
Два года назад Сундар Пичаи, глава Google, рассказал о том, что компания из mobile-first становится AI-first и фокусируется на машинном обучении. Год спустя вышел Machine Learning Kit — набор инструментов, с которым можно эффективно использовать ML на iOS и Android.
Об ML Kit очень много говорят в США, но на русском языке информации почти нет. А так как мы используем его для некоторых задач в Яндекс.Деньгах, я решил поделиться опытом и показать на примерах, как с его помощью можно делать интересные вещи.
Меня зовут Юра, последний год я работаю в команде Яндекс.Денег над мобильным кошельком. Мы поговорим про машинное обучение в мобайле.
Прим. редакции: этот пост — пересказ доклада Юрия Чечёткина «From mobile first to AI first» с митапа Яндекс.Денег Android Paranoid.
Что такое ML Kit?
Это мобильный SDK от Google, который позволяет использовать легко использовать машинное обучение на устройствах с Android и iOS. Необязательно быть экспертом в ML или в искусственном интеллекте, потому что в несколько строчек кода можно реализовать очень сложные вещи. Более того, необязательно знать, как работают нейронные сети или оптимизация моделей.
Что же может ML Kit?
Базовые возможности достаточно широкие. Например, можно распознавать текст, лица, находить и отслеживать объекты, создавать метки для изображений и собственные модели классификации, сканировать штрих-коды и QR-метки.
Распознавание QR-кодов мы уже использовали в приложении Яндекс.Денег.
Ещё в ML Kit есть
- Распознавание ориентиров;
- Определение языка, на котором написан текст;
- Перевод текстов на устройстве;
- Быстрый ответ на письмо или сообщение.
Кроме огромного количества методов из коробки, есть поддержка кастомных моделей, что практически дает безграничные возможности — например, можно раскрашивать черно-белые фотографии и делать их цветными.
Важно, что для этого не нужно использовать какие-то сервисы, API или бэкенд. Всё можно делать прямо на устройстве, так мы не нагружаем трафик пользователя, не получаем кучу ошибок, связанных с сетью, не должны обрабатывать кучу кейсов, например, отсутствие интернета, потери связи и так далее. Более того, на девайсе это работает намного быстрее, чем через сеть.

Распознавание текста
Задача: дана фотография, нужно получить текст, обведенный в прямоугольником.
Начинаем с зависимости в Gradle. Достаточно подключить одну зависимость, и мы уже готовы работать.
dependencies { // ... implementation'com.google.firebase:firebase-ml-vision:20.0.0' }
Стоит указать метаданные, которые говорят, что модель будет загружена на устройство во время скачивания приложения из Play Market. Если не сделать этого и обращаться к API без модели, то получим ошибку, а модель придется скачивать в фоновом режиме. Если нужно использовать несколько моделей, желательно их указывать через запятую. В нашем примере используем модель OCR, а название остальных можно посмотреть в документации.
<application ...> ... <meta-data android:name="com.google.firebase.ml.vision.DEPENDENCIES" android:value="ocr" /> <!-- To use multiple models: android:value="ocr,model2,model3" --> </application>
После конфигурации проекта нужно задать входные значения. ML Kit работает с типом FirebaseVisionImage, у нас есть таких пять методов, сигнатуру которых я выписал ниже. Они конвертируют привычные типы Android и Java в типы ML Kit, с которыми ему удобно работать.
fun fromMediaImage(image: Image, rotation: Int): FirebaseVisionImage fun fromBitmap(bitmap: Bitmap): FirebaseVisionImage fun fromFilePath(context: Context, uri: Uri): FirebaseVisionImage fun fromByteBuffer( byteBuffer: ByteBuffer, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage fun fromByteArray( bytes: ByteArray, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage
Обратите внимание на последние два — они работают с массивом байтов и с байтовым буфером, и нам надо указать метаданные, чтобы ML Kit понимал, как это всё обрабатывать. Метаданные, по сути, описывают формат, в данном случае это ширина и высота, формат по умолчанию, IMAGE_FORMAT_NV21 и и rotation.
val metadata = FirebaseVisionImageMetadata.Builder() .setWidth(480) .setHeight(360) .setFormat(FirebaseVisionImageMetadata.IMAGE_FORMAT_NV21) .setRotation(rotation) .build() val image = FirebaseVisionImage.fromByteBuffer(buffer, metadata)
Когда входные данные собраны, создаем детектор, который будет распознавать текст.
Существует два вида детекторов, на устройстве и в облаке, они создаются буквально в одну строчку. Стоит отметить, что детектор на устройстве работает только с английским языком. Облачный детектор поддерживает больше 20 языков, их нужно указать в специальном методе setLanguageHints.
// onDevice val detector = FirebaseVision.getInstance().getOnDeviceTextRecognizer() // onCloud with options val options = FirebaseVisionCloudTextRecognizerOptions.Builder() .setLanguageHints(arrayOf("en", "ru")) .build() val detector = FirebaseVision.getInstance().getCloudTextRecognizer(options)
Количество поддерживаемых языков больше 20, они все есть на официальном сайте. В нашем примере — только английский и русский.
После того как есть входные данные и детектор, достаточно вызвать на этом детекторе метод processImage. Получаем результат в виде таска, на который вешаем два колбэка — на успех и на ошибку. На ошибку приходит стандартный exсeption, а на успех от onSuccessListener приходит тип FirebaseVisionText.
val result: Task<FirebaseVisionText> = detector.processImage(image) .addOnSuccessListener { result: FirebaseVisionText -> // Task completed successfully // ... } .addOnFailureListener { exception: Exception -> // Task failed with an exception // ... }
Как работать с типом FirebaseVisionText?
Он состоит из текстовых блоков (TextBlock), те в свою очередь состоят из строк (Line), а строки из элементов (Element). Они вложены друг в друга.
Более того, у каждого из этих классов есть пять методов, которые возвращают разные данные об объекте. Прямоугольник – та область, где находится текст, confidence – точность распознанного текста, corner points – угловые точки по часовой стрелке, начиная с левого верхнего угла, распознанные языки и сам текст.
FirebaseVisionText contains a list of FirebaseVisionText.TextBlock which contains a list of FirebaseVisionText.Line which is composed of a list of FirebaseVisionText.Element. fun getBoundingBox(): Rect // axis-aligned bounding rectangle of the detected text fun getConfidence(): Float // confidence of the recognized text fun getCornerPoints(): Array<Point> // four corner points in clockwise direction fun getRecognizedLanguages(): List<RecognizedLanguage> // a list of recognized languages fun getText(): String //recognized text as a string
Для чего это нужно?
Мы можем распознать как весь текст на картинке, так и отдельные его абзацы, куски, строчки или просто слова. И как пример, мы можем перебирать, на каждом этапе брать текст, брать границы этого текста, и отрисовывать. Очень удобно.
Мы планируем использовать этот инструмент в нашем приложении для распознавания банковских карт, надписи на которых расположены нестандартно. Далеко не все библиотеки распознавания карт работают хорошо, и для кастомных карт ML Kit был бы очень полезным. Поскольку текста немного, его очень легко обрабатывать таким способом.
Распознавание объектов на фото
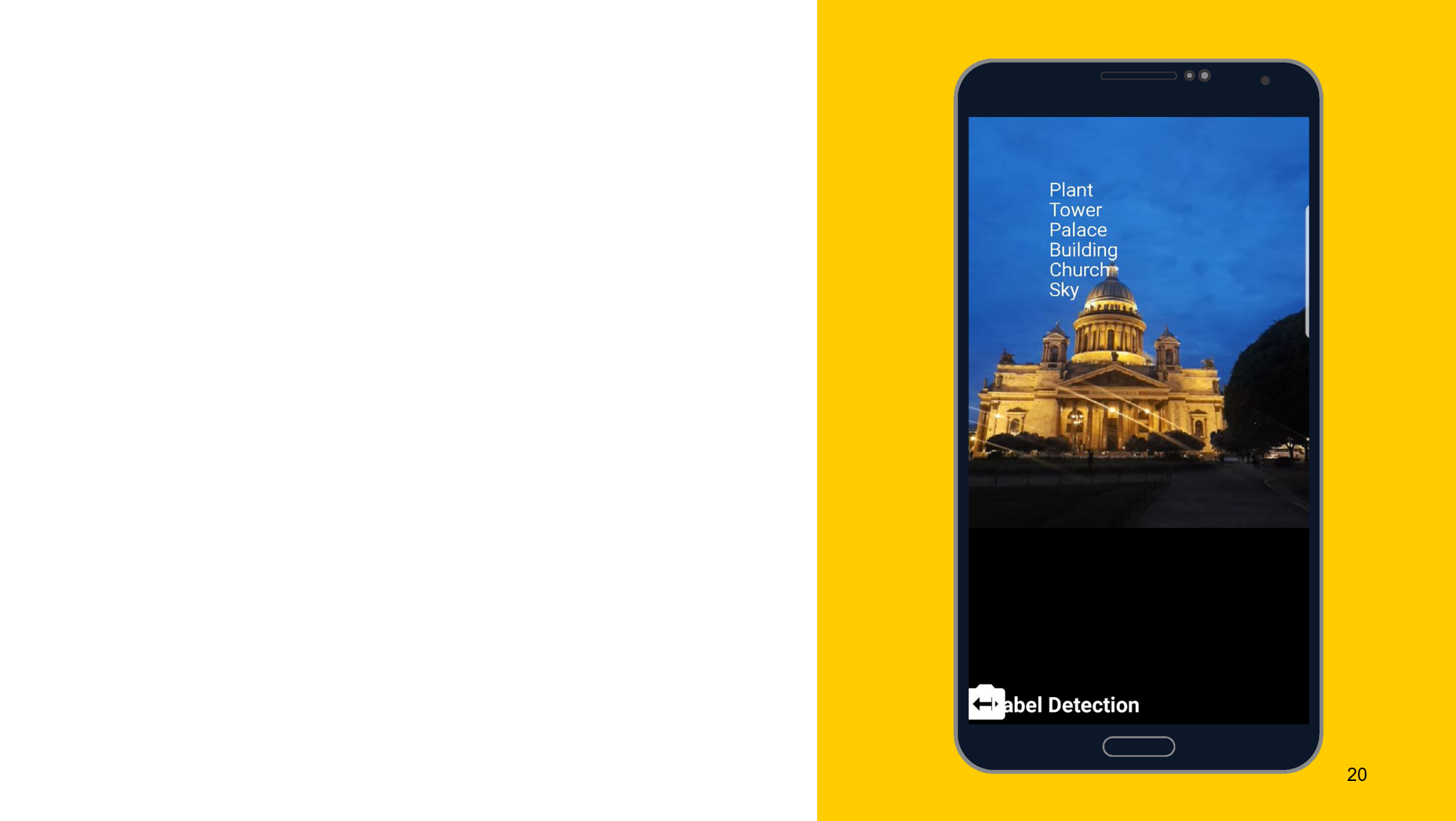
На примере следующего инструмента хотел бы показать, что принцип работы примерно одинаковый. В данном случае распознавание того, что изображено на объекте. Также создаем два детектора, один на девайсе, другой на облаке, в качестве параметров можем указать минимальную точность. По умолчанию 0,5, указали 0,7, и готовы к работе. Также получаем результат в виде FirebaseImageLabel, это список лейблов, каждый из которых содержит ID, описание и точность.
// onDevice val detector: FirebaseVisionImageLabeler = FirebaseVision .getInstance() .getOnDeviceImageLabeler() // onCloud with minimum confidence val options = FirebaseVisionCloudImageLabelerOptions.Builder() .setConfidenceThreshold(0.7f) .build() val detector: FirebaseVisionImageLabeler = FirebaseVision .getInstance() .getCloudImageLabeler(options)
Гарольд, скрывающий счастье

Можно попробовать понять, насколько хорошо Гарольд скрывает боль и счастлив ли он при этом. Используем инструмент распознавания лица, который, помимо распознавания черт лица, может сказать, насколько человек счастлив. Как оказалось, Гарольд счастлив на 93%. Либо он очень хорошо скрывает боль.

От легкого к легкому, но чуть более сложному. Кастомные модели.
Задача: классификация того, что изображено на фото.
Я сфотографировал ноутбук, и распознался модем, десктоп-компьютер и клавиатура. Похоже на правду. Есть тысяча классификаторов, и он берет три из них, которые лучше всего описывают эту фотографию.

При работе с кастомными моделями мы можем также работать с ними как на устройстве, так и через облако.
Если работаем через облако, нужно зайти в Firebase Console, во вкладку ML Kit, и в тап custom, где мы можем загрузить нашу модель в TensorFlow Lite, потому что ML Kit работает с моделями именно на этом разрешении. Если используем на девайсе, то можем просто положить модель в любую часть проекта в качестве ассета.
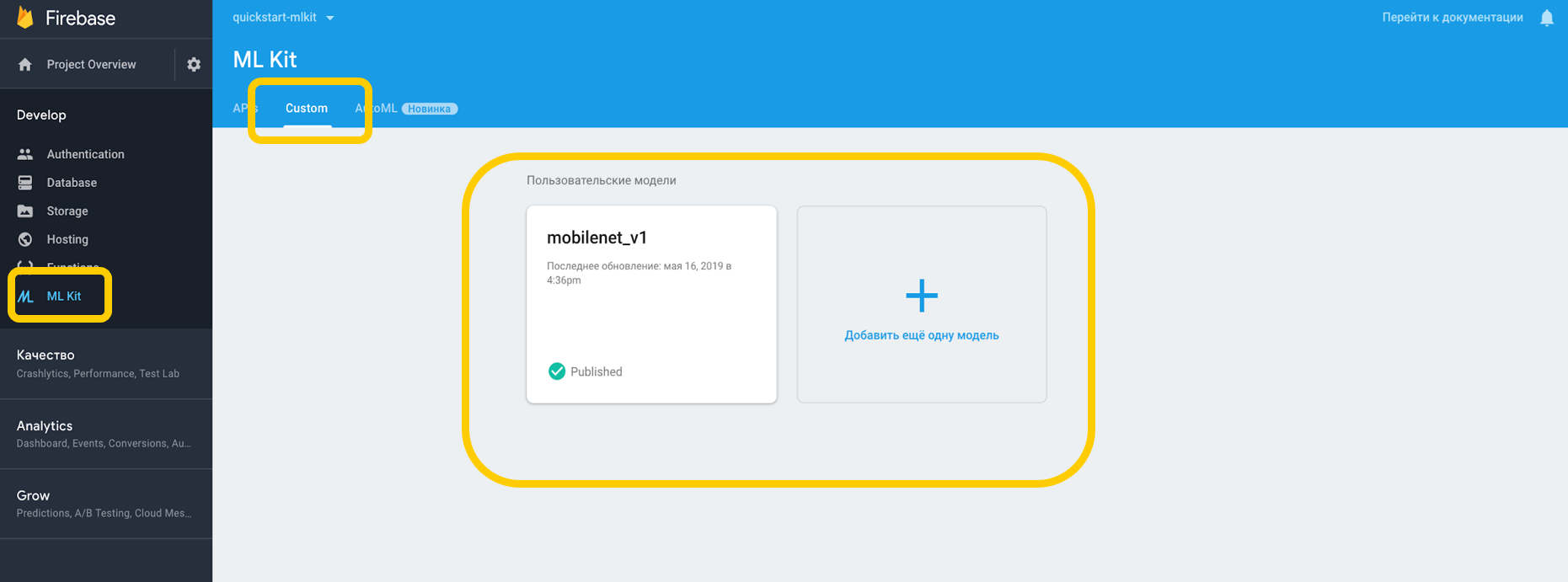
Указываем зависимость на интерпретатор, который умеет работать с кастомными моделями, и не забываем также о разрешении работы с интернетом.
<uses-permission android:name="android.permission.INTERNET" /> dependencies { // ... implementation 'com.google.firebase:firebase-ml-model-interpreter:19.0.0' }
Для тех моделей, которые находятся на девайсе, надо в Gradle указать, что модель не стоит сжимать, потому что она может исказиться.
android { // ... aaptOptions { noCompress "tflite" // Your model's file extension: "tflite" } }
Когда сконфигурировали всё в нашей среде, мы должны задать специальные условия, которые включают в себя, например, использование Wi-Fi, также с Android N доступно require charging и require device idle — эти условия показывают, что телефон заряжается или находится в режиме ожидания.
var conditionsBuilder: FirebaseModelDownloadConditions.Builder = FirebaseModelDownloadConditions.Builder().requireWifi() if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) { // Enable advanced conditions on Android Nougat and newer. conditionsBuilder = conditionsBuilder .requireCharging() .requireDeviceIdle() } val conditions: FirebaseModelDownloadConditions = conditionsBuilder.build()
Когда мы создаем удаленную модель, мы задаем условия инициализации и обновления, а также флаг, нужно ли обновлять нашу модель. Название модели должно совпадать с тем, которое мы указали в консоли Firebase. Когда создали удаленную модель, мы должны зарегистрировать её в Firebase Model Manager.
val cloudSource: FirebaseRemoteModel = FirebaseRemoteModel.Builder("my_cloud_model") .enableModelUpdates(true) .setInitialDownloadConditions(conditions) .setUpdatesDownloadConditions(conditions) .build() FirebaseModelManager.getInstance().registerRemoteModel(cloudSource)
Те же шаги делаем для локальной модели, указываем ее имя, путь до модели, и регистрируем её в Firebase Model Manager.
val localSource: FirebaseLocalModel = FirebaseLocalModel.Builder("my_local_model") .setAssetFilePath("my_model.tflite") .build() FirebaseModelManager.getInstance().registerLocalModel(localSource)
После этого надо создать такие опции, где мы указываем имена наших моделей, устанавливаем удаленную модель, устанавливаем локальную модель и создаем интерпретатор с этими опциями. Мы можем указать либо удаленную модель, либо только локальную, и интерпретатор будет сам понимать, с какой работать.
val options: FirebaseModelOptions = FirebaseModelOptions.Builder() .setRemoteModelName("my_cloud_model") .setLocalModelName("my_local_model") .build() val interpreter = FirebaseModelInterpreter.getInstance(options)
Ml Kit не знает ничего о формате входных и выходных данных кастомных моделей, поэтому нужно их указать.
Входные данные — многомерный массив, где 1 — количество изображений, 224х224 это разрешение, и 3 — трехканальное RGB изображение. Ну и тип данных – байты.
val input = intArrayOf(1, 224, 224, 3) //one 224x224 three-channel (RGB) image val output = intArrayOf(1, 1000) val inputOutputOptions = FirebaseModelInputOutputOptions.Builder() .setInputFormat(0, FirebaseModelDataType.BYTE, input) .setOutputFormat(0, FirebaseModelDataType.BYTE, output) .build()
Выходные значения – 1000 классификаторов. Задаем формат входных и выходных значений в байтах с указанными многомерными массивами. Помимо байтов также доступны float, long, int.
Теперь задаём входные значения. Берем Bitmap, сжимаем до 224 на 224, конвертируем в ByteBuffer и создаем входные значения с помощью FirebaseModelInput с помощью специального билдера.
val bitmap = Bitmap.createScaledBitmap(yourInputImage, 224, 224, true) val imgData = convertBitmapToByteBuffer(bitmap) val inputs: FirebaseModelInputs = FirebaseModelInputs.Builder() .add(imageData) .build()
И теперь, когда есть интерпретатор, формат входных и выходных значений и сами входные значения, мы можем выполнить запрос с помощью метода run. Всё перечисленное передаем в качестве параметров, и в результате получаем FirebaseModelOutput, который внутри себя содержит дженерик указанного нами типа. В данном случае это был массив Byte, получив который, мы можем приступить к обработке. Это как раз та тысяча классификаторов, которую мы просили, и мы выводим, например, топ-3 наиболее подходящих.
interpreter.run(inputs, inputOutputOptions) .addOnSuccessListener { result: FirebaseModelOutputs -> val labelProbArray = result.getOutput<Array<ByteArray>>(0) //handle labelProbArray } .addOnFailureListener( object : OnFailureListener { override fun onFailure(e: Exception) { // Task failed with an exception } })
Реализация за один день
Всё достаточно легко в реализации, и распознавание объектов встроенными срествами можно реализовать буквально за один день. Инструмент доступен на iOS и на Android, к тому же, можно использовать одну и ту же модель TensorFlow для обеих платформ.
Помимо этого есть куча методов, доступных из коробки, которые могут покрыть множество кейсов. Большинство API доступны на девайсе, то есть распознавание будет работать даже без интернета.
И самое главное – поддержка кастомных моделей, которые можно использовать как угодно и для любых задач.
Полезные ссылки
Документация по ML Kit
Демо-проект по ML Kit на Github
Machine Learning for mobile with Firebase (Google I/O’19)
Machine Learning SDK for mobile developers (Google I/O’18)
Creating a credit card scanner using Firebase ML Kit (Medium.com)
ссылка на оригинал статьи https://habr.com/ru/company/yamoney/blog/461867/
Добавить комментарий