
Введение
В ходе доработки одного проекта возникала необходимость в кэширование часто запрашиваемых данных. Реализация кэширования возможна разными способами, но хотелось реализовать с минимальными изменениями исходного проекта. Результат, его плюсы и минусы описаны далее.
Как всё было?
Изначально на каждый запрос, содержащий идентификатор запрашиваемого объекта, выполнялся запрос в базу данных (БД) PostgreSQL. Точнее, несколько запросов, поскольку для формирования полного ответа было необходимо обратиться в несколько таблиц БД. В результате обработки запросов формировался довольно сложный объект, часть полей которого представлена интерфейсами. В памяти данный объект занимает порядка 250 кБайт.
Производительность при такой реализации была не велика, не более 3500 RPS (request per second) при запросе одних и тех же данных при 1000 конкурирующих потоков.
Сразу возник вопрос, а как повысить RPS: сменить роутер, оптимизировать работу БД, кэшировать данные? Роутер использовался неплохой (github.com/julienschmidt/httprouter), да и замена роутера в большом проекте потребует немало времени и высок риск что-то сломать. Для оптимизации работы с БД тоже потребуется переписать существенную часть кода (сейчас используется github.com/jmoiron/sqlx). Очевидно, что кэширование самый оптимальный путь увеличения RPS.
Простое решение
Самое простое, что приходит в голову, это использование in-memory кэша. При использовании такого кэша было получено порядка 20000 RPS. Производительность in-memory кэша прекрасна, но использовать с множеством экземпляров сервиса такой кэш не получиться. Никогда не знаешь, на какой экземпляр сервиса прилетит запрос, и запросы могут быть не только на получение данных, но и на удаление/обновление.
Полученная с in-memory кэшем производительность была взята за эталон при дальнейшем поиске решения.
Идея, плохая идея
А не положить ли результат запроса как есть в NoSQL БД Redis? Это типовое решение для кэширования ответов на запросы. Данные хранятся в памяти, при использовании нескольких экземпляров сервиса, все они могут использовать общий кэш. Данное решение, было быстро реализовано. И тесты показали… А тесты показали, что производительность особо не увеличилась.
Дальнейшее исследование показало, что основные потери производительности связаны с маршалингом и анмаршалингом. Преобразование структуры в JSON и обратно требует использовать рефлексию, а это крайне недёшево по производительности. Отказаться от маршалинга/анмаршалинг не получиться, поскольку надо при запросе из кэша получить полноценный объект, с возможностью вызова методов структур, а не только получить значения отдельных полей. Использование различных библиотек с оптимизацией маршалинга/анмаршалинг также не спасло, рост был, но до in-memory кэша было очень далеко. Поэтому было решено, а не подружить ли «ежа и ужа» и сделать гибридный кэш.
Гибрид «ужа и ежа»
Полноценным гибридом его не назовёшь (см. рис.), по сути получился in-memory кэш, но с синхронизацией через Redis (использовалась библиотека github.com/go-redis/redis). В Redis будет храниться только уникальный идентификатор запрошенного из БД объекта (ID-объекта). Он будет добавляться в Redis во время обработки запроса на создание объекта, либо запроса на получение существующего объекта из БД. ID-объекта будет служить ключом значения в Redis, а значением будет генерируемый UUID (англ. universally unique identifier, универсальный уникальный идентификатор»). Генерироваться UUID будет только в момент добавления объекта в Redis. Зачем этот UUID нужен, будет рассказано далее.
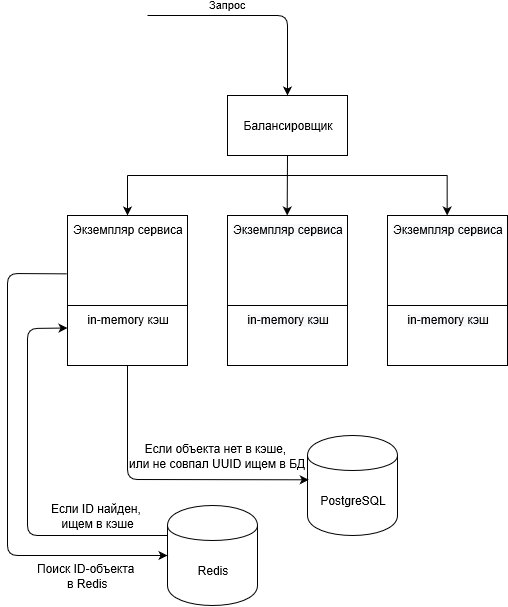
Структурная схема взаимодействия компонентов при сихронизации кэша через Redis
In-memory кэш реализован на базе sync.Map. Для элементов гибридного кэша задан TTL (time to live, время жизни), и если Redis сам чистит «протухшие» элементы, то in-memory кэш чиститься по таймеру (time.AfterFunc). Выполняется проход по всем элементам кэша и проверятся, а не «протух» ли элемент. Если происходит обращение к элементу кэша, то время его жизни продлевается, с ключами в Redis выполняется аналогичная операция.
Итак, теперь по алгоритму. Если приходит запрос и нам нужно извлечь объект, выполняется следующая последовательность действий:
- Смотрим, есть ли объект с заданным ID-объекта в Redis, если есть, то можно брать из in-memory кэша экземпляра сервиса:
- Если объекта нет в in-memory кэше, тогда берём его из БД и добавляем в in-memory кэш с UUID из Redis и обновляем TTL ключа в Redis.
- Если объект есть в in-memory кэше, тогда берём его из кэша, проверяем, совпадает ли UUID в кэше и в Redis и если да, то обновляем TTL в кэше и в Redis. Если UUID не совпадает, то удаляем объект из in-memory кэша, берём из БД, добавляем в in-memory кэш с UUID из Redis.
- Если объекта нет в Redis, то при наличии объекта в кэше, удалить его из кэша. Взять объект из БД и добавить в кэш и в Redis.
Если приходит запрос на удаление объекта, он сразу удаляется из БД, а далее операции с кэшем:
- Удаляем объект в Redis.
- Удаляем объект в in-memory кэше.
Теперь, если аналогичный запрос прилетит уже в другой экземпляр сервиса, то хотя объект ещё может лежать в in-memory кэше, использоваться он не будет.
Обновление объекта, после обновления в БД:
- Удаляем объект в Redis.
- Удаляем объект в in-memory кэше.
При запросе объекта в другом экземпляре сервиса будет выявлено, что в Redis его нет, значит надо взять из БД. Если есть ещё один экземпляр сервиса, и к нему запрос прилетел после обновления объекта и после его добавления вторым экземпляром в Redis, то, при проверке UUID будет выявлено различие, и третий экземпляр сервис тоже возьмёт объект из БД.
Т.е. по сути, в любой непонятной ситуации считаем, что кэш у нас неправильный, и надо брать данные из БД.
Заключение
В разработанном решении есть как плюсы, так и минусы.
Плюсы
- Разработанная схема кэширования позволила достичь порядка 19000 RPS, что практически равнозначно тестам с in-memory кэшем.
- В оригинальный код проекта внесено минимальное количество изменений.
Минусы
- Если Redis упадёт, сервис резко проседает по производительности и упирается в работу с БД.
- Каждый экземпляр сервиса будет требовать больше память, поскольку имеет свой in-memory кэш.
Поскольку высокая производительность была важнее, то минусы не считаю критичными. В перспективе, есть мысль, написать библиотеку, для упрощения реализации гибридного кэша, поскольку есть необходимость подобное кэширование применить в других проектах.
ссылка на оригинал статьи https://habr.com/ru/post/482704/
Добавить комментарий