Как это иногда делают:
WITH T1 AS ( SELECT row_number() OVER() rn , unnest v1 FROM unnest('{1,2,3,4}'::integer[]) ) , T2 AS ( SELECT row_number() OVER() rn , unnest v2 FROM unnest('{5,6}'::integer[]) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);
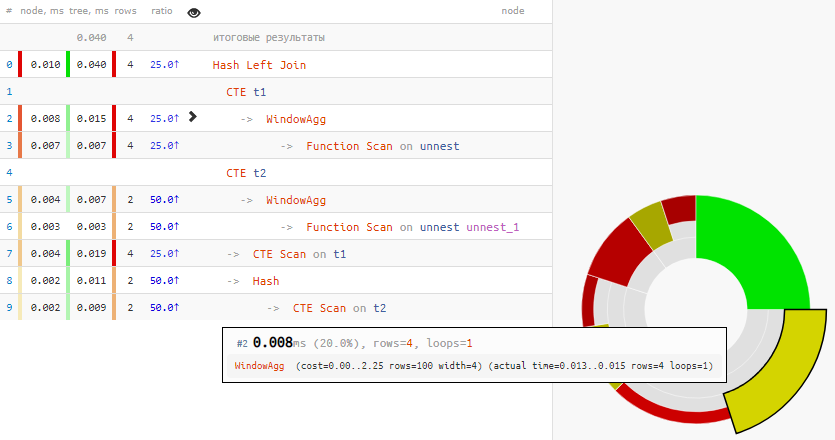
v1 | v2 ------- 1 | 5 2 | 6 3 | 4 | То есть сначала каждый из массивов был «развернут» в выборку, пронумерован, а затем этот номер использовался как ключ соединения CTE…
[посмотреть на explain.tensor.ru]
WITH ORDINALITY
Больше четверти всего времени ушло на пару WindowAgg!
Но если мы используем версию PG не ниже 9.4, то можем применить WITH ORDINALITY для нумерации результатов любой SRF, включая unnest:
WITH T1 AS ( SELECT * FROM unnest('{1,2,3,4}'::integer[]) WITH ORDINALITY T(v1, rn) ) , T2 AS ( SELECT * FROM unnest('{5,6}'::integer[]) WITH ORDINALITY T(v2, rn) ) SELECT T1.v1 , T2.v2 FROM T1 LEFT JOIN T2 USING(rn);  [посмотреть на explain.tensor.ru].
[посмотреть на explain.tensor.ru].
Таким образом, мы вообще избавились от использования оконных функций.
Multi-argument UNNEST
Но с точки зрения эффективности пока не все хорошо — почти половина времени ушла на Hash Left Join.
Да и автор явно исходил из предположения, что первый массив точно длиннее — потому и воспользовался LEFT JOIN. Но это допущение корректно не всегда, и может вызвать проблемы.
Чтобы его обойти, воспользуемся unnest для нескольких массивов одновременно, который появился с той же версии 9.4:
SELECT * FROM unnest( '{1,2,3,4}'::integer[] , '{5,6}'::integer[] ) T(v1, v2);В результате, и от запроса почти ничего не осталось, и от плана:
Function Scan on t (cost=0.01..1.00 rows=100 width=8) (actual time=0.006..0.007 rows=4 loops=1)Значит, и шансов допустить ошибку — намного меньше. Да и по времени выполнения улучшили в несколько раз — а на более длинных массивах эффект будет еще заметнее.
ссылка на оригинал статьи https://habr.com/ru/post/479920/
Добавить комментарий