Бывает смотришь фильм, и в голове только один вопрос – «я что опять попался на кликбейт?». Решим эту проблему и будем смотреть только годное кино. Предлагаю немного поэкспериментировать с данными и написать простую нейросеть для оценки фильма.
В основе нашего эксперимента лежит технология сентимент-анализа для определения настроения аудитории к какому-либо продукту. В качестве данных берем датасет обзоров пользователей на фильмы IMDb. Среда разработки Google Colab позволит быстро обучать нейросеть благодаря бесплатному доступу к GPU (NVidia Tesla K80).
Я использую библиотеку Keras, с помощью которой постою универсальную модель для решения подобных задач машинного обучения. Мне понадобится backend TensorFlow, дефолтная версия в Colab 1.15.0, поэтому просто обновим до 2.0.0.
from __future__ import absolute_import, division, print_function, unicode_literals import tensorflow as tf !tf_upgrade_v2 -h Далее импортируем все необходимые модули для предварительной обработки данных и построения модели. В предыдущих статьях делается акцент на библиотеках, можно заглянуть туда.
%matplotlib inline import matplotlib import matplotlib.pyplot as plt
import numpy as np from keras.utils import to_categorical from keras import models from keras import layers from keras.datasets import imdb
Разбор данных IMDb
Датасет IMDb состоит из 50 000 обзоров фильмов от пользователей, помеченных как положительные (1) и отрицательные (0).
- Рецензии предварительно обрабатываются, и каждая из них кодируется последовательностью индексов слов в виде целых чисел
- Слова в обзорах индексируются по их общей частоте появления в датасете. Например, целое число «2» кодирует второе наиболее частое используемое слово
- 50 000 обзоров разделены на два набора: 25 000 для обучения и 25 000 для тестирования
Загружаем датасет, который встроен в Keras. Поскольку данные разделены на обучение и тест в пропорции 50-50, я соединю их, чтобы в последствии разделить на 80-20.
from keras.datasets import imdb (training_data, training_targets), (testing_data, testing_targets) = imdb.load_data(num_words=10000) data = np.concatenate((training_data, testing_data), axis=0) targets = np.concatenate((training_targets, testing_targets), axis=0)
Изучение данных
Посмотрим на то, с чем мы работаем.
print("Categories:", np.unique(targets)) print("Number of unique words:", len(np.unique(np.hstack(data)))) 
length = [len(i) for i in data] print("Average Review length:", np.mean(length)) print("Standard Deviation:", round(np.std(length))) 
Можно видеть, что все данные относятся к двум категориям: 0 или 1, что представляет собой настроение обзора. Весь датасет содержит 9998 уникальных слов, средний размер обзора составляет 234 слова со стандартным отклонением 173.
Посмотрим на первый обзор из данного датасета, который помечен как положительный.
print("Label:", targets[0]) print(data[0]) 
index = imdb.get_word_index() reverse_index = dict([(value, key) for (key, value) in index.items()]) decoded = " ".join( [reverse_index.get(i - 3, "#") for i in data[0]] ) print(decoded) 
Подготовка данных
Пришло время подготовить данные. Нужно векторизовать каждый обзор и заполнить его нулями, чтобы вектор содержал ровно 10 000 чисел. Это означает, что каждый обзор, который короче 10 000 слов, мы заполняем нулями. Я делаю это потому, что самый большой обзор имеет почти такой же размер, а каждый элемент входных данных нашей нейронной сети должен иметь одинаковый размер. Также нужно выполнить преобразование переменных в тип float.
def vectorize(sequences, dimension = 10000): results = np.zeros((len(sequences), dimension)) for i, sequence in enumerate(sequences): results[i, sequence] = 1 return results data = vectorize(data) targets = np.array(targets).astype("float32")Далее делю датасет на обучающие и тестовые данные как и договаривались 4:1.
test_x = data[:10000] test_y = targets[:10000] train_x = data[10000:] train_y = targets[10000:]Создаем и обучаем модель
Дело за малым, осталось только написать модель и натренировать ее. Начать следует с выбора типа. В Keras доступны два типа моделей: последовательные и с функциональным API. Затем нужно добавить входные, скрытые и выходные слои.
Для предотвращения переобучения будем использовать между ними исключение («dropout»).На каждом слое используется функция «dense» для полного соединения слоев друг с другом. В скрытых слоях будем используем функцию активации «relu», это практически всегда приводит к удовлетворительным результатам. На выходном слое используем сигмоидную функцию, которая выполняет перенормировку значений в диапазоне от 0 до 1.
Я использую оптимизатор «adam», он будет изменять веса в процессе обучения.
В качестве функции потерь используем бинарную кросс-энтропию, в качестве метрики оценки — точность.
Теперь можно обучить нашу модель. Мы будем делать это с размером партии 500 и только тремя эпохами, поскольку было выявлено, что модель начинает переобучаться, если тренировать ее дольше.
model = models.Sequential() # Input - Layer model.add(layers.Dense(50, activation = "relu", input_shape=(10000, ))) # Hidden - Layers model.add(layers.Dropout(0.3, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) model.add(layers.Dropout(0.2, noise_shape=None, seed=None)) model.add(layers.Dense(50, activation = "relu")) # Output- Layer model.add(layers.Dense(1, activation = "sigmoid")) model.summary() # compiling the model model.compile( optimizer = "adam", loss = "binary_crossentropy", metrics = ["accuracy"] ) results = model.fit( train_x, train_y, epochs= 3, batch_size = 500, validation_data = (test_x, test_y) ) print("Test-Accuracy:", np.mean(results.history["val_acc"])) 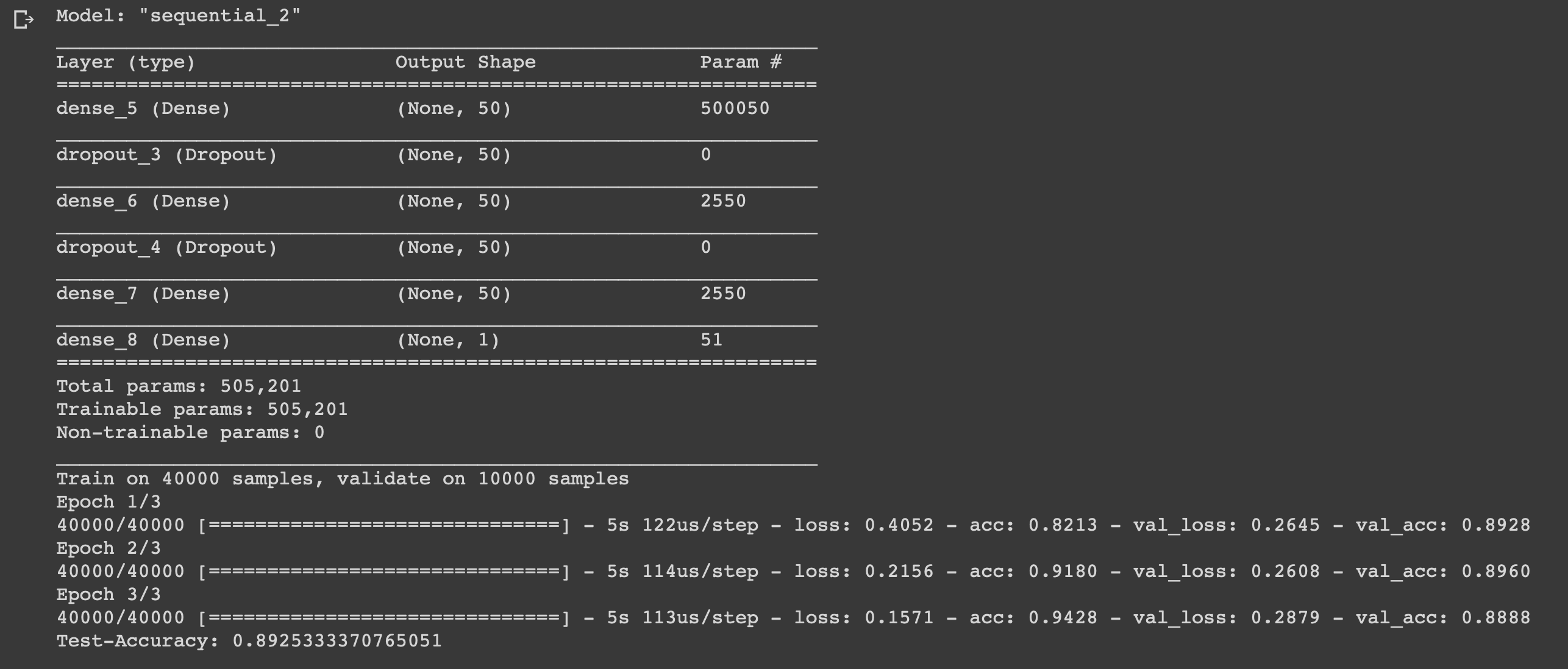
Заключение
Мы создали простую нейронную сеть с шестью слоями, которая может вычислять настроение авторов кинорецензий с точностью 0,89. Конечно, что бы смотреть классные фильмы вовсе необязательно писать нейросеть, но это был лишь еще один пример того, как можно использовать данные, извлекать из них пользу, ведь для того они и нужны. Нейросеть является универсальной за счет простоты своего строения, изменяя некоторые параметры можно адаптировать ее для совершенно других задач.
Свои идеи смело пишите в комментарии.
ссылка на оригинал статьи https://habr.com/ru/post/477630/
Добавить комментарий