
Балансировщики нагрузки играют в веб-архитектуре ключевую роль. Они позволяют распределять нагрузку по нескольким бэкендам, тем самым улучшая масштабируемость. А поскольку у нас сконфигурировано несколько бэкендов, сервис становится высокодоступным, потому что в случае сбоя на одном сервере балансировщик может выбирать другой работающий сервер.
Поигравшись с профессиональными балансировщиками наподобие NGINX, я попробовал ради веселья создать простенький балансировщик. Написал я его на Go, это современный язык, поддерживающий полноценный параллелизм. Стандартная библиотека в Go имеет широкие возможности и позволяет писать высокопроизводительные приложения с меньшим количеством кода. К тому же для простоты распространения она генерирует единственный статически скомпонованный бинарник.
Как работает наш балансировщик
Для распределения нагрузки по бэкендам используются разные алгоритмы. Например:
- Round Robin — нагрузка распределяется равномерно, с учётом одинаковой вычислительной мощности серверов.
- Weighted Round Robin — в зависимости от вычислительной мощности серверам могут присваиваться разные веса.
- Least Connections — нагрузка распределяется по серверам с наименьшим количеством активных подключений.
В нашем балансировщике мы реализуем простейший алгоритм — Round Robin.
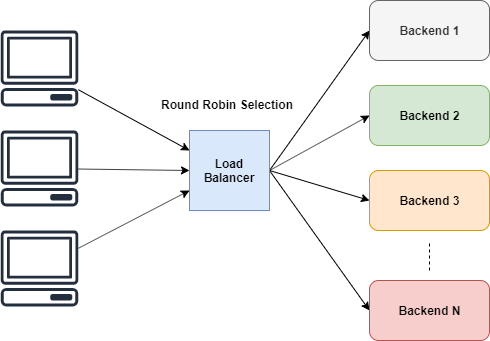
Выбор в Round Robin
Алгоритм Round Robin прост. Он даёт всем исполнителям одинаковые возможности по выполнению задач.
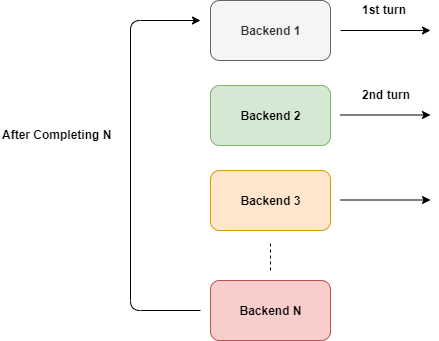
Выбор серверов в Round Robin для обработки входящих запросов.
Как показано на иллюстрации, алгоритм выбирает серверы по кругу, циклически. Но мы не можем выбирать их напрямую, верно?
А если сервер лежит? Вероятно, нам не нужно отправлять на него трафик. То есть сервер не может использоваться напрямую, пока мы не приведём его в нужное состояние. Нужно направлять трафик только на те серверы, которые запущены и работают.
Определим структуры
Нам нужно отслеживать все подробности, связанные с бэкендом. Необходимо знать, живой ли он, а также отслеживать URL. Для этого мы можем определить такую структуру:
type Backend struct { URL *url.URL Alive bool mux sync.RWMutex ReverseProxy *httputil.ReverseProxy }Не волнуйтесь, я поясню значения полей в Backend.
Теперь в балансировщике нужно как-то отслеживать все бэкенды. Для этого можно воспользоваться Slice и счётчиком переменных. Определим его в ServerPool:
type ServerPool struct { backends []*Backend current uint64 }
Использование ReverseProxy
Как мы уже определили, суть балансировщика в распределении трафика по разным серверам и возвращении результатов клиенту. Как сказано в документации Go:
ReverseProxy — это обработчик HTTP, который берёт входящие запросы и отправляет на другой сервер, проксируя ответы обратно клиенту.
Именно то, что нам нужно. Не надо изобретать колесо. Можно просто транслировать наши запросы через ReverseProxy.
u, _ := url.Parse("http://localhost:8080") rp := httputil.NewSingleHostReverseProxy(u) // initialize your server and add this as handler http.HandlerFunc(rp.ServeHTTP) C помощью httputil.NewSingleHostReverseProxy(url) можно инициализировать ReverseProxy, который будет транслировать запросы на переданный url. В приведённом выше примере все запросы переданы на localhost:8080, а результаты отосланы клиенту.
Если посмотреть на сигнатуру метода ServeHTTP, то в ней можно найти сигнатуру HTTP-обработчика. Поэтому можно передавать его HandlerFunc в http.
Другие примеры есть в документации.
Для нашего балансировщика можно инициировать ReverseProxy с ассоциированным URL в Backend, чтобы ReverseProxy маршрутизировал запросы в URL.
Процесс выбора серверов
В ходе очередного выбора сервера нам нужно пропускать лежащие серверы. Но необходимо организовать подсчёт.
Многочисленные клиенты будут подключаться к балансировщику, и когда каждый из них попросит следующий узел передать трафик, может возникнуть состояние гонки. Для предотвращения этого мы можем блокировать ServerPool с помощью mutex. Но это будет избыточно, к тому же мы вообще не хотим блокировать ServerPool. Нам лишь нужно увеличить счётчик на единицу.
Наилучшим решением, соблюдающим эти требования, будет атомарное инкрементирование. Go поддерживает его с помощью пакета atomic.
func (s *ServerPool) NextIndex() int { return int(atomic.AddUint64(&s.current, uint64(1)) % uint64(len(s.backends))) }Мы атомарно увеличиваем текущее значение на единицу и возвращаем индекс, изменяя длину массива. Это означает, что значение всегда должно лежать в диапазоне от 0 до длины массива. В конце нас будет интересовать конкретный индекс, а не весь счётчик.
Выбор живого сервера
Мы уже знаем, что наши запросы циклически ротируются по всем серверам. И нам нужно лишь пропускать неработающие.
GetNext() всегда возвращает значение, лежащее в диапазоне от 0 до длины массива. В любой момент мы можем получить следующий узел, и если он неактивен, нужно в рамках цикла искать дальше по массиву.
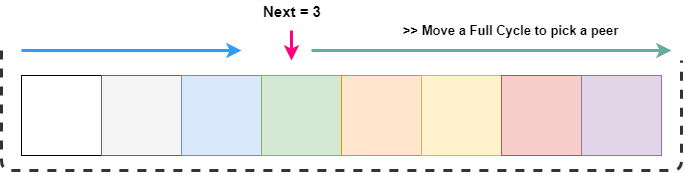
Циклически проходим по массиву.
Как показано на иллюстрации, мы хотим пройти от следующего узла до конца списка. Это можно сделать с помощью next + length. Но для выбора индекса нужно ограничить его рамками длины массива. Это легко можно сделать с помощью операции модифицирования.
После того, как мы в ходе поиска нашли работающий сервер, его нужно пометить как текущий:
// GetNextPeer returns next active peer to take a connection func (s *ServerPool) GetNextPeer() *Backend { // loop entire backends to find out an Alive backend next := s.NextIndex() l := len(s.backends) + next // start from next and move a full cycle for i := next; i < l; i++ { idx := i % len(s.backends) // take an index by modding with length // if we have an alive backend, use it and store if its not the original one if s.backends[idx].IsAlive() { if i != next { atomic.StoreUint64(&s.current, uint64(idx)) // mark the current one } return s.backends[idx] } } return nil }
Избегаем состояния гонки в структуре Backend
Здесь нужно помнить о важной проблеме. Структура Backend содержит переменную, которую могут изменять или запрашивать одновременно несколько горутин.
Мы знаем, что читать переменную будет больше горутин, чем записывать в неё. Поэтому для сериализации доступа к Alive мы выбрали RWMutex.
// SetAlive for this backend func (b *Backend) SetAlive(alive bool) { b.mux.Lock() b.Alive = alive b.mux.Unlock() } // IsAlive returns true when backend is alive func (b *Backend) IsAlive() (alive bool) { b.mux.RLock() alive = b.Alive b.mux.RUnlock() return }
Балансируем запросы
Теперь можно сформулировать простой метод для балансировки наших запросов. Он будет сбоить лишь в том случае, если упадут все серверы.
// lb load balances the incoming request func lb(w http.ResponseWriter, r *http.Request) { peer := serverPool.GetNextPeer() if peer != nil { peer.ReverseProxy.ServeHTTP(w, r) return } http.Error(w, "Service not available", http.StatusServiceUnavailable) } Этот метод можно передать HTTP-серверу просто в виде HandlerFunc.
server := http.Server{ Addr: fmt.Sprintf(":%d", port), Handler: http.HandlerFunc(lb), }
Маршрутизируем трафик только на работающие серверы
У нашего балансировщика серьёзная проблема. Мы не знаем, работает ли сервер. Чтобы узнать это, нужно проверить сервер. Сделать это можно двумя способами:
- Активный: выполняя текущий запрос, мы обнаруживаем, что выбранный сервер не отвечает, и помечаем его как нерабочий.
- Пассивный: можно пинговать серверы с каким-то интервалом и проверять статус.
Активно проверяем работающие серверы
При любой ошибке ReverseProxy инициирует функцию обратного вызова ErrorHandler. Это можно применять для обнаружения сбоев:
proxy.ErrorHandler = func(writer http.ResponseWriter, request *http.Request, e error) { log.Printf("[%s] %s\n", serverUrl.Host, e.Error()) retries := GetRetryFromContext(request) if retries < 3 { select { case <-time.After(10 * time.Millisecond): ctx := context.WithValue(request.Context(), Retry, retries+1) proxy.ServeHTTP(writer, request.WithContext(ctx)) } return } // after 3 retries, mark this backend as down serverPool.MarkBackendStatus(serverUrl, false) // if the same request routing for few attempts with different backends, increase the count attempts := GetAttemptsFromContext(request) log.Printf("%s(%s) Attempting retry %d\n", request.RemoteAddr, request.URL.Path, attempts) ctx := context.WithValue(request.Context(), Attempts, attempts+1) lb(writer, request.WithContext(ctx)) }При разработке этого обработчика ошибок мы использовали возможности замыканий. Это позволяет нам захватывать в наш метод такие внешние переменные, как серверный URL. Обработчик проверяет счётчик повторов, и если он меньше 3, то мы снова отправляем тот же запрос тому же серверу. Это делается потому, что из-за временных ошибок сервер может отбрасывать наши запросы, но вскоре он становится доступен (возможно, у сервера не было свободных сокетов для новых клиентов). Так что нужно настроить таймер задержки для новой попытки примерно через 10 мс. С каждым запросом мы увеличиваем счётчик попыток.
После сбоя каждой попытки мы помечаем сервер как нерабочий.
Теперь нужно назначить для того же запроса новый сервер. Делать мы это будем с помощью счётчика попыток, использующего пакет context. После увеличения счётчика попыток мы передаём его в lb для выбора нового сервера для обработки запроса.
Мы не можем делать это бесконечно, так что будем проверять в lb, не достигнуто ли максимальное количество попыток, прежде чем продолжить обработку запроса.
Можно просто получить счётчик попыток из запроса, если он достиг максимума, то мы прерываем запрос.
// lb load balances the incoming request func lb(w http.ResponseWriter, r *http.Request) { attempts := GetAttemptsFromContext(r) if attempts > 3 { log.Printf("%s(%s) Max attempts reached, terminating\n", r.RemoteAddr, r.URL.Path) http.Error(w, "Service not available", http.StatusServiceUnavailable) return } peer := serverPool.GetNextPeer() if peer != nil { peer.ReverseProxy.ServeHTTP(w, r) return } http.Error(w, "Service not available", http.StatusServiceUnavailable) }Это рекурсивная реализация.
Использование пакета context
Пакет context позволяет сохранять полезные данные в HTTP-запросах. Мы будем активно это использовать для отслеживания данных, относящихся к запросам — счётчиков Attempt и Retry.
Во-первых, нужно задать ключи для контекста. Рекомендуется использовать не строковые, а уникальные числовые значения. В Go есть ключевое слова iota для инкрементальной реализации констант, каждая из которых содержит уникальное значение. Это прекрасное решение для определения числовых ключей.
const ( Attempts int = iota Retry ) Затем можно извлечь значение, как мы обычно делаем с помощью HashMap. Возвращаемое по умолчанию значение может зависеть от текущей ситуации.
// GetAttemptsFromContext returns the attempts for request func GetRetryFromContext(r *http.Request) int { if retry, ok := r.Context().Value(Retry).(int); ok { return retry } return 0 }
Пассивная проверка серверов
Пассивные проверки позволяют идентифицировать и восстанавливать упавшие серверы. Мы пингуем их с определённым интервалом, чтобы определить их статус.
Для пингования попробуем установить TCP-соединение. Если сервер отвечает, мы помечаем его рабочим. Этот метод можно адаптировать для вызова специфических конечных точек наподобие /status. Удостоверьтесь, что закрыли подключение после его создания, чтобы уменьшить дополнительную нагрузку на сервер. Иначе он будет пытаться поддерживать это подключение и в конце концов исчерпает свои ресурсы.
// isAlive checks whether a backend is Alive by establishing a TCP connection func isBackendAlive(u *url.URL) bool { timeout := 2 * time.Second conn, err := net.DialTimeout("tcp", u.Host, timeout) if err != nil { log.Println("Site unreachable, error: ", err) return false } _ = conn.Close() // close it, we dont need to maintain this connection return true }Теперь можно итерировать серверы и отмечать их статусы:
// HealthCheck pings the backends and update the status func (s *ServerPool) HealthCheck() { for _, b := range s.backends { status := "up" alive := isBackendAlive(b.URL) b.SetAlive(alive) if !alive { status = "down" } log.Printf("%s [%s]\n", b.URL, status) } }Для периодического запуска этого кода можно запустить в Go таймер. Он позволит слушать события в канале.
// healthCheck runs a routine for check status of the backends every 2 mins func healthCheck() { t := time.NewTicker(time.Second * 20) for { select { case <-t.C: log.Println("Starting health check...") serverPool.HealthCheck() log.Println("Health check completed") } } } В этом коде канал <-t.C будет возвращать значение каждые 20 секунд. select позволяет определять это событие. При отсутствии ситуации default он ждёт, пока хотя бы один case может быть выполнен.
Теперь запускаем код в отдельной горутине:
go healthCheck()
Заключение
В этой статье мы рассмотрели много вопросов:
- Алгоритм Round Robin
- ReverseProxy из стандартной библиотеки
- Мьютексы
- Атомарные операции
- Замыкания
- Обратные вызовы
- Операция выбора
Есть ещё много способов улучшить наш балансировщик. Например:
- Использовать кучу для сортировки живых серверов, чтобы уменьшить область поиска.
- Собирать статистику.
- Реализовать алгоритм weighted round-robin c наименьшим количеством коннектов.
- Добавить поддержку конфигурационных файлов.
И так далее.
Исходный код лежит здесь.
ссылка на оригинал статьи https://habr.com/ru/company/mailru/blog/476276/
Добавить комментарий