Неправомерное Заимствование — это многоголовая гидра, враг, постоянно меняющий свое лицо. Наши лучшие частные сыщики готовы зацепиться за любое злодеяние, совершенное этим врагом. Однако противник не дремлет, он хитер и коварен: явно подставляясь в одном деле, он невероятно умело заметает следы в других. Иногда его удается поймать с поличным с помощью нашего самого шустрого сотрудника — Суффиксного Массива. Иногда противник мешкает, и скрупулезный, но неторопливый Поиск Парафраза успевает вычислить его местоположение. Но зло коварно, и нам постоянно нужны новые силы для борьбы с ним.
Сегодня мы расскажем о нашем новом детективе специального назначения по имени Нечеткий Поиск, а также о его первом столкновении с нечеткими заимствованиями.
С вами детективное агентство Антиплагиат, приготовьтесь к Делу о Таинственном Противнике

Источник изображения: pxhere.com
Место происшествия
При проверке местности (документа) Антиплагиат проверяет, не поступали ли звонки о возможном преступлении в этом районе. В качестве очевидцев, которые будут сигнализировать нам о преступлении, выступает Индекс шинглов.
«Шингл — это кусочек текста размером в несколько слов». Каждый такой кусочек хешируется, и в индексе ищутся документы, которые имеют шинглы с теми же хешами, что и в проверяемом документе.
Очевидец, видя совпадение по хешу двух шинглов, звонит нам с сообщением о преступлении. К сожалению, индекс шинглов нельзя наказать за ложный вызов, он невосприимчив к санкциям, из-за чего звонков происходит очень много. Агентство определяет документы с наибольшим скоплением таких звонков — места потенциального преступления.
Первая зацепка
Теперь ты детектив, сынок.
Отныне тебе запрещается верить в совпадения.
© «Темный рыцарь: возрождение легенды» («The Dark Knight Rises», реж. К. Нолан, 2012).
Детектив Нечеткий Поиск прибыл на место преступления. Достаточно крупные преступники не остаются незамеченными, ведь чем больше масштаб преступления, тем больше шансов оставить зацепку. Для Нечеткого Поиска такими зацепками являются короткие совпадения фиксированной длины. Кажется, что наш детектив упускает большую долю умело заметающих следы преступников, однако лишь 5% злоумышленников не оставляют такой зацепки. Важно не потерять преступников, поэтому детектив быстро сканирует местность, используя особую методику обнаружения совпадений.
Дневник детектива о методике работы. Первый этап
Воспользуемся двумя особенностями задачи:
- Нас интересуют четкие дубликаты фиксированной длины.
- В хорошем документе один и тот же шингл не дублируется слишком много раз.
Второе условие необходимо, чтобы ограничить количество найденных четких дубликатов. Ведь шингл, встречающийся 1000 раз в документе и в источнике, даст 1000000 пар совпадений. Такие часто повторяющиеся шинглы можно увидеть только в неочищенных документах с попытками обхода.
Очищенный от обходов документ представлен в виде последовательности слов. Приводим слова к нормальной словоформе, затем хешируем их. Получим последовательность целых чисел (на гифке — последовательность букв). Все шинглы этой последовательности хешируются и заносятся в хеш-таблицу с значением позиции начала подстроки. Затем для каждого шингла в документе-кандидате ищутся совпадения в хеш-таблице. Так формируются четкие дубликаты фиксированной длины. Тесты показывают трехкратное ускорение при использовании нового метода в сравнении с суффиксным массивом.
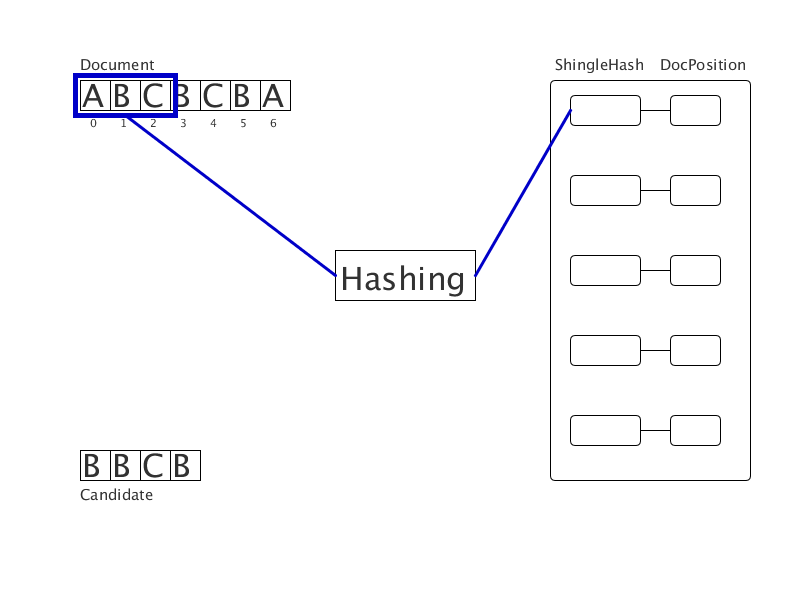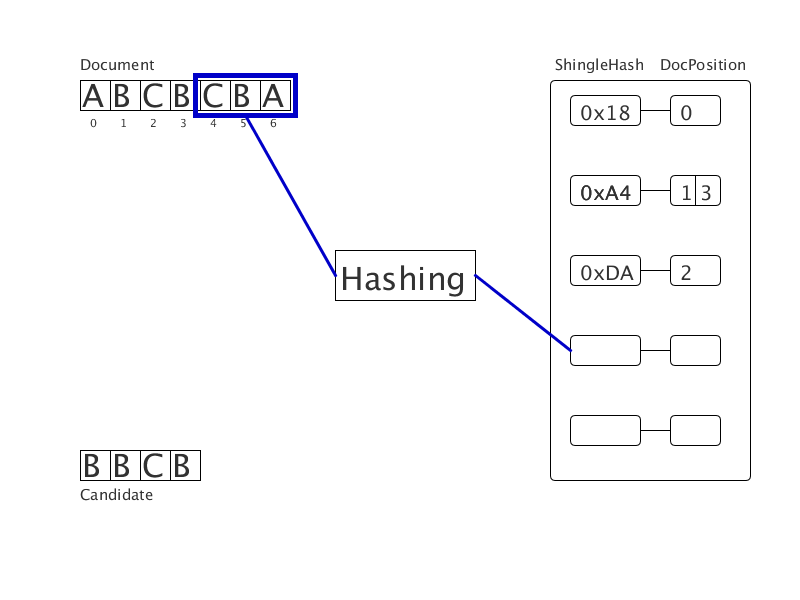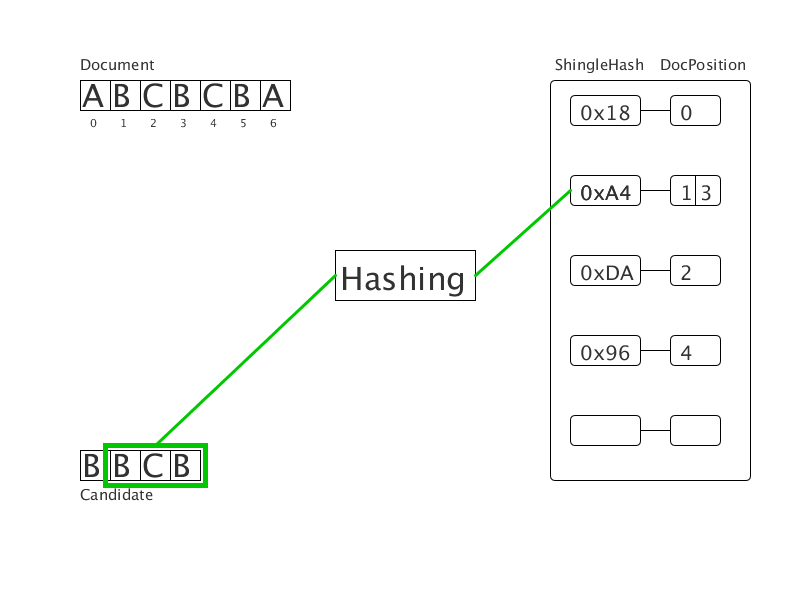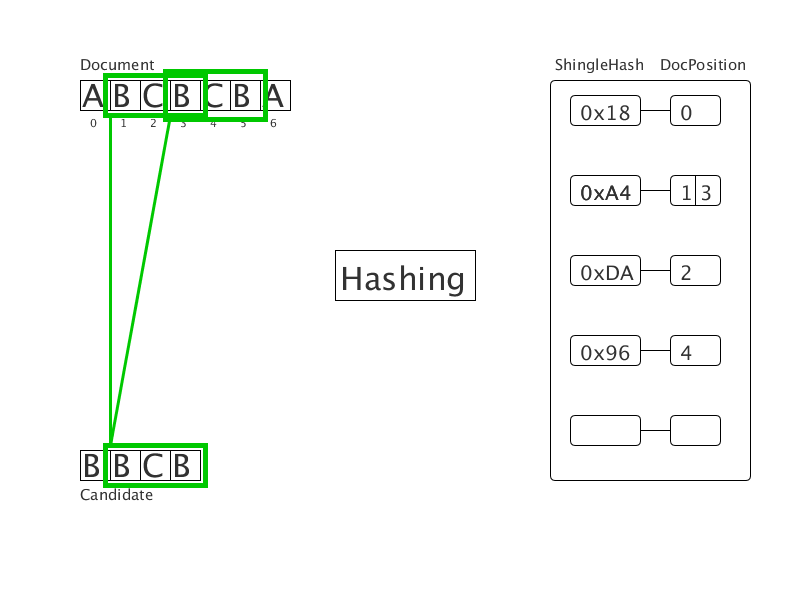
Вычисляем преступника
— Есть еще какие-то моменты, на которые вы посоветовали бы мне обратить внимание?
— На странное поведение собаки в ночь преступления.
— Собаки? Но она никак себя не вела!
— Это-то и странно, — сказал Холмс.
© Артур Конан-Дойль, «Серебрянный» (из серии «Записки о Шерлоке Холмсе»)
Итак, Нечеткий Поиск отыскал несколько зацепок, по которым нужно установить преступников. Наш герой использует свои дедуктивные способности на полную катушку, чтобы по крупицам, постепенно восстановить образ преступника по найденным зацепкам. Сыщик постепенно расширяет картину происходящего, дополняя ее новыми деталями, обнаруживая все новые и новые улики, пока эта картина, наконец, не станет полной. Нашего детектива иногда заносит, и его приходится спускать с небес на землю и убеждать, что нам нужна личность преступника, а не биография его двоюродной сестры. Нечеткий Поиск ворчит, но смиренно сужает картину до желаемых масштабов.
Дневник детектива о методике работы. Второй этап

Источник изображения: pixabay.com
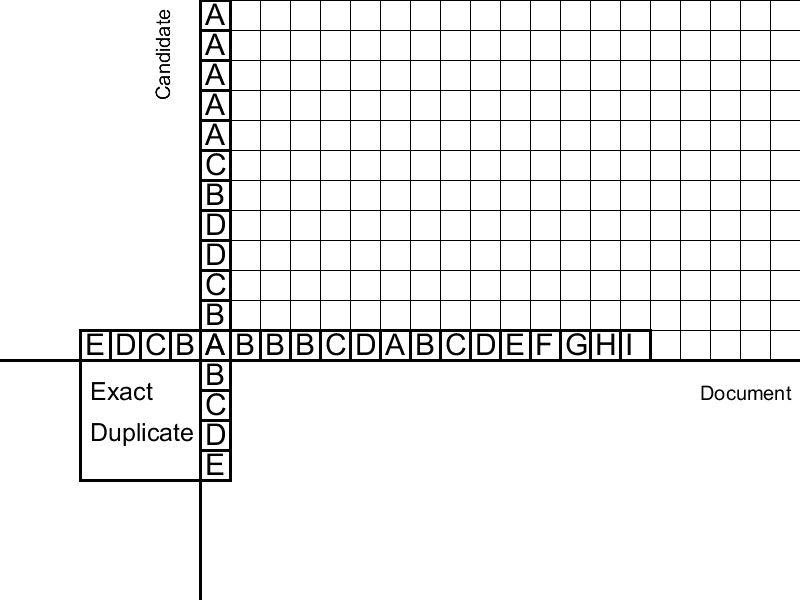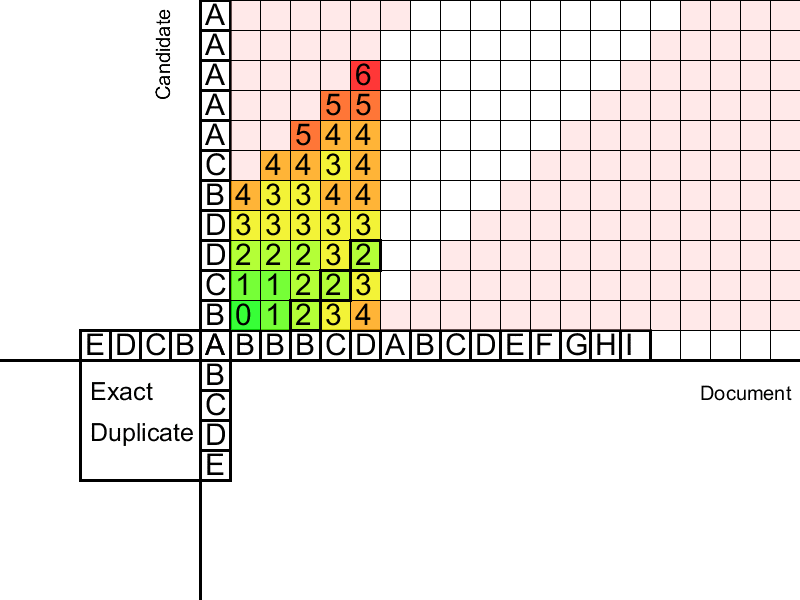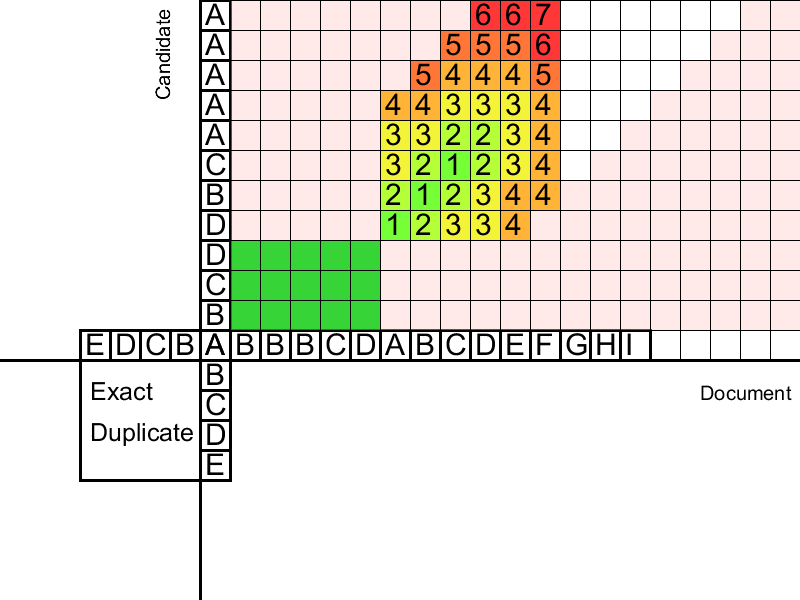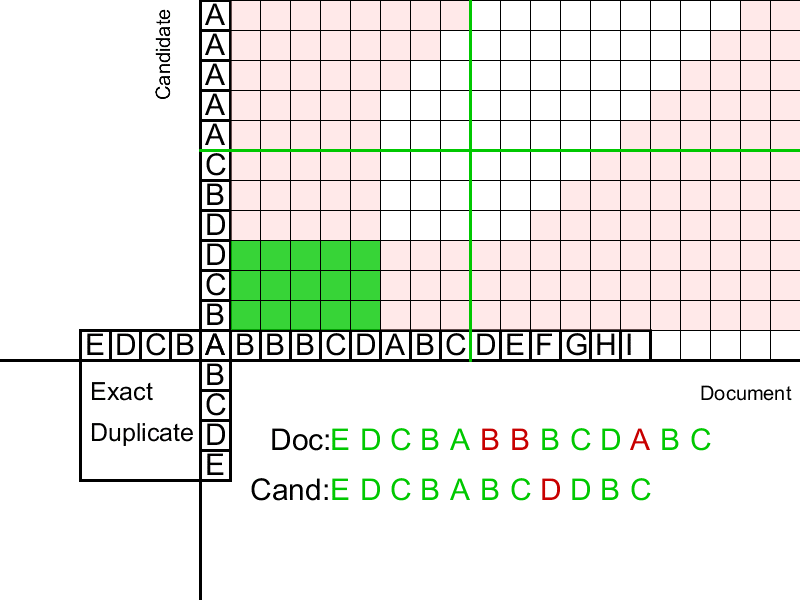
Второй этап распространяет дубликаты влево и вправо по документу. Распространение происходит от «центров» — найденных четких дубликатов. Для сравнения суффиксов используем расстояние Левенштейна — минимальное количество удалений/замен/вставок слов, необходимое для приведения одной строки к другой. Дистанцию можно вычислять динамически для суффиксов дубликата, используя алгоритм Вагнера-Фишера, опирающийся на рекурсивное определение расстояния Левенштейна. Однако этот алгоритм квадратичный по сложности и не позволяет контролировать долю ошибок. Еще одной проблемой является точное определение границ дубликатов. Для решения этих вопросов мы применяем несколько прямолинейных, но, тем не менее, эффективных процедур.
На этом шаге предлагается сначала последовательно заполнять Матрицу Расстояний Левенштейна для суффиксов нечеткого дубликата (потом, аналогично, для префиксов). Поскольку мы проверяем суффиксы на «похожесть», нас интересуют только значения вблизи диагонали этой матрицы (Расстояние Левенштейна больше либо равно разности длин строк). Это позволяет добиться линейной сложности. Задав максимально допустимое расстояние Левенштейна, будем заполнять таблицу, пока не встретим столбец со значениями больше допустимых. Такой столбец сигнализирует о том, что наш нечеткий дубликат недавно закончился и слова практически полностью перестали совпадать. Заранее сохранив для каждой заполненной клетки предыдущую оптимальную, спускаемся из клетки с минимальным в критическом столбце штрафом, пока не встретим несколько совпадений, после которых ошибка начала резко расти. Это и будут границы найденного нечеткого дубликата.
Дополнительно, чтобы ошибки не накапливались, вводится процедура, которая сбрасывает число ошибок, начиная распространение заново, если мы наткнулись на «островок» из последовательных совпадений.
Банда преступников
— Завтра с одногруппниками планируем собраться!
— В одного большого одногруппника?
— Что?
© Bashorg
Нечеткому Поиску осталась несложная задачка: объединить преступников, пойманных в одном и том же месте, в банды, оправдать невиновных подозреваемых и собрать полученные результаты воедино.

Источник изображения: pixabay.com
Склейка дубликатов решает сразу 3 проблемы. Во-первых, второй этап «распространение дубликатов» поглощает модификации слов и словосочетаний, но не целых предложений. Если увеличить «способность распространения» алгоритма, то он начнет распространятся по случайно найденным совпадениям и на слишком большое расстояние, а границы дубликатов будут определяться хуже. Так мы потеряем столь важный нам Precision, которым обладал четкий поиск.
Во-вторых, второй этап плохо распознает перестановку двух дубликатов. Хотелось бы, чтобы перестановка двух предложений местами образовывала фразу, близкую к исходной, но для строки из уникальных символов перестановка префикса и суффикса местами приводит к строке, максимально удаленной от исходной (в метрике Левенштейна). Получается, что второй этап при перестановке предложений находит два расположенных рядом дубликата, которые хочется объединить в один.
И третья причина — это Granularity, или Гранулярность. Гранулярность — это метрика, которая определяет усредненное количество найденных дубликатов в одном истинном заимствовании, которое мы обнаружили. Другими словами, гранулярность показывает, насколько хорошо мы находим заимствование целиком вместо нескольких частей, покрывающих его. Формальное определение гранулярности, а также определение микро-усредненной точности и полноты можно посмотреть в статье «An evaluation framework for plagiarism detection».
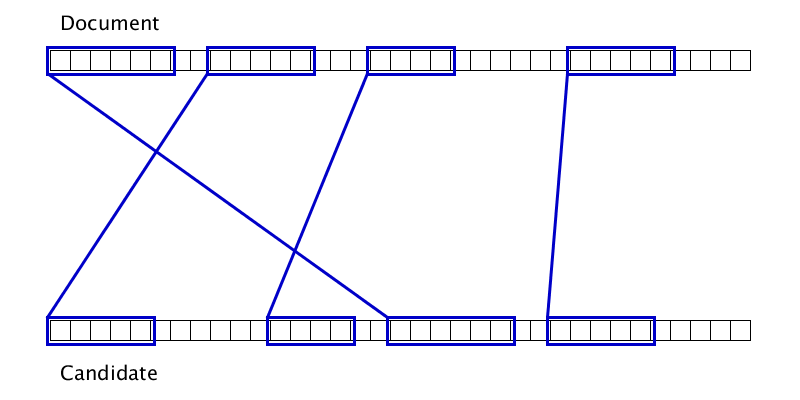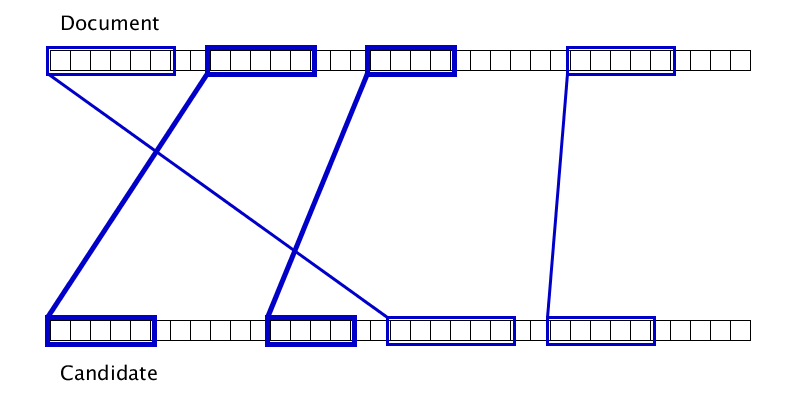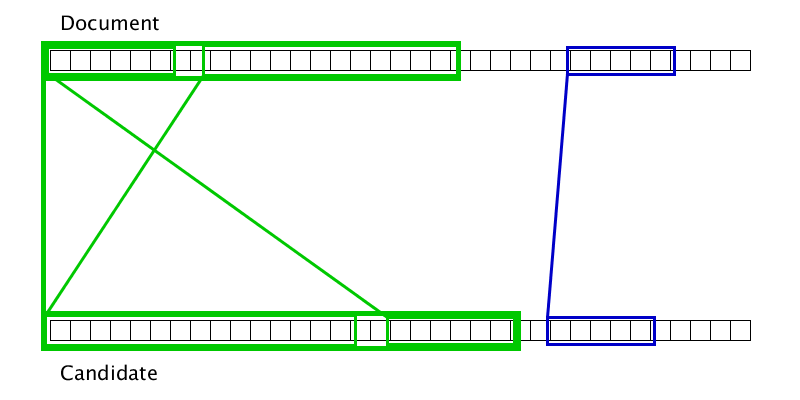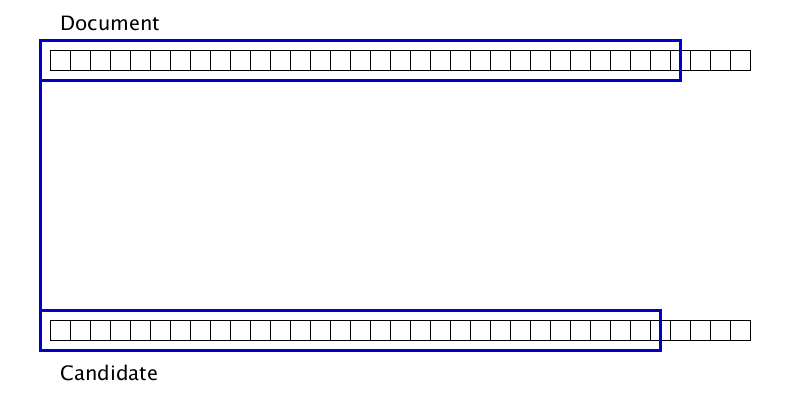
Гифка показывает, что иногда два дубликата можно склеить лишь после того, как один из них приклеится к третьему дубликату. Соответственно, просто одним проходом слева направо по документу полноценную склейку произвести не получится.
Список дубликатов на входе отсортирован по левой границе в документе.
Текущий дубликат пробуем склеить с несколькими ближайшими кандидатами перед ним.
Если получается, пробуем склеить еще раз, если нет — переходим к следующему дубликату.
Поскольку количество дубликатов не больше, чем длина документа, а каждая перепроверка уменьшает количество дубликатов на 1 и выполняется за константное время, то сложность этого алгоритма — O(n).
В качестве правила для склейки дубликатов используется набор нескольких параметров, но, если забыть про микрооптимизации качества, то мы будем склеивать те дубликаты, для которых максимум из расстояний в документе и источнике достаточно мал.
Локальность склейки обеспечивает O(1) дубликатов, к которым можно приклеить текущий дубликат.
Профессиональная подготовка новичка
Детективу необходимо было приспособиться под особенности нашего городка, адаптироваться под местность, прогуляться по неприметным улочкам и узнать получше его жителей. Для этого новичок проходит специальный курс обучения, в котором он изучает схожие ситуации на тренировочном полигоне. Детектив на практике изучает зацепки, дедукцию и построение социальных связей для максимально эффективной поимки преступников.
Параметрическую модель было необходимо оптимизировать. Для определения оптимальных параметров модели использовалась выборка PlagEvalRus.
Выборка разбита на 4 коллекции:
- Generated_Copypast (4250 пар) — дословные сгенерированные заимствования
- Generated_Paraphrased (4250 пар) — слабо и средне-модифицированные заимствования, сгенерированные машиной с помощью зашумления оригинальных отрывков (произвольные замены/удаления/вставки)
- Manually_Paraphrased (713 пар) Написанные вручную тексты с различными типами заимствований, преимущественно слабые и средне-модифицированные заимствования (заменено не более 30% слов в дубликате)
- Manually_Paraphrased 2 (198 пар) Написанные вручную тексты с средне и сильно-модифицированными (более 30% слов) заимствованиями
- DEL — Удаление отдельных слов (до 20%) из исходного предложения.
- ADD — Добавление отдельных слов (до 20%) в исходное предложение.
- LPR — Изменение форм (изменение числа, падежа, формы и времени глагола и т.п.) отдельных слов (до 30%) исходного предложения.
- SHF — Изменение порядка следования слов или частей предложения (оборотов, частей простого предложения в составе сложного) без значительных изменений «внутри» переставляемых частей.
- CCT — Склейка двух или более предложений исходного текста в одно предложение.
- SEP/SSP — Разбиение исходного сложного предложения на два или более самостоятельных предложения (возможно, с изменением порядка их следования в тексте).
- SYN — Замена отдельных слов или отдельных терминов на синонимы (например, «поваренная соль» – «хлорид натрия»), замена аббревиатур на их полные расшифровки и наоборот, раскрытие инициалов ФИО и наоборот, замена имени–отчества на инициалы и т.п.
- HPR — Сильная переработка исходного предложения, которая является комбинацией многих (3–5 и более) типов модификации текста, приведенных выше. Этот же тип предполагает сильное изменение исходного текста путем перифразы с использованием идиоматических выражений, сложных синонимических конструкций, перестановку слов или частей сложного предложения и т.п. приемы, в совокупности затрудняющие определение соответствия между источником-оригиналом и изменённым текстом.
Поиск оптимальных параметров модели мы осуществляли с помощью метода спуска с мультистартом. Максимизировалась -мера с (упор на точность). Приведем здесь наиболее значимые оптимальные параметры.
| Параметр модели | Описание | Manually_Paraphrased (более строгая модель) | Manually_Paraphrased 2 (менее строгая модель) |
|---|---|---|---|
| MinExactCiteLength | Длина четкого дубликата для 1-го этапа | 5 | 3 |
| MinSymbolCiteLength | Минимальная длины итоговой цитаты в символах | 70 | 95 |
| Limit | Максимально допустимое расстояние Левенштейна | 5 | 10 |
| MinExpandLength | Количество совпадение для обнуления штрафа распространения | 2 | 2 |
| GlueDistance | Расстояние в словах для склейки дубликатов | 11 | 29 |
| MinWordLength | Минимальная длины итоговой цитаты в словах | 10 | 11 |
Статистика раскрытых дел
Испытательный срок нашего Нечеткого Поиска подошел к концу. Давайте сравним его продуктивность с продуктивностью другого детектива, Суффиксного Массива. Тренировочный курс Нечеткий Поиск проходил по программе Manually_Paraphrased.

В полевых условиях новичок показал значительное превосходство в доле раскрытых дел. Скорость его работы также не может не радовать. В нашем агентстве не хватало такого ценного сотрудника.
Сравнивая качество модели с суффиксным массивом, заметим значительное улучшение гранулярности, а также более качественное обнаружение средне и сильно-модифицированных заимствований.
| Manually_Paraphrased | Manually_Paraphrased 2 | |
|---|---|---|
| Качество |
|
|
Тестируя на документах размером вплоть до 107 слов, убеждаемся в линейности обоих алгоритмов. На процессоре i5-4460 программа обрабатывает пару «документ-источник» длиной в миллион слов менее чем за секунду.

Сгенерировав тексты с большим числом заимствований, убеждаемся, что нечеткий поиск (синяя линия) не медленнее суффиксного массива (красная линия). Наоборот, суффиксный массив страдает на больших документах от слишком большого количества дубликатов. Мы сравнили быстродействие при минимальной длине дубликата равной 5 словам. Но для достаточного покрытия заимствованиями мы используем четкий поиск с минимальной длиной дубликата равной 3 словам, что на гигантских документах приводит к значительному падению производительности (оранжевая линия). Стоит заметить, что обычные документы содержат меньше заимствований, и на практике этот эффект выражен значительно меньше. Зато такой эксперимент позволяет понять расширение границ применимости моделей новым нечетким поиском.
Примеры:
| Оригинал | Заимствование |
|---|---|
| «За сочетание захватывающих историй с анализом человеческой натуры» в 2014 году он получил заслуженную награду — Национальную медаль США в области искусств | В 2014 году награжден Национальной медалью США в области искусств с формулировкой «за сочетание захватывающих историй с анализом человеческой натуры» |
| складываться культура тоталитаризма, где подавлялось всякое инакомыслие. Для построения социализма были поставлены следующие задачи: ликвидация безграмотности, создание системы высших учебных заведений, подготовку кадров |
Складывается культура тоталитаризма. Всякое инакомыслие подавлялось. Для достижения главной цели построения социализма были пост лены следующие задачи: 1.Культурная революция, включающая ликвидацию безграмотности, создание гигантской системы ВУЗов; НИИ, библиотек, театров, подготовку кадров |
Видно, что алгоритм, несмотря на малую вычислительную сложность, справляется с обнаружением замен/удалений/вставок, а третий шаг позволяет обнаруживать заимствования с перестановкой предложений и их частей.
Эпилог
Нечеткий Поиск работает в команде с другими нашими инструментами: Быстрым Поиском Документов-кандидатов, Извлечением Форматирования Документа, Масштабным Отловом Попыток Обхода. Такая команда позволяет быстро найти потенциальный плагиат. Нечеткий Поиск прижился в этой команде и выполняет свои поисковые функции качественнее, и, что немаловажно, быстрее, чем это делал Суффиксный Массив. Наше агентство будет еще лучше справляться со своими задачами, а недобросовестные авторы столкнутся с новыми проблемами при использовании не оригинального текста.
Творите собственным умом!
ссылка на оригинал статьи https://habr.com/ru/company/antiplagiat/blog/461903/
Добавить комментарий