
Привет, Хабр. Недавно прошло соревнование от Тинькофф и McKinsey. Конкурс проходил в два этапа: первый — отборочный, в kaggle формате, т.е. отсылаешь предсказания — получаешь оценку качества предсказания; побеждает тот, у кого лучше оценка. Второй — онсайт хакатон в Москве, на который проходит топ 20 команд первого этапа. В этой статье я расскажу об отборочном этапе, где мне удалось занять первое место и выиграть макбук. Команда на лидерборде называлась «дети Лёши».
Соревнование проходило с 19 сентября до 12 октября. Я начал решать ровно за неделю до конца и решал почти фулл-тайм.
Краткое описание соревнования:
Летом в банковском приложении Тинькофф появились stories (как в Instagram). На story можно отреагировать лайком, дизлайком, скипнуть или просмотреть до конца. Задача предсказать реакцию пользователя на story.
Соревнование по большей части табличное, но в самих историях есть текст и картинки.
План рассказа
- Метрика
- Данные и Feature engineering
- Какую задачу мы решаем и как формировать предсказание?
- Модель
- Киллер-фичи
- Оптимизация модели
- Интересные наблюдения
- Трешхолд предсказаний
- Результаты соревнования
- Что не сработало
- Выводы

Метрика
Прогноз реакции может принимать значение от -1 до 1 включительно — чем оно ближе к 1, тем выше вероятность получить лайк. А при значении -1 лучше убрать эту историю долой с глаз пользователя.
Для проверки точности решений используется формула, нормированная на максимально возможный результат:
Какие данные есть:
- Базовая информация о пользователе
- Транзакции пользователей
- Информация о story (json, из которого можно её сконструировать)
- История реакций пользователей на stories.
Далее я подробно расскажу о каждом кусочке данных, как я его обрабатывал и какие признаки (далее фичи) извлекал.
Информация о пользователе

что есть изначально:
- id пользователя
- анонимизированные продукты банка, которые пользователь открыл (OPN), пользуется (UTL) или закрыл (CLS)
- пол, бинаризованный возраст, семейное положение, время первого захода в приложение
- job_title — то, что люди сами пишут о себе
- job_position_cd — должность человека, как одна из 22 категорий
как фичи используем всё вышеперечисленное кроме job_title, т.к. предполагаем, что job_position_cd нормально описывает должность человека.
Транзакции

что есть изначально:
- id пользователя
- день, месяц транзакции
- сумма транзакции (бинаризована с шагом 250)
- merchant_id — внутренний банковский id кассового аппарата. В дальнейшем не используется.
- merchant_mcc
MCC — Merchant category code. Это стандартизованный код услуги, которую предоставляет получатель. Эта информация открыта, вот расшифровка. Эти коды можно удобно разбить на категории, например: entertainment, hotels и т.п.
Для каждого customer_id сопоставим следующие фичи:
- посчитаем сумму расходов, средний чек, стандартное отклонение
- количество транзакций
- разобъём mcc коды на 20 категорий, посчитаем сколько человек потратил денег на эту категорию. Получим 20 фичей
- ещё 20 фичей получим, разделив расходы в категории на сумму расходов. Т.е. получим процент денег потраченных на категорию.
Stories
Всего историй у нас 959.
что есть изначально:
- id истории
- json истории.
выглядит json подобным образом:

Это такое дерево элементов, где каждый элемент описывается ключами: [‘guid’, ‘type’, ‘description’, ‘properties’, ‘content’]. В ‘content’ лежит список дочерних элементов. История состоит из страниц. На страницу накиданы фон, текст, картинки. Конструктора историй у нас не было, а самому отрисовать всё это достаточно сложно и не факт, что значительно поможет в дальнейшем.
Регулярками вытащим весь текст и соответствующий размер шрифта. Извлечём следующие фичи:
- количество страниц, ссылок, всего элементов
- средний размер шрифта текста
- количество текстовых элементов
- «объём текста» — эвристика, чтобы взвешенно учесть длину текста в зависимости от размера шрифта.
def get_text_amount(all_text, font_sizes): assert len(all_text) == len(font_sizes) lengths = np.array(list(map(len, all_text))) sizes = (np.array(font_sizes) / 100)**2 return (lengths * sizes).sum()
- Возьмём теперь весь текст, с помощью dostoevsky определим семантику текста: [‘neutral’, ‘negative’, ‘skip’, ‘speech’, ‘positive’]. И добавим это в качестве 5 фичей
Реакции

что есть изначально:
- id пользователя и истории
- время
- реакция
Обработаем время и как фичи добавим:
- день недели
- час, минута
Далее ещё добавится группа фичей исходя из данных по реакциям, а пока что идём в бой с этим арсеналом фичей делать бейзлайн.
Какую задачу мы решаем и как формировать предсказание?
Лучший подход, который использовал весь топ, следующий: cведём задачу к многоклассовой классификации, т.е. предсказываем вероятность каждой реакции. Считаем матожидание оценки для данной истории :
Бинаризуем :
— наш ответ для объекта , который может принимать значение
Модель
С самого начала и до конца я использовал CatBoost. Обусловлено это тем, что CatBoost из коробки строит полезные статистики для категориальных фичей. А статистика по пользователю — то, насколько он склонен к каким реакциям, и статистика по истории — то, как чаще всего не неё реагируют, являются самыми сильными фичами в этой задаче.
Как CatBoost работает с категориальными фичами хорошо объяснено в документации.
TLDR:
- генерирует несколько перестановок данных
- идёт по-порядку и строит mean target encoding (mte) по тем объектам, которые он уже видел
берём значение признака, например, один из customer_id, считаем процент случаев, когда этот customer отреагировал лайком, дизлайком, скипнул или просмотрел. Получим 4 числа. Заменяем customer_id на эти 4 числа и используем их как признаки. Делаем так для каждого customer_id.
Текущий результат
С текущими фичами, с неоптимизированным катбустом, на публичном лидерборде я занимал на тот момент 11 место с результатом 0.31209
Киллер фичи
В какой-то момент появилась гипотеза, что приложение может показывать истории чаще или реже в зависимости от того, как пользователь отреагировал на неё ранее. Давайте тогда добавим фичи, которые будут говорить:
- сколько раз пользователь видел соответствующую историю в прошлом/будущем, в течение месяца/дня/часа/всего
- время, которое прошло с последнего просмотра этой же истории
- время, через которое пользователь в следующий раз посмотрит эту же историю
- на самом деле у пользователя в одну секунду загружается сразу несколько историй, обычно около 5-7. Назовём этот набор историй группой. Я добавил это количество историй в группе как фичу, что дало большой прирост качества.
Конечно же, эти фичи использовать в продакшне нельзя, т.к. их банально не будет на момент применения модели, но в соревновании любые средства хороши.
Итак, сказано — сделано. Получили 0.35657 на лидерборде.
Оптимизация модели
Перебирал параметры я с помощью байесовской оптимизации
Из интересного можно упомянуть параметр max_ctr_complexity, который отвечает за максимальное количество категориальных фичей, которые могут быть скомбинированы. Пример под спойлером.
Assume that the objects in the training set belong to two categorical features: the musical genre (“rock”, “indie”) and the musical style (“dance”, “classical”). These features can occur in different combinations. CatBoost can create a new feature that is a combination of those listed (“dance rock”, “classic rock”, “dance indie”, or “indie classical”).
Интересные наблюдения
-
CatBoost можно обучать на GPU, это заметно ускоряет обучение, но также вводит много ограничений, особенно касательно категориальных фичей. В этой задаче обучение на GPU давало результат сильно хуже, чем на CPU.
-
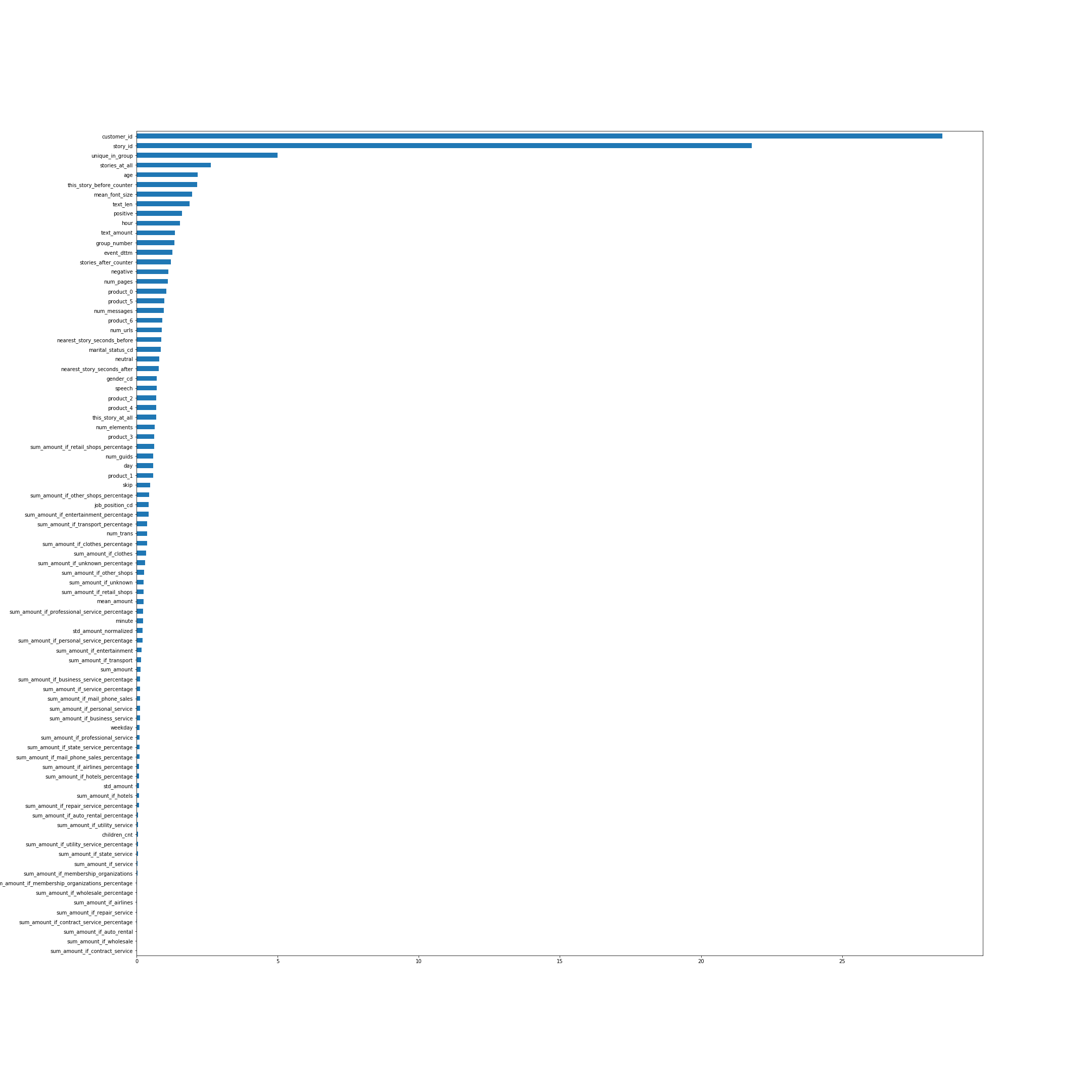
Важность фичей по мнению CatBoost. Во многом названия фичей говорят сами за себя, но некоторые, не самые очевидные, из топа, я поясню:
- unique_in_group — количество историй в группе. (Внутри группы они всегда уникальные, просто на момент создания фичи я этого не знал)
- stories_at_all — количество историй, которое просмотрел человек и в будущем, и в прошлом.
- this_story_before_counter — сколько раз человек посмотрел эту историю ранее.
- text_amount — та эвристика с объёмом текста.
- group_number — порядковый номер группы.
- nearest_story_seconds_before/after — по существу это время до показа следующей группы.
Картинка кликабельна.
-
Давайте посмотрим на распределение реакций с течением времени:

Т.е. в какой то момент распределение по реакциям сильно меняется.
Далее хочется получить какое-нибудь подтверждение, что на тесте распределение такое же, как и в конце тренировочной выборки. Зашлём как предсказание все единички, получим результат 0.00237. Предскажем все единички на последней части трейна — получим около 0.009, на первой части — около -0.22. Значит распределение на тесте скорее всего такое же, как в конце трейна и точно не похоже на основную часть. Отсюда рождается гипотеза, что если подправить распределение в наших предсказаниях, то результат на лидерборде сильно улучшится, т.к. распределения на трейне и на тесте отличаются.
Трешхолд предсказаний
На последнем шаге получения итоговых предсказаний добавим трешхолд:
В последней модели у меня было что-то около 66% единичек, если бинаризовать с трешхолдом равным 0. Оказалось, что действительно, уменьшение количества +1 давало сильный прирост качества. Оценивались только последние 3 посылки, поэтому я заслал предсказания лучшей модели с разными трешхолдами так, чтобы процент плюс единичек был примерно 62, 58 и 54.
По итогу на публичном лидерборде мой лучший результат был 0.37970.
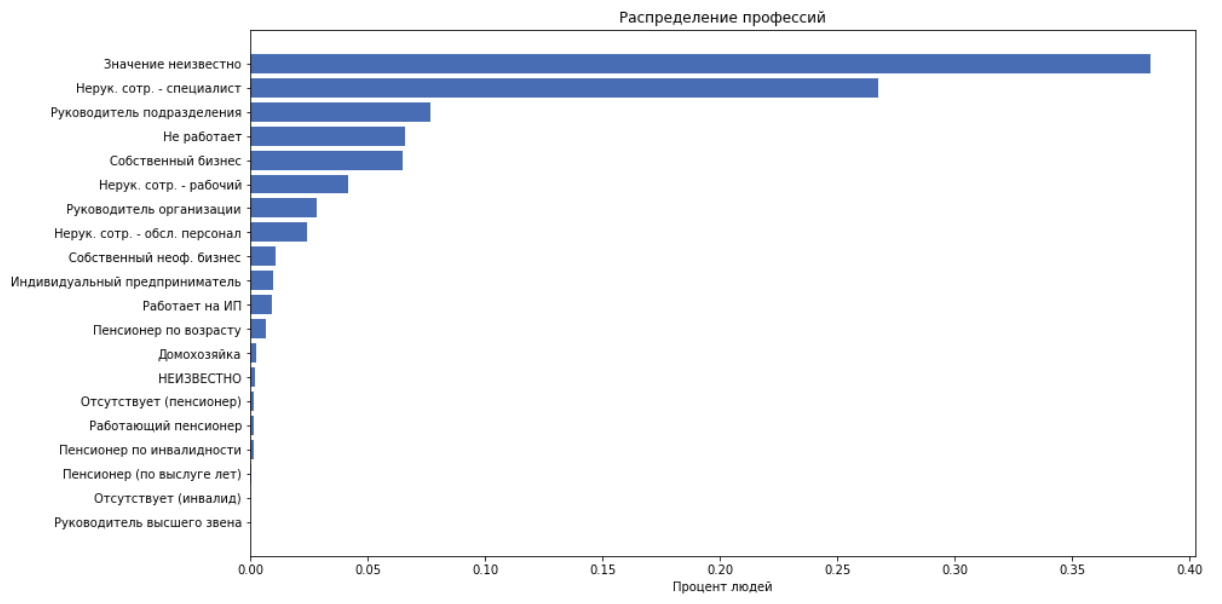
Результаты соревнования
Как обычно принято в соревнованиях по машинному обучению, когда отправляешь предсказания в систему, результат оценивается только по части всей тестовой выборки. Обычно около 30%. Результаты для этой части отражаются на публичном лидерборде. По оставшейся части теста оценивается итоговый результат, который отображается после окончания соревнования на приватном лидерборде.
В конце соревнования на публичном лидерборде положение было таким:
- 0.382 — ЗдесьМоглаБытьВашаРеклама
- 0.379 — дети Лёши
- 0.372 — Gardeners
- 0.35 — lazy&akulov
На приватном лидерборде, по которому считались итоговые результаты, мне повезло и ребята по какой-то причине с первого места упали на 4ое. Вот итоговое положение.
- 0.45807 дети Лёши
- 0.45264 Gardeners
- 0.44136 Zhuk
- 0.43704 ЗдесьМоглаБытьВашаРеклама
- 0.43474 lazy&akulov
Что не сработало
- Я пробовал переводить весь текст из истории в вектор с помощью fasttext, затем кластеризовал векторы и использовал номер кластера как категориальную фичу. Эта фича была топ 3 (после story_id и customer_id) в feature importance CatBoost’а, но почему-то стабильно и значительно ухудшала результат на валидации.
- Благодаря кластерам можно было найти истории, которые относились к чемпионату мира по футболу и присутствовали только в тренировочной выборке.
Однако выкидывание таких объектов из датасета не улучшило результат. - по дефолту CatBoost генерирует случайные перестановки объектов и считает по ним признаки для категориальных фичей. Но можно сказать катбусту, что у нас есть время в данных — has_time = True. Тогда он будет идти по порядку, не перемешивая датасет. В данной задаче, несмотря на то, что время у нас действительно есть, результат с has_time был стабильно хуже.
В общем случае если время есть, но его не учитывать при построении Mean Target Encoding’а, то модель будет использовать информацию о правильных ответах из будущего и может переобучиться под это. В данной задаче, видимо, это не имело большого эффекта и пробежаться несколько раз по разным перестановкам было важнее.
- Была идея назначать больший вес объектам в конце трейна, т.е. чтобы больше учитывать объекты с правильным распределением реакций. Но и на валидации, и на публичном лидерборде это давало результат хуже.
- Можно учитывать разные реакции с разным весом при обучении. Хотя у меня это результат не улучшало, некоторым командам это помогло.
Выводы
Соревнование получилось интересным, поскольку объединяло много компонентов, таких как табличные данные, тексты и картинки. Было много пространства для исследований, много с чем ещё можно было бы экспериментировать. В общем, скучать не пришлось.
Спасибо организаторам конкурса!
Весь код выложен на гитхабе.
ссылка на оригинал статьи https://habr.com/ru/company/ods/blog/475182/
Добавить комментарий