Язык запросов Cypher изначально разработан специально для графовой СУБД Neo4j. Целью Cypher является предоставить человеко-читаемый язык запросов к графовым базам данных похожий на SQL. На сегодня Cypher поддерживается несколькими графовыми СУБД. Для стандартизации Cypher была создана организация openCypher.
Основы работы с СУБД Neo4j описаны в статье Основы работы с Neo4j в браузере.
Для знакомства с Cypher рассмотрим пример генеалогического дерева заимствованный из классического учебника по Прологу за авторством И. Братко. На этом примере будет показано как добавлять узлы и связи в граф, как им назначать метки и атрибуты и как задавать вопросы.
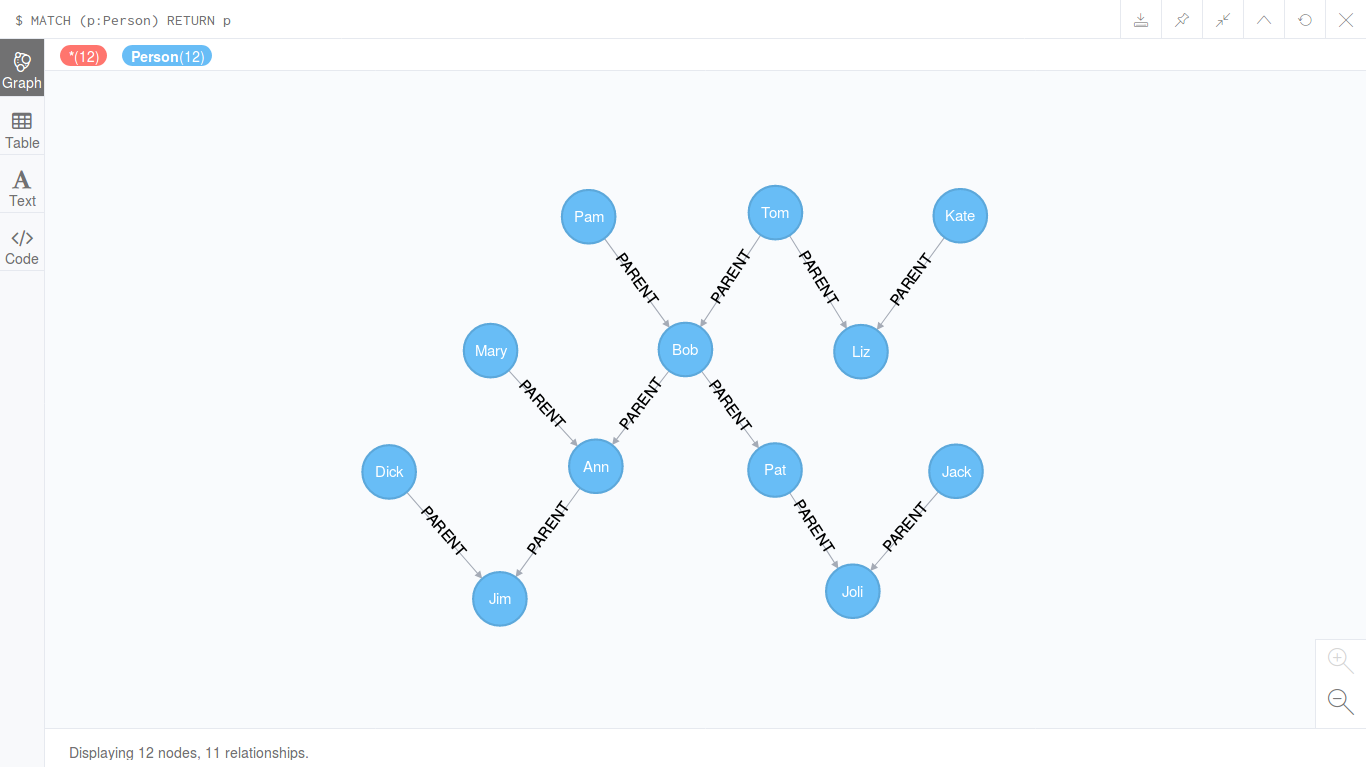
Итак, пусть мы имеем генеалогическое дерево, представленное на картинке ниже.
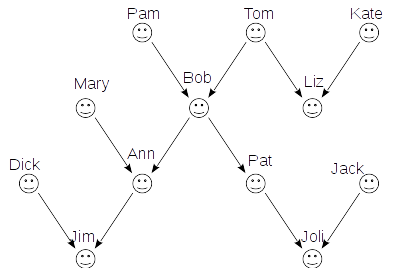
Посмотрим как сформировать соответствующий граф на языке Cypher:
CREATE (pam:Person {name: "Pam"}), (tom:Person {name: "Tom"}), (kate:Person {name: "Kate"}), (mary:Person {name: "Mary"}), (bob:Person {name: "Bob"}), (liz:Person {name: "Liz"}), (dick:Person {name: "Dick"}), (ann:Person {name: "Ann"}), (pat:Person {name: "Pat"}), (jack:Person {name: "Jack"}), (jim:Person {name: "Jim"}), (joli:Person {name: "Joli"}), (pam)-[:PARENT]->(bob), (tom)-[:PARENT]->(bob), (tom)-[:PARENT]->(liz), (kate)-[:PARENT]->(liz), (mary)-[:PARENT]->(ann), (bob)-[:PARENT]->(ann), (bob)-[:PARENT]->(pat), (dick)-[:PARENT]->(jim), (ann)-[:PARENT]->(jim), (pat)-[:PARENT]->(joli), (jack)-[:PARENT]->(joli)
Запрос CREATE на добавление данных в графовую СУБД состоит из двух частей: добавление узлов и добавление связей между ними. Каждому добавляемому узлу назначено в рамках данного запроса имя, которое затем использовано при создании связей. Узлы и связи могут хранить документы. В нашем случае узлы содержат документы с полями name, а связи документов не содержат. Также узлы и связи могут быть помечены. В нашем случае узлам назначена метка Person, а связям PARENT. Метка в запросах выделяется двоеточием перед её названием.
Итак, Neo4j нам сообщил, что: Added 12 labels, created 12 nodes, set 12 properties, created 11 relationships, completed after 9 ms.
Посмотрим, что у нас получилось:
MATCH (p:Person) RETURN p
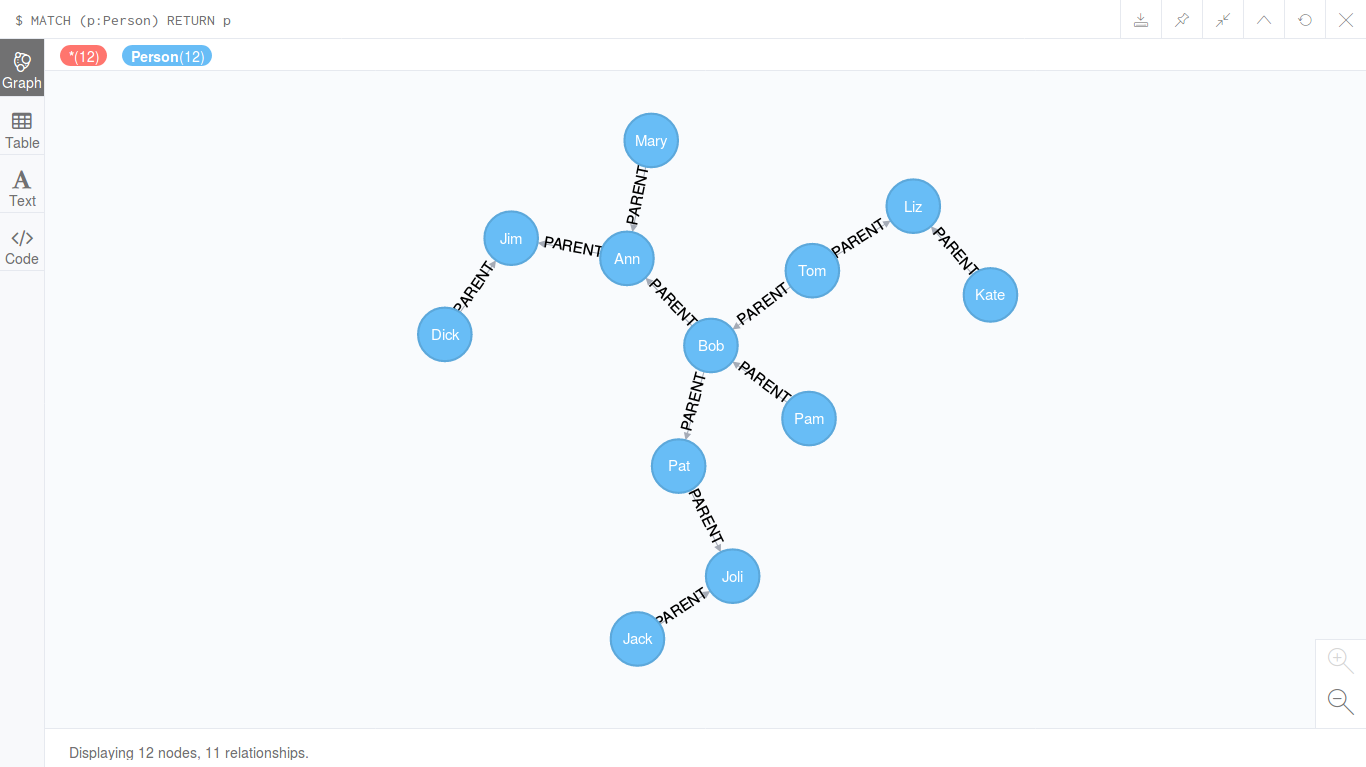
Никто не запрещает нам отредактировать внешний вид получившегося графа:
Что с этим можно делать? Можно убедиться в том, что, например, Pam является
родителем Bob’а:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Bob"}) RETURN ans
Получим соответствующий подграф:

Однако это не совсем то, что нам надо. Изменим запрос:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Bob"}) RETURN ans IS NOT NULL
Теперь в ответ получаем true. А если спросим:
MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Liz"}) RETURN ans IS NOT NULL
То ничего не получим… Здесь нужно добавить слово OPTIONAL, тогда если
результат будет пуст, то будет возвращаться false:
OPTIONAL MATCH ans = (:Person {name: "Pam"})-[:PARENT]->(:Person {name: "Liz"}) RETURN ans IS NOT NULL
Теперь получаем ожидаемый ответ false.
Далее, можно посмотреть, кто кому является родителем:
MATCH (p1:Person)-[:PARENT]->(p2:Person) RETURN p1, p2
Откроем вкладку результата с надписью Text и увидим таблицу с двумя колонками:
╒═══════════════╤═══════════════╕ │"p1" │"p2" │ ╞═══════════════╪═══════════════╡ │{"name":"Pam"} │{"name":"Bob"} │ ├───────────────┼───────────────┤ │{"name":"Tom"} │{"name":"Bob"} │ ├───────────────┼───────────────┤ │{"name":"Tom"} │{"name":"Liz"} │ ├───────────────┼───────────────┤ │{"name":"Kate"}│{"name":"Liz"} │ ├───────────────┼───────────────┤ │{"name":"Mary"}│{"name":"Ann"} │ ├───────────────┼───────────────┤ │{"name":"Bob"} │{"name":"Ann"} │ ├───────────────┼───────────────┤ │{"name":"Bob"} │{"name":"Pat"} │ ├───────────────┼───────────────┤ │{"name":"Dick"}│{"name":"Jim"} │ ├───────────────┼───────────────┤ │{"name":"Ann"} │{"name":"Jim"} │ ├───────────────┼───────────────┤ │{"name":"Pat"} │{"name":"Joli"}│ ├───────────────┼───────────────┤ │{"name":"Jack"}│{"name":"Joli"}│ └───────────────┴───────────────┘
Что ещё мы можем узнать? Например, кто является родителем конкретного члена рода, например, для Bob’а:
MATCH (parent:Person)-[:PARENT]->(:Person {name: "Bob"}) RETURN parent.name
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Tom" │ ├─────────────┤ │"Pam" │ └─────────────┘
Здесь в качестве ответа мы запрашиваем не весь узел, а только его конкретный атрибут.
Также можем узнать, кто дети Bob’а:
MATCH (:Person {name: "Bob"})-[:PARENT]->(child:Person) RETURN child.name
╒════════════╕ │"child.name"│ ╞════════════╡ │"Ann" │ ├────────────┤ │"Pat" │ └────────────┘
Ещё мы можем поинтересоваться, у кого есть дети:
MATCH (parent:Person)-[:PARENT]->(:Person) RETURN parent.name
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Pam" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Kate" │ ├─────────────┤ │"Mary" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Dick" │ ├─────────────┤ │"Ann" │ ├─────────────┤ │"Pat" │ ├─────────────┤ │"Jack" │ └─────────────┘
Хм, Tom и Bob встретились по два раза, исправим это:
MATCH (parent:Person)-[:PARENT]->(:Person) RETURN DISTINCT parent.name
Мы добавили в возвращаемый результат запроса слово DISTINCT, по смыслу
аналогичное таковому в SQL.
╒═════════════╕ │"parent.name"│ ╞═════════════╡ │"Pam" │ ├─────────────┤ │"Tom" │ ├─────────────┤ │"Kate" │ ├─────────────┤ │"Mary" │ ├─────────────┤ │"Bob" │ ├─────────────┤ │"Dick" │ ├─────────────┤ │"Ann" │ ├─────────────┤ │"Pat" │ ├─────────────┤ │"Jack" │ └─────────────┘
Можно также заметить, что Neo4j возвращает нам родителей в порядке их ввода в запросе CREATE.
Давайте теперь спросим, кто является дедушкой или бабушкой:
MATCH (grandparent:Person)-[:PARENT]->()-[:PARENT]->(:Person) RETURN DISTINCT grandparent.name
Отлично, всё так и есть:
╒══════════════════╕ │"grandparent.name"│ ╞══════════════════╡ │"Tom" │ ├──────────────────┤ │"Pam" │ ├──────────────────┤ │"Bob" │ ├──────────────────┤ │"Mary" │ └──────────────────┘
В шаблоне запроса мы использовали промежуточный безымянный узел () и две связи типа PARENT.
Выясним теперь кто является отцом. Отцом является мужчина, у которого есть ребёнок. Таким образом, нам не хватает данных о том, кто является мужчиной. Соответственно, для определения, кто является мамой, потребуется знать, кто является женщиной. Добавим соответствующие сведения в нашу базы данных. Для этого мы присвоим метки Male и Female уже существующим узлам.
MATCH (p:Person) WHERE p.name IN ["Tom", "Dick", "Bob", "Jim", "Jack"] SET p:Male
MATCH (p:Person) WHERE p.name IN ["Pam", "Kate", "Mary", "Liz", "Ann", "Pat", "Joli"] SET p:Female
Поясним, что мы здесь сделали: мы выбрали все узлы с меткой Person, проверили их
свойство name по заданному списку, задаваемому в квадратных скобках, и присвоили подходящим узлам метку Male или Female соответственно.
Проверим:
MATCH (p:Person) WHERE p:Male RETURN p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Tom" │ ├────────┤ │"Bob" │ ├────────┤ │"Dick" │ ├────────┤ │"Jack" │ ├────────┤ │"Jim" │ └────────┘
MATCH (p:Person) WHERE p:Female RETURN p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Pam" │ ├────────┤ │"Kate" │ ├────────┤ │"Mary" │ ├────────┤ │"Liz" │ ├────────┤ │"Ann" │ ├────────┤ │"Pat" │ ├────────┤ │"Joli" │ └────────┘
Мы запросили все узлы с меткой Person, у которой есть также метка Male или Female, соответственно. Но мы могли бы составить наши запросы несколько иначе:
MATCH (p:Person:Male) RETURN p.name MATCH (p:Person:Female) RETURN p.name
Давайте ещё раз взглянем на наш граф визуально:
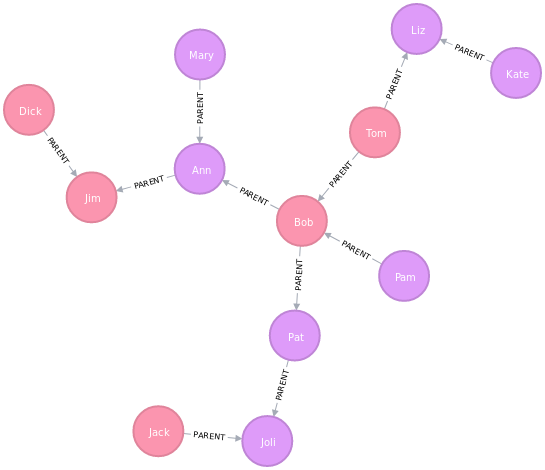
Neo4j Browser раскрасил узлы в два разных цвета в соответствии с метками Male и
Female.
Отлично, теперь мы можем запросить из базы данных всех отцов:
MATCH (p:Person:Male)-[:PARENT]->(:Person) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Tom" │ ├────────┤ │"Bob" │ ├────────┤ │"Dick" │ ├────────┤ │"Jack" │ └────────┘
И матерей:
MATCH (p:Person:Female)-[:PARENT]->(:Person) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Pam" │ ├────────┤ │"Kate" │ ├────────┤ │"Mary" │ ├────────┤ │"Ann" │ ├────────┤ │"Pat" │ └────────┘
Давайте теперь сформулируем отношения брат и сестра. X является братом для Y,
если он мужчина, и для X и Y имеется хотя бы один общий родитель. Аналогично для
отношения сестры.
Отношение брат на Cypher:
MATCH (brother:Person:Male)<-[:PARENT]-()-[:PARENT]->(p:Person) RETURN brother.name, p.name
╒══════════════╤════════╕ │"brother.name"│"p.name"│ ╞══════════════╪════════╡ │"Bob" │"Liz" │ └──────────────┴────────┘
Отношение сестра на Cypher:
MATCH (sister:Person:Female)<-[:PARENT]-()-[:PARENT]->(p:Person) RETURN sister.name, p.name
╒═════════════╤════════╕ │"sister.name"│"p.name"│ ╞═════════════╪════════╡ │"Liz" │"Bob" │ ├─────────────┼────────┤ │"Ann" │"Pat" │ ├─────────────┼────────┤ │"Pat" │"Ann" │ └─────────────┴────────┘
Итак, мы можем узнавать кто чей родитель, а также кто чей дедушка или бабушка. А как быть с предками более дальними? С прадедушками, прапрадедушками или так далее? Не будем же мы для каждого такого случая писать соответствующее правило, да и всё проблематичней это будет с каждым разом. На самом деле всё просто: X является для Y предком, если он является предком для родителя Y. Cypher предоставляет паттерн *, позволяющий потребовать последовательность связей любой длины:
MATCH (p:Person)-[*]->(s:Person) RETURN DISTINCT p.name, s.name
Есть в этом правда одна проблема: это будут любые связи. Добавим указание на связь PARENT:
MATCH (p:Person)-[:PARENT*]->(s:Person) RETURN DISTINCT p.name, s.name
Чтобы не увеличивать длину статьи, найдём всех предков Joli:
MATCH (p:Person)-[:PARENT*]->(:Person {name: "Joli"}) RETURN DISTINCT p.name
╒════════╕ │"p.name"│ ╞════════╡ │"Jack" │ ├────────┤ │"Pat" │ ├────────┤ │"Bob" │ ├────────┤ │"Pam" │ ├────────┤ │"Tom" │ └────────┘
Рассмотрим более сложное правило для выяснения кто кому является родственником.
Во-первых, родственниками являются предки и потомки, например, сын и мать, бабушка и внук. Во-вторых, родственниками являются братья и сёстры в том числе двоюродные, троюродные и так далее, что в терминах предков означает, что у них общий предок. И, в-третьих, родственниками считаются те, у кого общие потомки, например, муж и жена.
На Cypher для множества паттернов нужно воспользоваться UNION:
MATCH (r1:Person)-[:PARENT*]-(r2:Person) RETURN DISTINCT r1.name, r2.name UNION MATCH (r1:Person)<-[:PARENT*]-(:Person)-[:PARENT*]->(r2:Person) RETURN DISTINCT r1.name, r2.name UNION MATCH (r1:Person)-[:PARENT*]->(:Person)<-[:PARENT*]-(r2:Person) RETURN DISTINCT r1.name, r2.name
Здесь, в первом правиле, использованы связи, направление которых нам неважно. Указывается такая связь без стрелки, просто тире -. Второе и третье правило записаны очевидным, уже знакомым образом.
Мы не будем здесь приводить результат тотального запроса, скажем только то, что найденных пар родственников 132, что согласуется с вычисленным значением как число упорядоченных пар из 12. Мы могли бы также конкретизировать данный запрос, заменив вхождение переменной r1 или r2 на (:Person {name: "Liz"}) к примеру, однако в нашем случае в этом нет большого смысла, так как все персоны в нашей базе данных очевидно являются родственниками.
На этом мы закончим рассматривать выявление связей между персонами в нашей базе данных.
На последок рассмотрим как удалять узлы и связи.
Для удаления всех наших персон, можно выполнить запрос:
MATCH (p:Person) DELETE p
Однако, Neo4j нам сообщит, что нельзя удалить узлы, у которых есть связи.
Поэтому удалим сначала связи и затем повторим удаление узлов:
MATCH (p1:Person)-[r]->(p2:Person) DELETE r
Что мы сейчас сделали: сопоставили две персоны, между которыми есть связь, поименовали эту связь как r и затем удалили её.
Заключение
В статье на простом примере социального графа показано, как использовать возможности языка запросов Cypher. Более подробная информация о языке Cypher может быть найдена по ссылкам ниже.
Ссылки
Библиография
- Робинсон Ян, Вебер Джим, Эифрем Эмиль. Графовые базы данных. Новые возможности
для работы со связанными данными / пер. с англ. – 2-е изд. – М.: ДМК-Пресс,
2016 – 256 с. - Братко И. Программирование на языке Пролог для искусственного интеллекта:
пер. с англ. – М.: Мир, 1990. – 560 с.: ил.
Послесловие
Автору статьи известно только две компании (обе из Санкт-Петербурга), которые для своих продуктов используют графовые СУБД. Но хотелось бы знать, как много компаний читателей этой статьи используют их в своих разработках. Поэтому предлагаю поучаствовать в опросе. Пишите также о своём опыте в комментариях, очень интересно будет узнать.
ссылка на оригинал статьи https://habr.com/ru/post/482418/
Добавить комментарий