не так уж и быстро, учитывая, что непосредственно на процесс создания ВМ тратится приблизительно 2-3 минуты. За оставшееся время ManageIQ успевает выполнить следующее:
- Система собирает параметры, заданные пользователем в форме заказа, и раскладывает их в переменные.
- В системе управления инцидентами создается новый запрос на изменение, в котором отображаются данные о новом ресурсе.
- Система выдачи ресурсных имен по запросу от ManageIQ присылает значение для нового ресурса.
- Система управления IP-адресами выдает новый адрес на основании введенных параметров.
- Регистрируется новая DNS-запись на локальном DNS-сервере.
- На основании параметров, среды и загруженности ресурсов, выбирается тип виртуализации и кластер для размещения.
- Далее происходит процесс создания виртуальной машины с заданными параметрами.
- Когда виртуальная машина развернута из шаблона, нужно запустить скрипты, которые произведут финальные настройки:
- расширение диска до заданного размера,
- генерация нового root-пароля, смена его на Linux хосте и запись в менеджер паролей,
- создание YAML-файла с конфигурацией для Puppet в GitLab,
- запуск runbook’ов, которые принесут нужные настройки и обновления для Windows ВМ или
- запуск Puppet, который обновит и настроит Linux машины.
- После всего этого закрывается запрос на изменение, созданный в п.2. В него добавляются свежие данные, вроде IP-адреса и имени хоста.
- В базе управления вычислительными ресурсами (CMDB) регистрируется новая единица.
- Виртуальная машина регистрируется в Zabbix и добавляется на мониторинг.
- Заказчику и другим заинтересованным лицам поступает e-mail с информацией о новой единице, созданной с помощью ManageIQ.
Что внутри
Давайте углубимся в технические детали продукта. По умолчанию ManageIQ может создать виртуальную машину из шаблона. Чем это отличается от того, что мы делаем, например, в vCenter? Правильный ответ – ничем. ManageIQ использует те же методы, что и системы виртуализации, но делает это из единого места. В дополнение к этому можно дописать свои сценарии, которые не вписываются в стандартный набор возможностей. Таким образом, если у вас есть ресурсы, например, в публичном Azure, в vCenter, который развернут на своём железе, плюс ещё где-то крутится кластер Kubernetes, то всем этим можно удобно управлять из ManageIQ.
Помимо большого разнообразия провайдеров для интеграции, ManageIQ обладает удобными инструментами для кастомизации. Это, например, создание удобных форм для решения вашей задачи:

Благодаря этому удалось сконструировать полноценный интерфейс для заказа виртуальной машины, уместив в него все необходимые параметры:
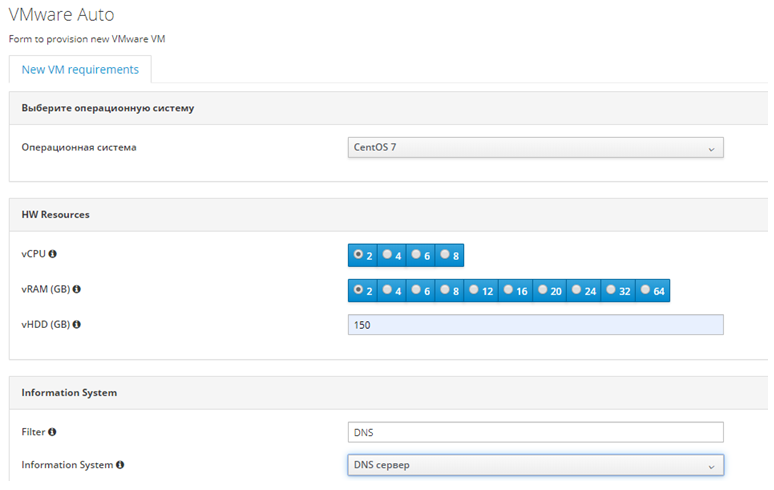
Мы выбираем количество вычислительных ресурсов, ОС, заполняем всю дополнительную информацию, которая нужна для интеграции с внешними системами. Дальше, используя внутренние механизмы (о них чуть позже), система выбирает, где будут размещены новые ресурсы: датацентр, кластер, хост и датастор выбираются в зависимости от всех внесенных параметров и загруженности ресурсов.
Не стоит забывать о том, что люди могут заказать слишком много ресурсов или совсем не то, что им нужно на самом деле. Здесь в игру вступает система запросов и подтверждений:
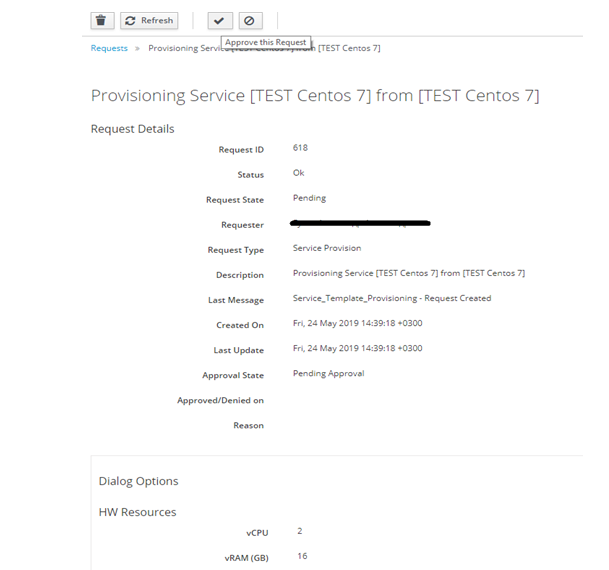
Любые ресурсы, которые заказывает пользователь, должны быть одобрены ответственным лицом. В Хоуме это делает группа архитекторов.
Структура автоматизации
Если разложить все процессы автоматизации в ManageIQ на мелкие детали, то можно заметить определенную структуру.
Automate Domain

В Datastore размещаются все домены, которые есть в ManageIQ.
По умолчанию есть домен ManageIQ, который заблокирован и является чем-то, вроде эталонной модели. Если нужно внести изменения, то создается ещё один домен, в который копируются элементы из домена ManageIQ и изменяются под собственные задачи.
Automate Namespace

Внутри домены делятся на части, которые отвечают за отдельные процессы: это может быть раздел, отвечающий за управление инфраструктурой (Infrastructure) или за работу с сервисами (Service). У нас есть свой Namespace, в котором размещено всё, что связано с системами банка.
Рассмотрим структуру более детально на примере процесса выделения ресурсов (provisioning) для новой виртуальной машины. Он описан в Automate Class, который называется VMProvision_VM.
Automate Class
Класс имеет структуру, в которую входят Instances, Methods, Properties и Schema. С точки зрения автоматизации наибольший интерес представляет Schema:

Схема похожа на pipeline в системах CI/CD. В ней описываются шаги, которые будут выполнены в процессе автоматизации.
Automate Instance

У класса, описанного выше, есть два Automate Instance. Каждый из них наследует от схемы этапы, для которых заданы Default Value. Этапы, у которых пустые значения, описываются в инстансе.

В инстансе появились значения для этапов, которые были пустыми в описании схемы. Также видно, кто и когда последний раз вносил изменения.
Посмотрим, что собой представляет одно из значений Value:

Перед нами Automate Class с именем Methods, у которого есть один Automate Instance. В его схеме описаны атрибут ipam_base_uri и метод execute. Метод execute, в свою очередь, вызывает Automate Method acquire_ip.
Automate Method
Это Ruby скрипт, который позволяет виртуальной машине взаимодействовать через REST API с другими системами. Например, как в случае с системой управления адресным пространством IPAM. В IPAM получаем адрес, маску, подсеть и VLAN для ВМ. Сложность в том, что машина может разворачиваться в тестовой среде или продуктивной, под приложения или БД. А может быть, служба безопасности постановила разместить её в контуре PCI-DSS. Вся эта информация собирается на этапе создания ВМ или передается в параметрах вызываемого инстанса (на скриншоте выше можно увидеть, что в параметре передается uri, по которому метод будет обращаться к IPAM):
base_uri = $evm.object['ipam_base_uri'] prov = $evm.root["miq_provision"] site = prov.get_option(:site) app = prov.get_option(:dialog_dropdown_list_information_system) crq = prov.get_option(:crq) descr = prov.get_option(:dialog_textarea_box_usernotes) owner = $evm.root['user'].name scope = prov.get_option(:dialog_dropdown_scope) environment = prov.get_option(:landscape)
$evm.root – это метод, который возвращает все, что может храниться в ManageIQ. Это может быть информация о пользователе, окружении, переменных, текущем запросе (‘miq_request’) и т.д. Нас интересует то, что касается текущего процесса provision.

Далее можем забрать нужные значения: get_option(:site) забирает значение, которое было передано на одном из предыдущих этапов, а, например, get_option(:dialog_dropdown_list_information_system) забирает из формы, которую заполняет пользователь при заказе новых ресурсов.
Все полученные значения передаются переменными в теле запроса в формате JSON:
options = { verify: false, headers: {"Content-Type" => "application/json"}, body: { "site" => "#{site}", "env" => "#{env}", "app" => "#{app}", "scope" => "#{scope}", "role" => "#{role}", "crq" => "#{crq}", "descr" => "#{descr}", "owner" => "#{owner}", }.to_json, }
По данному набору параметров IPAM однозначно определит, в каком VLAN должна быть размещена виртуальная машина, и вернёт сетевые параметры.
Помимо получения данных для корректной настройки ВМ, ManageIQ может ещё и генерировать дополнительную информацию, для того, чтобы произвести какие-то настройки на этапе так называемого post provisioning (после того, как виртуальная машина развернута и запущена). В Хоуме мы используем Puppet для управления конфигурациями Linux хостов. Для каждой вычислительной единицы создаем в GitLab YAML-файл с набором групп:
options = { headers: {"Private-Token" => "#{api_token}", "Content-Type" => "application/json"}, } body = { "branch" => "#{branch}", "author_email" => "email@your.domain", "author_name" => "ManageIQ Bot", "content" => "", "commit_message" => "New host created by ManageIQ", } descr = prov.get_option(:long_description) if descr.include?('rancher') && descr.include?('test') then body[:content] = "---\ngroups:\n - #{yaml_server}\n - rancher\n - user-devops-UDCR" end unless descr.include?('test') then if descr.include?('rancher') then body[:content] = "---\ngroups:\n - #{yaml_server}\n - rancher\n" end end unless descr.include?('rancher') then body[:content] = "---\ngroups:\n - #{yaml_server}\n - #{$is_id}" end
Группы зависят от типа виртуальной машины, среды, в которой она создана, информационной системы.

После удачного завершения процедуры, пользователю приходит письмо с информацией:

Текст письма также можно скорректировать, добавив туда необходимую информацию.
В случае, если произошла ошибка на каком-то из критичных этапов процесса, можно добавить условие, в котором будет явно указано, что процесс должен быть прерван. Если ошибка не несет фатальных последствий, также указать, что можно продолжать, несмотря на проблему.
Логирование
ManageIQ пишет логи всего, что можно отследить. Процесс автоматизации пишется в automation.log. Кроме этого есть логи API, разных облачных провайдеров, логи безопасности, логируется даже вывод команды top.
Для каждого события в схеме можно настроить запись в лог их начала и завершения:
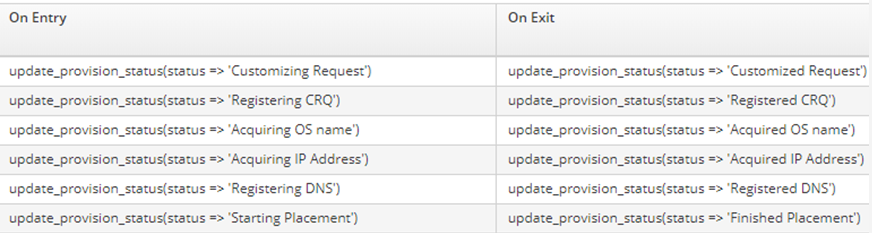
Кроме этого, можно писать в логи свои сообщения:
$evm.log(:info, "Call job status uri: #{item_uri}/#{job_id}/api/json")
Это очень полезно при обращении к системам по API, чтобы понять, почему что-то пошло не так. Или, чтобы отслеживать текущий статус продолжительного процесса, вроде выполнения Jenkins job’a или SCCM Runbook’a:
$evm.log(:info, "acquire_osname --- naming jobStatus: #{jobStatus}") break if jobStatus.to_s == "Completed"
Можно для записи в логи использовать и стандартные функции для exceptions:
raise “VM not specified” if vm.nil?
По умолчанию все логи хранятся в разделе /var/log/manageiq/*, но по собственному опыту могу сказать, что искать проблему через tail и grep – не самое удобное решение. Учитывая, что ManageIQ пишет очень много разнообразных логов, стоит позаботиться о том, чтобы перенаправлять логи, например, в стек ELK.
ManageIQ API
Помимо удобного веб-интерфейса, ManageIQ имеет функциональный API. С его помощью, например, мы решили проблему динамического определения идентификатора шаблона, который нужно указывать
def get_template(vendor, os, ems) user = '#{user}' pass = '#{pass}' options = { verify: false, headers: {"Accept" => "*/*", "accept-encoding" => "gzip, deflate"}, basic_auth: { username: "#{user}", password: "#{pass}" }, } response = HTTParty.get("#{host}/api/templates?filter[]=vendor=%27#{vendor}%27&filter[]=name=%27%2A#{os}%2A%27&filter[]=ems_id=%27#{ems}%27", options).to_s link = JSON.parse(response) link["resources"].each do |r| $url = r["href"] end response = HTTParty.get($url,options).to_s template = ["#{JSON.parse(response)['id']}"+", "+"#{JSON.parse(response)['name']}"] return template end
C помощью POST запроса и указания фильтров для поиска, получаем нужный шаблон.
Помимо решения внутренних задач, можно создавать новые методы API для использования внешними системами. В начале статьи был показан процесс заказа новой виртуальной машины с помощью веб-интерфейса. А вот так он выглядит, если делать это с помощью
curl -X POST \ http://Manageiq.hostname/api/service_catalogs/4/service_templates/31 \ -H 'Authorization: Basic Token-Value' \ -H 'Content-Type: application/json' \ -d '{ "action": "order", "resource": { "radio_button_vcpu": "a_2", "radio_button_vram": "a_2", "hdd_size": "40", "dropdown_os": "CentOS", "text_box_filter": "dns", "dropdown_list_information_system": "DNS сервер", "text_box_validator": "OK (DNS сервер)", "textarea_box_usernotes": "Дополнительная информация", "dropdown_env": "production", "date_control_retirement_dt": "2022-05-21", "dropdown_scope": "-" } }'
Заключение
Плюсы:
- Невероятная гибкость: ManageIQ позволяет не только кастомизировать процесс автоматизации так, как это нужно вам, но ещё даёт возможность изменить его визуальную часть, добавив дополнительные кнопки, поля и т.п.
- Встроенный редактор кода с подсветкой синтаксиса и валидацией кода. Мне это показалось очень удачным решением, если нужно быстро что-то поправить.
- Большое количество источников, с которыми умеет работать система. Облака: Amazon EC2, Google Compute Engine, Azure, OpenStack, VMware vCloud. Инфраструктура: Microsoft SCVMM, OpenStack Platform Director, Red Hat Virtualization, VMware vCenter. Контейнеры: Kubernetes, OpenShift.
Минусы:
- Большие возможности инструмента несут в себе и отрицательный момент. Не вся документация хорошо структурирована, и иногда сложно понять, где искать то, что тебе нужно. Однако, стоит отметить, что ситуация меняется в лучшую сторону, документация дополняется и улучшается.
- Небольшое сообщество. Если столкнётесь с какой-то очень специфической проблемой, возможно не удастся быстро «нагуглить» ответ. Или не удастся совсем.
- Пункт, который вытекает из предыдущих двух. Некоторые базовые вещи, настройки и сценарии можно найти в документации или интернете, но более специфические и узкие вопросы требовали большого времени для осмысления и проработки, в том числе методом научного тыка:smile:.
Как у нас сейчас:
За счет того, что ManageIQ может использовать все преимущества языка Ruby, мы смогли интегрировать его для работы со следующими API:
- Менеджер паролей. Он генерирует root-пароль в соответствии с требованиями службы безопасности, пишет его в свою базу, а ManageIQ применяет его внутри ОС;
- Службы Service Center Orchestration для управления DNS-записями и именами хостов;
- BMC Remedy. Весь процесс фиксируется в виде комментариев к запросу. После успешного выполнения, запрос закрывается;
- CMDB. Информация о новых конфигурационных единицах создается в базе со всеми нужными данными.
- Zabbix. В зависимости от принадлежности к информационной системе и среде, хосты добавляются в соответствующие группы мониторинга.
- Rancher. Реализовано создание новых окружений, установка агентов и регистрация хостов в существующих окружениях.
- Jenkins. В Jenkins запускаются job’ы для конфигурирования ВМ в oVirt;
- LDAP. Создание новых групп, которые используются для управления доступами в окружениях Rancher и для настройки политик в Vault;
- Vault. В Хоуме только началась интеграция этого продукта в банковские процессы, но мы уже сделали методы для создания новых групп, политик и разделов для хранения;
- Puppet и IPAM были упомянуты ранее.
Функционал и возможности системы очень обширны, и со многими из них я знакомился и продолжаю знакомиться в процессе внедрения системы.
Например, я не упомянул, что в системе есть возможность создания своих дашбордов со статистикой, настройки биллинга или кнопок, к которым можно прикрепить как отдельные скрипты, так и целые сценарии. Можно добавлять собственные поля для записи дополнительной информации о сервисах и виртуальных машинах и т.д.
К чему стремится Хоум:
- Обновление до версии Hammer, в которой в режиме HA можно будет попробовать поработать со встроенным Ansible.
- Переход от согласования для каждой единицы виртуальных ресурсов к управлению. Команды смогут получать новые ВМ ещё быстрее, если квота не исчерпана.
- Разработка новых методов для дальнейшего предоставления внешним системам.
- Например, различные SaaS, вроде jenkins, logstash и т.п.
- Внедрение новых методов API в существующий портал для владельцев информационных систем. Пользователям не нужно будет задумываться о том, как интегрироваться с новым элементом инфраструктуры, они просто будут использовать это как сервис для получения новых ресурсов или изменения существующих.
В самом конце хотелось бы напомнить, что инструменты – это прекрасно, но не стоит забывать о важности взаимодействия между разными командами. Изменения, описанные в статье, не были бы возможны без хорошо налаженной коммуникации и постоянного взаимодействия по возникающим вопросам всех заинтересованных сторон.
ссылка на оригинал статьи https://habr.com/ru/company/homecredit/blog/461891/
Добавить комментарий