
Технология Optical character recognition (OCR) развивается в мире уже десятки лет. Мы в Яндексе начали разрабатывать собственную технологию OCR, чтобы улучшить свои сервисы и дать пользователям больше возможностей. Картинки — это огромная часть интернета, и без способности их понимать поиск по интернету будет неполным.
Решения для анализа изображений становятся все более востребованными. Это связано с распространением искусственных нейронных сетей и устройств с качественными сенсорами. Понятно, что в первую очередь речь идет о смартфонах, но не только о них.
Сложность задач в области распознавания текста постоянно растет — все начиналось с распознавания отсканированных документов. Потом добавилось распознавание Born-Digital-картинок с текстом из интернета. Затем, с ростом популярности мобильных камер, — распознавание хороших снимков с камеры (Focused scene text). И чем дальше, тем больше параметры усложнялись: текст может быть нечетким (Incidental scene text), написанным с любым изгибом или по спирали, самых разных категорий — от фотографий чеков до прилавков магазинов и вывесок.
Какой путь мы прошли
Распознавание текста — это отдельный класс задач компьютерного зрения. Как и многие алгоритмы компьютерного зрения, до популярности нейросетей оно во многом основывалось на ручных признаках и эвристиках. Однако за последнее время, с переходом на нейросетевые подходы, качество технологии существенно выросло. Посмотрите на пример на фото. Как это происходило, я расскажу дальше.
Сравните сегодняшние результаты распознавания с результатами в начале 2018 года:
 |
 |
| 2018 Увлажняющая n HO -мичеллярная роскошная гладкость вода. бережная мультифункциональная формула использования В качестве средства Sl ДЛЯ вместо очищающего лосьона или тоника Без спирта, красителей, парабенов … |
2019 УВЛАЖНЯЮЩАЯ ТЕРМАЛЬНО-МИЦЕЛЛЯРНАЯ ВОДА «РОСКОШНАЯ ГЛАДКОСТЬ» AUBY Мягкая и бережная мультифункциональная формула для ежедневного использования в качестве средства для демакияжа, вместо очищающего лосьона или тоника. Без спирта, красителей, парабенов … |
Какие трудности нам встретились сначала
В начале своего пути мы делали технологию распознавания для русского и английского языков, а основными сценариями использования были сфотографированные страницы текста и картинки из интернета. Но в ходе работы мы поняли, что этого недостаточно: текст на изображениях встречался на любом языке, на любой поверхности, а картинки порой оказывались самого разного качества. Значит, распознавание должно работать в любой ситуации и на всех типах входящих данных.
И тут мы столкнулись с рядом сложностей. Вот только некоторые:
- Детали. Для человека, привыкшего получать из текста информацию, текст на изображении — это абзацы, строки, слова и буквы, но для нейронной сети все выглядит по-другому. Из-за сложной природы текста сеть вынуждена видеть как картину в целом (например, если люди взялись за руки и выстроили собой надпись), так и мельчайшие детали (во вьетнамском языке похожие символы ử и ừ меняют значение слов). Отдельными сложными задачами являются распознавание текста произвольной формы и нестандартных шрифтов.
- Мультилингвальность. Чем больше языков мы добавляли, тем больше сталкивались с их спецификой: в кириллице и латинице слова состоят из отдельных букв, в арабском они написаны слитно, в японском не выделяются отдельные слова. Некоторые языки используют написание слева направо, некоторые справа налево. Некоторые слова пишутся горизонтально, некоторые вертикально. Универсальный инструмент должен учитывать все эти особенности.
- Структура текста. Для распознавания специфических изображений, например чеков или сложных документов, принципиально важна структура, учитывающая расположение абзацев, таблиц и других элементов.
- Производительность. Технология используется на самых разных устройствах, в том числе в офлайн-режиме, поэтому мы должны были учитывать жесткие требования по производительности.
Выбор модели детекции
Первый шаг к распознаванию текста — определение его положения (детекция).
Детекцию текста можно рассматривать как задачу распознавания объектов, где в качестве объекта могут выступать отдельные символы, слова или строки.
Нам было важно, чтобы модель впоследствии масштабировалась на другие языки (сейчас мы поддерживаем 45 языков).
Во многих исследовательских статьях про детекцию текста используются модели, которые предсказывают положения отдельных слов. Но в случае универсальной модели такой подход имеет ряд ограничений — например, само понятие слова для китайского языка принципиально отличается от понятия слова, к примеру, в английском языке. Отдельные слова в китайском не отделены пробелом. В тайском языке пробелом отбиваются только отдельные предложения.
Вот примеры одного и того же текста на русском, китайском и тайском языках:
Сегодня отличная погода. Замечательный день для прогулки.
今天天气很好 这是一个美丽的一天散步。
สภาพอากาศสมบูรณ์แบบในวันนี้ มันเป็นวันที่สวยงามสำหรับเดินเล่นกันหน่อยแล้ว
Строки же в свою очередь бывают очень вариативными по соотношению сторон. Из-за этого возможности таких распространенных детекционных моделей (например, SSD или RCNN-based) для предсказания линий ограничены, так как эти модели основаны на регионах-кандидатах / анкорных боксах с множеством предопределенных соотношений сторон. Кроме того, линии могут иметь произвольную форму, например изогнутую, поэтому для качественного описания строк недостаточно исключительно описывающего четырехугольника, даже с углом поворота.
Несмотря на то, что положения отдельных символов локальные и описываемые, их недостаток состоит в том, что требуется отдельный этап постобработки — нужно подобрать эвристики для склеивания символов в слова и строки.
Поэтому за основу для детекции мы взяли модель SegLink, основная идея которой — декомпозировать строки/слова на две более локальные сущности: сегменты и связи между ними.
Архитектура детектора
Архитектура модели основывается на SSD, который предсказывает положения объектов сразу на нескольких масштабах признаков. Только помимо предсказания координат отдельных «сегментов» предсказываются также и «связи» между соседними сегментами, то есть принадлежат ли два сегмента одной и той же строке. «Связи» предсказываются как для соседних сегментов на одинаковом масштабе признаков, так и для сегментов, находящихся в смежных областях на соседних масштабах (сегменты c разных масштабов признаков могут незначительно отличаться по размерам и принадлежать одной линии).
Для каждого масштаба каждая ячейка признаков ассоциируется с соответствующим «сегментом». Для каждого сегмента s(x, y, l) в точке (x,y) на масштабе l обучается:
— ps является ли данный сегмент текстом;
— xs, ys, ws, hs, θs — смещение базовых координат и угол наклона сегмента;
— 8 score наличия «связей» с соседними на l-ом масштабе сегментами (Lws,s’, s’ из {s(x’, y’, l)} / s(x, y, l), где x–1 ≤ x’ ≤ x+1, y–1 ≤ y’ ≤ y+1);
— 4 score наличия «связей» с соседними на l-1 масштабе сегментами (Lcs,s’, s’ из {s(x’, y’, l-1)}, где 2x ≤ x’ ≤ 2x+1, 2y ≤ y’ ≤ 2y+1) (что верно благодаря тому, что размерность признаков на соседних масштабах отличается ровно в 2 раза).
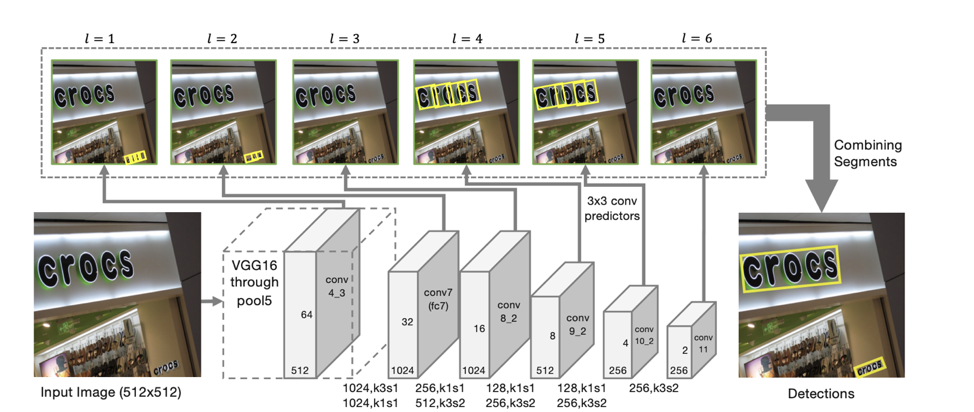
Иллюстрация принципов работы детектора SegLink из статьи Detecting Oriented Text in Natural Images by Linking Segments
По таким предсказаниям, если взять в качестве вершин все сегменты, для которых вероятность того, что они являются текстом больше порога α, а в качестве ребер все связи, вероятность которых больше порога β, то сегменты образуют связные компоненты, каждый из которых описывает линию текста.
Полученная модель имеет высокую обобщающую способность: даже обученная в первых подходах на русских и английских данных, она качественно находила китайский и арабский текст.
Десять скриптов
Если для детекции нам удалось создать модель, которая работает сразу для всех языков, то для распознавания найденных линий такую модель получить заметно сложнее. Поэтому мы решили использовать отдельную модель для каждого скрипта (кириллический, латинский, арабский, иврит, греческий, армянский, грузинский, корейский, тайский). Отдельная общая модель используется для китайского и японского языков из-за большого пересечения по иероглифам.
Общая для всего скрипта модель отличается от отдельной модели для каждого языка менее чем на 1 п.п. качества. В то же время и создание, и внедрение одной модели проще, чем, к примеру, 25 моделей (количество латинских языков, поддерживаемых нашей моделью). Но из-за частого присутствия во всех языках вкраплений английского все наши модели умеют помимо основного скрипта предсказывать также символы латинского алфавита.
Чтобы понять, какую модель необходимо использовать для распознавания, мы вначале определяем принадлежность полученных линий одному из 10 доступных для распознавания скриптов.
Стоит отдельно отметить, что не всегда по линии можно однозначно определить её скрипт. К примеру, цифры или одиночные латинские символы содержатся во многих скриптах, поэтому один из выходных классов модели — «неопределенный» скрипт.
Определение скрипта
Для определения скрипта мы сделали отдельный классификатор. Задача определения скрипта существенно проще, чем задача распознавания, и на синтетических данных нейронная сеть легко переобучается. Поэтому в наших экспериментах существенное улучшение качества модели давало предобучение на задаче распознавания строк. Для этого мы вначале обучали сеть для задачи распознавания для всех имеющихся языков. После этого полученный backbone использовался для инициализации модели на задачу классификации скрипта.
В то время как скрипт у отдельной линии часто бывает достаточно шумным, картинка в целом чаще всего содержит текст на одном языке, либо помимо основного вкрапления английского (или в случае наших пользователей русского). Поэтому для увеличения стабильности мы агрегируем предсказания линий с картинки с целью получения более стабильного предсказания скрипта картинки. Линии с предсказанным классом «неопределённый» не учитываются при агрегации.
Распознавание строк
Следующим шагом, когда мы уже определили положение каждой линии и ее скрипт, нам необходимо распознать последовательность символов из заданного скрипта, которая на ней изображена, то есть из последовательности пикселей предсказать последовательность символов. После множества экспериментов мы пришли к следующей sequence2sequence attention based модели:

Использование CNN+BiLSTM в encoder позволяет получить признаки, улавливающие как локальный, так и глобальный контекст. Для текста это важно — зачастую он написан одним шрифтом (отличить схожие буквы, имея информацию о шрифте, гораздо проще). И чтобы отличить две буквы, написанные через пробел, от идущих подряд, тоже нужны глобальные для линии статистики.
Интересное наблюдение: в полученной модели выходы маски attention для конкретного символа можно использовать для предсказания его позиции на изображении.
Это вдохновило нас попробовать явно «фокусировать» внимание модели. Такие идеи встречались и в статьях — например, в статье Focusing Attention: Towards Accurate Text Recognition in Natural Images.
Так как механизм attention дает вероятностное распределение над пространством признаков, если взять в качестве дополнительного loss сумму выходов attention внутри маски, соответствующей предсказываемой на данном шаге букве, мы получим ту часть «внимания», которая фокусируется непосредственно на ней.
Введя в качестве loss -log(∑i, j∈Mtαi, j), где Mt — маска t-ой буквы, α — выход attention, мы будем поощрять «внимание» за фокусирование на заданном символе и таким образом помогать нейронной сети обучаться лучше.
Для тех обучающих примеров, для которых местоположение отдельных символов неизвестно или неточно (не для всех обучающих данных имеется разметка на уровне отдельных символов, а не слов), — это слагаемое в финальном loss не учитывалось.
Еще одна приятная особенность: такая архитектура позволяет без дополнительных правок предсказывать распознавание линий right-to-left (что важно, к примеру, для таких языков как арабский, иврит). Модель сама начинает выдавать распознавание справа налево.
Быстрая и медленная модели
В процессе мы столкнулись проблемой: для «высоких» шрифтов, то есть шрифтов, вытянутых по вертикали, модель работала плохо. Вызвано это было тем, что размерность признаков на уровне attention в 8 раз меньше, чем размерность исходной картинки из-за страйдов и пулингов в архитектуре сверточной части сети. И местоположения нескольких соседних символов на исходной картинке могут соответствовать местоположению одного и того же вектора признаков, что может приводить к ошибкам на таких примерах. Использование архитектуры с меньшим сужением размерности признаков приводило к росту качества, но также к росту времени обработки.
Чтобы решить эту проблему и избежать увеличения времени обработки, мы сделали следующие доработки модели:
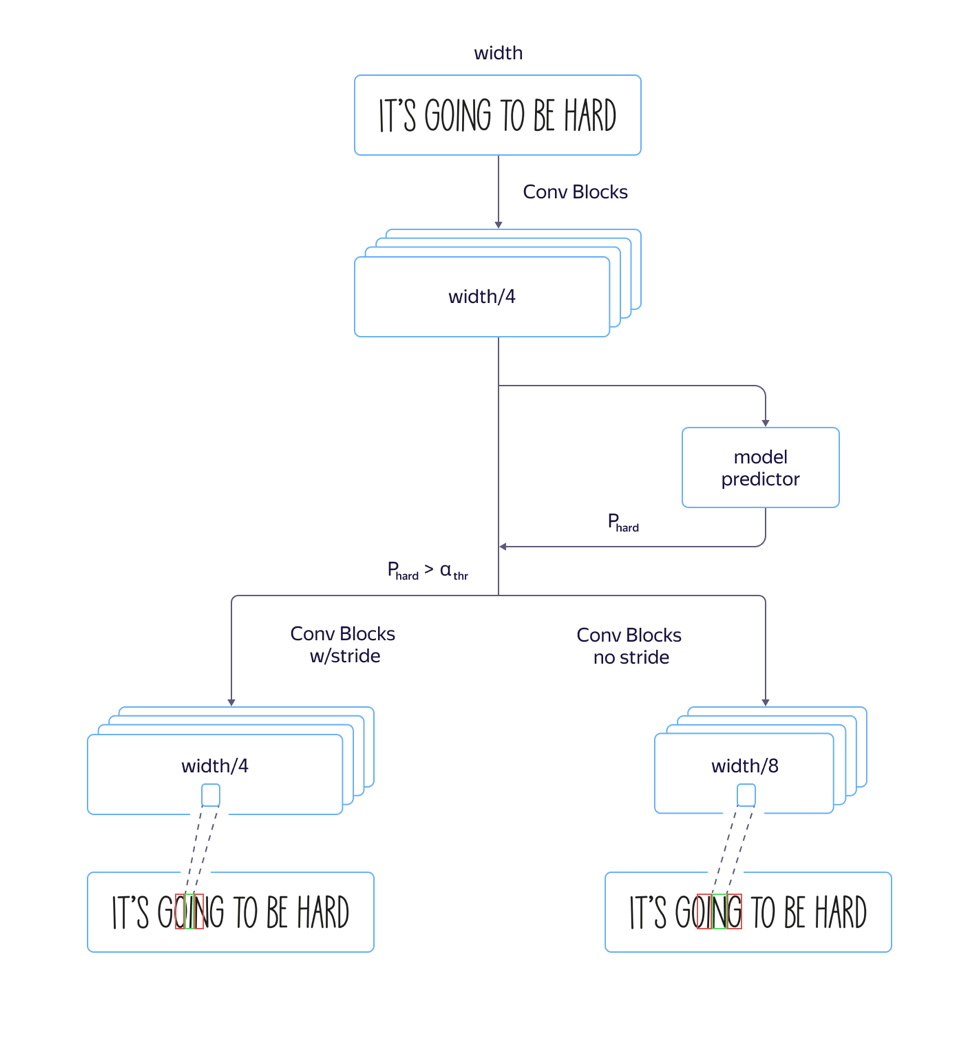
Мы обучили одновременно и быструю модель с большим количеством страйдов, и медленную с меньшим. На слое, где параметры модели начинали отличаться, мы добавили отдельный выход сети, который предсказывал, у какой модели будет меньше ошибка распознавания. Суммарный loss модели складывался из Lsmall + Lbig + Lquality. Таким образом, на промежуточном слое модель училась определять «сложность» данного примера. Далее на этапе применения общая часть и предсказание «сложности» примера считались для всех линий, а в зависимости от его выхода по значению порога в дальнейшем применялась либо быстрая, либо медленная модель. Это позволило нам получить качество, почти не отличающееся от качества долгой модели, при этом скорость увеличилась лишь на 5% процентов вместо предполагаемых 30%.
Данные для обучения
Важный этап создания качественной модели — подготовка большой и разнообразной обучающей выборки. «Синтетическая» природа текста дает возможность генерировать примеры в большом количестве и получать достойные результаты на реальных данных.
После первого подхода к генерации синтетических данных мы внимательно посмотрели на результаты полученной модели и выявили, что модель недостаточно хорошо распознает одиночные буквы ‘I’ из-за смещения в текстах, используемых для создания обучающей выборки. Поэтому мы явно сгенерировали набор «проблемных» примеров, и когда добавили его к исходным данным модели, качество ощутимо выросло. Этот процесс мы повторяли многократно, добавляя все больше сложных срезов, на которых хотели повысить качество распознавания.
Важный момент состоит в том, что сгенерированные данные должны быть разнообразными и похожими на реальные. И если вы хотите от модели, чтобы она работала на фотографиях текста на листках бумаги, а весь синтетический датасет содержит текст, написанный поверх пейзажей, то это может не сработать.
Еще одним важным шагом является использование для обучения тех примеров, на которых текущее распознавание ошибается. При наличии большого количества картинок, для которых нет разметки, можно взять те выходы текущей системы распознавания, в которых она не уверена, и разметить только их, тем самым сократив затраты на разметку.
Для получения сложных примеров мы просили пользователей сервиса Яндекс.Толока за вознаграждение сфотографировать и отправить нам изображения определенной «сложной» группы — например, фотографии упаковок товаров:


Качество работы на «сложных» данных
Мы хотим дать нашим пользователям возможность работать с фотографиями любой сложности, ведь распознать или перевести текст может понадобиться не только на странице книги или отсканированном документе, но и на уличной вывеске, объявлении или упаковке продукта. Поэтому, сохраняя высокое качество работы на потоке книг и документов (этой теме посвятим отдельный рассказ), мы уделяем особое внимание «сложным наборам изображений».
Описанным выше способом мы собрали набор изображений, содержащих текст in the wild, который может быть полезен нашим пользователям: фотографии вывесок, объявлений, табличек, обложек книг, тексты на бытовых приборах, одежде и предметах. На этом наборе данных (ссылка на который ниже) мы оценили качество работы нашего алгоритма.
В качество метрики для сравнения мы использовали стандартную метрику точности и полноты распознавания слов в датасете, а также F-меру. Распознанное слово считается правильно найденным, если его координаты соответствуют координатам размеченного слова (IoU > 0.3) и распознавание совпадает с размеченным с точностью до регистра. Цифры на получившемся датасете приведены ниже:
| Система распознавания | Полнота | Точность | F-мера |
| Yandex Vision | 73.99 | 86.57 | 79.79 |
| Google Cloud Vision API | 73.00 | 73.77 | 73.38 |
| ABBYY Cloud OCR SDK | 45.9 | 69.41 | 55.26 |
Результаты распознавания текста с помощью различных систем по состоянию на 25.10.2019. Результаты верны для данных из домена in the wild и могут существенно отличаться на изображениях другого типа. Датасет, метрики и скрипты для воспроизведения результатов доступны по ссылке.
Следующие шаги
На стыке отдельных шагов, таких как детекция и распознавание, всегда возникают проблемы: малейшие изменения в модели детекции влекут за собой необходимость изменений модели распознавания, поэтому мы активно экспериментируем над созданием end-to-end решения.
Помимо уже описанных путей усовершенствования технологии мы будем развивать направление анализа структуры документа, которая принципиально важна при извлечении информации и востребована у пользователей.
Заключение
Пользователи уже привыкли к удобным технологиям и не задумываясь включают камеру, наводят на вывеску магазина, меню в ресторане или страницу в книжке на иностранном языке и быстро получают перевод. Мы распознаем текст на 45 языках с подтвержденной точностью, и возможности будут только расширяться. Набор инструментов внутри Яндекс.Облака дает возможность любому желающему использовать те наработки, которые в Яндексе долгое время делали для себя.
Сегодня можно просто взять готовую технологию, интегрировать в собственное приложение и использовать для того, чтобы создавать новые продукты и автоматизировать собственные процессы. Документация по нашему OCR доступна по ссылке.
Что почитать:
- D. Karatzas, S. R. Mestre, J. Mas, F. Nourbakhsh, and P. P. Roy, “ICDAR 2011 robust reading competition-challenge 1: reading text in born-digital images (web and email),” in Document Analysis and Recognition (ICDAR), 2011 International Conference on. IEEE, 2011, pp. 1485–1490.
- Karatzas D. et al. ICDAR 2015 competition on robust reading //2015 13th International Conference on Document Analysis and Recognition (ICDAR). – IEEE, 2015. – С. 1156-1160.
- Chee-Kheng Chng et. al. ICDAR2019 Robust Reading Challenge on Arbitrary-Shaped Text (RRC-ArT) [arxiv:1909.07145v1]
- ICDAR 2019 Robust Reading Challenge on Scanned Receipts OCR and Information Extraction rrc.cvc.uab.es/?ch=13
- ShopSign: a Diverse Scene Text Dataset of Chinese Shop Signs in Street Views [arxiv:1903.10412]
- Baoguang Shi, Xiang Bai, Serge Belongie Detecting Oriented Text in Natural Images by Linking Segments [arxiv:1703.06520].
- Zhanzhan Cheng, Fan Bai, Yunlu Xu, Gang Zheng, Shiliang Pu, Shuigeng Zhou Focusing Attention: Towards Accurate Text Recognition in Natural Images [arxiv:1709.02054].
ссылка на оригинал статьи https://habr.com/ru/company/yandex/blog/475956/
Добавить комментарий