«Understanding Message Brokers»,
автор: Jakub Korab, издательство: O’Reilly Media, Inc., дата издания: June 2017, ISBN: 9781492049296.
Предыдущая переведенная часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 1. Введение
Kafka была разработана в LinkedIn для того, чтобы обойти некоторые ограничения традиционных брокеров сообщений и избежать необходимости настраивать несколько брокеров сообщений для разных взаимодействий «точка-точка», что описано в данной книге в разделе «Вертикальное и горизонтальное масштабирование» на странице 28. Сценарии использования в LinkedIn в основном основывались на однонаправленном поглощении очень больших объемов данных, таких как клики на страницах и журналы доступа, в то же время позволяя использовать эти данные нескольким системам, не влияя на производительность продюсеров или других консюмеров. Фактически, причина существования Kafka заключается в том, чтобы получить такую архитектуру обмена сообщениями, которую описывает Universal Data Pipeline.
С учетом этой конечной цели, естественно, возникли и другие требования. Kafka должна:
- Быть чрезвычайно быстрой
- Предоставлять большую пропускную способность при работе с сообщениями
- Поддерживать модели «Издатель-Подписчик» и «Точка-Точка»
- Не замедляться с добавлением потребителей. Например, производительность и очереди, и топика в ActiveMQ ухудшается при росте количества потребителей на адресате
- Быть горизонтально масштабируемой; если один брокер, сохраняющий (persists) сообщения, может делать это только на максимальной скорости диска, то для увеличения производительности имеет смысл выйти за пределы одного экземпляра брокера
- Разграничивать доступ к хранению и повторному извлечению сообщений
Чтобы достигнуть всего этого, в Kafka принята архитектура, которая переопределила роли и обязанности клиентов и брокеров обмена сообщениями. Модель JMS очень ориентирована на брокер, где он отвечает за распространение сообщений, а клиенты должны беспокоиться только об отправке и получении сообщений. Kafka, с другой стороны, ориентирована на клиента, при этом клиент берет на себя многие функции традиционного брокера, такие как справедливое распределение соответствующих сообщений среди потребителей, в обмен получая чрезвычайно быстрый и масштабируемый брокер. Для людей, работавших с традиционными системами обмена сообщениями, работа с Kafka требует фундаментальных изменений во взглядах.
Это инженерное направление привело к созданию инфраструктуры обмена сообщениями, способной на много порядков увеличить пропускную способность по сравнению с обычным брокером. Как мы увидим, этот подход сопряжен с компромиссами, которые означают, что Kafka не подходит для определенных типов нагрузок и установленного ПО.
Унифицированная модель адресата
Чтобы выполнить требования, описанные выше, Kafka объединила обмен сообщениями типа «публикация-подписка» и «точка-точка» в рамках одного вида адресата — топика. Это сбивает с толку людей, работавших с системами обмена сообщениями, где слово «топик» относится к широковещательному механизму, из которого (из топика) чтение не является надежным (is nondurable). Топики Kafka следует рассматривать как гибридный тип адресата, в соответствии с определением, данным во введении к этой книге.
В оставшейся части этой главы, если мы явно не укажем иное, термин «топик» будет относиться к топику Kafka.
Чтобы полностью понять, как ведут себя топики и какие гарантии они предоставляют, нам нужно сначала рассмотреть, как они реализованы в Kafka.
У каждого топика в Kafka есть свой журнал.
Продюсеры, отправляющие сообщения в Kafka, дописывают в этот журнал, а консюмеры читают из журнала с помощью указателей, которые постоянно перемещаются вперед. Периодически Kafka удаляет самые старые части журнала, независимо от того, были ли сообщения в этих частях прочитаны или нет. Центральной частью дизайна Kafka является то, что брокер не заботится о том, прочитаны ли сообщения или нет — это ответственность клиента.
Термины «журнал» и «указатель» не встречаются в документации Kafka. Эти хорошо известные термины используются здесь, чтобы помочь пониманию.
Эта модель полностью отличается от ActiveMQ, где сообщения из всех очередей хранятся в одном журнале, а брокер помечает сообщения, как удаленные, после того как они были прочитаны.
Давайте теперь немного углубимся и рассмотрим журнал топика более подробно.
Журнал Kafka состоит из нескольких партиций (Рисунок 3-1). Kafka гарантирует строгую упорядоченность в каждой партиции. Это означает, что сообщения, записанные в партицию в определенном порядке, будут прочитаны в том же порядке. Каждая партиция реализована в виде цикличного (rolling) файла журнала, который содержит подмножество (subset) всех сообщений, отправленных в топик его продюсерами. Созданный топик содержит по-умолчанию одну партицию. Идея партиций — это центральная идея Kafka для горизонтального масштабирования.
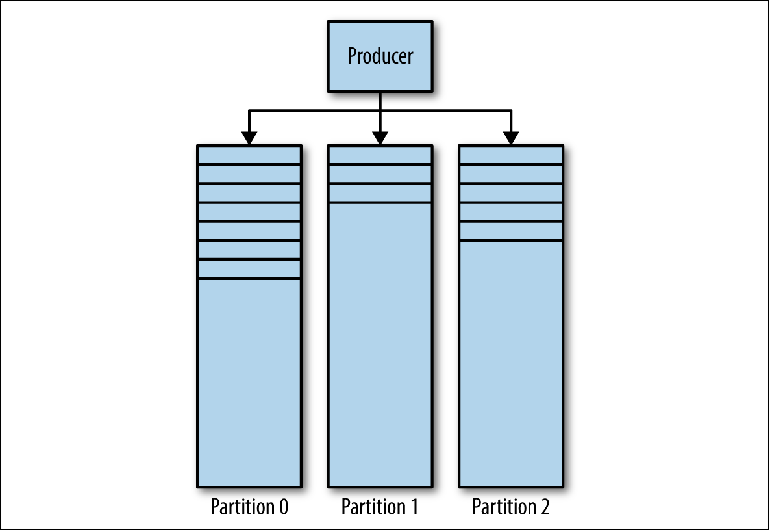
Figure 3-1. Партиции Kafka
Когда продюсер отправляет сообщение в топик Kafka, он решает, в какую партицию отправить сообщение. Мы рассмотрим это более подробно позже.
Чтение сообщений
Клиент, который хочет прочитать сообщения, управляет именованным указателем, называемым группа консюмеров (consumer group), который указывает на смещение (offset) сообщения в партиции. Смещение — это позиция с возрастающим номером, которая начинается с 0 в начале партиции. Эта группа консюмеров, на которую ссылаются в API через определяемый пользователем идентификатор group_id, соответствует одному логическому потребителю или системе.
Большинство систем, использующих обмен сообщениями, читают данные из адресата посредством нескольких экземпляров и потоков для параллельной обработки сообщений. Таким образом, обычно будет много экземпляров консюмеров, совместно использующих одну и ту же группу консюмеров.
Проблему чтения можно представить следующим образом:
- Топик имеет несколько партиций
- Использовать топик может одновременно множество групп консюмеров
- Группа консюмеров может иметь несколько отдельных экземпляров
Это нетривиальная проблема «многие ко многим». Чтобы понять, как Kafka обращается с отношениями между группами консюмеров, экземплярами консюмеров и партициями, рассмотрим ряд постепенно усложняющихся сценариев чтения.
Консюмеры и группы консюмеров
Давайте возьмем в качестве отправной точки топик с одной партицией (Figure 3-2).
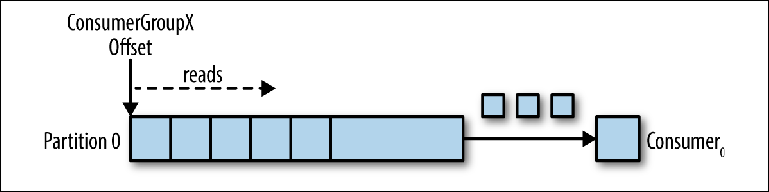
Figure 3-2. Консюмер читает из партиции
Когда экземпляр консюмера подключается со своим собственным group_id к этому топику, ему назначается партиция для чтения и смещение в этой партиции. Положение этого смещения конфигурируется в клиенте, как указатель на самую последнюю позицию (самое новое сообщение) или самую раннюю позицию (самое старое сообщение). Консюмер запрашивает (polls) сообщения из топика, что приводит к их последовательному чтению из журнала.
Позиция смещения регулярно коммитится обратно в Kafka и сохраняется, как сообщения во внутреннем топике _consumer_offsets. Прочитанные сообщения все равно не удаляются, в отличие от обычного брокера, и клиент может перемотать (rewind) смещение, чтобы повторно обработать уже просмотренные сообщения.
Когда подключается второй логический консюмер, используя другой group_id, он управляет вторым указателем, который не зависит от первого (Figure 3-3). Таким образом, топик Kafka действует как очередь, в которой существует один консюмер и, как обычный топик pub-sub, на который подписаны несколько консюмеров, с дополнительным преимуществом, что все сообщения сохраняются и могут обрабатываться несколько раз.
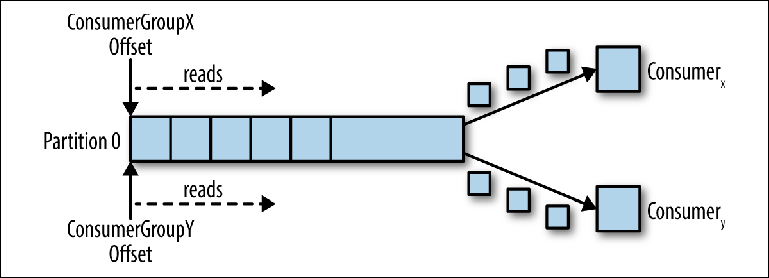
Figure 3-3. Два консюмера в разных группах консюмеров читают из одной партиции
Консюмеры в группе консюмеров
Когда один экземпляр консюмера читает данные из партиции, он полностью контролирует указатель и обрабатывает сообщения, как описано в предыдущем разделе.
Если несколько экземпляров консюмеров были подключены с одним и тем же group_id к топику с одной партицией, то экземпляру, который подключился последним, будет передан контроль над указателем и с этого момента он будет получать все сообщения (Figure 3-4).
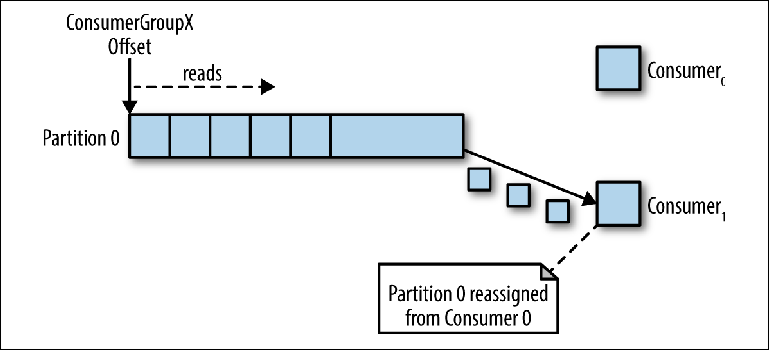
Figure 3-4. Два консюмера в одной и той же группе консюмеров читают из одной партиции
Этот режим обработки, в котором количество экземпляров консюмеров превышает число партиций, можно рассматривать как разновидность монопольного потребителя. Это может быть полезно, если вам нужна «активно-пассивная» (или «горячая-теплая») кластеризация ваших экземпляров консюмеров, хотя параллельная работа нескольких консюмеров («активно-активная» или «горячая-горячая») намного более типична, чем консюмеры в режиме ожидания.
Такое поведение распределения сообщений, описанное выше, может вызывать удивление в сравнении с тем, как ведет себя обычная очередь JMS. В этой модели сообщения, отправленные в очередь, будут равномерно распределены между двумя консюмерами.
Чаще всего, когда мы создаем несколько экземпляров консюмеров, мы делаем это либо для параллельной обработки сообщений, либо для увеличения скорости чтения, либо для повышения устойчивости процесса чтения. Поскольку читать данные из партиции может одновременно только один экземпляр консюмера, то как это достигается в Kafka?
Один из способов сделать это — использовать один экземпляр консюмера, чтобы прочитать все сообщения и передать их в пул потоков. Хотя этот подход увеличивает пропускную способность обработки, он увеличивает сложность логики консюмеров и ничего не делает для повышения устойчивости системы чтения. Если один экземпляр консюмера отключается из-за сбоя питания или аналогичного события, то вычитка прекращается.
Каноническим способом решения этой проблемы в Kafka является использование бОльшего количества партиций.
Партиционирование
Партиции являются основным механизмом распараллеливания чтения и масштабирования топика за пределы пропускной способности одного экземпляра брокера. Чтобы лучше понять это, давайте рассмотрим ситуацию, когда существует топик с двумя партициями и на этот топик подписывается один консюмер (Figure 3-5).
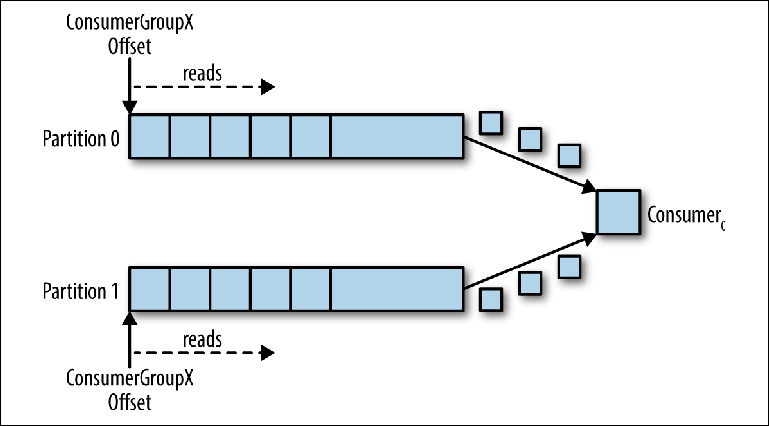
Figure 3-5. Один консюмер читает из нескольких партиций
В этом сценарии консюмеру дается контроль над указателями, соответствующими его group_id в обоих партициях, и начинается чтение сообщений из обеих партиций.
Когда в этот топик добавляется дополнительный консюмер для того же group_id, Kafka переназначает (reallocate) одну из партиций с первого на второй консюмер. После чего каждый экземпляр консюмера будет вычитывать из одной партиции топика (Figure 3-6).
Чтобы обеспечить обработку сообщений параллельно в 20 потоков, вам потребуется как минимум 20 партиций. Если партиций будет меньше, у вас останутся консюмеры, которым не над чем работать, что описано ранее в нашем обсуждении монопольных консюмеров.
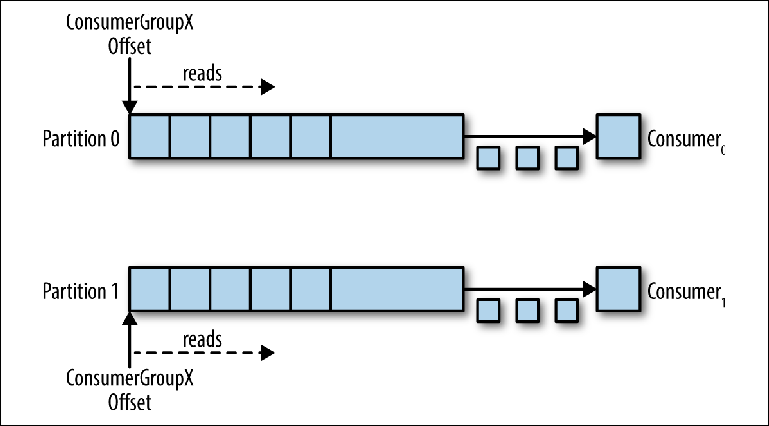
Figure 3-6. Два консюмера в одной и той же группе консюмеров читают из разных партиций
Эта схема значительно снижает сложность работы брокера Kafka по сравнению с распределением сообщений, необходимым для поддержки очереди JMS. Здесь не нужно заботится о следующих моментах:
- Какой консюмер должен получить следующее сообщение, основываясь на циклическом (round-robin) распределении, текущей емкости буферов предварительной выборки или предыдущих сообщениях (как для групп сообщений JMS).
- Какие сообщения отправлены каким консюмерам и должны ли они быть доставлены повторно в случае сбоя.
Все, что должен сделать брокер Kafka — это последовательно передавать сообщения консюмеру, когда последний запрашивает их.
Однако, требования к распараллеливанию вычитки и повторной отправке неудачных сообщений никуда не деваются — ответственность за них просто переходит от брокера к клиенту. Это означает, что они должны быть учтены в вашем коде.
Отправка сообщений
Ответственность за решение, в какую партицию отправить сообщение, возлагается на продюсер этого сообщения. Чтобы понять механизм, с помощью которого это делается, нам сначала нужно рассмотреть, что именно мы на самом деле отправляем.
В то время, как в JMS мы используем структуру сообщения с метаданными (заголовками и свойствами) и телом, содержащим полезную нагрузку (payload), в Kafka сообщение является парой «ключ-значение». Полезная нагрузка сообщения отправляется, как значение (value). Ключ, с другой стороны, используется главным образом для партиционирования и должен содержать специфичный для бизнес-логики ключ, чтобы поместить связанные сообщений в ту же партицию.
В Главе 2 мы обсуждали сценарий онлайн-ставок, когда связанные события должны обрабатываться по порядку одним консюмером:
- Учетная запись пользователя настроена.
- Деньги зачисляются на счет.
- Делается ставка, которая выводит деньги со счета.
Если каждое событие представляет собой сообщение, отправленное в топик, то в этом случае естественным ключом будет идентификатор учетной записи.
Когда сообщение отправляется с использованием Kafka Producer API, оно передается функции партиционирования, которая, учитывая сообщение и текущее состояние кластера Kafka, возвращает идентификатор партиции, в которую должно быть отправлено сообщение. Эта функция реализована через интерфейс Partitioner в Java.
Этот интерфейс выглядит следующим образом:
interface Partitioner { int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster); }Реализация Partitioner для определения партиции использует по-умолчанию алгоритм хеширования ключа (general-purpose hashing algorithm over the key) или циклический перебор (round-robin), если ключ не указан. Это значение по-умолчанию работает хорошо в большинстве случаев. Однако, в будущем вы захотите написать свой собственный.
Написание собственной стратегии партиционирования
Давайте рассмотрим пример, когда вы хотите отправить метаданные вместе с полезной нагрузкой сообщения. Полезная нагрузка в нашем примере — это инструкция для внесения депозита на игровой счет. Инструкция — это то, что мы хотели бы гарантированно не модифицировать при передаче и хотим быть уверены, что только доверенная вышестоящая система может инициировать эту инструкцию. В этом случае отправляющая и принимающая системы согласовывают использование подписи для проверки подлинности сообщения.
В обычном JMS мы просто определяем свойство «подпись сообщения» и добавляем его к сообщению. Тем не менее, Kafka не предоставляет нам механизм для передачи метаданных — только ключ и значение.
Поскольку значение — это полезная нагрузка банковского перевода (bank transfer payload), целостность которой мы хотим сохранить, у нас не остается другого выбора, кроме определения структуры данных для использования в ключе. Предполагая, что нам нужен идентификатор учетной записи для партиционирования, так как все сообщения, относящиеся к учетной записи, должны обрабатываться по порядку, мы придумаем следующую структуру JSON:
{ "signature": "541661622185851c248b41bf0cea7ad0", "accountId": "10007865234" }Поскольку значение подписи будет варьироваться в зависимости от полезной нагрузки, дефолтная стратегия хеширования интерфейса Partitioner не будет надежно группировать связанные сообщения. Поэтому нам нужно будет написать свою собственную стратегию, которая будет анализировать этот ключ и разделять (partition) значение accountId.
Kafka включает контрольные суммы для обнаружения повреждения сообщений в хранилище и имеет полный набор функций безопасности. Даже в этом случае иногда появляются специфические для отрасли требования, такие как приведенное выше.
Пользовательская стратегия партиционирования должна гарантировать, что все связанные сообщения окажутся в одной партиции. Хотя это кажется простым, но требование может быть усложнено из-за важности упорядочивания связанных сообщений и того, насколько фиксировано количество партиций в топике.
Количество партиций в топике может изменяться со временем, так как их можно добавить, если трафик выходит за пределы первоначальных ожиданий. Таким образом, ключи сообщений могут быть связаны с партицией, в которую они были первоначально отправлены, подразумевая часть состояния, которое должно быть распределено между экземплярами продюсера.
Другим фактором, который следует учитывать, является равномерность распределения сообщений между партициями. Как правило, ключи не распределяются равномерно по сообщениям, и хеш-функции не гарантируют справедливое распределение сообщений для небольшого набора ключей.
Важно отметить, что, как бы вы ни решили разделить сообщения, сам разделитель, возможно, придется использовать повторно.
Рассмотрим требование репликации данных между кластерами Kafka в разных географических расположениях. Для этой цели Kafka поставляется с инструментом командной строки под названием MirrorMaker, который используется для чтения сообщений из одного кластера и передачи их в другой.
MirrorMaker должен понимать ключи реплицируемого топика, чтобы поддерживать относительный порядок между сообщениями при репликации между кластерами, поскольку количество партиций для этого топика может не совпадать в двух кластерах.
Пользовательские стратегии партиционирования встречаются относительно редко, так как дефолтные хеширование или циклический перебор успешно работают в большинстве сценариев. Однако, если вам требуются строгие гарантии упорядочивания или вам необходимо извлечь метаданные из полезных нагрузок, то партиционирование — это то, на что вам следует взглянуть более подробно.
Преимущества масштабируемости и производительности Kafka обусловлены переносом некоторых обязанностей традиционного брокера на клиента. В этом случае принимается решение о распределении потенциально связанных сообщений по нескольким консюмерам, работающим параллельно.
JMS брокеры также должны иметь дело с такими требованиями. Интересно, что механизм отправки связанных сообщений одному и тому же консюмеру, реализованный через JMS Message Groups (разновидность стратегии балансировки sticky load balancing (SLB)), также требует, чтобы отправитель помечал сообщения, как связанные. В случае JMS, брокер отвечает за отправку этой группы связанных сообщений одному консюмеру из многих и передачу прав собственности на группу если консюмер отвалился.
Соглашения по продюсеру
Партиционирование — это не единственное, что необходимо учитывать при отправке сообщений. Давайте рассмотрим методы send () класса Producer в Java API:
Future < RecordMetadata > send(ProducerRecord < K, V > record); Future < RecordMetadata > send(ProducerRecord < K, V > record, Callback callback); Следует сразу отметить, что оба метода возвращают Future, что указывает на то, что операция отправки не выполняется немедленно. В результате получается, что сообщение (ProducerRecord) записывается в буфер отправки для каждой активной партиции и передается брокеру фоновым потоком в библиотеке клиента Kafka. Хотя это делает работу невероятно быстрой, это означает, что неопытно написанное приложение может потерять сообщения, если его процесс будет остановлен.
Как всегда, есть способ сделать операцию отправки более надежной за счет производительности. Размер этого буфера можно установить в 0, и поток отправляющего приложения будет вынужден ждать, пока передача сообщения брокеру не будет завершена, следующим образом:
RecordMetadata metadata = producer.send(record).get();Еще раз о чтении сообщений
Чтение сообщений имеет дополнительные сложности, о которых необходимо порассуждать. В отличие от API JMS, который может запускать слушателя сообщений (message listener) в ответ на поступление сообщения, интерфейс Consumer Kafka только опрашивает (polling). Давайте подробнее рассмотрим метод poll (), используемый для этой цели:
ConsumerRecords < K, V > poll(long timeout); Возвращаемое значение метода — это контейнерная структура, содержащая несколько объектов ConsumerRecord из потенциально нескольких партиций. ConsumerRecord сам по себе является объектом-холдером для пары ключ-значение с соответствующими метаданными, такими, как партиция, из которой он получен.
Как обсуждалось в Главе 2, мы должны постоянно помнить, что происходит с сообщениями после их успешной или неуспешной обработки, например, если клиент не может обработать сообщение или если он прерывает работу. В JMS это обрабатывалось через режим подтверждения (acknowledgement mode). Брокер либо удалит успешно обработанное сообщение, либо повторно доставит необработанное или зафейленное (при условии, что были использованы транзакции). Kafka работает совсем по-другому. Сообщения не удаляются в брокере после вычитки и ответственность за то, что происходит при сбое, лежит на самом вычитывающем коде.
Как мы уже говорили, группа консюмеров связана со смещением в журнале. Позиция в журнале, связанная с этим смещением, соответствует следующему сообщению, которое будет выдано в ответ на poll (). Решающее значение при чтении имеет момент времени, когда это смещение увеличивается.
Возвращаясь к модели чтения, рассмотренной ранее, обработка сообщения состоит из трех этапов:
- Извлечь сообщение для чтения.
- Обработать сообщение.
- Подтвердить сообщение.
Консюмер Kafka поставляется с опцией конфигурации enable.auto.commit. Это часто используемая настройка по умолчанию, как это обычно бывает с настройками, содержащими слово «авто».
До Kafka 0.10 клиент, использовавший этот параметр, отправлял смещение последнего прочитанного сообщения при следующем вызове poll () после обработки. Это означало, что любые сообщения, которые были извлечены (fetched), имели возможность быть повторно обработанными, если клиент обработал сообщения, но неожиданно был уничтожен перед вызовом poll (). Поскольку брокер не сохраняет никакого состояния относительно того, сколько раз сообщение было прочитано, следующий консюмер, который извлекает это сообщение, не будет знать, что произошло что-то плохое. Это поведение было псевдо-транзакционным. Смещение коммитилось только в случае успешной обработки сообщения, но если клиент прерывал работу, брокер снова отправлял то же самое сообщение другому клиенту. Такое поведение соответствовало гарантии доставки сообщений «по крайней мере один раз«.
В Kafka 0.10 код клиента был изменен таким образом, что коммит стал периодически запускаться библиотекой клиента, в соответствии с настройкой auto.commit.interval.ms. Это поведение находится где-то между режимами JMS AUTO_ACKNOWLEDGE и DUPS_OK_ACKNOWLEDGE. При использовании автокоммита сообщения могли быть подтверждены независимо от того, были ли они фактически обработаны — это могло произойти в случае медленного консюмера. Если консюмер прерывал работу, сообщения извлекались следующим консюмером, начиная с закоммиченной позиции, что могло привести к пропуску сообщения. В этом случае Kafka не теряла сообщения, читающий код просто не обрабатывал их.
Этот режим имеет те же перспективы, что и в версии 0.9: сообщения могут быть обработаны, но в случае сбоя, смещение может быть не закоммичено, что потенциально может привести к задвоению доставки. Чем больше сообщений вы извлекаете при выполнении poll (), тем больше эта проблема.
Как обсуждалось в разделе «Чтение сообщений из очереди» на стр. 21, в системе обмена сообщениями нет такого понятия, как однократная доставка сообщения, если принять во внимание режимы сбоев.
В Kafka есть два способа зафиксировать (закоммитить) смещение (оффсет): автоматически и вручную. В обоих случаях сообщения могут обрабатываться несколько раз, в том случае, если сообщение было обработано, но произошел сбой до коммита. Вы также можете вообще не обрабатывать сообщение, если коммит произошел в фоне и ваш код был завершен до того, как он приступил к обработке (возможно в Kafka 0.9 и более ранних версиях).
Управлять процессом коммита смещения вручную можно в API консюмера Kafka, установив параметр enable.auto.commit в значение false и явно вызвав один из следующих методов:
void commitSync(); void commitAsync(); Если вы стремитесь обработать сообщение «хотя бы один раз», вы должны закоммитить смещение вручную с помощью commitSync (), выполнив эту команду сразу после обработки сообщений.
Эти методы не позволяют подтверждать (acknowledged) сообщения до того, как они будут обработаны, но они ничего не делают для устранения потенциального задвоения обработки, в то же время создавая видимость транзакционности. В Kafka отсутствуют транзакции. У клиента нет возможности сделать следующее:
- Автоматически откатить (roll back) зафейленное сообщение. Консюмеры сами должны обрабатывать исключения, возникающие из-за проблемных пэйлоадов и отключений бекэнда, так как они не могут полагаться на повторную доставку сообщений брокером.
- Отправить сообщения в несколько топиков в рамках одной атомарной операции. Как мы скоро увидим, контроль над различными топиками и партициями может находиться на разных машинах в кластере Kafka, которые не координируют транзакции при отправке. На момент написания этой статьи была проделана определенная работа, чтобы сделать это возможным с помощью KIP-98.
- Связать чтение одного сообщения из одного топика с отправкой другого сообщения в другой топик. Опять же, архитектура Kafka зависит от множества независимых машин, работающих как одна шина и не делается никаких попыток скрыть это. Например, не существует компонентов API, которые позволили бы связать Консюмер и Продюсер в транзакции. В JMS это обеспечивается объектом Session, из которого создаются MessageProducers и MessageConsumers.
Если мы не можем полагаться на транзакции, как мы можем обеспечить семантику, более близкую к той, которую предоставляют традиционные системы обмена сообщениями?
Если существует вероятность того, что смещение консюмера может увеличиться до того, как сообщение было обработано, например, во время сбоя консюмера, то у консюмера нет способа узнать, пропустила ли его группа консюмеров сообщения, когда ей назначают партицию. Таким образом, одна из стратегий заключается в перемотке (rewind) смещения на предыдущую позицию. API консюмера Kafka предоставляет следующие методы для этого:
void seek(TopicPartition partition, long offset); void seekToBeginning(Collection < TopicPartition > partitions); Метод seek () может использоваться с методом
offsetsForTimes (Map<TopicPartition,Long> timestampsToSearch) для перемотки в состояние в какой-либо определенный момент в прошлом.
Неявно, использование этого подхода означает, что, весьма вероятно, некоторые сообщения, которые были обработаны ранее, будут прочитаны и обработаны заново. Чтобы избежать этого, мы можем использовать идемпотентное чтение, как описано в Главе 4, для отслеживания ранее просмотренных сообщений и исключения дубликатов.
Как альтернатива, код вашего консюмера может быть простым, если допустима потеря или дублирование сообщений. Когда мы рассматриваем сценарии использования, для которых обычно используется Kafka, например, обработка событий логов, метрик, отслеживание кликов и т.д., мы понимаем, что потеря отдельных сообщений вряд ли окажет значимое влияние на окружающие приложения. В таких случаях значения по-умолчанию вполне допустимы. С другой стороны, если вашему приложению нужно передавать платежи, вы должны тщательно заботиться о каждом отдельном сообщении. Все сводится к контексту.
Личные наблюдения показывают, что с ростом интенсивности сообщений, ценность каждого отдельного сообщения снижается. Сообщения большого объема становятся, как правило, ценными, если их рассматривать в агрегированной форме.
Высокая доступность (High Availability)
Подход Kafka в отношении высокой доступности существенно отличается от подхода ActiveMQ. Kafka разработана на базе горизонтально масштабируемых кластеров, в которых все экземпляры брокера принимают и раздают сообщения одновременно.
Кластер Kafka состоит из нескольких экземпляров брокера, работающих на разных серверах. Kafka была разработана для работы на обычном автономном железе, где каждый узел имеет свое собственное выделенное хранилище. Использование сетевых хранилищ (SAN) не рекомендуется, поскольку множественные вычислительные узлы могут конкурировать за временнЫе интервалы хранилища и создавать конфликты.
Kafka — это постоянно включенная система. Многие крупные пользователи Kafka никогда не гасят свои кластеры и программное обеспечение всегда обеспечивает обновление путем последовательного рестарта. Это достигается за счет гарантирования совместимости с предыдущей версией для сообщений и взаимодействий между брокерами.
Брокеры подключены к кластеру серверов ZooKeeper, который действует, как реестр конфигурационных данный и используется для координации ролей каждого брокера. ZooKeeper сам является распределенной системой, которая обеспечивает высокую доступность посредством репликации информации путем установления кворума.
В базовом случае топик создается в кластере Kafka со следующими свойствами:
- Количество партиций. Как обсуждалось ранее, точное значение, используемое здесь, зависит от желаемого уровня параллельного чтения.
- Коэффициент (фактор) репликации определяет, сколько экземпляров брокера в кластере должны содержать журналы для этой партиции.
Используя ZooKeepers для координации, Kafka пытается справедливо распределить новые партиции между брокерами в кластере. Это делается одним экземпляром, который выполняет роль Контроллера.
В рантайме для каждой партиции топика Контроллер назначает брокеру роли лидера (leader, master, ведущего) и последователей (followers, slaves, подчиненных). Брокер, выступающий в качестве лидера для данной партиции, отвечает за прием всех сообщений, отправленных ему продюсерами, и распространение сообщений по консюмерам. При отправке сообщений в партицию топика они реплицируются на все узлы брокера, выступающие в качестве последователей для этой партиции. Каждый узел, содержащий журналы для партиции, называется репликой. Брокер может выступать в качестве лидера для одних партиций и в качестве последователя для других.
Последователь, содержащий все сообщения, хранящиеся у лидера, называется синхронизированной репликой (репликой, находящейся в синхронизированном состоянии, in-sync replica). Если брокер, выступающий в качестве лидера для партиции, отключается, любой брокер, который находится в актуализированном или синхронизированном состоянии для этой партиции, может взять на себя роль лидера. Это невероятно устойчивый дизайн.
Частью конфигурации продюсера является параметр acks, который определяет, сколько реплик должно подтвердить (acknowledge) получение сообщения, прежде чем поток приложения продолжит отправку: 0, 1 или все. Если задано значение all, то при получении сообщения лидер отправит подтверждение (confirmation) обратно продюсеру, как только получит подтверждение (acknowledgements) записи от нескольких реплик (включая саму себя), определенных настройкой топика min.insync.replicas (по умолчанию 1). Если сообщение не может быть успешно реплицировано, то продюсер вызовет исключение для приложения (NotEnoughReplicas или NotEnoughReplicasAfterAppend).
В типичной конфигурации создается топик с коэффициентом репликации 3 (1 лидер, 2 последователя для каждой партиции) и параметр min.insync.replicas устанавливается в значение 2. В этом случае, кластер будет допускать, чтобы один из брокеров, управляющих партицией топика, мог отключаться без влияния на клиентские приложения.
Это возвращает нас к уже знакомому компромиссу между производительностью и надежностью. Репликация происходит за счет дополнительного времени ожидания подтверждений (acknowledgments) от последователей. Хотя, поскольку она выполняется параллельно, репликация, как минимум на три узла, имеет такую же производительность, как и на два (игнорируя увеличение использования пропускной способности сети).
Используя эту схему репликации, Kafka ловко избегает необходимости обеспечивать физическую запись каждого сообщения на диск с помощью операции sync (). Каждое сообщение, отправленное продюсером, будет записано в журнал партиции, но, как обсуждалось в Главе 2, запись в файл первоначально выполняется в буфер операционной системы. Если это сообщение реплицировано на другой экземпляр Kafka и находится в его памяти, потеря лидера не означает, что само сообщение было потеряно — его может взять на себя синхронизированная реплика.
Отказ от необходимости выполнять операцию sync () означает, что Kafka может принимать сообщения со скоростью, с которой она может записывать их в память. И наоборот, чем дольше можно избежать сброса (flushing) памяти на диск, тем лучше. По этой причине нередки случаи, когда брокерам Kafka выделяется 64 Гб памяти или более. Такое использование памяти означает, что один экземпляр Kafka может легко работать на скоростях во много тысяч раз быстрее, чем традиционный брокер сообщений.
Kafka также можно настроить для применения операции sync () к пакетам сообщений. Поскольку всё в Kafka ориентировано на работу с пакетами, это на самом деле работает довольно хорошо для многих сценариев использования и является полезным инструментом для пользователей, которые требуют очень сильных гарантий. Большая часть чистой производительности Kafka связана с сообщениями, которые отправляются брокеру в виде пакетов, и с тем, что эти сообщения считываются из брокера последовательными блоками с помощью zero-copy операций (операциями, в ходе которых не выполняется задача копирования данных из одной области памяти в другую). Последнее является большим выигрышем с точки зрения производительности и ресурсов и возможно только благодаря использованию лежащей в основе структуры данных журнала, определяющей схему партиции.
В кластере Kafka возможна гораздо более высокая производительность, чем при использовании одного брокера Kafka, поскольку партиции топика могут горизонтально масштабироваться на множестве отдельных машин.
Итоги
В этой главе мы рассмотрели, как архитектура Kafka переосмысливает отношения между клиентами и брокерами, чтобы обеспечить невероятно устойчивый конвейер обмена сообщениями, с пропускной способностью во много раз большей, чем у обычного брокера сообщений. Мы обсудили функциональность, которую она использует для достижения этой цели, и кратко рассмотрели архитектуру приложений, обеспечивающих эту функциональность. В следующей главе мы рассмотрим общие проблемы, которые необходимо решать приложениям на основе обмена сообщениями, и обсудим стратегии их решения. Мы завершим главу, обрисовав, как рассуждать о технологиях обмена сообщениями в целом, чтобы вы могли оценить их пригодность для ваших сценариев использования.
Предыдущая переведенная часть: Понимание брокеров сообщений. Изучение механики обмена сообщениями посредством ActiveMQ и Kafka. Глава 1
Перевод выполнен: tele.gg/middle_java
Продолжение следует…
ссылка на оригинал статьи https://habr.com/ru/post/466585/
Добавить комментарий