
В данной статье разберемся с выравнием данных, а также решим 17-е задание с сайта pwnable.kr.
- PWN;
- криптография (Crypto);
- cетевые технологии (Network);
- реверс (Reverse Engineering);
- стеганография (Stegano);
- поиск и эксплуатация WEB-уязвимостей.
Вдобавок к этому я поделюсь своим опытом в компьютерной криминалистике, анализе малвари и прошивок, атаках на беспроводные сети и локальные вычислительные сети, проведении пентестов и написании эксплоитов.
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал канал в Telegram и группу для обсуждения любых вопросов в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации рассмотрю лично и отвечу всем.
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Выравнивание данных
Выравнивание данных в оперативной памяти компьютера представляет собой особой размещение данных в памяти для ускорения доступа. При работе с памятью процессы в качестве основной единицы используют машинное слово. У различных видов процессоров оно можем быть разного размера: один, два, четыре, восемь и т.д. байтов. При сохранении объектов в памяти может получиться так, что некоторое поле выйдет за пределы этих границ слов. Некоторые процессоры могут работать с невыровненными данными более длительное время, чем с выравненными. А неторые процессоры вообще не могут работать с невыравненными данными.
Для того, чтобы лучше представить себе модель выровненных и невыровненных данных, рассмотрим пример на следующем объекте — структура Data.
struct Data{ int var1; void* mas[4]; };Так как размер переменной типа int в x32 и x64 процессорах не равно 4 байта, а значение переменной типа void* — 4 и 8 байт соответственно, то в памяти данная структура для процессоров x32 и x64 будет представлена следующим образом.

Процессоры x64 с такой структорой работать не будут, так как данные не выравнены. Для выравнивания данных необходимо добавить в структуру еще одно поле 4 байт.
struct Data{ int var1; int addition; void* mas[4]; };Таким образом данные структуры Data для процессоров x64 будут выровнены в памяти.

Решение задания memcpy
Нажимаем на иконку с подписью memcpy, и нам говорят, что нужно подключиться по SSH с паролем guest.
// compiled with : gcc -o memcpy memcpy.c -m32 -lm #include <stdio.h> #include <string.h> #include <stdlib.h> #include <signal.h> #include <unistd.h> #include <sys/mman.h> #include <math.h> unsigned long long rdtsc(){ asm("rdtsc"); } char* slow_memcpy(char* dest, const char* src, size_t len){ int i; for (i=0; i<len; i++) { dest[i] = src[i]; } return dest; } char* fast_memcpy(char* dest, const char* src, size_t len){ size_t i; // 64-byte block fast copy if(len >= 64){ i = len / 64; len &= (64-1); while(i-- > 0){ __asm__ __volatile__ ( "movdqa (%0), %%xmm0\n" "movdqa 16(%0), %%xmm1\n" "movdqa 32(%0), %%xmm2\n" "movdqa 48(%0), %%xmm3\n" "movntps %%xmm0, (%1)\n" "movntps %%xmm1, 16(%1)\n" "movntps %%xmm2, 32(%1)\n" "movntps %%xmm3, 48(%1)\n" ::"r"(src),"r"(dest):"memory"); dest += 64; src += 64; } } // byte-to-byte slow copy if(len) slow_memcpy(dest, src, len); return dest; } int main(void){ setvbuf(stdout, 0, _IONBF, 0); setvbuf(stdin, 0, _IOLBF, 0); printf("Hey, I have a boring assignment for CS class.. :(\n"); printf("The assignment is simple.\n"); printf("-----------------------------------------------------\n"); printf("- What is the best implementation of memcpy? -\n"); printf("- 1. implement your own slow/fast version of memcpy -\n"); printf("- 2. compare them with various size of data -\n"); printf("- 3. conclude your experiment and submit report -\n"); printf("-----------------------------------------------------\n"); printf("This time, just help me out with my experiment and get flag\n"); printf("No fancy hacking, I promise :D\n"); unsigned long long t1, t2; int e; char* src; char* dest; unsigned int low, high; unsigned int size; // allocate memory char* cache1 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); char* cache2 = mmap(0, 0x4000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); src = mmap(0, 0x2000, 7, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0); size_t sizes[10]; int i=0; // setup experiment parameters for(e=4; e<14; e++){ // 2^13 = 8K low = pow(2,e-1); high = pow(2,e); printf("specify the memcpy amount between %d ~ %d : ", low, high); scanf("%d", &size); if( size < low || size > high ){ printf("don't mess with the experiment.\n"); exit(0); } sizes[i++] = size; } sleep(1); printf("ok, lets run the experiment with your configuration\n"); sleep(1); // run experiment for(i=0; i<10; i++){ size = sizes[i]; printf("experiment %d : memcpy with buffer size %d\n", i+1, size); dest = malloc( size ); memcpy(cache1, cache2, 0x4000); // to eliminate cache effect t1 = rdtsc(); slow_memcpy(dest, src, size); // byte-to-byte memcpy t2 = rdtsc(); printf("ellapsed CPU cycles for slow_memcpy : %llu\n", t2-t1); memcpy(cache1, cache2, 0x4000); // to eliminate cache effect t1 = rdtsc(); fast_memcpy(dest, src, size); // block-to-block memcpy t2 = rdtsc(); printf("ellapsed CPU cycles for fast_memcpy : %llu\n", t2-t1); printf("\n"); } printf("thanks for helping my experiment!\n"); printf("flag : ----- erased in this source code -----\n"); return 0; }
При подключении мы видим соответствующий баннер.
Давайте узнаем, какие файлы есть на сервере, а также какие мы имеем права.

У нас имеется файл readme. Прочитав его, узнаем, что программа работает на порте 9022.

Подключимся к порту 9022. Нам предлагают эксперимент — сравнить медленную и быструю версию memcpy. Далее программа провесит ввести число в определенном промежутке и выдает отчет о сравнении медленной и быстрой версии функции. Есть одно но: экспериментов 10, а отчетов — 5.
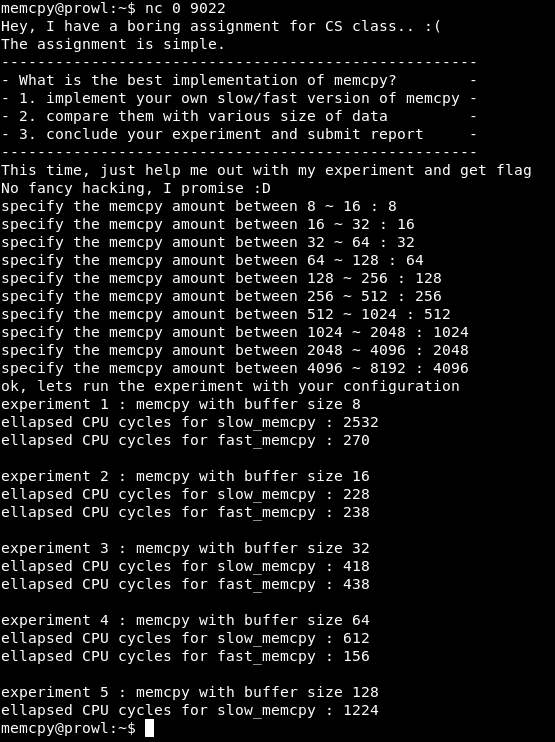
Давайте рабираться почему. Найдем в коде место сравнения результатов.
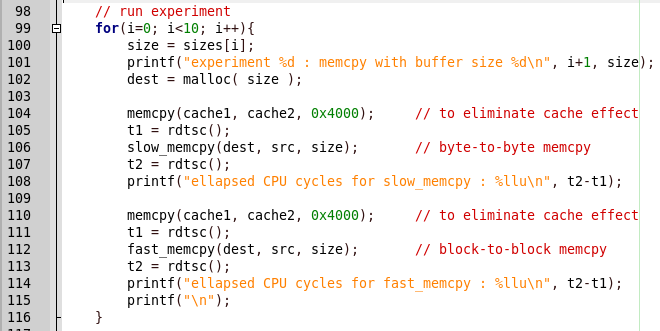
Все просто, сначала вызывается slow_memcpy, потом — fast_memcpy. Но в отчете программы есть вывод о медленной релизации функции, а при вызове быстрой реалиации — программа падает. Посмотрим код быстрой реалиации.
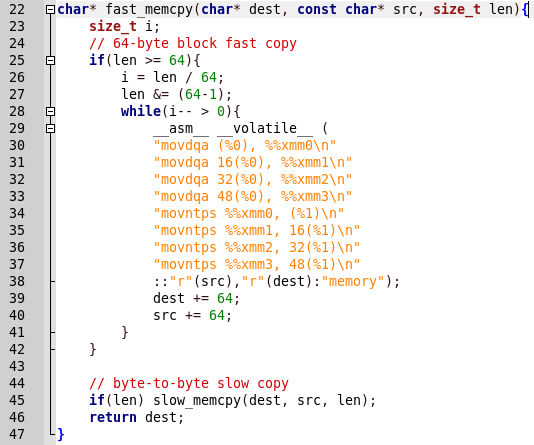
Копирование выполняется с помощью ассемблерных функций. По командам определяем, что это SSE2. Как сказано тут: SSE2 использует восемь 128-битных регистров (xmm0 до xmm7), включённых в архитектуру x86 с вводом расширения SSE, каждый из которых трактуется как 2 последовательных значения с плавающей точкой двойной точности. Тем более, в данном коде ведется работа с выровнеными данными.


Таким образом, работая с невыровненнымми данными, программа может упасть. Выравнивание производится по 128 бит, то есть по 16 байт, значит блоки должны быть равны 16. Нам нужно узнать сколько байт уже есть в первом блоке на куче (пусть X) тогда мы должны каждый передавать программу столько байт (пусть Y), чтобы (X+Y)%16 было равно 0.
Так как все операции занимают блоки кучи, кратные двум, переберем X как 2, 4, 8, т.д. до 16.
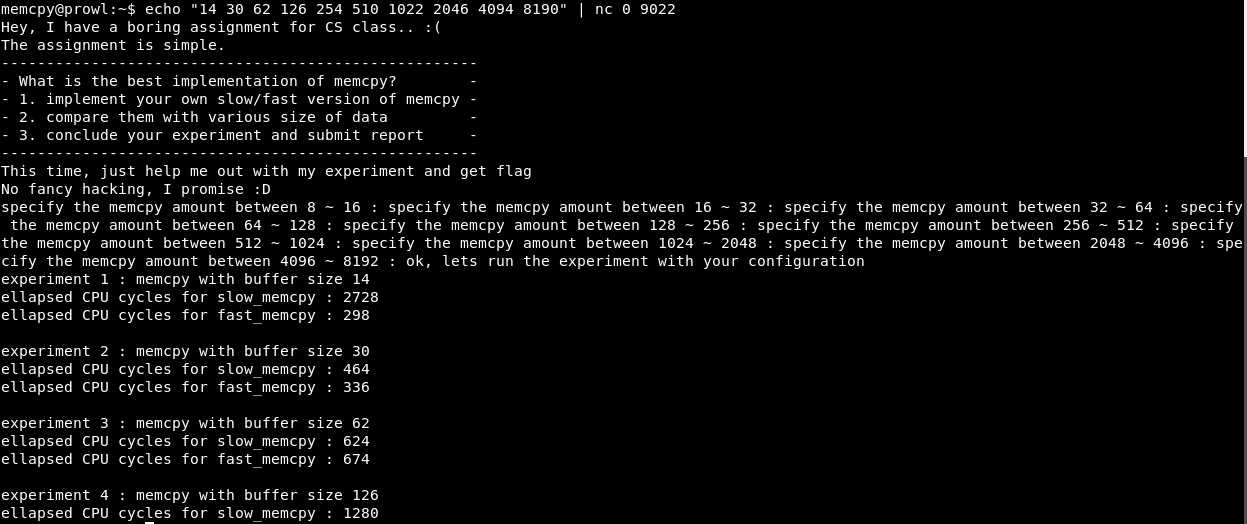
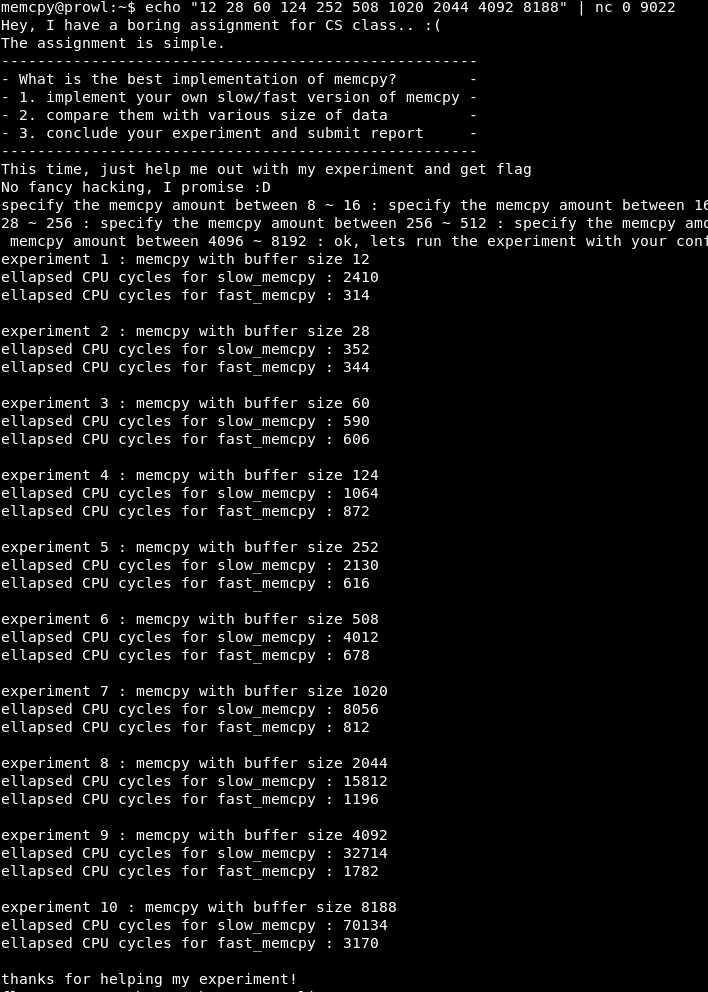
Как видим, при X=4 программа успешно выполняется.

Получаем шелл, читаем флаг, получаем 10 очков.
Вы можете присоединиться к нам в Telegram. В следующий раз разберемся с переполнением кучи.
ссылка на оригинал статьи https://habr.com/ru/post/462895/
Добавить комментарий