
Для облачного сервиса все иначе — у него возникают проблемы хранения данных. Каждая игра может весить десятки или сотни гигабайт, например, «Ведьмак 3» занимает 50 Гбайт, а «Call of Duty: Black Ops III» — 113. При этом игроки не будут пользоваться сервисом с 2-3 играми, как минимум нужно несколько десятков. Кроме хранения сотен игр, сервису нужно решать, какой объем хранилища выделять на одного игрока, и масштабироваться, когда их будут тысячи.
Хранить ли все это на своих серверах: сколько их нужно, где ставить дата-центры, как «на лету» синхронизировать данные между несколькими дата-центрами? Покупать «облака»? Использовать виртуальные машины? Можно ли хранить данные пользователей со сжатием в 5 раз и предоставлять их в real-time? Как исключить любое влияние пользователей друг на друга при последовательном использовании одной и той же виртуальной машины?
Все эти задачи успешно удалось решить в Playkey.net — облачной игровой платформе. Владимир Рябов — руководитель отдела системного администрирования — подробно расскажет о технологии ZFS для FreeBSD, которая в этом помогла, и ее свежем форке ZOL (ZFS on Linux).
Тысяча серверов компании расположены в удаленных дата-центрах в Москве, в Лондоне и Франкфурте. В сервисе больше 250 игр, в которые играют 100 тысяч игроков в месяц.
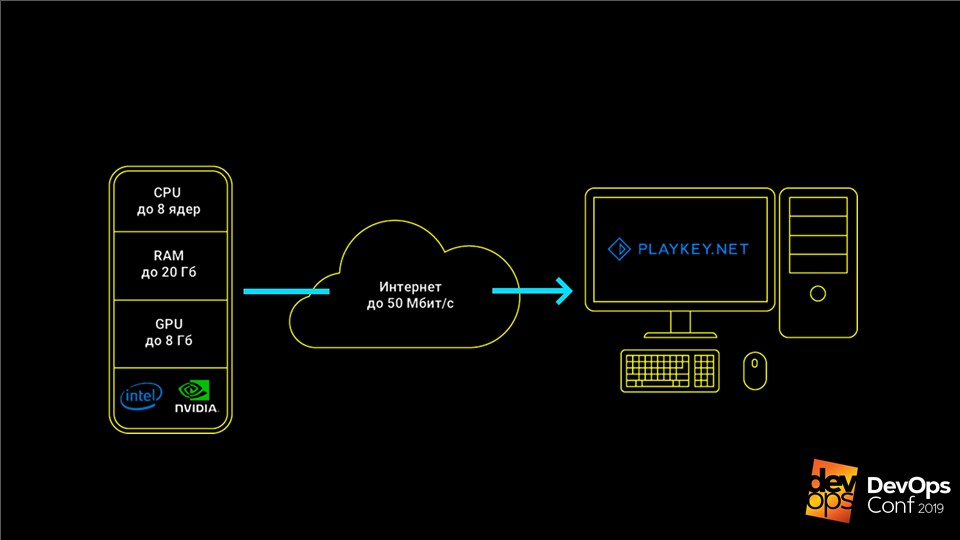
Сервис работает так: игра запускается на серверах компании, от пользователя получается поток контролов от клавиатуры, мышки или геймпада, а в ответ отправляется видеопоток. Это позволяет играть в современные топовые игры на компьютерах со слабым железом, ноутбуках с интегрированным видео или на Mac, под которые эти игры вообще не выпускают.
Игры надо хранить и обновлять
Основные данные для облачного игрового сервиса — это дистрибутивы игр, которые могут переваливать за сотню Гбайт, и пользовательские сохранения.
Когда мы были маленькие, у нас был всего десяток серверов и скромный каталог на 50 игр. Все данные мы хранили локально на серверах, обновлялись вручную, все устраивало. Но пришло время расти и мы отправились в облака AWS.
С AWS у нас появилось несколько сотен серверов, но архитектура не изменилась. Это также были серверы, но теперь уже виртуальные, с локальными дисками, на которых лежали дистрибутивы игр. Однако обновляться вручную на сотне серверов уже не получится.
Мы стали искать решение. Сначала попробовали обновляться через rsync. Но оказалось, что это крайне медленно, а на основную ноду идет слишком большая нагрузка. Но даже не это самое страшное: когда у нас был низкий онлайн, мы отключали часть виртуалок, чтобы не платить за них, и при обновлении данные не заливались на выключенные серверы. Все они оставались без обновлений.
Решением стали торренты — программа BTSync. Она позволяет синхронизировать папку на большом количестве нод без явного указания центральной ноды.
Проблемы роста
Какое-то время все это замечательно работало. Но сервис развивался, игр и серверов становилось больше. Количество локальных хранилищ тоже увеличивалось, нам приходилось платить все больше. В облаках это дорого, особенно за SSD. В один момент даже обычная индексация папки для начала её синхронизации стала занимать больше часа, а все серверы могли обновляться несколько дней.
BTSync создала еще одну проблему с избыточным сетевым трафиком. На тот момент в Amazon он был платный даже между внутренними виртуалками. Если классический лаунчер игры вносит небольшие изменения в большие файлы, то BTSync сразу же считает, что весь файл изменился, и начинает полностью перекачивать его на все ноды. В результате обновление даже на 15 Мбайт могло породить десятки Гбайт трафика синхронизации.
Ситуация стала критична, когда хранилище подросло до 1 ТБайта. Как раз вышла новая игра World of Warships. В ее дистрибутиве было несколько сотен тысяч мелких файлов. BTSync никак не могла ее переварить и раздать на все остальные серверы — это тормозило раздачу остальных игр.
Все эти факторы создали две проблемы:
- плодить локальные хранилища дорого, неудобно и трудно актуализировать;
- облака оказались очень дорогими.
Мы решили вернуться обратно к концепции своих физических серверов.
Своя система хранения данных
Прежде чем переходить к физическим серверам, нам нужно избавиться от локальных хранилищ. Для этого требуется своя система хранения данных — СХД. Это система, которая хранит все дистрибутивы и централизованно раздает на все серверы.
Кажется, что задача простая — ее уже неоднократно решали. Но с играми есть нюансы. Например, большинство игр просто отказывается работать, если им дать доступ только на чтение. Даже при обычном штатном запуске они любят что-нибудь записать в свои файлы, а без этого отказываются работать. Наоборот, если большому количеству пользователей дать доступ к одному набору дистрибутивов, они начинают бить друг другу файлы при конкурентном доступе.
Мы подумали над проблемой, проверили несколько вариантов решения, и пришли к ZFS — Zettabyte File System на FreeBSD.
ZFS на FreeBSD
Это не совсем обычная файловая система. Классические системы изначально устанавливаются на одно устройство, а для работы с несколькими дисками уже требуют менеджер томов.
ZFS изначально строится на виртуальных пулах.
Они называются zpool и состоят из групп дисков или RAID-массивов. Весь объем этих дисков доступен для любой файловой системы в рамках zpool. Все потому, что ZFS изначально разрабатывалась как система, которая будет работать с большими объемами данных.
Как ZFS помогла решить наши проблемы
В этой системе есть замечательный механизм создания снимков и клонов. Они создаются моментально, и весят всего несколько Кбайт. Когда мы вносим изменения в один из клонов, он увеличивается на объем этих изменений. При этом данные в остальных клонах не меняются и остаются уникальными. Это позволяет раздать диск объемом 10 Тбайт с монопольным доступом конечному пользователю, затратив всего несколько Кбайт.
Если клоны растут в процессе внесения изменений на игровой сессии, то не займут ли они столько же места, сколько все игры? Нет, мы выяснили, что даже в достаточно длинных игровых сессиях набор изменений редко превышает 100-200 Мбайт — это не критично. Поэтому, мы можем выдать полноценный доступ к полноценному жесткому диску большого объема нескольким сотням пользователей одновременно, потратив всего лишь 10 Тбайт с хвостиком.
Как работает ZFS
Описание кажется сложным, но работает ZFS достаточно просто. Разберем его работу на простом примере — создадим zpool data из доступных дисков zpool create data /dev/da /dev/db /dev/dc.
Примечание. На продакшн так делать не надо, потому что если хотя бы один диск умрет, весь пул уйдет в небытие вместе с ним. Лучше используйте группы RAID.
Создаем файловую систему zfs create data/games, а в ней блочное устройство с названием data/games/disk объемом 10 Тбайт. Устройство доступно по адресу /dev/zvol/data/games/disk как обычный диск — с ним можно проводить те же манипуляции.
Дальше начинается самое интересное. Отдаем этот диск по iSCSI нашему мастеру обновлений — обычной виртуальной машине под управлением Windows. Подключаем диск, и ставим на него игры просто из Steam, как на обычном домашнем компьютере.
Заполняем диск играми. Теперь осталось раздать эти данные на 200 серверов для конечных пользователей.
- Создадим моментальный снимок этого диска и назовем его первой версией —
zfs snapshot data/games/disk@ver1. Создаем его клонzfs clone data/games/disk@ver1 data/games/disk-vm1, который уйдет в первую виртуальную машину. - Отдаем клон по iSCSI и KVM запускает виртуалку с этим диском. Она загружается, уходит в пул доступных серверов для пользователей, и ожидает игрока.
- Когда пользовательская сессия завершена, забираем с этой виртуалки все пользовательские сохранения и складываем их на отдельный сервер. Саму виртуальную машину выключаем и уничтожаем клон —
zfs destroy data/games/disk-vm1. - Возвращаемся к первому шагу, снова создаем клон и запускаем виртуальную машину.
Это позволяет предоставить каждому следующему пользователю всегда чистую машину, на которой нет никаких изменений от предыдущего игрока. Диск после каждой пользовательской сессии удаляется, а место, которое он занимал на СХД, освобождается. Аналогичные операции мы также проводим и с системным диском, и со всеми нашими виртуалками.
Недавно на YouTube наткнулся на видео, где довольный пользователь во время игровой сессии форматировал наши жесткие диски на серверах, и очень радовался тому, что все сломал. Да пожалуйста, лишь бы платил — может играть и баловаться. В любом случае, следующий пользователь получит всегда чистую работоспособную виртуалку, что бы ни сделал предыдущий.
По этой схеме игры раздаются всего на 200 серверов. Цифру 200 мы вычислили экспериментальным путем: это то количество серверов, при котором не возникают критические нагрузки на диски СХД. Все потому, что у игр достаточно специфический профиль нагрузки: они много читают на этапе запуска или на этапе загрузки уровня, а в процессе игры, наоборот, практически не используют диск. Если у вас профиль нагрузки отличается, то и цифра будет другая.
В старой схеме на одновременное обслуживание 200 пользователей нам потребовалось бы 2000 Тбайт локального хранилища. Сейчас мы можем потратить чуть больше 10 Тбайт под основной набор данных, и в запасе еще есть 0,5 Тбайта под пользовательские изменения. Хотя ZFS и любит, когда у нее в пуле остается хотя бы 15% свободного места, мне кажется, что мы существенно сэкономили.
Что если у нас несколько дата-центров?
Этот механизм будет работать только внутри одного дата-центра, где серверы с системой хранения данных соединены хотя бы 10 гигабитными интерфейсами. Что делать, если ДЦ несколько? Как обновлять основной диск с играми (датасет) между ними?
Для этого у ZFS есть свое решение — механизм Send/Receive. Команда на выполнение очень простая:
zfs send -v data/games/disk@ver1 | ssh myzfsuser@myserverip zfs receive data/games/diskМеханизм позволяет передать с одной СХД на другую моментальный снимок с основной системы. В первый раз придется отправить на пустую СХД все 10 Тбайт данных, которые записаны на master-ноде. Но при следующих обновлениях мы будем отправлять только изменения с момента создания предыдущего моментального снимка.
В результате получаем:
- Все изменения вносятся централизованно на одной СХД. Дальше они разъезжаются по всем остальным дата-центрам в любом количество, а данные на всех нодах всегда идентичны.
- Механизму Send/Receive не страшен обрыв связи. Данные к основному датасету не применяются до тех пор, пока они полностью не передадутся наslave-ноду. При обрыве связи повредить данные невозможно, и достаточно лишь повторить процедуру отправки.
- Любая нода легко может стать master-нодой во время аварии всего за несколько минут, так как данные на всех нодах всегда идентичны.
Дедупликация и бэкапы
В ZFS есть еще одна полезная функция — дедупликация. Эта функция помогает не хранить два одинаковых блока данных. Вместо этого хранится только первый блок, а на месте второго хранится ссылка на первый. Два одинаковых файла будут занимать место как один, а при совпадении на 90%, будут заполнять 110% от изначального объема.
Функция нам очень помогла в хранении пользовательских сохранений. В одной игре у разных пользователей сохранения похожи, многие файлы совпадают. За счет применения дедупликации мы можем хранить в пять раз больше данных. Наш коэффициент дедупликации 5,22. Физически у нас занято 4,43 Тбайта, умножаем на коэффициент, и получаем, что практически 23 Тбайта реальных данных. Это хорошо экономит место, позволяя не хранить дубли.
| NAME | SIZE | ALLOC | FREE | DEDUP |
| data | 7,16 Tбайт | 4,43 Tбайт | 2,73 Tбайт | 5.22x |
Моментальные снимки хорошо подходят для бэкапа. Мы используем эту технологию на наших файловых хранилищах. Например, если каждый день в течение месяца сохранять по одному снимку, можно в любой момент развернуть клон на любой день этого месяца и вытащить потерянные или поврежденные файлы. Это позволяет не откатывать все хранилище или разворачивать его полную копию.
Мы используем клоны для помощи нашим разработчикам. Например, они хотят испытать потенциально опасную миграцию на боевой базе. Разворачивать классический бэкап базы, которая подбирается к 1 Тбайту, не быстро. Поэтому мы просто снимаем клон с диска базы и добавляем его мгновенно в новый инстанс. Теперь разработчики могут совершенно спокойно там все протестировать.
ZFS API
Конечно, все это надо автоматизировать. Зачем лезть на серверы, работать руками, писать скрипты, если это можно отдать программистам? Поэтому мы написали свое простенькое Web API.
В него мы завернули все стандартные функции ZFS, отрезали доступ к тем, которые потенциально опасны и могут сломать всю СХД, и отдали все это программистам. Теперь все операции с дисками строго централизованы и выполняются кодом, а мы всегда знаем статус каждого диска. Все работает замечательно.
ZoL — ZFS on Linux
Мы централизовали систему и задумались, а так ли это хорошо? Ведь теперь для любого расширения нам сразу же надо покупать несколько стоек серверов: они завязаны на СХД, и дробить систему нерационально. Что делать, когда мы решим развернуть небольшой демо-стенд, чтобы показать технологию партнерам в других странах?
Подумав, мы пришли к старой идее — использовать локальные диски, но только уже со всем опытом и знаниями, которые получили. Если развернуть идею глобальнее, то почему бы не дать нашим пользователям возможность не только пользоваться нашими серверами, но и сдавать в аренду свои компьютеры?
В этом нам сильно помог относительно свежий форк ZFS on Linux — ZoL.
Теперь каждый сервер сам себе СХД.
Только он хранит не по 10 Тбайт данных, как в случае централизованной инсталляции, а лишь 1-2 дистрибутива тех игр, которые обслуживает. Для этого достаточно одного SSD-диска. Все это прекрасно работает: каждый следующий пользователь получает всегда чистую виртуалку, как и на боевой инсталляции.
Однако тут мы столкнулись с двумя проблемами.
Как обновлять?
Обновлять централизованно по SSH, как мы делаем в дата-центрах не получится. Пользователи могут быть подключены к локальной сети или просто выключены, в отличие от СХД, да и поднимать столько SSH-соединений со своей стороны не хочется.
Мы столкнулись с теми же проблемами, что и при использовании rsync. Однако торренты поверх ZFS уже не получить. Мы внимательно подумали, как работает механизм Send: он отправляет все изменившиеся блоки данных на конечную СХД, где Receive применяет их к текущему датасету. Почему бы не записать данные в файл, вместо того, чтобы отправлять их до конечного пользователя?
В результате получилось то, что мы называем diff. Это файл, в который последовательно записаны все измененные блоки между двумя последними моментальными снимками. Мы выкладываем этот diff на CDN, и по HTTP отдаем всем нашим пользователям: он включил машину, увидел, что есть обновления, выкачал и применил к локальному датасету, используя Receive.
Что делать с драйверами?
У централизованных серверов конфигурация одинакова, а у конечных пользователей всегда разные компьютеры и видеокарты. Даже если мы максимально заполним дистрибутив ОС всеми возможными драйверами, при первом запуске она все равно захочет поставить эти драйвера, потом обязательно перезагрузится, а потом, возможно, еще раз. Так как мы каждый раз предоставляем чистый клон, то вся эта карусель будет происходить после каждой пользовательской сессии — это плохо.
Мы хотели провести какой-то инициализационный запуск: дождаться, пока Windows загрузится, установит все драйвера, выполнит все, что ей хочется, и уже потом оперировать с этим диском. Но проблема в том, что если внести изменения в основной датасет, сломаются обновления, так как данные на источнике и на приемнике будут различаться, и diff просто не применится.
Однако ZFS гибкая система и позволила нам сделать небольшой костыль.
- Как обычно создаем моментальный снимок:
zfs snapshot data/games/os@init. - Создаем его клон —
zfs clone data/games/os@init data/games/os-init— и запускаем в режиме инициализации. - Ждем пока установятся все драйвера и все перезагрузится.
- Выключаем виртуальную машину и снова создаем снимок. Но на этот раз уже не с изначального датасета, а с инициализационного клона:
zfs snapshot data/games/os-init@ver1. - Создаем клон снимка уже со всеми установленными драйверами. Он больше не будет перезагружаться:
zfs clone data/games/os-init@ver1 data/games/os-vm1. - Дальше работаем по классической связке.
Сейчас эта система находится на этапе альфа-тестирования. Мы проверяем ее на реальных пользователях без знаний Linux, но у них получается все это развернуть у себя. Наша конечная цель — чтобы любой пользователь мог просто воткнуть загрузочную флешку в свой компьютер, подключить дополнительный SSD-диск и сдать его в аренду на нашей облачной платформе.
Мы обсудили только малую часть функциональности ZFS. Эта система умеет гораздо больше интересного и разного, но о ZFS мало кто знает — пользователи не стремятся рассказывать о ней. Надеюсь, что после этой статьи в ZFS-community появятся новые пользователи.
Подпишитесь на телеграм-канал или рассылку, чтобы узнавать о новых статьях и видео с конференции DevOpsConf. В рассылке кроме того собираем новости готовящихся конференций и рассказываем, например, что интересного для DevOps-фанатов будет на Saint HighLoad++.
ссылка на оригинал статьи https://habr.com/ru/company/oleg-bunin/blog/480622/
Добавить комментарий