
Как вы, возможно, знаете, концепция объединенного облачного провайдера на текущий момент представлена тремя совместно работающими брендами:
- #CloudMTS, создан центром инноваций компании МТС;
- Компания ИТ-ГРАД, облачный IaaS-провайдер;
- Сервис 1cloud.
Сейчас все бренды в рамках этой концепции работают совместно и взаимно дополняют друг друга, стремясь закрыть запросы различных сегментов нашей аудитории. Однако в процессе слияния мы столкнулись с некоторыми трудностями, одна из которых привела к разработке новой системы мониторинга.
После сделки был начат процесс выделения облачной IT-инфраструктуры ИТ-ГРАД в отдельный сегмент. Это был сложный переходный момент, в ходе которого происходило отключение большого количества оборудования и ЦОДов, которые не вошли в контур сделки. Поменялась маршрутизация внутренней и внешней сети. При этом сроки поджимали, и триггеры в системе мониторинга не всегда удавалось актуализировать вовремя. Это привело к генерации множества ложных инцидентов от уже несуществующего оборудования.
В процессе глобальной реконфигурации несладко пришлось и сотрудникам тех. поддержки — они столкнулись с таким огромным потоком ложных оповещений, что обработать все события корректно и своевременно было крайне сложно. Требовалось полностью перенастроить систему мониторинга, актуализировав ее под текущие задачи, и фактически трансформировать в новую услугу как для внутреннего использования, так и для наших заказчиков.
В результате было принято решение создать выделенное подразделение управления событиями, которое наладит работу системы мониторинга в ИТ-ГРАД и впоследствии станет единым центром по наблюдению за состоянием инфраструктуры объединенного облачного провайдера.
В результате трансформации основными требованиями стали:
- Система мониторинга должна работать не только на ИТ-ГРАД, но и стать внутренним сервисом для «Объединенного облачного провайдера» и услугой для заказчиков.
- Требовалось решение, которое будет собирать статистику со всей IT-инфраструктуры.
- Так как систем много, все события мониторинга должны сходиться в едином агрегаторе данных, где события и триггеры сверяются с единой CMDB и при необходимости происходит автоматическое оповещение пользователей.
Собрав и проанализировав все данные, которые были доступны на тот момент, мы разбили реализацию проекта на несколько этапов:
- Определение требований к системе мониторинга.
- Подготовка моделей «здоровья компонентов» услуги.
- Анализ требований к надежности и отказоустойчивости системы мониторинга.
- Тестирование и последовательное внедрение системы.
- Организация мониторинга как услуги для клиентов.
Для наглядности приведем этот процесс в виде блок-схемы.

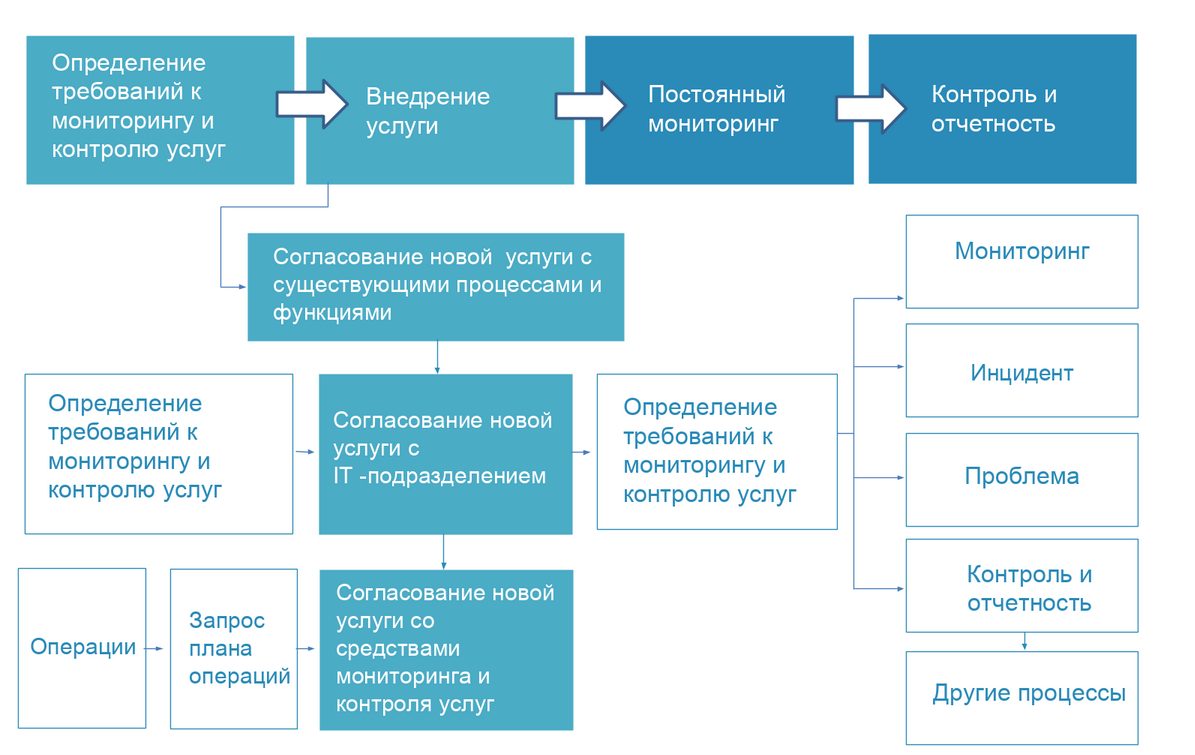
Трудности роста
Разумеется, внедрение такой сложной системы не могло пройти идеально гладко, и мы столкнулись с некоторыми сложностями.
- Первый момент — формирование нового отдела. Оказалось, найти узкоспециализированных специалистов, которые знают и имеют практический опыт работы с различными системами мониторинга, не так-то просто. Одним из наших требований было понимание мониторинга как сервиса, а не просто как одного из компонентов IT-инфраструктуры.
- Сжатые сроки для решения задачи.
- Географически разрозненная IT-инфраструктура, которую требовалось привести к единому стандарту.
- Большое количество разрозненных систем мониторинга, которые было необходимо объединить в единую систему.
Контроль и отчетность в системе мониторинга

Социализм IT-инфраструктура — это учет и контроль. Ни одно событие, даже самое незначительное, не должно остаться без внимания. На текущий момент нам удалось выстроить процесс отчетности и контроля, включающий в себя:
- создание отчетов и отслеживание статистики по компонентам наших заказчиков;
- проведение управленческого анализа «Эксплуатационное состояние» нашей внутренней инфраструктуры;
- планирование улучшений услуг на основе собранной отчетности.
Созданная единая CMDB позволяет нам отслеживать состояние и историю событий как по всей инфраструктуре в целом, так и по каждому компоненту в отдельности.
Дополнительно мы стали отслеживать состояние отдельных услуг, например, резервное копирование, а именно корректность выполнения backup-задач. Если по какой-то причине задача завершается с ошибкой, система регистрирует инцидент. В нем указан сервер резервного копирования, сама задача и виртуальная машина — зная это, мы можем быстро все починить. Также благодаря мониторингу услуг мы можем предоставлять отчёты нашим клиентам.

Ниже мы приведем скриншот отчетов компании «Лайв Технологии».

Ниже вы можете видеть сводный отчет по количеству инцидентов с группировкой по классу конфигурационных единиц (КЕ) в разрезе степени влияния на инфраструктуру.

Результаты работы системы мониторинга
Новая система мониторинга уже активно функционирует, и мы готовы поделиться с вами результатами её работы и нашими собственными наблюдениями.
На текущий момент нам удалось полностью восстановить мониторинг инфраструктуры ИТ-ГРАД и избавиться от генерации ложных инцидентов. Услуга для клиентов проходит тестирование и скоро станет доступна. В дальнейшем мы планируем завершить объединение инфраструктур, подключив 1cloud и #CloudMTS к единой системе мониторинга ИТ-ГРАД.

Ранее при срабатывании триггера на alert генерировался инцидент на 1-линию поддержки. Дежурный сотрудник обрабатывал его и оповещал заказчика либо звонком, либо по электронной почте.
Сейчас всё работает автономно: при срабатывании триггера в течение 2-х минут, если это необходимо, происходит автоматическое оповещение клиента.
Уделим немного внимания тому, как устроены оповещения.

В случае изменения состояния IT-компонента система мониторинга регистрирует событие в агрегаторе данных, который обрабатывает событие по телу письма и, в зависимости от степени критичности состояния компонента, указанного в алерте, формирует запрос, оповещение или инцидент с нужным приоритетом. Далее система через CMDB определяет, какому заказчику принадлежит КЕ, и в соответствии с моделью здоровья производит оповещение посредством email или смс. Кроме того, на текущий момент специальный телеграм-бот для оповещений проходит стадию доработки и скоро станет доступен всем нашим клиентам.

Сейчас в рамках процесса мониторинга и контроля услуг мы в режиме реального времени следим за «состоянием здоровья» рабочей IT-среды, автоматизировано оповещая как внешних, так и внутренних пользователей. Мониторинг состояния IT-инфраструктуры и услуг, а также собираемые данные позволяют предпринимать проактивные действия до того, как что-то выйдет из строя.
Как видите, процесс построения системы мониторинга изобилует подводными камнями. Тем не менее, мы уверены, что в результате совместной работы наших инженеров и аналитиков получился отличный продукт, который решает сразу две бизнес-задачи: обеспечивает качественным мониторингом нас и позволяет реализовать мониторинг как услугу для клиентов.
ссылка на оригинал статьи https://habr.com/ru/company/it-grad/blog/479058/
Добавить комментарий