Доброго времени суток и мое почтение, читатели Хабра!
Предыстория
У нас на работе принято обмениваться интересными находками в командах разработки. На очередной встрече, обсуждая будущее .NET и .NET 5 в частности, мы с коллегами заострили внимание на видении унифицированный платформы с этой картинки:
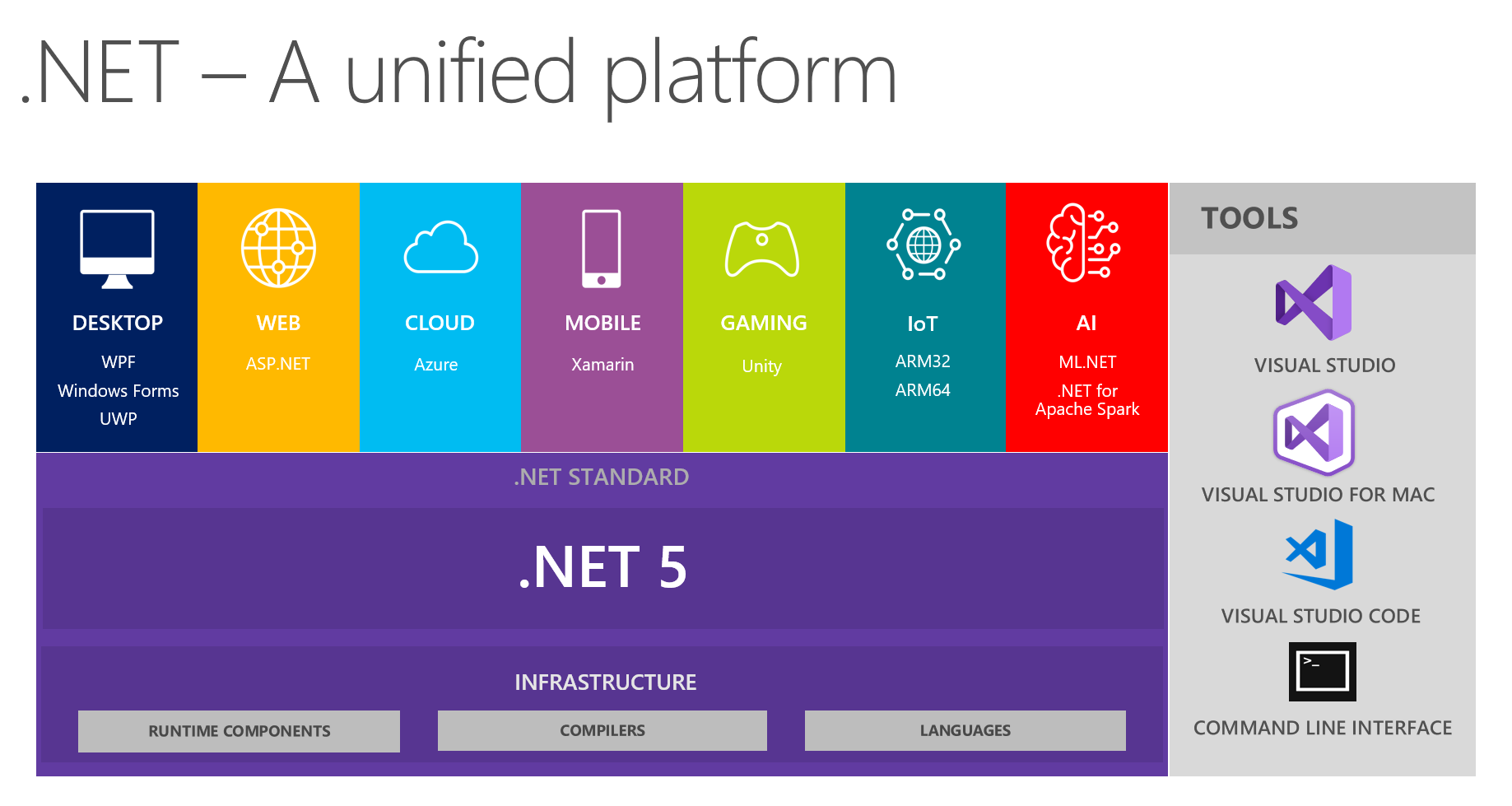
На ней показано, что платформа объединяет DESKTOP, WEB, CLOUD, MOBILE, GAMING, IoT и AI. Мне пришла в голову идея провести беседу в формате небольшого доклада + вопросов/ответов по каждой теме на следующих встречах. Ответственный за ту или иную тему предварительно готовится, вычитывает информацию об основных новшествах, пробует что-то реализовать с помощью выбранной технологии, а затем делится с нами своими мыслями и впечатлениями. В итоге все получают реальный отзыв об инструментарии из проверенного источника из первых уст — очень удобно, учитывая то, что самому попробовать и поштурмить все темы может быть не сподручно, банально руки не дойдут.
Поскольку я некоторое время активно интересуюсь машинным обучением в качестве хобби (и иногда использую для небизнесовых задачек в работе), мне досталась тема AI & ML.NET. В процессе подготовки я наткнулся на замечательные инструменты и материалы, к своему удивлению обнаружил, что про них очень мало информации на Хабре. Ранее в официальном блоге Microsoft писали про релиз ML.Net, и Model Builder в частности. Я бы хотел поделиться тем, как вышел на него и какие получил впечатления от работы с ним. Статья больше про Model Builder, чем про ML в .NET в целом; мы постараемся посмотреть на то, что предлагает MS среднему .NET-разработчику, но глазами подкованного в ML человека. Постараюсь при этом держать баланс между пересказыванием туториала, совсем уж разжевыванием для новичков и описанием деталей для ML-специалистов, которым почему-то потребовалось прийти в .NET.
Основная часть
Итак, беглое гугление про ML в .NET приводит меня на страничку туториала:
Оказывается, есть специальное расширение для Visual Studio под названием Model Builder, которое «позволяет добавить машинное обучение в Ваш проект правой кнопкой мыши» (вольный перевод). Я вкратце пробегусь по основным шагам туториала, которые предлагается проделать, дополню деталями и своими мыслями.
Download and install
Нажимаем кнопку, качаем, устанавливаем. Студию придется перезапустить.
Create your app
Для начала создаем обычное C# приложение. В туториале предлагается создать Core, но и под Framework годится. А дальше, собственно, начинается ML — кликаем правой кнопкой мышки по проекту, затем Add -> Machine Learning. Появившееся окно создания модели мы будем разбирать, ибо именно в нем происходит вся магия.
Pick a scenario
Выбираем «сценарий» своего приложения. На данный момент доступны 5 (туториал немного устарел, там пока 4):
- Sentiment analysis — анализ тональности, binary classification (бинарная классификация), по тексту определяется его эмоциональный окрас окрас, позитивный или негативный.
- Issue classification — multiclass classification (многоклассовая классификация), целевая метка для issue (тикета, ошибки, обращения в поддержку и т.д.) может быть выбрана как один из трех взаимоисключающих вариантов
- Price prediction — regression, классическая задача регрессии, когда выходным результатом является непрерывное число; в примере это оценка квартиры
- Image classification — multiclass classification (многоклассовая классификация), но уже для изображений
- Custom scenario — свой сценарий; вынужден огорчить, что ничего нового в этом варианте не будет, просто на более позднем этапе дадут выбрать один из ранее описанных четырех вариантов.
Заметим, что нет multilabel-классификации, когда целевых метод может быть много одновременно (например, высказывание может быть одновременно оскорбительным, расистским и матерным, а может не быть никаким из этого). Для изображений нет возможность выбора задачи сегментации. Я предполагаю, что с помощью фреймворка они в целом решаемы, однако сегодня фокусируемся именно на билдере. Кажется, что масштабирование визарда на расширение количества задач не является трудной задачей, поэтому стоит ожидать в их будущем.
Download and add data
Предлагается скачать датасет. Из необходимости скачивания на свою машину автоматически делаем вывод о том, что обучение будет происходить на нашей локальной машине. У этого есть как плюсы:
- Вы контролируете все данные, можете подправить, изменить локально и повторить эксперименты.
- Вы не выгружаете данные в облако, таким образом сохраняя приватность. Ведь не выгружаете, да Microsoft? 🙂
так и минусы:
- Скорость обучения ограничена ресурсами Вашей локальной машины.
Далее предлагается выбрать скачанный датасет в качестве инпута типа «Файл». Так же есть вариант использовать «SQL Server» — потребуется указать необходимые реквизиты сервера, затем выбрать таблицу. Если я правильно понял, пока нельзя указать конкретный скрипт. Ниже я пишу про проблемы, которые у меня возникли с этим вариантом.
Train your model
На этом шаге последовательно обучаются различные модели, для каждой выводится скор, и в конце выбирается лучшая. Ах да, я забыл упомянуть, что это AutoML — т.е. лучший алгоритм и параметры (не уверен, см. ниже) будут выбраны автоматически, так что Вам ничего делать не нужно! Предлагается ограничить максимальное время обучения количеством секунд. Эвристика по определению этого времени: https://github.com/dotnet/machinelearning-samples/blob/master/modelbuilder/readme.md#train. На моей машине за дефолтные 10 секунд учится всего одна модель, так что приходится ставить сильно больше. Запускаем, ожидаем.
Тут очень хочется добавить, что названия моделей лично мне показались немного непривычными, например: AveragedPerceptronBinary, FastTreeOva, SdcaMaximumEntropyMulti. Слово «Perceptron» не так часто используется в эти дни, «Ova» вероятно one-vs-all, а «FastTree» я затрудняюсь сказать что.
Еще из интересного — среди алгоритмов-кандидатом присутствует LightGbmMulti. Если я правильно понимаю, это тот самый LightGBM, движок градиентного бустинга, который вместе с CatBoost сейчас оказывает конкуренцию когда-то единолично правившему XGBoost. Он немного расстраивает своей скоростью в текущем исполнении — на моих данных его обучение заняло больше всего времени (порядка 180 секунд). Хотя входные данные — текст, после векторизации колонок тысячи, больше чем входных примеров — это не лучший кейс для бустинга и деревьев в целом.
Evaluate your model
Собственно, оценка результатов модели. На данном шаге можно посмотреть на то, какие целевые метрики были достигнуты, а так же погонять модель вживую. Про сами метрики можно почитать тут: MS и sklearn.
Меня в первую очередь заинтересовал вопрос — на чем тестировалось-то? Поиск по той же страницу с хелпом дает ответ — разбиение очень консервативное, 80% на 20%. Я не нашел возможности это настроить в UI. На практике хотелось бы это контролировать, ибо когда данных реально много, разбиение может быть даже 99% и 1% (по словам Andrew Ng, сам я с такими данными не работал). Так же полезно было бы иметь возможность задать random seed сэмплинга данных, ибо повторяемость в ходе построения и выбора лучшей модели трудно переоценить. Кажется, что добавить эти опции несложно, для сохранения прозрачности и простоты можно скрыть их за каким-нибудь чекбоксом «Extra options».
В консоль в процессе построения модели выводятся таблички со скорами, код генерации которых можно найти в проектах из следующего шага. Можно сделать вывод, что сгенерированный код реально работает, и выводится его честный вывод, никакой бутафории.
Интересное наблюдение — во время написания статьи я еще раз прошелся по шагам билдера, использовал предлагаемый датасет комментариев с Википедии. Но в качестве задачи я выбрал «Custom», затем многоклассовую классификацию как таргет (хотя классов всего два). В итоге скор получился примерно на 10% хуже (порядка 73% против 83%), чем скор со скриншота с бинарной классификацией. По мне это немного странно, ведь система могла бы и догадаться, что класса всего два. В принципе и классификаторы по типу one-vs-all (а-ля один против всех, когда задача многоклассовой классификации сводится к последовательному решению N-задач бинарной по каждому из N классов) тоже должны были в этой ситуации показывать аналогичный бинарной скор.
Generate code
На этом шаге сгенерируются и добавятся в решение (solution) два проекта. В одном из них есть полноценный пример использования модели, а в другой следует заглядывать только если интересны детали реализации.
Для себя обнаружил то, что весь процесс обучения лаконично формируется в пайплайн (привет пайплайнам из sk-learn):
// Data process configuration with pipeline data transformations var processPipeline = mlContext.Transforms.Conversion.MapValueToKey("Sentiment", "Sentiment") .Append(mlContext.Transforms.Text.FeaturizeText("SentimentText_tf", "SentimentText")) .Append(mlContext.Transforms.CopyColumns("Features", "SentimentText_tf")) .Append(mlContext.Transforms.NormalizeMinMax("Features", "Features")) .AppendCacheCheckpoint(mlContext);
(чуть-чуть тронул форматирование кода, чтобы уместилось красиво)
Помните, я говорил про параметры? Я не вижу ни одного кастомного параметра, все значения по умолчанию. Кстати по лейблу SentimentText_tf на выходе FeaturizeText можно сделать вывод, что это term frequency (документация говорит, что это n-grams и char-grams текста; интересно, есть ли там IDF, inversed document frequency).
Consume your model
Собственно, пример использования. Могу отметить только то, что Predict делается элементарно.
Ну вот, собственно, и все — мы рассмотрели все шаги билдера и отметили ключевые моменты. Но эта статья была бы неполной без теста на собственных данных, ведь любой, кто хоть раз сталкивался с ML и AutoML, прекрасно знает, что на стандартных задачках, синтетических тестах и датасетах из интернета любой автомл хорош. Поэтому было решено проверить билдер на своих задачах; тут и далее это всегда работа с текстом или текстом + категориальными фичами.
У меня совершенно неслучайно оказался под рукой датасет с некоторыми ошибками/issue/дефектами, зарегистрированными на одном из проектов. В нем 2949 строк, 8 несбалансированных целевых классов, 4мб.
ML.NET (загрузка, преобразования, алгоритмы из списка ниже; заняло 219 секунд)
| Top 2 models explored | -------------------------------------------------------------------------------- | Trainer MicroAccuracy MacroAccuracy Duration #Iteration| |1 SdcaMaximumEntropyMulti 0,7475 0,5426 176,7 1| |2 AveragedPerceptronOva 0,7128 0,4492 42,4 2| --------------------------------------------------------------------------------
(ужал пустоты в табличке, чтобы поместилось в Markdown)
Моя версия на Python (загрузка, чистка, преобразования, затем LinearSVC; заняло 41 секунду):
Classsification report: precision recall f1-score support Class 1 0.71 0.61 0.66 33 Class 2 0.50 0.60 0.55 5 Class 3 0.65 0.58 0.61 59 Class 4 0.75 0.60 0.67 5 Class 5 0.78 0.86 0.81 77 Class 6 0.75 0.46 0.57 13 Class 7 0.82 0.90 0.86 227 Class 8 0.86 0.79 0.82 169 accuracy 0.80 588 macro avg 0.73 0.67 0.69 588 weighted avg 0.80 0.80 0.80 588
0.80 vs 0.747 Micro и 0.73 vs 0.542 Macro (в определении Макро может быть некоторая неточность, если интересно — в комментариях расскажу).
Я приятно удивлен, всего 5% разницы. На некоторых других датасетах разница была еще меньше, а порой и вовсе не было. Анализируя величину разницы стоит принять во внимание тот факт, что количество сэмплов в датасетах невелико, и, порой, после очередной выгрузки (что-то удаляется, что-то добавляется) я наблюдал подвижки скора на 2-5 процентов.
Пока я самолично экспериментировал, никаких проблем в использовании билдера не возникло. Однако во время презентации коллегам все же встретились несколько косяков:
- Один из датасетов мы попробовали честно загрузить из таблицы в БД, но наткнулись на неинформативное сообщение об ошибке. Я примерно представлял, какого плана текстовые данные там находятся, и сразу прикинул, что проблема может быть в переводах строк. Что ж, загрузил датасет с помощью pandas.read_csv, почистил от \n \r \t, сохранил в tsv, двинулись дальше.
- На обучении очередной модели получили исключение, сообщающее о том, что матрица размером ~ 220000 на 1000 не может комфортно расположиться в памяти, так что обучение остановлено. Модель при этом тоже не сгенерировалась. Что делать дальше — непонятно, вышли из ситуации с помощью подстановки ограничения времени обучения «на глазок» — чтобы падающий алгоритм не успел начать работать.
Кстати, из второго пункта можно сделать вывод о том, что количество слов и n-грам при векторизации не особо-то и ограничивается по верхней границе, и «n» вероятно равен двум. Я могу по своему опыту сказать, что 200к явно слишком большое число. Обычно его либо ограничивают наиболее частыми вхождениями, либо применяют поверх разного рода алгоритмы сокращения размерности, например SVD или PCA.
Выводы
Билдер предлагает на выбор несколько сценариев, в которых я не обнаружил критичных мест, требующих погружения в ML. С этой точки зрения он прекрасно подходит как инструмент «getting started» или решения типичных простых задач здесь и сейчас. Реальные сценарии использования полностью зависят от Вашей фантазии. Можно пойти по предлагаемым MS вариантам:
- решать задачу оценки тональности (sentiment analysis), допустим, в комментариях к продуктам на сайте
- классифицировать тикеты по категориям или командам (issue classification)
- продолжить издеваться над тикетами, но уже с помощью регрессии (price prediction) — оценить временные затраты
А можно вносить что-то свое, например, автоматизировать задачу распределения поступающих ошибок/инцидентов по разработчикам, сведя ее к задаче классификации по тексту (целевая метка — ID/Фамилия разработчика). Или можно порадовать операционистов внутреннего АРМ, которые заполняют поля в карточке с фиксированным набором значений (выпадающий список) по другим полям или текстовому описанию. Для этого понадобится всего лишь подготовить выборку в csv (для экспериментов хватит даже нескольких сотен строк), научить модель прямо из UI Visual Studio и применить ее в своем проекте путем копирования кода из сгенерированного примера. Я веду к тому, что ML.NET по моему мнению вполне пригоден для решения практических, прагматичных, приземленных задач, которые не требуют особой квалификации и попусту отъедают время. Причем применить его можно в самом обычном проекте, который не претендует на инновационность. Автором же такой модели может стать любой .NET-разработчик, который готов освоить новую библиотеку.
У меня немного больше бэкграунд по ML, чем у среднего .NET-разработчика, поэтому для себя я решил так: для картинок наверное нет, для сложных кейсов нет, а для простых табличных задач — однозначно да. На текущий момент мне удобнее сделать любую ML-задачу на более привычном стеке технологий Python/numpy/pandas/sk-learn/keras/pytorch, однако типовой кейс для последующего встраивания в .NET-приложение я бы вполне сделал и с помощью ML.NET.
Кстати приятно, что с текстом фреймворк работает отлично без каких-либо лишних телодвижений и необходимости тюнинга со стороны пользователя. В целом, это не удивительно, ибо на практике на небольших объемах данных старые добрые TfIDF с классификаторами типа SVC/NaiveBayes/LR работают вполне приемлемо. Это обсуждалось на летнем DataFest в докладе от iPavlov — на некотором тестовом наборе word2vec, GloVe, ELMo (вроде) и BERT сравнивались с TfIdf. На тесте удалось достичь превосходства в пару процентов только в одном случае из 7-10 кейсов, хотя объем затраченных ресурсов на обучение совсем не сопоставим.
P.S. Популяризация ML в массах сейчас в тренде, взять даже «Гугловый инструмент для создания ИИ, которым может воспользоваться даже школьник«. Он весь из себя прикольный и интуитивно понятный пользователю, но что там действительно происходит за кадром в облаке — непонятно. В этом для плане для .NET-разработчиков ML.NET с билдером моделей выглядит более привлекательной опцией.
P.S.S. Презентация зашла на ура, коллеги замотивировались попробовать 🙂
Feedback
Кстати, в одной из рассылок с заголовком «ML.NET Model Builder» говорилось:
Give Us Your Feedback
If you run into any issues, feel that something is missing, or really love something about ML.NET Model Builder, let us know by creating an issue in our GitHub repo.
Model Builder is still in Preview, and your feedback is super important in driving the direction we take with this tool!
Данную статью можно считать фидбеком!
Ссылки
ссылка на оригинал статьи https://habr.com/ru/post/476052/
Добавить комментарий