Что будем выгружать?
Для аналитики динамики позиций поисковых фраз потребуется выгрузки из Яндекс.Вебмастера и Google Search Console. Для оценки «полезности» прокачивания позиции поисковой фразы будут полезны данные о частотности. Их можно получить из Яндекс.Директа и Google Ads. Ну а для анализа поведения технической стороны сайта воспользуемся Page Speed Insider.
Google Search Console
Для взаимодействия с API воспользуемся библиотекой searchconsole. На гитхабе подробно описано, как получить необходимые токены для логина. Процедура для выгрузки данных и загрузки их в базу данных MS SQL будет следующей:
def google_reports(): # авторизация в нужный ресурс account = searchconsole.authenticate(client_config=r'credentials.json' , credentials=r'cred_result.json') webproperty = account['https://test.com/'] # выгрузка данных за последнюю неделю в разрезе страны, устройства, посадочной страницы и поисковой фразы report = webproperty.query.range('today', days=-10).dimension('country', 'device', 'page', 'query').get() now = datetime.now() fr = now - timedelta(days = 9) to = now - timedelta(days = 3) res = pd.DataFrame(columns=['dt_from', 'dt_to', 'country', 'device', 'page', 'query', 'clicks', 'impressions', 'position']) # собираем данные в DataFrame и записываем их на сервер for i in report.rows: temp={} temp['country'] = i[0] temp['device'] = i[1] temp['page'] = i[2] temp['query'] = i[3] temp['clicks'] = i[4] temp['impressions'] = i[5] temp['position'] = i[7] temp['dt_from'] = fr.strftime("%Y-%m-%d") temp['dt_to'] = to.strftime("%Y-%m-%d") res = res.append(temp, ignore_index=True) to_sql_server(res, 'google_positions')
Яндекс.Вебмастер
К сожалению, Вебмастер умеет выгружать только 500 поисковых фраз. Выгрузить разрезы по стране, типу устройства и т.п. он тоже не может. Из-за этих ограничений помимо выгрузки позиций по 500 словам из Вебмастера мы выгрузим данные из Яндекс.Метрики по посадочным страницам. Для тех, у кого поисковых фраз не так много, 500 слов будет достаточно. Если же у вас семантическое ядро по Яндексу достаточно широкое, то придется выгружать позиции из иных источников или писать свой парсер позиций.
def yandex_reports(): token = "..." # получаем UserID url = "https://api.webmaster.yandex.net/v4/user/" headers = {"Authorization": "OAuth " + token} res = requests.get(url, headers=headers) a = json.loads(res.text) userId = a['user_id'] host_id = "https:test.com:443" # выгружаем 500 запросов по числу показов в разрезе показов res = requests.get(url+str(userId)+"/hosts/"+host_id+"/search-queries/popular/?order_by=TOTAL_SHOWS&query_indicator=TOTAL_SHOWS", headers=headers) df1 = pd.DataFrame(columns=['query_id', 'query_text', 'shows', 'dt_from', 'dt_to']) a = json.loads(res.text) for i in a['queries']: temp={} temp['query_id'] = i['query_id'] temp['query_text'] = i['query_text'] temp['shows'] = i['indicators']['TOTAL_SHOWS'] temp['query_text'] = i['query_text'] temp['dt_from'] = a['date_from'] temp['dt_to'] = a['date_to'] df1 = df1.append(temp, ignore_index=True) # выгружаем 500 запросов по числу показов в разрезе кликов res = requests.get(url+str(userId)+"/hosts/"+host_id+"/search-queries/popular/?order_by=TOTAL_SHOWS&query_indicator=TOTAL_CLICKS", headers=headers) df2 = pd.DataFrame(columns=['query_id', 'clicks']) a = json.loads(res.text) for i in a['queries']: temp={} temp['query_id'] = i['query_id'] temp['clicks'] = i['indicators']['TOTAL_CLICKS'] df2 = df2.append(temp, ignore_index=True) # выгружаем 500 запросов по числу показов в разрезе позиций res = requests.get(url+str(userId)+"/hosts/"+host_id+"/search-queries/popular/?order_by=TOTAL_SHOWS&query_indicator=AVG_SHOW_POSITION", headers=headers) df3 = pd.DataFrame(columns=['query_id', 'position']) a = json.loads(res.text) for i in a['queries']: temp={} temp['query_id'] = i['query_id'] temp['position'] = i['indicators']['AVG_SHOW_POSITION'] df3 = df3.append(temp, ignore_index=True) df1 = df1.merge(df2, on='query_id') df1 = df1.merge(df3, on='query_id') to_sql_server(df1, 'yandex_positions')
Page Speed Insider
Позволяет оценить скорость загрузки контента сайта. Если сайт стал загружаться медленнее, то это может существенно снизить позиции сайта в поисковой выдаче.
# выгружаем топ-50 страниц для подсчета скорости загрузки conn = pymssql.connect(host=host,user=user,password=password) sql_string = r''' ;with a as( select distinct page, sum(clicks) as clicks from seo_google_positions group by page ) select top 50 page from a order by clicks desc ''' data = pd.read_sql(sql_string, conn) conn.close() # выгружаем данные о средней скорости загрузки страницы dat = pd.DataFrame(columns=['first_cpu_idle', 'first_contentful_paint', 'page', 'dt']) for i, j in data.iterrows(): url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url={0}&category=performance&strategy=desktop".format(j[0]) res = requests.get(url) res = json.loads(res.text) temp = {} temp['first_cpu_idle'] = res['lighthouseResult']['audits']['first-cpu-idle']['displayValue'] temp['first_contentful_paint'] = res['lighthouseResult']['audits']['first-contentful-paint']['displayValue'] temp['page'] = j[0] temp['dt'] = now.strftime("%Y-%m-%d") dat = dat.append(temp, ignore_index = True) to_sql_server(dat, 'google_pagespeed')
Google Ads и Яндекс Директ
Для оценивания частотности поисковых запросов выгрузим частотность нашего СЕО-ядра.
Прогноз бюджета Яндекс
Планировщик ключевых слов Google
Яндекс Метрика
Выгрузим данные по просмотрам и визитам на страницы входа с SEO-трафика.
token = token headers = {"Authorization": "OAuth " + token} now = datetime.now() fr = (now - timedelta(days = 9)).strftime("%Y-%m-%d") to = (now - timedelta(days = 3)).strftime("%Y-%m-%d") res = requests.get("https://api-metrika.yandex.net/stat/v1/data/?ids=ids&metrics=ym:s:pageviews,ym:s:visits&dimensions=ym:s:startURL,ym:s:lastsignSearchEngine,ym:s:regionCountry,ym:s:deviceCategory&date1={0}&date2={1}&group=all&filters=ym:s:lastsignTrafficSource=='organic'&limit=50000".format(fr,to), headers=headers) a = json.loads(res.text) re = pd.DataFrame(columns=['page', 'device', 'view', 'dt_from', 'dt_to', 'engine', 'visits', 'country', 'pageviews']) for i in a['data']: temp={} temp['page'] = i['dimensions'][0]['name'] temp['engine'] = i['dimensions'][1]['name'] temp['country'] = i['dimensions'][2]['name'] temp['device'] = i['dimensions'][3]['name'] temp['view'] = i['metrics'][0] temp['visits'] = i['metrics'][1] temp['pageviews'] = i['metrics'][0] temp['dt_from'] = fr temp['dt_to'] = to re=re.append(temp, ignore_index=True) to_sql_server(re, 'yandex_pages')
Сбор данных в Power BI
Посмотрим, что у нас получилось выгрузить:
- google_positions и yandex_positions
- google_frequency и yandex_frequency
- google_speed и yandex_speed
- yandex_metrika
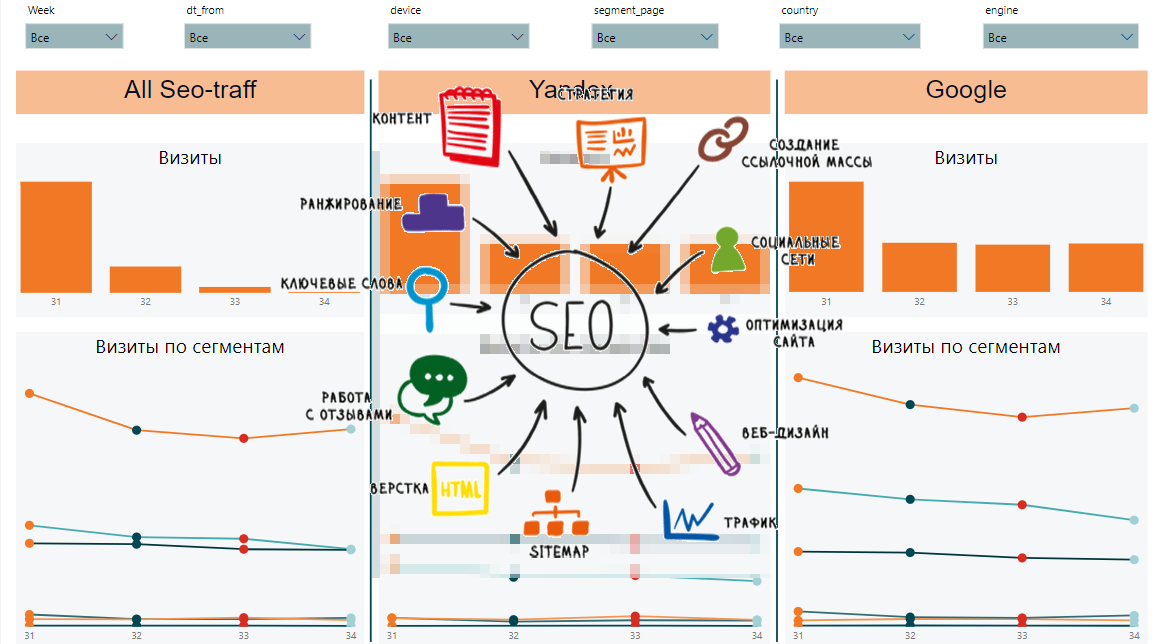
Из этих данных мы сможем собрать динамику по неделям, по сегмантам, общие данные по сегментам и запросам, динамику и общие данные по страницам и скорости загрузки контента. Вот так может выглядеть финальный отчет:

С одной стороны, очень много разных табличек и сложно понять, каковы общие тенденции. С другой стороны, в каждой табличке отображены важные данные по позициям, показам, кликам, CTR, скорости загрузки страницы.
Статьи из цикла:
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 1: Удобный интерфейс
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 2: Email-рассылки. Стратегический дашборд
- Проектирование дашбордов для веб-аналитики e-commerce сайта. Часть 2: Email-рассылки. Операционный дашборд
ссылка на оригинал статьи https://habr.com/ru/post/467019/
Добавить комментарий