
В этой статье я хочу предложить альтернативу традиционному стилю дизайна тестов, используя концепции функционального программирования в Scala. Подход был навеян многомесячной болью от поддержки десятков и сотен падающих тестов и жгучим желанием сделать их проще и понятнее.
Несмотря на то, что код написан на Scala, предлагаемые идеи будут актуальны для разработчиков и тестировщиков на всех языках, поддерживающих парадигму функционального программирования. Ссылку на Github с полным решением и примером вы сможете найти в конце статьи.
Проблема
Если вы когда-либо имели дело с тестами (не важно — юнит-тестами, интеграционными или функциональными), скорее всего они были написаны в виде набора последовательных инструкций. К примеру:
// Данные тесты описывают простой магазин. В зависимости от совокупности // своей роли, количества бонусов и общей стоимости заказа, пользователь // может получить скидку разного размера. "Если роль покупателя = 'customer'" - { import TestHelper._ "И общая сумма покупки < 250 после вычета бонусов - нет скидки" in { val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40) val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1) result shouldBe 90 } "И общая сумма покупки >= 250 после вычета бонусов - скидка 10%" in { val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 100) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 120) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 130) insertBonus(db, id = 1, packageId = 1, bonusAmount = 40) val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1) result shouldBe 279 } } "Если роль покупателя = 'vip'" - {/*...*/}
Это предпочтительный для большинства, не требующий освоения, способ описания тестов. В нашем проекте около 1000 тестов разных уровней (юнит-тестов, интеграционных, end-to-end), и все они, до недавнего времени, были написаны в подобном стиле. По мере роста проекта, мы начали ощущать значительные проблемы и замедление при поддержке таких тестов: приведение тестов в порядок занимало не меньше времени, чем написание бизнес-значимого кода.
При написании новых тестов всегда приходилось придумывать с нуля, как подготовить данные. Зачастую копипастой шагов из соседних тестов. Как следствие, когда изменялась модель данных в приложении, карточный домик рассыпался и приходилось собирать его по-новой в каждом тесте: в лучшем случае, всего лишь изменением функций-хелперов, в худшем — глубоким погружением в тест и его переписыванием.
Когда тест падал честно — т. е. из-за бага в бизнес-логике, а не из-за проблем в самом тесте — понять, где что-то пошло не так, без дебага было невозможно. Из-за того, что в тестах нужно было долго разбираться, никто в полной мере не обладал знаниями о требованиях — каким образом система должна себя вести при определенных условиях.
Вся эта боль — симптомы двух более глубоких проблем такого дизайна:
- Содержимое теста допускается в слишком свободной форме. Каждый тест уникален, как снежинка. Необходимость вчитываться в детали теста занимает массу времени и демотивирует. Не важные подробности отвлекают от главного — требования, проверяемого тестом. Копипаста становится основным способом написания новых тест-кейсов.
- Тесты не помогают разработчику локализовать баги, а только сигнализируют о какой-то проблеме. Чтобы понять состояние, на котором выполняется тест, нужно восстанавливать его в голове или подключаться дебаггером.
Моделирование
Можем ли мы сделать лучше? (Спойлер: можем.) Давайте рассмотрим, из чего состоит этот тест.
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Тестируемый код, как правило, будет ждать на вход некие явные параметры — идентификаторы, размеры, объемы, фильтры и т. п. Также зачастую ему будут необходимы и данные из реального мира — мы видим, что для получения меню и шаблонов меню приложение обращается к базе данных. Для надежного выполнения теста нам понадобится фикстура (fixture) — состояние, в котором должна находиться система и/или провайдеры данных до запуска теста и входные параметры, нередко связанные с состоянием.
Этой фикстурой мы подготовим зависимость (dependency) — наполним базу данных (очередь, внешний сервис и т. п.). Подготовленной зависимостью мы инициализируем тестируемый класс (сервисы, модули, репозитории, т. п.).
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
Исполнив тестируемый код на некоторых входных параметрах, мы получим бизнес-значимый результат (output) — как явный (возвращенный методом), так и неявный — изменение пресловутого состояния: базы данных, внешнего сервиса и т. д.
result shouldBe 90
Наконец, мы проверим, что результаты оказались ровно такими, какими ожидали, подводя итог теста одной или несколькими проверками (assertion).
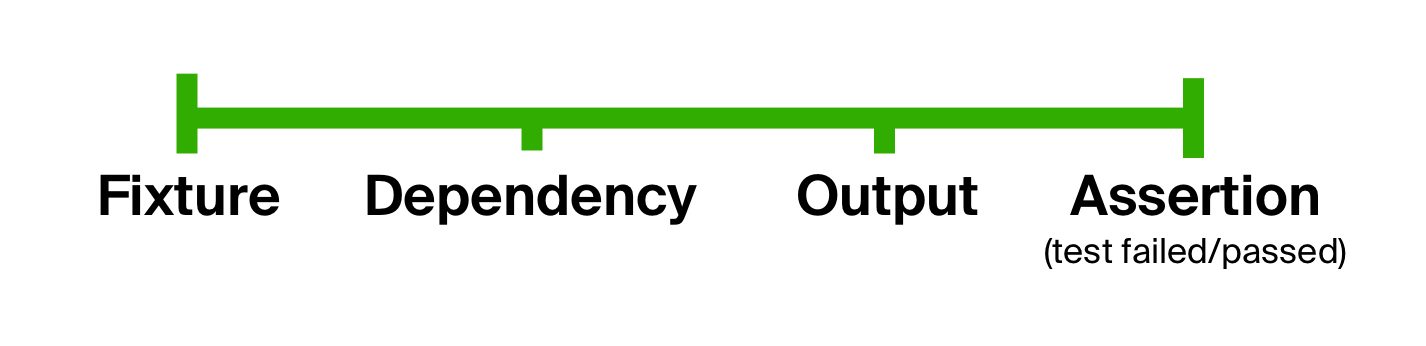
Можно прийти к выводу, что в целом тест состоит из одних и тех же стадий: подготовки входных параметров, выполнения на них тестируемого кода и сравнения результатов с ожидаемыми. Мы можем использовать этот факт, чтобы избавиться от первой проблемы в тесте — слишком свободной формы, явно разделив тест на стадии. Эта идея не нова и уже давно применяется в тестах в BDD-стиле (behavior-driven development).
Что насчет расширяемости? Любой из шагов процесса тестирования может содержать в себе сколько угодно промежуточных. Забегая вперед, мы могли бы формировать фикстуру, создавая сначала некую человекочитаемую структуру, а потом конвертировать ее в объекты, которыми наполняется БД. Процесс тестирования бесконечно расширяем, но, в конечном счете, всегда сводится к основным стадиям.

Запуск тестов
Попробуем воплотить идею разделения теста на стадии, но сначала определим, каким бы мы хотели видеть конечный результат.
В целом, нам хочется сделать написание и поддержку тестов менее трудозатратным и более приятным процессом. Чем меньше в теле теста явных неуникальных (повторящихся где-то еще) инструкций, тем меньше изменений нужно будет вносить в тесты после изменения контрактов или рефакторинга и тем меньше времени понадобится на прочтение теста. Дизайн теста должен подталкивать к переиспользованию часто используемых кусков кода и препятствовать бездумному копированию. Неплохо было бы, если бы тесты имели унифицированный вид. Предсказуемость улучшает читаемость и экономит время — представьте, как много времени бы уходило у студентов-физиков на освоение каждой новой формулы, если бы они были описаны словами в свободной форме, а не математическим языком.
Таким образом, наша цель — скрыть все отвлекающее и лишнее, оставив на виду только критически важную для понимания приложения информацию: что тестируется, что ожидается на входе, а что — на выходе.
Вернемся к модели устройства теста. Технически каждую точку на этом графике может представлять тип данных, а переходы из одной в другую — функции. Прийти от начального типа данных к конечному можно, поочередно применяя последующую функцию к результату предыдущей. Иными словами, используя композицию функций: подготовки данных (назовем ее prepare), исполнения тестируемого кода (execute) и проверки ожидаемого результата (check). На вход этой композиции мы передадим первую точку графика — фикстуру. Получившуюся функцию высшего порядка назовем функцией жизненного цикла теста.
def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] = // В Scala вместо того, чтобы писать check(execute(prepare(fixture))) // можно использовать более читабельный вариант с функцией andThen: (prepare andThen execute andThen check) (fixture)
Встает вопрос, откуда возьмутся внутренние функции? Готовить данные мы будем ограниченным количеством способов — наполнять базу, мокать, т. п. — поэтому варианты функции prepare будут общие для всех тестов. Как следствие, проще будет сделать специализированные функции жизненного цикла, скрывающие в себе конкретные реализации подготовки данных. Поскольку способы вызова проверяемого кода и проверки — относительно уникальные для каждого теста, execute и check будут подаваться явно.
// Наполнить базу фикстурой — имплементируется отдельно под приложение def prepareDatabase[DB](db: Database): DbFixture => DB def testInDb[DB, OUT]( fixture: DbFixture, execute: DB => OUT, check: OUT => Future[Assertion], db: Database = getDatabaseHandleFromSomewhere(), ): Future[Assertion] = runTestCycle(fixture, prepareDatabase(db), execute, check)
Делегируя все административные нюансы в функцию жизненного цикла, мы получаем возможность расширять процесс тестирования, не влезая ни в один уже написанный тест. За счет композиции мы можем внедряться в любую точку процесса, извлекать или добавлять туда данные.
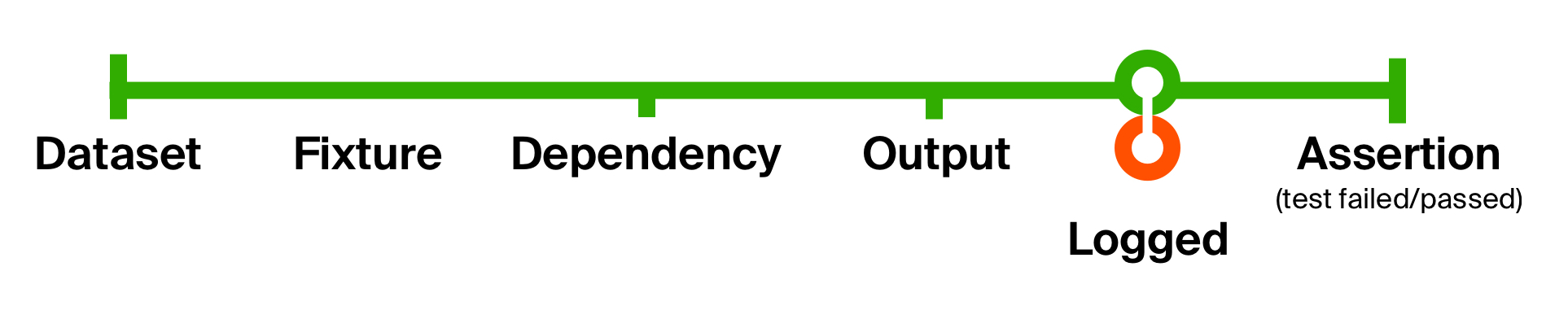
Чтобы лучше проиллюстрировать возможности такого подхода, решим вторую проблему нашего изначального теста — отсутствие вспомогательной информации для локализации проблем. Добавим логирование при получении ответа от тестируемого метода. Наше логирование не будет изменять тип данных, а лишь будет производить сайд-эффект — вывод сообщения на консоль. Поэтому после сайд-эффекта мы вернем его как есть.
def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => { // Передавая в качестве аргумента инстанс тайпкласса Logged для T, // мы получаем возможность “добавить” абстрактному that поведение log(). // Подробнее о тайпклассах - дальше. loggedT.log(that) // Существует продвинутый вариант записи: that.log() that // объект возвращается неизменным } def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] )(implicit loggedOut: Logged[OUT]): F[Assertion] = // Внедряем logged сразу после получения результата - после execute (prepare andThen execute andThen logged andThen check) (fixture)
Вот таким простым движением мы добавили логирование возвращаемого результата и состояния базы в каждом тесте. Преимущество таких маленьких функций в том, что их легко понимать, легко композировать для переиспользования и легко избавиться, если они станут не нужны.

В результате наш тест будет выглядеть следующим образом:
val fixture: SomeMagicalFixture = ??? // Объявлен где-то в другом месте def runProductionCode(id: Int): Database => Double = (db: Database) => new SomeProductionLogic(db).calculatePrice(id) def checkResult(expected: Double): Double => Future[Assertion] = (result: Double) => result shouldBe expected // Создание и наполнение Database скрыто в testInDb "Если роль покупателя = 'customer'" in testInDb( state = fixture, execute = runProductionCode(id = 1), check = checkResult(90) )
Тело теста стало немногословным, фикстуру и проверки можно переиспользовать в других тестах, и мы больше нигде вручную не подготавливаем базу данных. Остается лишь одна проблема…
Подготовка фикстур
В коде выше мы использовали предположение, что фикстура уже откуда-то возьмется в готовом виде и ее лишь нужно будет передать в функцию жизненного цикла. Поскольку данные — ключевой ингредиент простых и поддерживаемых тестов, мы не можем не коснуться того, как их формировать.
Предположим, у нашего тестируемого магазина есть типичная БД среднего размера (для простоты примера с 4 таблицами, но в реальности их могут быть сотни). Часть содержит справочную информацию, часть —непосредственно бизнесовую, и все вместе это можно связать в несколько полноценных логических сущностей. Таблицы связаны между собой ключами (foreign keys) — чтобы создать сущность Bonus, потребуется сущность Package, а ей в свою очередь — User. И так далее.

Обходы ограничений схемы и всяческие хаки ведут к неконсистентности и, как следствие, к нестабильности тестов и часам увлекательного дебага. По этой причине мы будем наполнять базу по-честному.
Мы могли бы использовать боевые методы для наполнения, но даже при поверхностном рассмотрении этой идеи возникает много непростых вопросов. Что будет готовить данные в тестах на сами эти методы? Нужно ли будет переписывать тесты, если поменяется контракт? Что делать, если данные доставляются вообще не тестируемым приложением (например, импортом кем-то еще)? Как много различных запросов придется сделать, чтобы создать сущность, зависимую от многих других?
insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
Разрозненные хелпер-методы, как в изначальном примере — это та же проблема, но под другим соусом. Они возлагают ответственность по управлению зависимыми объектами и их связями на нас самих, а нам бы хотелось этого избежать.
В идеале, хотелось бы иметь такой тип данных, одного взгляда на который достаточно, чтобы в общих чертах понять, в каком состоянии будет находиться система во время теста. Одним из неплохих кандидатов для визуализации состояния является таблица (а-ля датасеты в PHP и Python), где нет ничего лишнего, кроме критичных для бизнес-логики полей. Если в фиче изменится бизнес-логика, вся поддержка тестов сведется к актуализации ячеек в датасете. Например:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
Из нашей таблицы, мы сформируем ключи — связи сущностей по ID. При этом, если сущность зависит от другой, сформируется ключ и для зависимости. Может случиться так, что две разные сущности сгенерируют зависимость с одинаковым идентификатором, что может привести к нарушению ограничения по первичному ключу БД (primary key). Но на этом этапе данные предельно дешево дедуплицировать — поскольку ключи содержат только идентификаторы, мы можем сложить их в коллекцию, обеспечивающую дедупликацию, например в Set. Если этого окажется недостаточно, мы всегда можем сделать более умную дедупликацию в виде дополнительной функции, скомпозированной в функцию жизненного цикла.
sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
Генерацию фейкового наполнения полей (например, имен) мы делегируем отдельному классу. Затем, прибегая к помощи этого класса и правил конвертации ключей, мы получим объекты-строки, предназначенные непосредственно для вставки в базу.
object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
Дефолтных фейковых данных, как правило, нам будет недостаточно, поэтому нужно будет иметь возможность переопределить конкретные поля. Мы можем воспользоваться линзами — пробегать по всем созданным строкам и менять поля только тех, которых нужно. Поскольку линзы в итоге — это обычные функции, их можно композировать, и в этом заключается их полезность.
def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
Благодаря композиции, внутри всего процесса мы сможем применить различные оптимизации и улучшения — к примеру, сгруппировать строки по таблицам, чтобы вставлять их одним insert’ом, уменьшая время прохождения тестов, или залогировать конечное состояние БД для упрощения отлова проблем.
def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
Все вместе даст нам фикстуру, которая наполнит зависимость для теста — базу данных. В самом тесте при этом не будет видно ничего лишнего, кроме изначального датасета — все подробности будут скрыты внутри композиции функций.

Наш тест-сьют теперь будет выглядеть следующим образом:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) "Если роль покупателя -" - { "'customer'" - { "И общая сумма покупки" - { "< 250 после вычета бонусов - нет скидки" - { "(кейс: нет бонусов)" in calculatePriceFor(dataTable, 1) "(кейс: есть бонусы)" in calculatePriceFor(dataTable, 3) } ">= 250 после вычета бонусов" - { "Если нет бонусов - скидка 10% от суммы" in calculatePriceFor(dataTable, 2) "Если есть бонусы - скидка 10% от суммы после вычета бонусов" in calculatePriceFor(dataTable, 4) } } } "'vip' - то применяется скидка 20% к сумме покупки до вычета бонусов, а потом применяются все остальные скидочные правила" in calculatePriceFor(dataTable, 5) }
А вспомогательный код:
// Переиспользованное тело теста def calculatePriceFor(table: Seq[DataRow], idx: Int) = testInDb( state = makeState(table.row(idx)), execute = runProductionCode(table.row(idx)._1), check = checkResult(table.row(idx)._5) ) def makeState(row: DataRow): Logger => DbFixture = { val items: Map[Int, Int] = ((1 to row._3.length) zip row._3).toMap val bonuses: Map[Int, Int] = ((1 to row._4.length) zip row._4).toMap MyFixtures.makeFixture( state = PackageRelationships .minimal(id = row._1, userId = 1) .withItems(items.keys) .withBonuses(bonuses.keys), overrides = changeRole(userId = 1, newRole = row._2) andThen items.map { case (id, newPrice) => changePrice(id, newPrice) }.foldPls andThen bonuses.map { case (id, newBonus) => changeBonus(id, newBonus) }.foldPls ) } def runProductionCode(id: Int): Database => Double = (db: Database) => new SomeProductionLogic(db).calculatePrice(id) def checkResult(expected: Double): Double => Future[Assertion] = (result: Double) => result shouldBe expected
Добавление новых тест-кейсов в таблицу становится тривиальной задачей, что позволяет сконцентрироваться на покрытии максимального числа граничных условий, а не на бойлерплейте.
Переиспользование кода подготовки фикстур на других проектах
Хорошо, мы написали много кода для подготовки фикстур в одном конкретном проекте, потратив на это немало времени. Что, если у нас несколько проектов? Обречены ли мы каждый раз переизобретать велосипед и копипастить?
Мы можем абстрагировать подготовку фикстур от конкретной доменной модели. В мире ФП существует концепция тайпкласса (typeclass). Если коротко, тайпклассы — это не классы из ООП, а нечто вроде интерфейсов, они определяют некое поведение группы типов. Принципиальное различие в том, что эта группа типов определяется не наследованием классами, а инстанцированием, как обычные переменные. Так же, как с наследованием, резолвинг инстансов тайпклассов (через имплиситы) происходит статически, на этапе компиляции. Для простоты в наших целях, тайпклассы можно воспринимать как расширения (extensions) из Kotlin и C#.
Чтобы залогировать объект, нам не нужно знать, что у этого объекта внутри, какие у него поля и методы. Нам важно лишь, чтобы для него было определено поведение log с определенной сигнатурой. Имплементировать некий интерфейс Logged в каждом классе было бы трудозатратно, да и не всегда возможно — например, у библиотечных или стандартных классов. В случае с тайпклассами все намного проще. Мы можем создать инстанс тайпкласса Logged, например, для фикстуры, и вывести ее в удобочитаемом виде. А для всех остальных типов создать инстанс для типа Any и использовать стандартный метод toString, чтобы бесплатно логировать любые объекты в своем внутреннем представлении.
trait Logged[A] { def log(a: A)(implicit logger: Logger): A } // Для всех Future implicit def futureLogged[T]: Logged[Future[T]] = new Logged[Future[T]] { override def log(futureT: Future[T])(implicit logger: Logger): Future[T] = { futureT.map { t => // map на Future позволяет вмешаться в ее результат после того, как она // выполнится logger.info(t.toString()) t } } } // Фоллбэк, если в скоупе не нашлись другие имплиситы implicit def anyNoLogged[T]: Logged[T] = new Logged[T] { override def log(t: T)(implicit logger: Logger): T = { logger.info(t.toString()) t } }
Кроме логирования, мы можем расширить этот подход на весь процесс подготовки фикстур. Решение для тестов будет предлагать свои тайпклассы и абстрактную имплементацию функций на их основе. Ответственность использующего его проекта — написать свои инстансы тайпклассов для типов.
// Функция формирования фикстуры def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state) override def extractKeys(implicit toKeys: ToKeys[DbState]): DbState => Set[Key] = (db: DbState) => db.toKeys() override def enrichWithSampleData(implicit enrich: Enrich[Key]): Key => Set[Row] = (key: Key) => key.enrich() override def buildFixture(implicit insert: Insertable[Set[Row]]): Set[Row] => DbFixture = (rows: Set[Row]) => rows.insert() // Тайпклассы, описывающие разбиение чего-то (например, датасета) на ключи trait ToKeys[A] { def toKeys(a: A): Set[Key] // Something => Set[Key] } // ...конвертацию ключей в строки trait Enrich[A] { def enrich(a: A): Set[Row] // Set[Key] => Set[Row] } // ...и вставку строк в базу trait Insertable[A] { def insert(a: A): DbFixture // Set[Row] => DbFixture } // Имплементируем инстансы в конкретном проекте (см. в примере в конце статьи) implicit val toKeys: ToKeys[DbState] = ??? implicit val enrich: Enrich[Key] = ??? implicit val insert: Insertable[Set[Row]] = ???
При проектировании генератора фикстур, я ориентировался на выполнение принципов программирования и проектирования SOLID как на индикатор его устойчивости и адаптируемости к разным системам:
- Принцип единственной ответственности (The Single Responsibility Principle): каждый тайпкласс описывает ровно один аспект поведения типа.
- Принцип открытости/закрытости (The Open Closed Principle): мы не модифицируем существующий боевой тип для тестов, мы расширяем его инстансами тайпклассов.
- Принцип подстановки Лисков (The Liskov Substitution Principle) в данном случае не имеет значения, поскольку мы не используем наследование.
- Принцип разделения интерфейса (The Interface Segregation Principle): мы используем много специализированных тайпклассов вместо одного глобального.
- Принцип инверсии зависимостей (The Dependency Inversion Principle): реализация генератора фикстур зависит не от конкретных боевых типов, а от абстрактных тайпклассов.
Убедившись в выполнении всех принципов, можно утверждать, что наше решение выглядит достаточно поддерживаемо и расширяемо, чтобы пользоваться им в разных проектах.
Написав функции жизненного цикла, генерации фикстур и преобразования датасетов в фикстуры, а также абстрагировавшись от конкретной доменной модели приложения, мы, наконец, готовы масштабировать наше решение на все тесты.
Итоги
Мы перешли от традиционного (пошагового) стиля дизайна тестов к функциональному. Пошаговый стиль хорош на ранних этапах и небольших проектах тем, что не требует дополнительных трудозатрат и не ограничивает разработчика, но начинает проигрывать, когда тестов на проекте становится достаточно много. Функциональный стиль не призван решить все проблемы в тестировании, но позволяет значительно облегчить масштабирование и поддержку тестов в проектах, где их количество исчисляется сотнями или тысячами. Тесты в функциональном стиле получаются компактнее и фокусируются на том, что действительно важно (данные, тестируемый код и ожидаемый результат), а не на промежуточных шагах.
Кроме того, мы рассмотрели на живом примере, насколько мощными являются концепции композирования и тайпклассов в функциональном программировании. С их помощью легко проектировать решения, неотъемлемой частью которых являются расширяемость и переиспользуемость.
После нескольких месяцев эксплуатации можно сказать, что хоть команде и потребовалось некоторое время на то, чтобы привыкнуть к новым тестам, она осталась довольна результатом. Новые тесты пишутся быстрее, логи упрощают жизнь, а к датасетам удобно обращаться, когда возникают вопросы по корнер-кейсам. Мы стремимся к тому, чтобы постепенно перевести все тесты на новый стиль. Приятного вам тестирования!
Ссылка на решение и пример: Github
ссылка на оригинал статьи https://habr.com/ru/company/2gis/blog/463623/
Добавить комментарий