Когда мы планируем разработку, в нашем бэклоге лежат задачи. Рядом с каждой из них могут незаметно притаиться риски — один или несколько. Давайте поговорим о том, как эти риски увидеть и что с ними делать потом. Это обобщение моего опыта в роли тимлида — что я делал по поводу рисков в бэклоге, что получалось, что нет.

Что такое риски? Риск это возможная проблема в будущем. В зависимости от разных факторов, эта проблема или случится или пройдет мимо нас. На часть факторов мы можем воздействовать, другие находятся вне нашего контроля.
Недавно я выступал на Saint Teamlead Conf 2019 с докладом «Инструменты управления рисками в продуктовом бэклоге для тимлида». Предлагаю хабрасообществу улучшенную версию данного материала.
История одного релиза
Мы создаем экосистему МойОфис, и хотим рассказать про интересный кейс из нашей практики программной разработки. Благодаря нему мы научились лучше оценивать риски и делать более точные прогнозы.
Наша фронтенд-команда работает двухнедельными спринтами. На каждый публичный релиз приходится 6-8 таких спринтов. Однажды, когда мы находились в середине цикла и оставалось буквально 3 спринта, к нам приходят владелец продукта с дизайнерами. «Нужно сделать редизайн, очень желательно успеть к релизу. Вот макеты, которые всем нравятся».

Новый макет выглядит, действительно, лучше прежнего. Но нужно поменять довольно большую часть внешнего облика системы. Заводим задачу «сделать редизайн», оцениваем. Получается, что если сразу начать, то теоретически к концу спринта можно успеть. Есть некоторые нехорошие предчувствия, но мы всё равно начинаем. И к концу спринта мы, конечно, не успеваем. Ну уж в следующем-то успеем?
В следующем спринте становится ещё хуже. Мы сталкиваемся с множеством крайних случаев, про которые никто не подумал изначально. Приходится придумывать много решений по ходу. Например, где-то на макете появился управляющий элемент, которого нигде не было до этого — почти целый день уходит на споры о его необходимости и можно ли его заменить другим. Начинаем тестирование, и понимаем — всё стало еще хуже. Измененные части системы выглядят хорошо, зато расползаются те, которые мы не трогали. Потом кто-то проверяет как все выглядит в Internet Explorer…
В общем, это было непросто, но мы справились. История с редизайном была закончена только в самом конце спринта. С компромиссами и кучей костылей вливаем в master, и идём на ретроспективу.
Остается последний спринт релиза
На вливании в master история не заканчивается. Когда задача решается в самый последний день спринта, то как правило, страдает качество. Появляются регрессии по всему продукту. Затем, когда мы начинаем их править, на каждый исправленный баг вылезает по два новых.
Разбор полетов
Произошедшее заставило нас задуматься над тем, правильно ли мы умеем планировать свое время и управлять им. И какие выводы нужно сделать из этой ситуации, чтобы подобного не случалось в дальнейшем.
В случае с примером выше, ситуация становилась нервной ещё и потому, что в редизайн было вложено много усилий, наступили дедлайны и отступать было просто некуда. Вариант с удалением из основной ветки редизайна перед релизом тоже был маловероятен — поверх нового дизайна уже сделан ряд других важных функциональных изменений. В этот момент и появляется самый сильный страх — а вдруг, мы не успеем?
Для того, чтобы всё же успеть сдать релиз, пришлось напрячься и вложить все свои силы. Дальнейшее тестирование показало, что уровень качества даже такой работы оказался приемлемым. Правда затраты на разработку и тестирование, если считать честно, превышали оценку больше чем в три раза.
Так при чем тут управление рисками?
А его в этой истории и не было.
Это был главный вывод, который заставил нас сделать работу над ошибками и избегать подобных ситуаций впредь.
Управление рисками и кризис-менеджмент
Давайте немного поговорим о тушении пожаров.

Вспомним, что:
- риск — это возможная проблема. Когда такие проблемы видно заранее, мы можем с ними как-то работать, чтобы снизить вероятность или смягчить негативные последствия. Это управление рисками;
- кризис-менеджмент — ситуация, когда проблема уже возникла, её надо решать и минимизировать ущерб.
Управление рисками и кризис-менеджмент находятся в балансе. Все проблемы, которые не удалось предотвратить, нужно будет решать. Не управляешь рисками — будешь тренировать навыки кризис-менеджера.
В ситуации из примера мы понадеялись, что нам повезет и не предприняли никаких мер заранее. Не повезло.
Почему кризис-менеджмента лучше избегать?
Наверное, все слышали поговорку о том, что героизм одних — это следствие раздолбайства других. Неприятно, когда и герой и раздолбай находятся в одной команде. Это снижает уровень доверия, портит отношения, ухудшает продуктивность. А хуже всего когда раздолбай — тимлид.
Ситуацию внутри команды вы контролируете и можете сделать так, чтобы этих проблем не было. Скучно в любом случае не будет. Вам хватит героизма, вызванного неуправляемыми факторами.
Какие бывают риски
Некоторые риски уникальны, но большинство связаны с одними и теми же повторяющимися причинами. Эта статья посвящена только тем причинам, которые связаны с продуктовым бэклогом. Не будем говорить здесь про риски, связанные с качеством, человеческим фактором, отношениями с клиентами и т.п.
Мой топ-3 источников рисков:
- Неопределенность планирования
- Технический долг
- Соседние команды
Источник рисков: неопределенность планирования

Как вы думаете, неопределенность требований, неопределенность сроков и т.п. — риск для проекта?
Мой ответ — нет. Сама по себе неопределенность это не риск. Чтобы она стала риском, нужны дополнительные ингредиенты. Например, попытка составить более-менее четкий план на базе недостающей информации. И особенно, попытка давать обязательства по поставке, основываясь на таких планах.
Виды задач по критичности
Задачи стоит планировать по-разному в зависимости от приоритета.
Критичные (обязательные) задачи
Наша команда разрабатывает веб-интерфейс облачного файлового менеджера. Давайте возьмём для примера поддержку управления версиями документов. Эту функцию нужно было добавить в сервер и все клиенты в течение одного релиза. Если бы мы не успели сделать поддержку в своем компоненте, то система в целом осталась бы в недоделанном состоянии.
Для критичных задач у нас есть, по факту, фиксированный срок поставки. Если мы не попали в свой прогноз, то нужно искать компромиссы, которые помогут удешевить реализацию так, чтобы мы успели. Либо нести ущерб от нарушения своих обещаний и исключать эти задачи из релиза.
Для критичных задач наша цель управления рисками заключается в том, чтобы обеспечить поставку в срок. Если мы можем потратить чуть больше времени разработчиков, но при этом снизим риск — то это почти всегда стоит сделать.
Лучший способ сделать вовремя — начать раньше. Тут нам помогут ранняя интеграция, прототипы и декомпозиция.
Некритичные задачи
Однажды возникла идея — давайте сделаем режим галереи для просмотра фотографий, которые размещены внутри файлового менеджера. Эту фичу не включали в план релиза и никому заранее не обещали.
Фотогалерея отличный пример некритичной задачи. Управлять ими проще. Если мы такую задачу не успеем сделать в этом релизе, то ничего страшного не произойдет — сделаем в следующем. Эти задачи хорошо использовать в качестве буфера: если критичная задача не укладывается в оценку, мы можем выкинуть любую из некритичных и освободить время.
Основная цель управления рисками по некритичным задачам состоит в том, чтобы избежать возникновения проблем, которые помешают работе над чем-нибудь более важным.
Разберем один из случаев, когда затягивание работ по некритичной задаче может создать проблемы для более важных задач.
Оптимальная последовательность задач
Давайте посмотрим, как выглядит план релиза. У нас есть фиксированная дата выпуска и примерный перечень работ. Он делится на критичные и некритичные задачи. Первые мы обещали кому-то и на этих обещаниях другие люди могут строить свои планы. Вторые могут быть без особых последствий убраны, если вдруг что-то пойдет не так.
С точки зрения минимизации проблем, хорошо бы сначала сделать все обязательные истории, а необязательные — использовать в качестве задела на будущее.
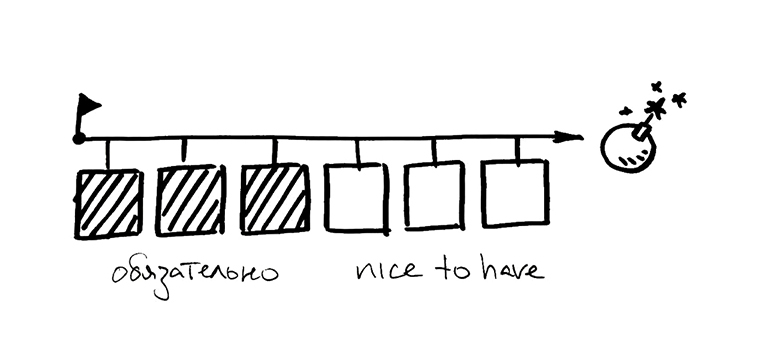
Как думаете, в реальной жизни так получится? Нет, реальная жизнь обычно выглядит по-другому. Многие критичные задачи имеют зависимости и мы не можем начать их прямо сразу:
- не готов бэкенд;
- владелец продукта продолжает уточнять требования;
- какие-то задачи в принципе появляются в середине релиза.
Поэтому, чаще всего многие разработчики сначала занимаются чем-то некритичным, что уже можно взять в работу, а критичные вещи ждут своих зависимостей. Расставив очередность выполнения критичных задач с учетом зависимостей, можно оптимизировать процесс и получить вот такую картину:
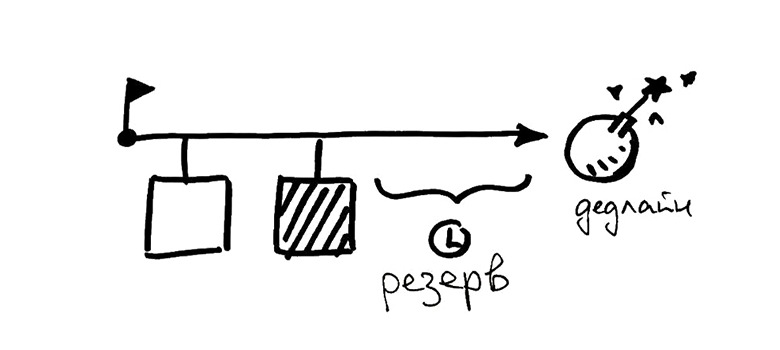
Как видите, общий буфер стал втрое меньше, а для одной из критичных задач его нет вообще. Получить полностью оптимальную последовательность задач, как правило, невозможно. Но правильная декомпозиция может улучшить ситуацию, об этом ниже. А пока попробуем разобраться, чем может навредить недооценка некритичной задачи.
Недооценка некритичной задачи
Возьмем упрощенный случай: у нас есть ровно две задачи. По критичной ждем зависимости, некритичную можно начинать сразу. За критичной задачей снова стоят некритичные, их используем в качестве буфера перед дедлайном.
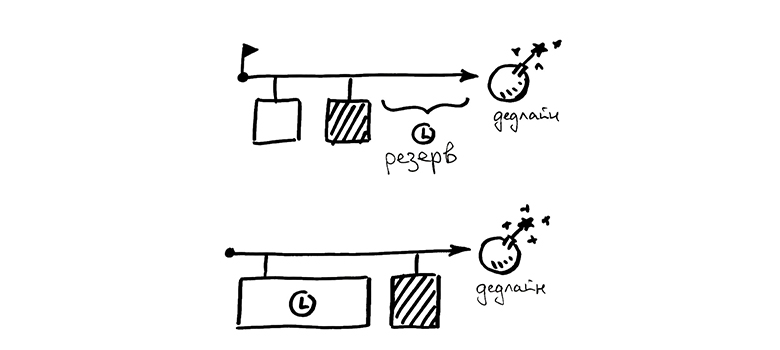
Как думаете, что случится, если мы недооценили первую задачу и поняли это уже в процессе?
Во-первых, когда задача уже начата, хочется её закончить. И когда она сильно вылезает из оценки, это может привести к тому, что из-за этой доделки позже будут начаты более критичные задачи.
Во-вторых, проблемные задачи можно сравнить с пожаром. На тушение постепенно отвлекаются силы всё большего числа людей в команде. Поэтому может случиться так, что все внимание уходит на некритичные для релиза, но терпящие бедствие задачи. В это же время критичные задачи страдают от недостатка внимания. Так продолжается до тех пор пока не начнется пожар уже в них самих 🙂
Поэтому, наиболее вероятный сценарий — на некритичную задачу будет потрачен буфер, предназначенный совcем для другого.
На мой взгляд, правильное решение заключается в том, что стоит останавливать работу по некритичной задаче сразу же при превышении исходной оценки. Естественный человеческий оптимизм мешает принять такое решение. Но оно, обычно, самое оптимальное.
Случай из практики
Недавно был такой случай. Одну из историй долго не удавалось стабилизировать. При исправлении одного дефекта возникало два, при их исправлении — ещё три, и так далее. Как только кончилось время, изначально выделенное на историю, мы остановили работу над ней. Каскад регрессий наглядно продемонстрировал, что есть архитектурные проблемы, которые мы не видели на этапе планирования. После остановки работ мы дали проблемной истории «отлежаться», проанализировали и описали технический долг в затронутом месте, запланировали его исправления. После рефакторинга история была закончена быстро и почти без дефектов.
В практике нашей команды мы никогда не жалели об остановке работ по некритичным задачам. Зато неоднократно жалели о том, что понадеялись на лучшее и не остановились.
Декомпозиция и снижение рисков
Декомпозиция — один из ключевых инструментов управления рисками, который позволяет начинать важные задачи раньше и снижать ущерб от расхождения оценки и фактических затрат, а также гибче реагировать на изменение обстоятельств. Декомпозиция на момент планирования заставляет погрузиться в задачу глубже, тем самым повышается качество оценки
Терминологическое отступление
Обсуждая декомпозицию, я буду оперировать двумя типами элементов бэклога.
- История — логически связанное и целостное изменение продукта. Достаточно велика, чтобы имело смысл оценивать и декомпозировать. Обычно разбита не отдельные задачи.
- Задача — самый маленький элемент бэклога, не декомпозируется.
Принципы декомпозиции
Любая отдельно взятая задача не должна делать продукт хуже.
Разделение большой истории на несколько сущностей поменьше снижает риски только в том случае, когда мы можем их планировать более-менее независимо. Если разделить большую историю на блоки «сделать хоть как-то» и «исправить баги из предыдущей истории», то такой независимости не будет. После завершения первой истории мы получим продукт в непригодном для релиза состоянии. И тем самым лишим себя свободы маневра: мы будем обязаны исправить дефекты как можно быстрее. Избежать такой ситуации можно, потребуется декомпозировать задачи таким образом, чтобы каждая сделанная история оставляла продукт в пригодном для релиза состоянии.
Лимит на размер истории
Хорошо себя показала практика введения ограничения на размер истории.
Всем известно, что корпус больших кораблей разделяют водонепроницаемыми переборками на несколько отсеков. Если будет пробит один отсек, то затопит только его. Корабль же останется на плаву. Аналогично с задачами — разделив наш план на несколько отдельных историй, мы снизим максимальный ущерб. Если что-то пойдет не так, то это будет ограничено отдельной веткой и не повлияет на всё остальное.
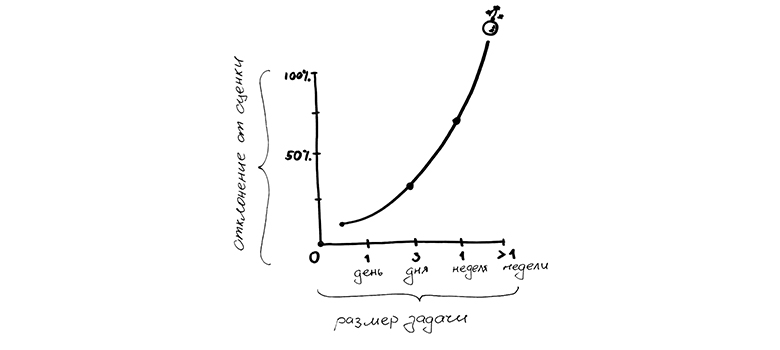
Кроме снижения ущерба, небольшие истории обычно оказываются точнее в оценке. Большинство команд показывает одну и ту же закономерность в соотношении запланированного и фактически потраченного времени — чем больше оценка, тем хуже она соотносится с реальностью. Например, по историям с оценкой в один день средний перерасход фактически затраченного времени может оказаться 20-30%. А с оценкой в 3-5 дней — больше 50%. Минус метода в том, что за границей недельного планирования начинается полная непредсказуемость и хаос.

Мы используем лимит в 3 человеко-дня разработки. Если история требует большего времени проработки, то её нужно или уменьшить или разделить на несколько.
Одна история — одна цель
При планировании полезно задавать себе вопрос — а что мы хотим достигнуть в результате реализации этой истории? К примеру, вариант «мы хотим сделать новую функциональность, на новой технологии и отрефакторить технический долг» будет очень плохим ответом. Достижение каждой из этих целей лучше оформить в виде отдельной истории.
Почему так?
Каждая цель увеличивает объем работ и является источником риска. А проблемы имеют интересное свойство нелинейно увеличиваться при наложении. Если с нами одновременно случилось две разных проблемы в рамках одной истории — общий ущерб будет как от трех независимых проблем.
Сделанная история улучшает продукт только в момент её завершения. Если под каждую цель выделять отдельную историю, то их плодами можно будет начать пользоваться раньше.
Исследования и прототипы
Один из инструментов снижения неопределенности — истории-прототипы. Цель прототипа не улучшить продукт, а добыть новые знания для команды.

Например, в одном из прошлых релизов мы делали печать документов через формат PDF. Ещё до того, как был готов бэкенд для экспорта соответствующей версии, наша команда взяла в работу прототип. В нем мы исследовали технические возможности по печати PDF в разных браузерах. Узнали много нового про особенности печати и существующие ограничения браузеров. Прототип позволил нам точно оценить полноценную реализацию. Когда был готов бэкенд, мы сделали свою часть с хорошим попаданием в оценку и минимумом технических сюрпризов.
Таймбокс для оценки прототипов
За счет того, что к прототипам не применяются обычные критерии качества, мы получаем свободу маневра по затрачиваемому времени. Это позволяет использовать таймбокс (лимит времени) вместо обычной оценки трудоемкости.
Как работает таймбокс? Если задачу удалось сделать до достижения лимита, мы закрываем её обычным образом. Если не удалось — работы сразу останавливаются и мы фиксируем промежуточные результаты. Дальше эта информация анализируется и позволяет нам лучше определить следующий шаг: берем фичу на реализацию, делаем ещё одно исследование с уточненными целями или перерабатываем исходную идею.
Например, для исследования особенностей реализации печати через формат PDF, мы можем прикинуть, что пары дней должно с запасом хватить для создания и проверки прототипа, а также для обсуждения результатов. Важность создаваемой функциональности оправдывает такие затраты времени. Остается только заложить эти дни в таймбокс, и оценка закончена.
Такой метод позволяет планироваться быстрее. Плюс к этому мы получаем задачи, которые редко выходят за оценку — ценное отличие от обычных задач.
Какие прототипы делать в первую очередь
Новые библиотеки. Архитектурные решения. И то и другое относится к техническим инновациям, которые сложно точно оценить — многие детали проясняются только в процессе реализации. Если не бросаться в полноценную реализацию, а начать с прототипа — обычно удается вытащить всю недостающую информацию на раннем этапе. В нашей команде принято соглашение, что технические инновации, кроме самых небольших (на несколько часов), обязательно разделяются на прототип и реализацию. В результате по техническим историям возникает меньше проблем, чем по изменениям запрошенным бизнесом. Раньше, когда мы менее осторожно подходили к техническим историям, всё было наоборот. Наш владелец продукта страшен в гневе, когда из-за затянувшегося рефакторинга приходится перекраивать планы на релиз. Зачем попадать в эту ситуацию, когда её можно избежать?
UI/UX решения. Можно сделать дешевую, упрощенную версию нового интерфейсного решения. И проверить на настоящих людях, так ли оно хорошо работает, как думает дизайн-команда. Если окажется, что нет — отлично! Мы потратили в 4-5-8 раз меньше времени, чем на полноценную реализацию и отвергли неудачную гипотезу. А без проверки фичу пришлось бы сначала делать, а потом выпиливать и заменять на что-то ещё.
Экспериментальные фичи. Бывало ли такое, что ваша команда продаж продала клиенту фичу, про которую вы ещё не знаете, можно ли её вообще реализовать? Продавать несуществующее опасно — может оказаться, что оно ещё и технически нереализуемое. А если делать что-то новое до проверки спроса — есть риск, что оно окажется невостребованным и усилия будут потрачены напрасно. Прототипы в этой ситуации представляют оптимальный баланс. Будучи в несколько раз дешевле полноценной разработки по усилиям, они снимают почти всю неизвестность относительно реализуемости, неочевидных нюансов и узких мест.
Источники рисков: технический долг
Следующий важный источник рисков — наш собственный технический долг. Представим, что у нас есть две аналогичных задачи. Одна из них относится к модулю с минимальным техническим долгом, а вторая к самой запущенной части системы. Трудоемкость реализации этих задач может отличаться в несколько раз. Кроме того, задачу с большим техдолгом гораздо сложнее оценить и ошибка планирования будет выше.

Тема управления техническим долгом большая. Поэтому, остановимся только на той части, которая касается управления бэклогом.
Основной принцип, к которому мы пришли — минимизация неопределенности, вызванной техническим долгом. Как мы этого добиваемся?
Технический долг зафиксирован в бэклоге
Людям свойственно забывать плохое. Например, впечатления от работы с самым старым модулем системы. Долгие попытки разобраться в том, что происходит или заново проанализировать код в неприятном стиле, провести многочасовую отладку — всё это может быть забыто в среднесрочной перспективе. А когда снова потребуется, то работа с этим модулем принесёт неприятные сюрпризы снова.
Поэтому, мы заносим весь технический долг в бэклог. Перед планированием новой функциональности есть обязательная активность по поиску связанного с этими местами системы технического долга.
Рефакторинг и новая функциональность — отдельные задачи
Ранее я писал о принципе «одна история — одна цель». В применении к техническому долгу это означает, что нужно разделять истории на его устранение и истории на создание новой функциональности. Тем самым, мы разделяем неопределенность от рефакторинга и неопределенность от реализации новой функциональности. Весь процесс получается более управляемым.
Если что-то идёт не так, то у нас есть готовый «план Б» — мы сможем сделать ту же функциональность, но уже без рефакторинга. Для критичных задач это бывает необходимо и является меньшим злом, чем попытка героически стабилизировать сырой результат рефакторинга и одновременно добавлять в него новую функциональность.
Дополнительный плюс такого разделения в том, что устранение техдолга не имеет внешних зависимостей. Эти задачи можно брать в работу сразу, не дожидаясь ничего от других команд.
Источники рисков: соседние команды

Последний из ведущих источников рисков — соседние команды.
Как я уже говорил, наша команда занимается фронтендом. В общем контексте жизненный цикл новых фич выглядит так:
- Идея приходит к владельцу продукта на оценку, приоретизацию и проработку.
- Дальше идет реализация бэкенда.
- Дизайнеры прорабатывают интерфейс.
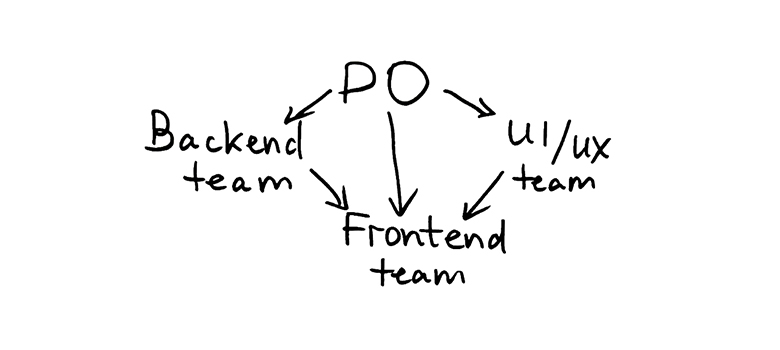
После получения и того и другого, мы приступаем к созданию фронтенда. Позиция в конце графа зависимостей добавляет свои сложности в работу.
Боль замыкающей команды
Максимум неизвестности при планировании. Помимо неопределенности в исходной задаче, мы получаем от каждой предшествующей команды неопределенность по срокам, качеству и деталям реализации.
Сдвиг сроков / поздняя интеграция. Что происходит, если команда бэкенда затягивает реализацию своей части задачи или когда дизайнеры долго согласовывают интерфейсное решение? Правильно, плывут сроки фронтенд-команды. Может получиться так, что итоговую интеграцию какой-нибудь критичной задачи нужно будет делать с одной попытки, потому что весь резерв времени был съеден выше по цепочке.
Недоработки ранее по цепочке. Перекликается с предыдущим. Несовершенство работы каждой команды создает дополнительную работу для всех следующих команд. Например, в бэкенде есть проблемы, которые не удается вовремя исправить. В результате, мы вынуждены скрывать их от пользователя на стороне фронтенда. А потом тратить время на удаление этих костылей, когда правильный бэкенд будет готов.
Описанные сложности полностью преодолеть невозможно. В лучшем случае, удастся несколько снизить частоту возникновения событий и средний масштаб проблемы. Так что основное, что мы можем сделать для управления своими рисками — всегда помнить об этих проблемах и не поддаваться излишнему оптимизму.
Декомпозиция по зависимостям
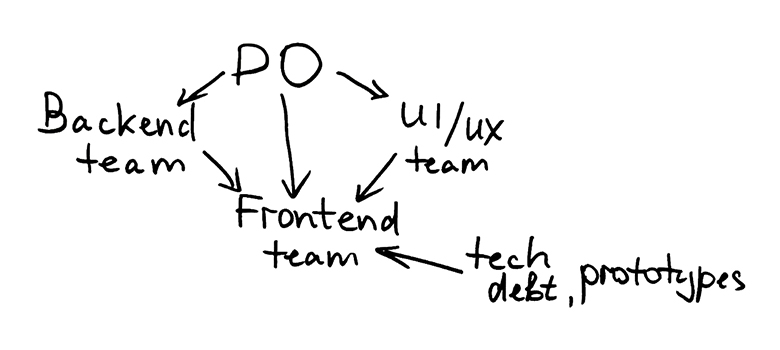
Ситуацию можно улучшить, если разделить интеграцию с каждой предыдущей командой на отдельные истории. Кроме того, можно заранее решить внутренние зависимости — убрать технический долг, сделать прототипы и исследования.
Например, в случае с управлением версиями документов, мы разделяли работу на такие истории:
Технический долг. Рефакторинг старого компонента боковой панели, куда предполагалось встраивать информацию о версиях. Никаких зависимостей, можно начинать в любой момент.
Интеграция с бэкендом. Сделать «страшную», но работающую версию, интегрировать с первой версией бэкенда. Тут мы проверяли вопросы работоспособности API и особенности поведения бэкенда без оглядки на UI.
Интеграция дизайна. Сделать красиво. Воплотили макеты в интерфейсе, обсудили, переделали некрасивые моменты. И так несколько раз, потому что согласовать все вопросы по дизайну с первой итерации — это фантастика.
Интеграция финальной версии бэкенда. Если мы знаем, что часть функциональности бэкенда будет готова только в самом конце релиза, то её поддержку в интерфейсе необходимо выделять в отдельную историю. Важно получить минимум рисков к этому моменту, потому что времени в резерве гарантированно не останется. Готовность предыдущих историй к моменту интеграции существенно влияет на достижение этого результата.
Выводы и рекомендации

Управление рисками — процесс вероятностный. Если у вас не возникает проблем, то это совсем не означает, что вы хорошо управляете рисками. И даже если вы всё сделали правильно, а проблемы всё равно возникли — то вам могло просто не повезти. Результат важен, но и про процесс забывать нельзя.
Обычно, главным критерием эффективности разработки является объем сделанного за единицу времени. Ускорять процесс можно, но многие варианты оптимизации повышают риски. Попробуйте отрегулировать другой параметр: можно поработать над снижением потерь от возникающих проблем. Практики управления рисками помогут сделать так, чтобы проблем было меньше и средний ущерб от каждой был бы ниже.
Поскольку предотвращение проблем обычно дешевле борьбы с их последствиями, то общая эффективность только выиграет.
«Быстро — это медленно, но без перерывов»
Практики из этой статьи тоже можно разделить на небольшие фрагменты. И каждый из них — использовать по отдельности. Возьмите ту часть, что покажется самой простой для внедрения и попробуйте реализовать в своем проекте. Лучший способ получить пользу от этого материала — попробовать что-нибудь сделать на практике, посмотреть на результат и улучшить.
p.s. Отдельное спасибо дизайнеру Марине Зиновьевой за иллюстрации для этой статьи.
ссылка на оригинал статьи https://habr.com/ru/company/ncloudtech/blog/478304/
Добавить комментарий