
Конкурсные работы публиковались в открытых твитах и личными сообщениями, которые содержали только байты PRG-файла и хэш MD5.
Список участников со ссылками на исходный код:
- Филип Херон (код — 34 байта, победитель)
- Гейр Страуме (код — 34 байта)
- Петри Хаккинен (код — 37 байт)
- Матлев Раксенблатц (код — 38 байт)
- Ян Ахрениус (код — 48 байт)
- Джейми Фуллер (код — 50 байт)
- Дэвид А. Гершман (код — 53 байта)
- Янне Хеллстен (код — 56 байт)
(Если я кого-то пропустил, пожалуйста, дайте знать, я обновлю список).
Остальная часть статьи посвящена некоторым трюкам ассемблера, которые применялись в конкурсе.
Основы
ГрафикаC64 по умолчанию работает в режиме кодировки символов 40×25. Фреймбуфер в оперативной памяти разбивается на два массива:
$0400(Screen RAM, 40×25 байт)$d800(Color RAM, 40×25 байт)
Чтобы установить символ, вы сохраняете байт в экраннное ОЗУ, в $0400 (например, $0400+y*40+x). Color RAM по умолчанию инициализируется светло-синим (цвет 14): именно этот цвет мы используем для линий, то есть ОЗУ цветности можно не трогать.
Вы управляете цветами границы и фона с помощью отображённых в памяти регистров ввода-вывода, в $d020 (граница) и $d021 (фон).
Нарисовать две линии довольно легко, если напрямую запрограммировать наклон фиксированной линии. Вот реализация C, которая рисует линии и сбрасывает содержимое экрана в stdout (используется malloc(), чтобы код работал на PC):
#include <stdint.h> #include <stdio.h> #include <stdlib.h> void dump(const uint8_t* screen) { const uint8_t* s = screen; for (int y = 0; y < 25; y++) { for (int x = 0; x < 40; x++, s++) { printf("%c", *s == 0xa0 ? '#' : '.'); } printf("\n"); } } void setreg(uintptr_t dst, uint8_t v) { // *((uint8_t *)dst) = v; } int main() { // uint8_t* screenRAM = (uint_8*)0x0400; uint8_t* screenRAM = (uint8_t *)calloc(40*25, 0x20); setreg(0xd020, 0); // Set border color setreg(0xd021, 0); // Set background color int yslope = (25<<8)/40; int yf = yslope/2; for (int x = 0; x < 40; x++) { int yi = yf >> 8; // First line screenRAM[x + yi*40] = 0xa0; // Second line (X-mirrored) screenRAM[(39-x) + yi*40] = 0xa0; yf += yslope; } dump(screenRAM); } Коды экрана выше: $20 (пустой) и $a0 (заполненный блок 8×8). Если запустить, вы увидите ASCII-картинку с двумя линиями:
##....................................## ..#..................................#.. ...##..............................##... .....#............................#..... ......##........................##...... ........##....................##........ ..........#..................#.......... ...........##..............##........... .............#............#............. ..............##........##.............. ................##....##................ ..................#..#.................. ...................##................... ..................#..#.................. ................##....##................ ..............##........##.............. .............#............#............. ...........##..............##........... ..........#..................#.......... ........##....................##........ ......##........................##...... .....#............................#..... ...##..............................##... ..#..................................#.. ##....................................##
То же самое тривиально реализуется в ассемблере:
!include "c64.asm" +c64::basic_start(entry) entry: { lda #0 ; black color sta $d020 ; set border to 0 sta $d021 ; set background to 0 ; clear the screen ldx #0 lda #$20 clrscr: !for i in [0, $100, $200, $300] { sta $0400 + i, x } inx bne clrscr ; line drawing, completely unrolled ; with assembly pseudos lda #$a0 !for i in range(40) { !let y0 = Math.floor(25/40*(i+0.5)) sta $0400 + y0*40 + i sta $0400 + (24-y0)*40 + i } inf: jmp inf ; halt }Получается PRG довольно большого размера 286 байт.
Прежде чем погрузиться в оптимизации, сделаем несколько наблюдений.
Во-первых, мы работаем на C64 с заложенными подпрограммами ROM. Там куча подпрограмм, которые могут быть полезны. Например, очистка экрана с помощью JSR $E544.
Во-вторых, вычисления адресов на 8-битном процессоре типа 6502 могут быть громоздкими и съедать много байт. У этого процессора также нет множителя, поэтому вычисление вроде y*40+i обычно включает в себя либо кучу логических сдвигов, либо таблицу поиска, которая тоже съедает байты. Чтобы избежать умножения на 40, лучше продвигать экранный курсор инкрементально:
int yslope = (25<<8)/40; int yf = yslope/2; uint8_t* dst = screenRAM; for (int x = 0; x < 40; x++) { dst[x] = 0xa0; dst[(39-x)] = 0xa0; yf += yslope; if (yf & 256) { // Carry set? dst += 40; yf &= 255; } } Продолжаем добавлять наклон линии к неподвижному счётчику yf, а когда 8-битное сложение устанавливает флаг переноса, добавляем 40.
Вот инкрементальный подход на ассемблере:
!include "c64.asm" +c64::basic_start(entry) !let screenptr = $20 !let x0 = $40 !let x1 = $41 !let yf = $60 entry: { lda #0 sta x0 sta $d020 sta $d021 ; kernal clear screen jsr $e544 ; set screenptr = $0400 lda #<$0400 sta screenptr+0 lda #>$0400 sta screenptr+1 lda #80 sta yf lda #39 sta x1 xloop: lda #$a0 ldy x0 ; screenRAM[x] = 0xA0 sta (screenptr), y ldy x1 ; screenRAM[39-x] = 0xA0 sta (screenptr), y clc lda #160 ; line slope adc yf sta yf bcc no_add ; advance screen ptr by 40 clc lda screenptr adc #40 sta screenptr lda screenptr+1 adc #0 sta screenptr+1 no_add: inc x0 dec x1 bpl xloop inf: jmp inf } С 82 байтами он ещё довольно здоровенный. Одна из очевидных проблем — 16-разрядные вычисления адресов. Устанавливаем значение screenptr для косвенно-индексной адресации:
; set screenptr = $0400 lda #<$0400 sta screenptr+0 lda #>$0400 sta screenptr+1 Переводим screenptr на следующую строку добавлением 40:
; advance screen ptr by 40 clc lda screenptr adc #40 sta screenptr lda screenptr+1 adc #0 sta screenptr+1Конечно, этот код можно оптимизировать, но что, если вообще избавиться от 16-битных адресов? Давайте посмотрим, как это сделать.
Трюк 1. Прокрутка!
Вместо того, чтобы строить линию в экранном ОЗУ, рисуем только в последней экранной строке Y=24 и прокручиваем весь экран вверх, вызывая функцию прокрутки ROM с помощью JSR $E8EA!
Вот как оптимизируется xloop:
lda #0 sta x0 lda #39 sta x1 xloop: lda #$a0 ldx x0 ; hardcoded absolute address to last screen line sta $0400 + 24*40, x ldx x1 sta $0400 + 24*40, x adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: inc x0 dec x1 bpl xloopТак выглядит рендеринг:

Это один из моих любимых трюков в данной программе. Его самостоятельно обнаружили почти все участники конкурса.
Трюк 2. Самомодифицирующийся код
Код для хранения значений пикселей заканчивается примерно так:
ldx x1 ; hardcoded absolute address to last screen line sta $0400 + 24*40, x ldx x0 sta $0400 + 24*40, x inc x0 dec x1Это кодируется в следующую последовательность из 14 байт:
0803: A6 22 LDX $22 0805: 9D C0 07 STA $07C0,X 0808: A6 20 LDX $20 080A: 9D C0 07 STA $07C0,X 080D: E6 22 INC $22 080F: C6 20 DEC $20С помощью самомодифицирующегося кода (SMC) можно записать это более компактно:
ldx x1 sta $0400 + 24*40, x addr0: sta $0400 + 24*40 ; advance the second x-coord with SMC inc addr0+1 dec x1…что кодируется в 13 байт:
0803: A6 22 LDX $22 0805: 9D C0 07 STA $07C0,X 0808: 8D C0 07 STA $07C0 080B: EE 09 08 INC $0809 080E: C6 22 DEC $22
Трюк 3. Эксплуатация состояния ‘power on’
В конкурсе считалось нормальным делать дикие предположения о рабочей среде. Например, что чертёж линий — первое, что запускается после включения питания C64, и нет никаких требований к чистому выходу обратно в командную строку BASIC. Поэтому всё, что вы найдёте в начальной среде при входе в PRG, можно и нужно использовать в своих интересах:
- Регистры A, X, Y приняты за нули
- Все флаги CPU очищены
- Содержимое zeropage (адреса
$00—$ff)
Точно так же при вызове каких-то процедур KERNAL ROM можно полностью воспользоваться любыми побочными эффектами: возвращённые флаги CPU, временные значения zeropage и т. д.
После первых оптимизаций поищем что-нибудь интересное в машинной памяти:
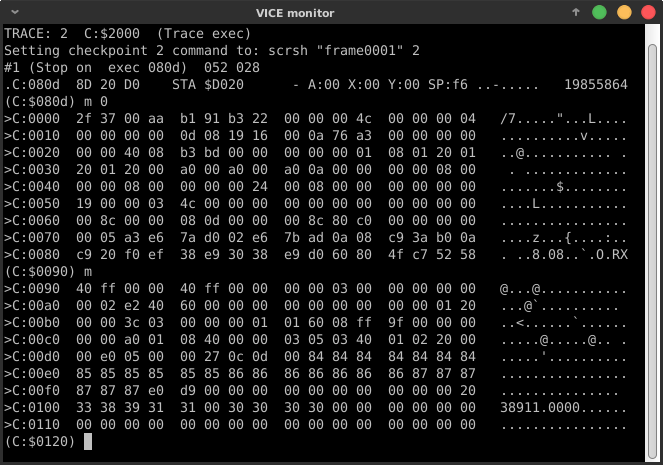
Zeropage действительно содержит некоторые полезные значения для наших целей:
$d5: 39/$27 == длина линии − 1$22: 64/$40 == начальное значение для счётчика наклона линии
Это позволит сэкономить несколько байт при инициализации. Например:
!let x0 = $20 lda #39 ; 0801: A9 27 LDA #$27 sta x0 ; 0803: 85 20 STA $20 xloop: dec x0 ; 0805: C6 20 DEC $20 bpl xloop ; 0807: 10 FC BPL $0805 Поскольку $d5 содержит значение 39, вы можете указать его счётчику x0, избавившись от пары LDA/STA:
!let x0 = $d5 ; nothing here! xloop: dec x0 ; 0801: C6 D5 DEC $D5 bpl xloop ; 0803: 10 FC BPL $0801 Победитель конкурса Филип в своём коде доводит это до крайности. Вспомним адрес последнего символа строки $07C0 (==$0400+24*40). Этого значения нет в zeropage при инициализации. Однако в качестве побочного эффекта того, как подпрограмма скроллинга из ROM использует временные значения zeropage, адреса $D1-$D2 на выходе из функции будут содержать значение $07C0. Поэтому для хранения пикселя вместо STA $07C0,x можно использовать на один байт более короткую косвенно-индексную адресацию STA ($D1),y.
Трюк 4. Оптимизация загрузки
Типичный двоичный файл C64 PRG содержит следующее:
- Первые 2 байта: адрес загрузки (обычно
$0801) - 12 байт последовательности загрузки BASIC
Основная последовательность загрузки выглядит так (адреса $801-$80C):
0801: 0B 08 0A 00 9E 32 30 36 31 00 00 00 080D: 8D 20 D0 STA $D020 Не вдаваясь в подробности о токенизированной компоновке памяти BASIC, эта последовательность более или менее соответствует ’10 SYS 2061′. Адрес 2061 ($080D) — то место, где запускается наша фактическая программа машинного кода, когда интерпретатор BASIC выполняет команду SYS.
Просто кажется, что 14 байт — это слишком много. Филип, Матлев и Гейр применили несколько хитрых трюков, чтобы полностью избавиться от основной последовательности. Это требует загрузки PRG с LOAD"*",8,1, поскольку LOAD"*",8 игнорирует адрес загрузки PRG (первые два байта) и всегда загружается в $0801.
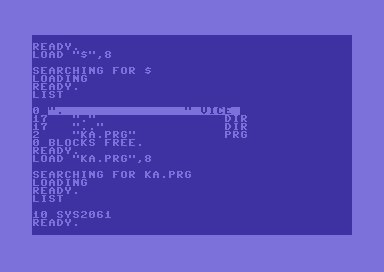
Тут использовались два метода:
- Трюк со стеком
- Трюк с «тёплым» сбросом вектора BASIC
Трюк со стеком
Хитрость заключается в том, чтобы занести в процессорный стек на $01F8 значение, которое указывает на нашу желаемую точку входа. Это делается путём создания PRG, который начинается с 16-битного указателя на наш код, и загрузки PRG в $01F8:
* = $01F8 !word scroll - 1 ; overwrite stack scroll: jsr $E8EA Как только загрузчик BASIC (см. код после дизассемблирования) закончил загрузку и хочет возвратиться к вызывающему объекту с помощью RTS, то возвращается прямо в наш PRG.
Трюк с «тёплым» сбросом вектора BASIC
Это немного легче объяснить, просто взглянув на PRG после дизассемблирования.
02E6: 20 EA E8 JSR $E8EA 02E9: A4 D5 LDY $D5 02EB: A9 A0 LDA #$A0 02ED: 99 20 D0 STA $D020,Y 02F0: 91 D1 STA ($D1),Y 02F2: 9D B5 07 STA $07B5,X 02F5: E6 D6 INC $D6 02F7: 65 90 ADC $90 02F9: 85 90 STA $90 02FB: C6 D5 DEC $D5 02FD: 30 FE BMI $02FD 02FF: 90 E7 BCC $02E8 0301: 4C E6 02 JMP $02E6 Обратите внимание на последнюю строку (JMP $02E6). Инструкция JMP начинается с $0301 с адресом перехода в $0302-$0303.
Когда этот код загружается в память, начиная с адреса $02E6, значение $02E6 записывается в адреса $0302-$0303. Ну, у этого местоположения особое значение: оно содержит указатель на «цикл ожидания BASIC» (для более подробной информации см. карту памяти C64). Загрузка PRG перезаписывает его с помощью $02E6 и поэтому, когда интерпретатор BASIC после тёплого сброса пытается перейти к циклу ожидания, то никогда не входит в этот цикл, а вместо этого попадает в программу рендеринга!
Другие трюки с запуском BASIC
Петри обнаружил ещё один трюк запуска BASIC, который позволяет вводить собственные константы в zeropage. В этом методе вы вручную создаёте собственную токенизированную последовательность запуска BASIC и кодируете константы в номерах строк программы BASIC. На входе номера строк BASIC, кхм, то есть ваши константы будут храниться в адресах $39-$3A. Очень умно!
Трюк 5. Нестандартный поток управления
Вот несколько упрощённая версия x-loop, которая выводит только одну линию, а затем останавливает выполнение:
lda #39 sta x1 xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: dec x1 bpl xloop ; intentionally halt at the end inf: jmp infНо здесь есть ошибка. Когда мы нарисовали последний пиксель, то больше НЕЛЬЗЯ прокручивать экран. Таким образом, нужны дополнительные ветвления для прекращения прокрутки после записи последнего пикселя:
lda #39 sta x1 xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x dec x1 ; skip scrolling if last pixel bmi done adc yf sta yf bcc no_scroll ; scroll screen up! jsr $e8ea no_scroll: jmp xloop done: ; intentionally halt at the end inf: jmp inf Поток управления очень похож на то, что выдаст компилятор C из структурированной программы. Код для пропуска последней прокрутки вводит новую инструкцию JMP abs, которая занимает 3 байта. Условные переходы всего по два байта, поскольку они кодируют адреса перехода с помощью относительного 8-битного операнда с непосредственной адресацией.
JMP для «пропуска последней прокрутки» можно избежать, переместив вызов прокрутки вверх в верхнюю часть цикла и немного изменив структуру потока управления. Вот как это реализовал Филип:
lda #39 sta x1 scroll: jsr $e8ea xloop: lda #$a0 ldx x1 sta $0400 + 24*40, x adc yf sta yf dec x1 ; doesn't set carry! inf: bmi inf ; hang here if last pixel! bcc xloop ; next pixel if no scroll bcs scroll ; scroll up and continueЭто полностью устраняет один трёхбайтовый JMP и преобразует другой JMP в двухбайтовый условный переход, экономя в общей сложности 4 байта.
Трюк 6. Линии со сжатием битов
Некоторые элементы не используют счётчик наклона линии, а скорее сжимают биты в 8-битную константу. Такая упаковка базируется на том, что положение пикселя вдоль линии соответствует повторяющемуся 8-пиксельному шаблону:
int mask = 0xB6; // 10110110 uint8_t* dst = screenRAM; for (int x = 0; x < 40; x++) { dst[x] = 0xA0; if (mask & (1 << (x&7))) { dst += 40; // go down a row } }Это транслируется в довольно компактный ассемблер. Однако варианты счётчика наклона, как правило, ещё меньше.
Победитель
Вот программа-победитель конкурса размером 34 байта от Филипа. В его коде хорошо сочетается большинство из вышеперечисленных трюков:
ov = $22 ; == $40, initial value for the overflow counter ct = $D5 ; == $27 / 39, number of passes. Decrementing, finished at -1 lp = $D1 ; == $07C0, pointer to bottom line. Set by the kernal scroller ; Overwrite the return address of the kernal loader on the stack ; with a pointer to our own code * = $01F8 .word scroll - 1 scroll: jsr $E8EA ; Kernal scroll up, also sets lp pointer to $07C0 loop: ldy ct ; Load the decrementing counter into Y (39 > -1) lda #$A0 ; Load the PETSCII block / black col / ov step value sta $D020, y ; On the last two passes, sets the background black p1: sta $07C0 ; Draw first block (left > right line) sta (lp), y ; Draw second block (right > left line) inc p1 + 1 ; Increment pointer for the left > right line adc ov ; Add step value $A0 to ov sta ov dec ct ; Decrement the Y counter bmi * ; If it goes negative, we're finished bcc loop ; Repeat. If ov didn't overflow, don't scroll bcs scroll ; Repeat. If ov overflowed, scroll
Но зачем останавливаться на 34 байтах?
Как только конкурс закончился, все поделились своим кодом и заметками — и прошёл ряд оживлённых дискуссий о том, как ещё его улучшить. После дедлайна было представлено ещё несколько вариантов:
Обязательно посмотрите — там есть несколько настоящих жемчужин.
Спасибо за чтение. И особая благодарность Матлеву, Филу, Гейру, Петри, Джейми, Яну и Дэвиду за участие (надеюсь, что я никого не упустил — было действительно трудно отслеживать все упоминания в твиттере!)
P. S. Петри назвал мой конкурс «ежегодным», так что, хм, наверное, увидимся в следующем году.
ссылка на оригинал статьи https://habr.com/ru/post/464377/
Добавить комментарий