
В прошлой статье мы познакомились со стеком ELK, из каких программных продуктов он состоит. И первая задача с которой сталкивается инженер при работе с ELK стеком это отправление логов для хранения в elasticsearch для последующего анализа. Однако, это просто лишь на словах, elasticsearch хранит логи в виде документов с определенными полями и значениями, а значит инженер должен используя различные инструменты распарсить сообщение, которое отправляется с конечных систем. Сделать это можно несколькими способами — самому написать программу, которая по API будет добавлять документы в базу либо использовать уже готовые решения. В рамках данного курса мы будем рассматривать решение Logstash, которое является частью ELK stack. Мы посмотрим как можно отправить логи с конечных систем в Logstash, а затем будем настраивать конфигурационный файл для парсинга и перенаправления в базу данных Elasticsearch. Для этого в качестве входящей системы берем логи с межсетевого экрана Check Point.
В рамках курса не рассматривается установка ELK stack, так как существует огромное количество статей на эту тему, будем рассматривать конфигурационную составляющую.
Составим план действий по конфигурации Logstash:
- Проверка что elasticsearch будет принимать логи (проверка работоспособности и открытости порта).
- Рассматриваем каким образом мы можем отправить события в Logstash, выбираем способ, реализуем.
- Настраиваем Input в конфигурационном файле Logstash.
- Настраиваем Output в конфигурационном файле Logstash в режиме дебага, для того чтобы понять как выглядит лог сообщение.
- Настраиваем Filter.
- Настраиваем корректный Output в ElasticSearch.
- Запускам Logstash.
- Проверяем логи в Kibana.
Рассмотрим более детально каждый пункт:
Проверка что elasticsearch будет принимать логи
Для этого можно проверить командой curl доступ в Elasticsearch из системы, на которой развернут Logstash. Если у вас настроена аутентификация, то также через curl передаем пользователь/пароль, указываем порт 9200 если вы его не меняли. Если приходит ответ наподобие как указано ниже, значит все в порядке.
[elastic@elasticsearch ~]$ curl -u <<user_name>> : <<password>> -sS -XGET "<<ip_address_elasticsearch>>:9200" { "name" : "elastic-1", "cluster_name" : "project", "cluster_uuid" : "sQzjTTuCR8q4ZO6DrEis0A", "version" : { "number" : "7.4.1", "build_flavor" : "default", "build_type" : "rpm", "build_hash" : "fc0eeb6e2c25915d63d871d344e3d0b45ea0ea1e", "build_date" : "2019-10-22T17:16:35.176724Z", "build_snapshot" : false, "lucene_version" : "8.2.0", "minimum_wire_compatibility_version" : "6.8.0", "minimum_index_compatibility_version" : "6.0.0-beta1" }, "tagline" : "You Know, for Search" } [elastic@elasticsearch ~]$ Если ответ не пришел, то может быть несколько видов ошибок: не работает процесс elasticsearch, указан не тот порт, либо порт заблокирован фаерволом на сервере, где стоит elasticsearch.
Рассматриваем как можно отправить логи в Logstash с межсетевого экрана check point.
С Check Point management server можно отправить логи в Logstash через syslog, используя утилиту log_exporter, более подробно можно ознакомиться с ней по данной статье, здесь оставим только команду которая создает поток:
cp_log_export add name check_point_syslog target-server <<ip_address_logstash>> target-port 5555 protocol tcp format generic read-mode semi-unified
<<ip_address_logstash>> — адрес сервера на котором крутится Logstash, target-port 5555 — порт на который будем отправлять логи, отправление логов по tcp может нагрузить сервер, поэтому в некоторых случаях более правильно ставить udp.
Настраиваем INPUT в конфигурационном файле Logstash.
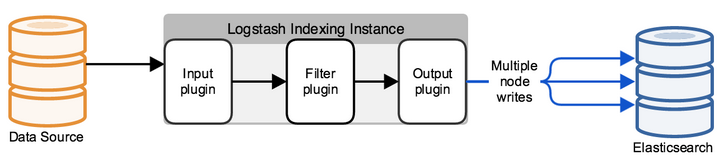
По умолчанию конфигурационный файл находится в директории /etc/logstash/conf.d/. Конфигурационный файл состоит из 3 осмысленных частей: INPUT, FILTER, OUTPUT. В INPUT мы указываем откуда система будет брать логи, в FILTER парсим лог — настраиваем как поделить сообщение на поля и значения, в OUTPUT настраиваем выходящий поток — куда распарсенные логи будут отправляться.
Сначала настроим INPUT, рассмотрим некоторые типы которые могут быть — file, tcp и exe.
Tcp:
input { tcp { port => 5555 host => “10.10.1.205” type => "checkpoint" mode => "server" } } mode => «server»
Говорит о том что Logstash принимает соединения.
port => 5555
host => “10.10.1.205”
Принимаем соединения по IP адресу 10.10.1.205 (Logstash), порт 5555 — порт должен быть разрешен политикой фаервола.
type => «checkpoint»
Маркируем документ, очень удобно в случае если у вас несколько входящих соединений. В последующем для каждого соединения можно написать свой фильтр с помощью логической конструкции if.
File:
input { file { path => "/var/log/openvas_report/*" type => "openvas" start_position => "beginning" } } Описание настроек:
path => «/var/log/openvas_report/*»
Указываем директорию, файлы в которой необходимо считать.
type => «openvas»
Тип события.
start_position => «beginning»
При изменении файла считывает файл целиком, если выставить «end» то система ждет появления новых записей в конце файла.
Exec:
input { exec { command => "ls -alh" interval => 30 } } По данному инпуту запускается (только!) shell команда и ее вывод оборачивается в лог сообщение.
command => «ls -alh»
Команда, вывод которой нас интересует.
interval => 30
Интервал вызова команды в секундах.
Для того чтобы принимать логи с межсетевого экрана прописываем фильтр tcp или udp, в зависимости от того как отправляются логи в Logstash.
Настраиваем Output в конфигурационном файле Logstash в режиме дебага, для того чтобы понять как выглядит лог сообщение.
После того как мы сконфигурировали INPUT, необходимо понять как будет выглядеть лог сообщение, какие методы необходимо использовать для настройки фильтра(парсера) логов.
Для этого будем использовать фильтр который выдает результат в stdout для того чтобы просмотреть исходное сообщение, полностью конфигурационный файл на текущий момент будет выглядеть так:
input { tcp { port => 5555 type => "checkpoint" mode => "server" host => “10.10.1.205” } } output { if [type] == "checkpoint" { stdout { codec=> json } } } Запускам команду для проверки:
sudo /usr/share/logstash/bin//logstash -f /etc/logstash/conf.d/checkpoint.conf
Видим результат, картинка кликабельна:

Если скопировать это будет выглядеть так:
action=\"Accept\" conn_direction=\"Internal\" contextnum=\"1\" ifdir=\"outbound\" ifname=\"bond1.101\" logid=\"0\" loguid=\"{0x5dfb8c13,0x5,0xfe0a0a0a,0xc0000000}\" origin=\"10.10.10.254\" originsicname=\"CN=ts-spb-cpgw-01,O=cp-spb-mgmt-01.tssolution.local.kncafb\" sequencenum=\"8\" time=\"1576766483\" version=\"5\" context_num=\"1\" dst=\"10.10.10.10\" dst_machine_name=\"ts-spb-dc-01@tssolution.local\" layer_name=\"TSS-Standard Security\" layer_name=\"TSS-Standard Application\" layer_uuid=\"dae7f01c-4c98-4c3a-a643-bfbb8fcf40f0\" layer_uuid=\"dbee3718-cf2f-4de0-8681-529cb75be9a6\" match_id=\"8\" match_id=\"33554431\" parent_rule=\"0\" parent_rule=\"0\" rule_action=\"Accept\" rule_action=\"Accept\" rule_name=\"Implicit Cleanup\" rule_uid=\"6dc2396f-9644-4546-8f32-95d98a3344e6\" product=\"VPN-1 & FireWall-1\" proto=\"17\" s_port=\"37317\" service=\"53\" service_id=\"domain-udp\" src=\"10.10.1.180\" ","type":"qqqqq","host":"10.10.10.250","@version":"1","port":50620}{"@timestamp":"2019-12-19T14:50:12.153Z","message":"time=\"1576766483\" action=\"Accept\" conn_direction=\"Internal\" contextnum=\"1\" ifdir=\"outbound\" ifname=\"bond1.101\" logid=\"0\" loguid=\"{0x5dfb8c13, Смотря на данные сообщения, понимаем что логи имеют вид: поле = значение или key = value, а значит подходит фильтр, который называется kv. Для того чтобы правильно выбрать фильтр к каждому конкретному случаю было бы неплохо с ними ознакомиться в технической документации, либо спросить друга.
Настраиваем Filter
На прошлом этапе выбрали kv, далее представлена конфигурация этого фильтра:
filter { if [type] == "checkpoint"{ kv { value_split => "=" allow_duplicate_values => false } } } Выбираем символ по которому будем делить поле и значение — “=”. Если у нас есть в логе одинаковые записи, сохраняем в базе только один экземпляр, иначе у вас получится массив из одинаковых значений, то есть если имеем сообщение “foo = some foo=some” записываем только foo = some.
Настраиваем корректный Output в ElasticSearch
После того как настроен Filter можно выгружать логи в базу elasticsearch:
output { if [type] == "checkpoint" { elasticsearch { hosts => ["10.10.1.200:9200"] index => "checkpoint-%{+YYYY.MM.dd}" user => "tssolution" password => "cool" } } } Если документ подписан типом checkpoint, сохраняем событие в базу elasticsearch, которая принимает соединения на 10.10.1.200 на порт 9200 по дефолту. Каждый документ сохраняется в определенный индекс, в данном случае сохраняем в индекс «checkpoint-» + текущая временная дата. Каждый индекс может обладать определенным набором полей, либо создается автоматически при появлении нового поля в сообщении, настройки полей и их тип можно посмотреть в mappings.
Если у вас настроена аутентификация ( рассмотрим позже), обязательно должны быть указаны креды для записи в конкретный индекс, в данном примере это «tssolution» с паролем «cool». Можно разграничить права пользователей для записи логов только в определенный индекс и никакие больше.
Запускаем Logstash.
Конфигурационный файл Logstash:
input { tcp { port => 5555 type => "checkpoint" mode => "server" host => “10.10.1.205” } } filter { if [type] == "checkpoint"{ kv { value_split => "=" allow_duplicate_values => false } } } output { if [type] == "checkpoint" { elasticsearch { hosts => ["10.10.1.200:9200"] index => "checkpoint-%{+YYYY.MM.dd}" user => "tssolution" password => "cool" } } } Проверяем конфигурационный файл на правильность составления:
/usr/share/logstash/bin//logstash -f checkpoint.conf

Запускаем процесс Logstash:
sudo systemctl start logstash
Проверяем что процесс запустился:
sudo systemctl status logstash
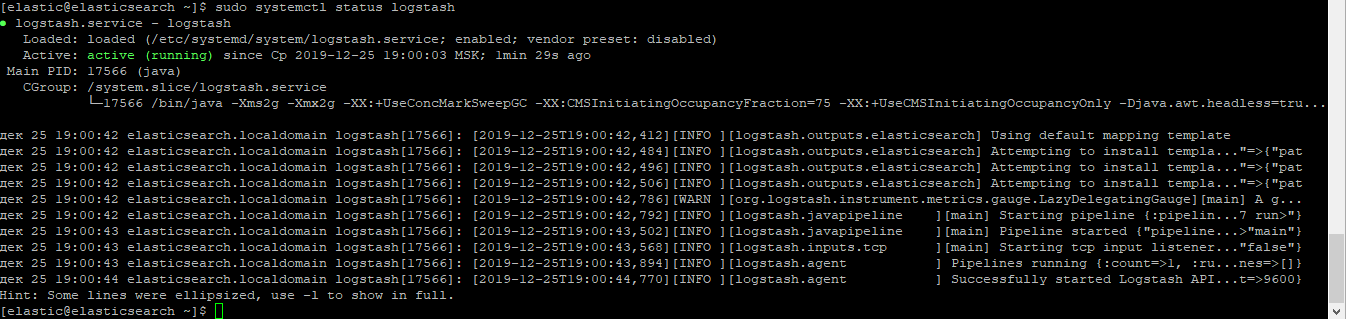
Проверяем поднялся ли сокет:
netstat -nat |grep 5555

Проверяем логи в Kibana.
После того как все запущено, заходим в Kibana — Discover, убеждаемся что все настроено правильно, картинка кликабельна!
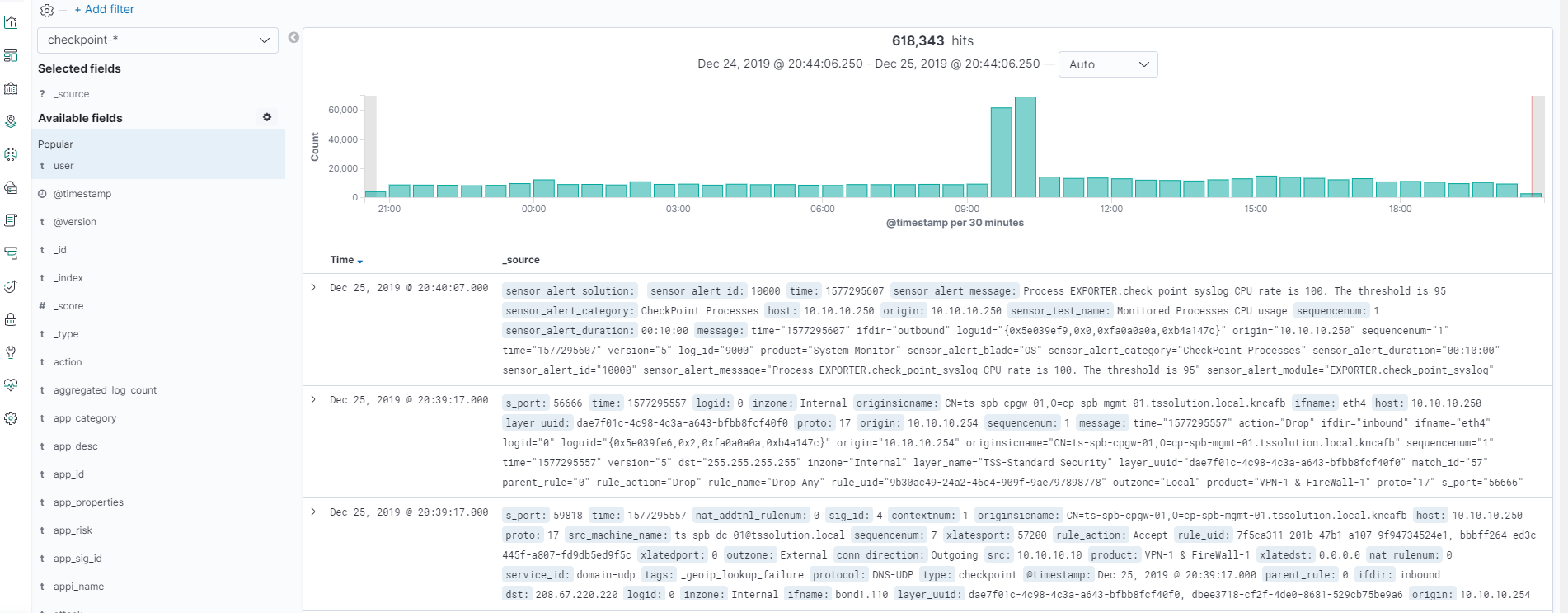
Все логи на месте и мы можем видеть все поля и их значения!
Заключение
Мы рассмотрели как писать конфигурационный файл Logstash, в результате получили парсер всех полей и значений. Теперь мы можем работать с поиском и составлением графиков по определенным полям. Далее в курсе мы рассмотрим визуализацию в Kibana, создадим простенький дашбоард. Стоит упомянуть что конфигурационный файл Logstash требуется постоянно дописывать в определенных ситуациях, например, когда хотим заменить значение поля с цифры на слово. В последующих статьях мы будем постоянно это делать.
Так что следите за обновлениями (Telegram, Facebook, VK, TS Solution Blog), Яндекс.Дзен.
ссылка на оригинал статьи https://habr.com/ru/company/tssolution/blog/481960/
Добавить комментарий